- The paper's main contribution is MELT's novel approach using rarity-aware token refinement and diffusion-based denoising to enhance compositional image retrieval.
- It effectively mitigates frequency bias and suppresses hard negative interference by amplifying rare modification semantics and refining similarity scores.
- Experimental results on FashionIQ and CIRR datasets show MELT outperforms existing baselines, promising robust retrieval in varied application scenarios.
MELT: Modification Frequentation-Rarity Balance Network for Robust Composed Image Retrieval
Introduction
The task of Composed Image Retrieval (CIR) is to search for a target image by jointly conditioning on a reference image and a modification text, where the text describes desired edits or changes to the reference. In CIR, the semantic asymmetry between image and text—where the modification instructions may have loose or partial correspondence to image content—complicates precise semantic alignment. This complexity is particularly exacerbated by two limitations observed in current methods: (1) frequency bias towards high-occurrence objects or instructions, resulting in rare sample neglect, and (2) the contamination of similarity scores by hard negative samples, which are visually or semantically close to true matches.
MELT (Modification frEquentation-rarity baLance neTwork) directly addresses these limitations via two architectural contributions: a Rarity-Aware Token Refinement (RATR) module that explicitly amplifies rare modification semantics in the multimodal interaction, and a Diffusion-Based Similarity Denoising (DSD) module that refines the similarity matrix to robustly suppress noise from hard negatives. These innovations result in superior retrieval accuracy, especially in cases involving rare compositional semantics or challenging negatives.
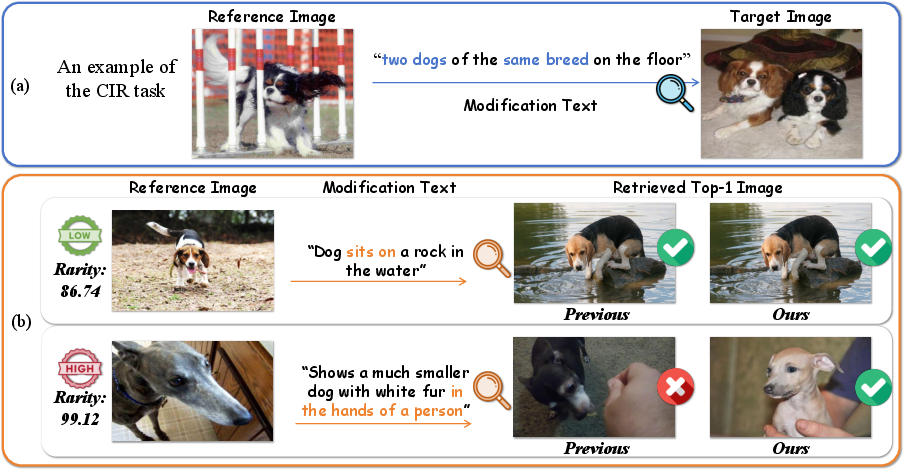
Figure 1: An instance of CIR showing MELT's effectiveness in handling rare semantic modifications and retrieval of rare samples.
Methodology
Rarity-Aware Token Refinement
The RATR module operates by first extracting deep representations of the reference image and modification text via BLIP-2’s Q-Former, producing query-based visual and textual embeddings. Cross-attention mechanisms identify the image regions that are most influenced by the modification text. By computing text-to-image attention, the model localizes tokens in the image with maximal semantic overlap to the text instruction.
To quantify and leverage rarity, MELT introduces a text-guided rarity measure. This is achieved by analyzing both the Mahalanobis distance (residual energy) between the modification direction in feature space and the global statistics of the dataset, and the cosine similarity to evaluate directional semantic alignment. Samples with high rarity scores are adaptively identified and subsequently transformed—via recalibration of the most relevant image token embeddings—thereby enhancing their discriminative power in the fused multimodal space.
