- The paper presents a novel PRISM dataset that overcomes conventional video-language limitations by providing multi-view, ontology-structured data for embodied AI in retail.
- It employs a hybrid annotation pipeline that integrates LLM-generated chain-of-thought, physics-grounded reasoning, and synchronized multi-modal video to ensure high-fidelity supervision.
- Empirical results demonstrate significant improvements, including a 23.8% accuracy increase and up to five-fold error reduction in embodied reasoning tasks.
PRISM: A Multi-View, Multi-Capability Retail Video Dataset for Embodied Vision-LLMs
The PRISM dataset establishes a new methodological and empirical standard for training and evaluating embodied vision-LLMs (VLMs) in structured retail environments. It provides the first large-scale, multi-view, and ontology-structured instruction-tuning corpus designed to comprehensively cover all key perceptual and reasoning capabilities required for real-world deployment of physical AI systems.
Motivation and Problem Statement
Conventional VLMs and video-language datasets exhibit critical limitations for embodied AI in physical settings, particularly in domains like retail. These gaps include inadequate coverage of spatial, temporal, and embodied action knowledge; a lack of synchronized egocentric and exocentric video; restricted capability probes; and non-systematic curriculum composition. PRISM directly addresses these deficits via (i) a tightly defined knowledge ontology spanning space, time, and embodied action; (ii) balanced coverage of synchronized egocentric, exocentric, and 360° panoramic video; and (iii) finely differentiated annotation protocols enabling chain-of-thought (CoT), multi-choice, and open-ended supervision. The unified framework renders PRISM especially suited for training robust, generalizable embodied VLMs in complex, dynamic environments such as retail stores.
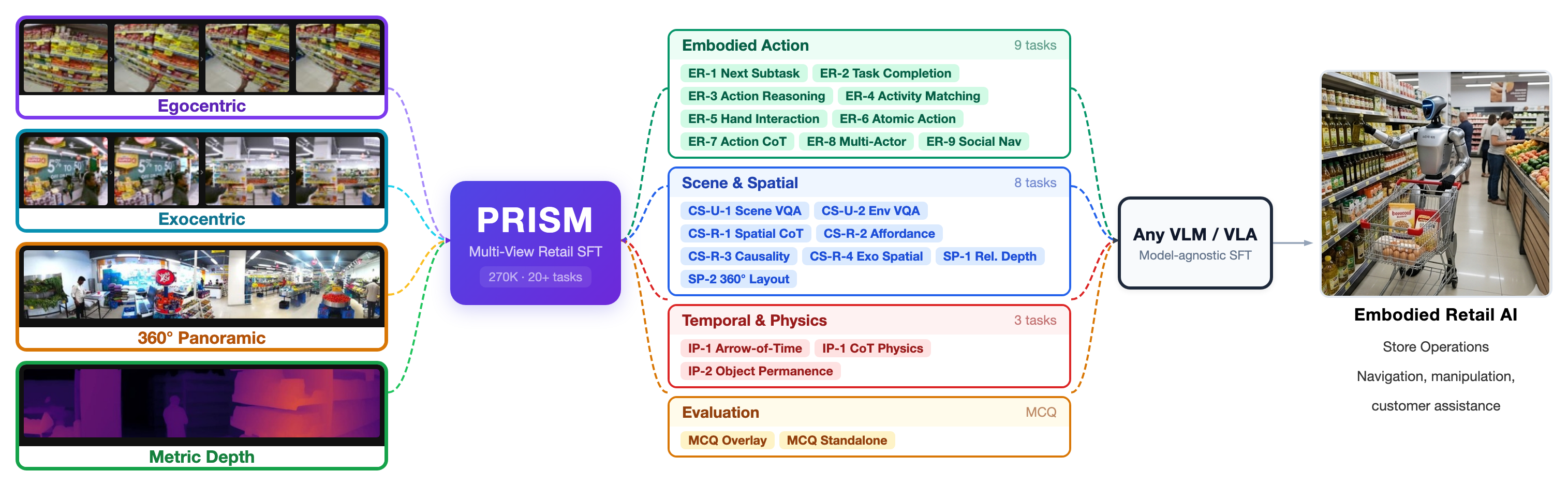
Figure 1: PRISM captures multi-view retail video from four synchronized modalities—egocentric, exocentric, 360° panoramic, and depth—enabling ontology-aligned supervision for robust, generalizable VLM adaptation.
Dataset Construction and Ontology
PRISM comprises 270,000 supervised fine-tuning (SFT) samples systematically distributed across 20+ distinct capability probes. The samples are drawn from video recorded in five diverse, structured retail environments using both wearable (egocentric) and omnidirectional (ALIA 360°) exocentric cameras. The ontology is explicitly factored into four capability domains—Embodied Reasoning (ER), Common Sense (CS), Spatial Perception (SP), and Intuitive Physics (IP)—which together instantiate a triadic knowledge structure: spatial understanding, temporal/causal inference, and embodied action reasoning.
