- The paper introduces SplatHLoc, a hierarchical relocalization method that leverages Feature Gaussian Splatting to generate virtual views and improve initial pose estimation under sparse observations.
- The paper details an adaptive coarse-to-fine retrieval pipeline that synthesizes multi-modal maps and employs a hybrid matching strategy to overcome low-texture and viewpoint sparsity challenges.
- The paper demonstrates superior performance on benchmarks like 7-Scenes, 12-Scenes, and Cambridge Landmarks, achieving lower median errors and higher recall rates compared to conventional methods.
Hierarchical Visual Relocalization with Feature Gaussian Splatting: A Technical Analysis
Framework Overview and Motivation
SplatHLoc introduces a hierarchical relocalization method grounded in Feature Gaussian Splatting (FGS), providing a comprehensive solution for estimating 6-DoF camera poses under sparse observations and complex appearance variation. The approach leverages the novel view synthesis capability of FGS to dynamically generate virtual candidates that address limitations in conventional hierarchical relocalization frameworks relying on static image databases. This enables the retrieval of reference images with viewpoints closely aligned to the query, facilitating robust initial pose estimation. By synthesizing multi-modal maps (color, depth, feature) from the FGS representation, SplatHLoc adapts image retrieval and feature matching, thus overcoming challenges posed by low-texture scenes, repetitive structures, and viewpoint sparsity.
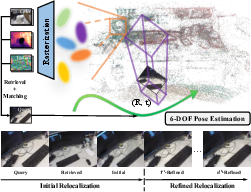
Figure 1: SplatHLoc exploits FGS to render color, depth, and feature maps for hierarchical relocalization, iteratively refining pose estimates via synthesized novel views.
Technical Contributions
Adaptive Viewpoint Retrieval
The adaptive viewpoint retrieval pipeline operates via coarse-to-fine stages: (i) coarse retrieval uses conventional image retrieval over global descriptors, (ii) insufficient inlier correspondences trigger fine retrieval, which involves rendering virtual keyframes via FGS by perturbing candidate poses. KNN-based retrieval followed by geometric verification identifies the reference view most consistent with the query. Perturbation hyperparameters (angle a, distance b) are tuned to optimize recall without excessive computational overhead, validated by ablation studies. This C2F pipeline efficiently navigates sparse observation regimes, yielding robust pose candidates and avoiding unnecessary database augmentation.
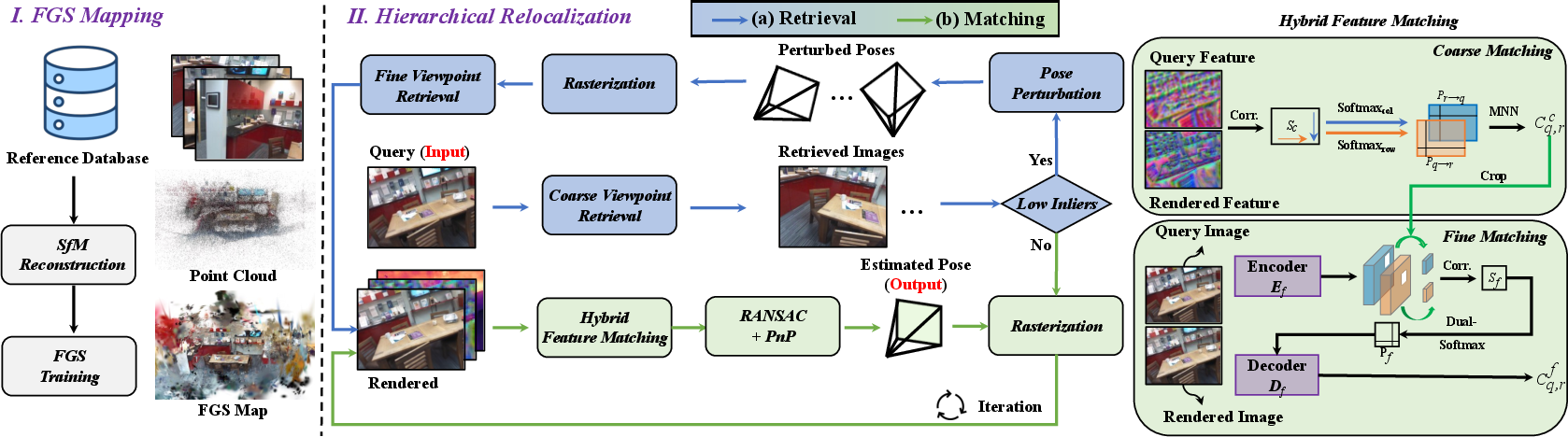
Figure 2: The SplatHLoc pipeline: database initialization, adaptive retrieval, hybrid matching, and iterative pose refinement.