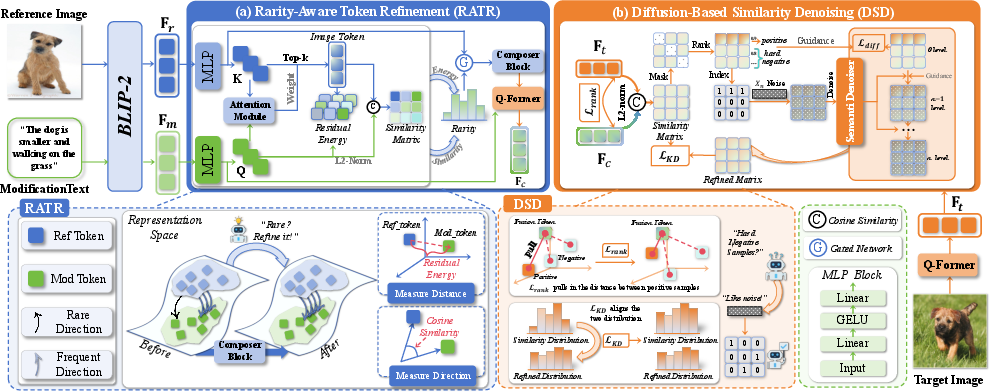
Figure 2: MELT architecture, illustrating (a) Rarity-Aware Token Refinement for rare semantic amplification and (b) Diffusion-Based Similarity Denoising for robust similarity estimation.
Diffusion-Based Similarity Denoising
Standard CIR scoring mechanisms are susceptible to high-similarity hard negative samples, which adversely impact ranking. The DSD module recasts similarity score refinement as a semantic denoising process, utilizing a denoising diffusion implicit model (DDIM). Given an initial similarity matrix between query and gallery items, the denoiser is trained to iteratively filter out the semantic noise characteristic of hard negatives. Gaussian noise is injected during training to simulate the confounding effects of these samples, and the denoiser is constrained by KL-divergence-based objectives for both the ground-truth and knowledge-distilled targets.
This multi-step refinement process produces a purified similarity matrix, driving improved ranking robustness and consistent semantics across domains with either frequent or rare modifications.
Experimental Results
MELT establishes new state-of-the-art performance on two representative CIR datasets: FashionIQ (fashion domain) and CIRR (open-domain). On FashionIQ, MELT yields an average R@10 of 59.20% and an average R@50 of 79.86%, outperforming all prior baselines—including ENCODER, SPRC, and QuRe—by significant margins (+3.07% on R@10, +2.27% on R@50). On CIRR, MELT increases R@1 and the overall average, confirming its efficacy both in domains with imbalanced category frequencies and in more uniform open-domain settings.
Ablation studies further demonstrate that both RATR and DSD are essential: removing attention or not discriminating by sample rarity significantly degrades performance, as does omitting the diffusion denoiser or its associated training constraints.
Implications
The explicit modeling of frequency bias and rare semantic localization encourages more fine-grained and equitable representation learning in CIR models, which is pivotal for robust downstream applications such as conditional visual generation and fine-grained visual search. The adoption of a diffusion-based semantic denoising technique is a notable departure from static similarity scoring, introducing principled robustness against hard negatives without the computational cost of generative modeling.
From a theoretical perspective, MELT's architecture suggests promising directions for hybrid information-bottleneck-inspired rarity analysis and progressive score denoising, with extensions potentially applicable to broader multimodal retrieval, cross-modal reasoning, and even open-ended vision-language understanding. Practically, the approach is expected to generalize to noisy or long-tailed real-world distributions, e.g., retrieval of rare concepts in e-commerce visual search or adaptive recommendation.
Conclusion
MELT introduces two key algorithmic advances for CIR: a rarity-aware cross-modal composition module that significantly improves semantic alignment for rare and subtle modifications, and a lightweight, diffusion-based denoising pipeline that robustly suppresses hard negative interference in the similarity estimation process. The resulting architecture delivers strong gains on both fashion and open-domain CIR datasets and establishes a new reference for addressing distribution shift and negative sample contamination in compositional retrieval scenarios.