The annotation pipeline integrates five strategies: (1) structured metadata extraction via domain-specific task logs, (2) LLM-based (Gemini 2.5 Flash) QA and CoT generation, (3) physics-grounded reasoning (Gemini Robotics ER 1.5) over video, (4) depth analysis (DepthCrafter) for spatial statistics, and (5) self-supervised transformations for physical pretext tasks (e.g., arrow-of-time, object permanence). This hybrid protocol yields high-diversity, high-fidelity supervision across all capabilities with minimal human cost.
(Figure 2)
Figure 2: PRISM pipeline overview showing data acquisition, multi-modal annotation, ontology-structured capability probes, and VLM fine-tuning integration across ego/exo/360° views.
Each capability probe implements a unique, operational challenge derived from practical deployment scenarios:
- Embodied Reasoning (ER): Sequential subtask prediction, task completion verification, goal-conditioned action reasoning, cross-view action matching, fine-grained hand interaction recognition, atomic action recognition/reasoning (exocentric), multi-actor scene analysis, and social navigation reasoning.
- Common Sense (CS): Scene/environment VQA (ego/exo), depth-aware spatial CoT, affordance and causality reasoning, and exocentric spatial inference.
- Spatial Perception (SP): Relative depth ordering and panoramic 360° spatial layout reasoning.
- Intuitive Physics (IP): Arrow-of-time discrimination (ego/exo), CoT over physical motion cues, and object permanence.
Each probe supports either open-ended understanding, CoT with ⟨think⟩ tags, or MCQ overlays, with a balanced mix to eliminate format-induced learning bias. The compositional diversity is unmatched in prior datasets and critically supports ablation and curriculum studies.
Experimental Protocol and Results
Fine-tuning experiments leverage Cosmos-Reason2-2B, a Qwen3-VL-based VLM optimized for video-language physical reasoning. PRISM training is performed with LoRA adaptation (49.3M parameters, BF16) to ensure resource-efficiency and analytic clarity. The evaluation suite measures MCQ accuracy (task-specific multiple choice) and GPT-4o auto-judged CoT quality, with rigorous hold-out validation for each capability.
Key findings:
- Aggregate Performance: PRISM fine-tuning increases average accuracy across all tasks from 62.8% (zero-shot baseline) to 86.6% (+23.8%), with an average error reduction of 66.6%.
- Embodied Reasoning: ER domains observe up to five-fold reduction in error rates. Notably, goal-conditioned action reasoning and atomic action CoT see >+55% absolute accuracy gains over baseline.
- Cross-View Generalization: Incorporating exocentric supervision significantly improves cross-view reasoning without degrading egocentric capabilities, validating the hypothesis that multi-view curriculum is synergistic.
- Chain-of-Thought Supervision: LLM-generated CoT labels yield stronger performance improvements than template-based alternatives, confirming that supervision format directly impacts learning signal quality and reasoning robustness.
- Data Scaling: 60% of the dataset achieves approximately 95% of total attainable gain, highlighting data efficiency for practical deployment.
(Figure 3)
Figure 3: Representative examples of PRISM’s diverse capability probes, including sequential next-action prediction, scene VQA, egocentric–exocentric matching, depth-aware spatial reasoning, and physics-grounded chain-of-thought outputs.
(Figure 4)
Figure 4: Scaling analysis—accuracy as a function of training progress, by domain and overall, showing rapid gains in early stages with diminishing returns after ~60% data utilization.
Theoretical and Practical Implications
PRISM’s methodology substantially extends the state of the art in both embodied VLM training and dataset design. Notable implications include:
- Unified, Domain-Aligned Instruction-Tuning: By enforcing deployment-specific, ontology-driven supervision, PRISM enables the development and evaluation of VLMs that are explicitly matched to the complex, multi-agent, multi-view challenges of real retail environments.
- Ego-Exo Curriculum as a Fundamental Axis: The results strongly argue that multi-view learning (especially panoramic exocentric) is essential for robust, deployment-relevant perception and long-horizon task planning—contradicting prior assumptions over reliance on purely egocentric corpora.
- Annotation Pipeline Efficiency: The demonstrated scalability via hybrid, LLM-augmented annotation sets a framework for future data curation across other structured domains (e.g., healthcare, logistics) without excessive manual cost.
- Format-Driven Reasoning Generalization: The systematic advantage of chain-of-thought over template supervision further supports the stance that annotation design—not solely model scale—mediates successful reasoning adaptation.
Limitations and Future Directions
The primary limitation is the focus on a single VLM backbone (Cosmos-Reason2-2B), which constrains generalization of scaling analysis to larger architectures. Automated evaluation (MCQ, GPT-4o) may underestimate emergent natural language capabilities on harder tasks. Future extensions include: scaling analysis on 7B–13B class VLMs, incorporating additional sensors (metric depth, IMUs), downstream deployment in closed-loop robotic control (e.g., GR00T pipeline), and collection of further data from new domains and retail settings to probe generalization limits.
Conclusion
PRISM delivers the first truly comprehensive, multi-view, capability-rich, and instruction-format balanced SFT dataset for embodied vision-LLMs in retail. The empirical evaluation demonstrates large, systematic improvements over state-of-the-art generalist video-LLMs, with the greatest impact in action reasoning, cross-view understanding, and spatial/temporal physical knowledge. Both PRISM and its findings constitute essential infrastructure for the next generation of robust, adaptable, and generalizable embodied AI systems.