Figure 3: Adaptive Viewpoint Retrieval increases co-visibility and inlier correspondences by synthesizing pose-perturbed virtual views.
Hybrid Coarse-to-Fine Feature Matching
SplatHLoc implements a hybrid matcher that exploits the strengths of both FGS-rendered feature maps and semi-dense matchers. Rendered features, benefiting from multi-view consistency, are used for patch-level coarse matching, while fine features extracted from color images using models such as JamMa perform pixel-level refinement. This design circumvents the feature gap between rendered features and those generated by conventional image encoders, which can negatively impact geometric precision in dense correspondence estimation. Ablation demonstrates that rendered features are ideal in the coarse stage, whereas fine matching should exclusively leverage semi-dense encoders for best accuracy.
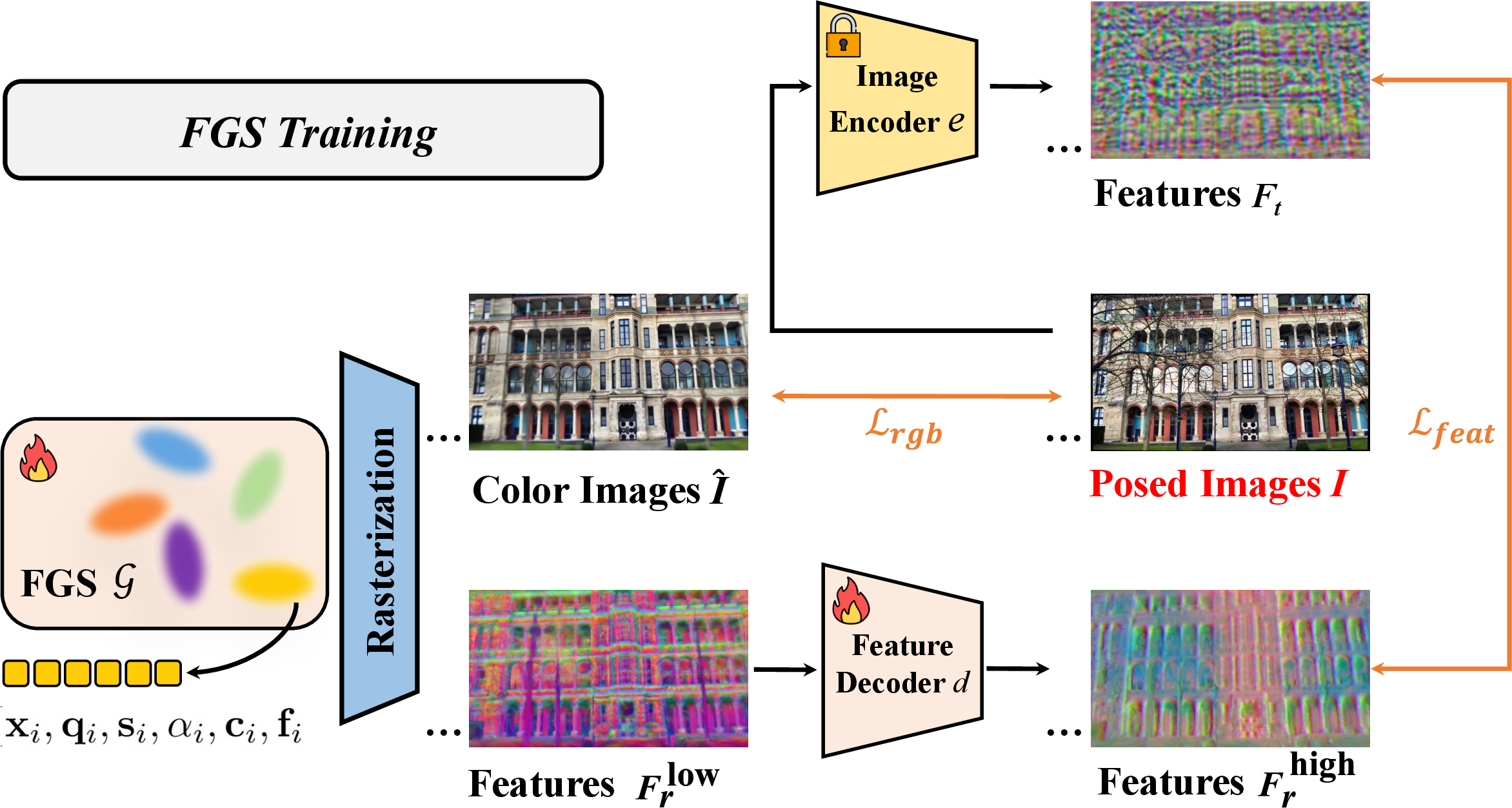
Figure 4: FGS training employs a feature decoder to compress rendered features, improving efficiency and reducing storage overhead.
Experimental Validation
Benchmark experiments on 7-Scenes, 12-Scenes, and Cambridge Landmarks datasets confirm significant improvements in both median translation/rotation errors and recall rates compared to state-of-the-art structure-based, regression-based, NeRF-based, and GS-based render methods. SplatHLoc achieves lowest average errors and highest recall across all metrics, with exemplary robustness in low-texture and wide-baseline settings:
- 7-Scenes Dataset: SplatHLoc outperforms alternatives with median errors (translation/rotation) as low as 0.55cm/0.17∘, establishing a new accuracy benchmark.
- 12-Scenes Dataset: Achieves 0.3cm/0.14∘ median error and 97.3% recall under stringent 2cm,2∘ thresholds.
- Cambridge Landmarks: Maintains <10cm/0.13∘ error, superseding NeRF-based and GS-based methods by large margins in urban, dynamic environments.

Figure 5: Visualization highlights accurate pose alignment by comparing query and rendered images; errors are localized to regions of scene ambiguity.

Figure 6: SplatHLoc demonstrates superior relocalization accuracy via visual alignment between query and rendered images on Cambridge Landmarks.

Figure 7: Result visualization on 7-Scenes emphasizes SplatHLoc's reliability across diverse indoor conditions.
Complexity and Efficiency
SplatHLoc delivers superior runtime efficiency with lower initial pose estimation and iterative refinement times relative to competing GS-based approaches (e.g., STDLoc). Training stages benefit from compressed feature fields, reducing GPU memory and map size nearly threefold. The modular feature decoder enables rapid scene mapping, supporting scalability toward large environments.
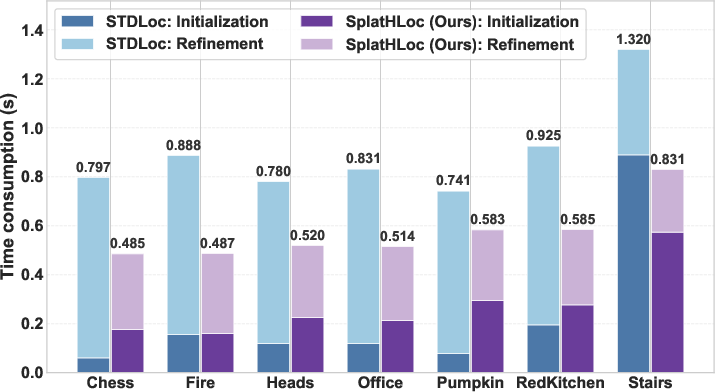
Figure 8: Runtime comparison reveals that SplatHLoc consistently outperforms STDLoc in both pose estimation and refinement stages.
Ablation and Analysis
Comprehensive ablation studies validate the necessity and positive impact of both adaptive viewpoint retrieval and the hybrid matching strategy. Using rendered features only for coarse matching and semi-dense matchers for refinement yields highest recall and lowest errors; reversing this pairing diminishes performance, confirming the design rationale. Increasing the number and range of virtual views balances recall and efficiency, with moderate perturbations optimizing initialization success.
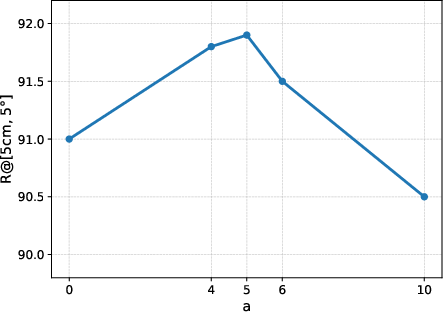
Figure 9: Recall analysis under varying angular perturbations confirms the impact of carefully tuned viewpoint sampling.
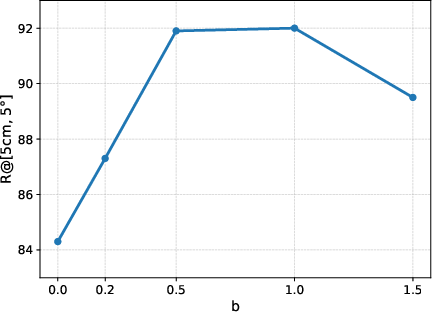
Figure 10: Recall as a function of spatial perturbation magnitude; performance peaks at moderate translation values.
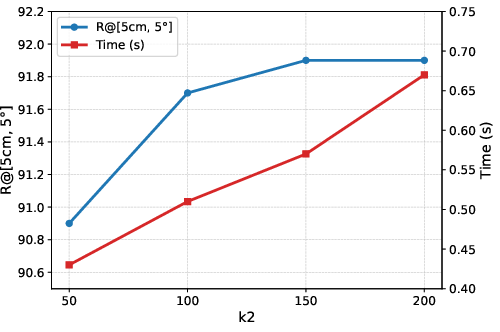
Figure 11: Initialization accuracy and runtime trade-off with number of virtual views, guiding practical system configuration.
Practical and Theoretical Implications
SplatHLoc's hierarchical integration of FGS for adaptive retrieval and hybrid feature matching positions it as a scalable, scene-agnostic solution for visual relocalization under diverse conditions. The framework adapts to non-uniform database sparsity, low feature textures, and appearance changes without requiring database augmentation or retraining, facilitating deployment in intelligent robotics, AR, and autonomous navigation.
Theoretically, the work elucidates the synergistic relationship between feature representation and matching granularity—demonstrating that multi-view rendered features inherently excel in coarse retrieval/matching, while fine correspondence must leverage original image features for geometric consistency. This insight informs future research on end-to-end learned feature fields and scene representations tailored for hierarchical relocalization.
Conclusion
SplatHLoc establishes a new benchmark in hierarchical visual relocalization by leveraging Feature Gaussian Splatting for adaptive viewpoint synthesis and hybrid feature matching, achieving state-of-the-art accuracy and efficiency in both indoor and outdoor settings (2603.29185). The framework's modularity and extensive validation underscore its applicability across challenging environments. Future directions include leveraging foundation 3D models for Gaussian primitive initialization and scalable mapping approaches for very large environments, pointing toward even greater robustness and generalization in visual localization systems.