- The paper introduces a novel framework that integrates multimodal LLMs with a customized toolchain to enhance web scraping accuracy.
- The methodology combines GUI agent manipulation with external code generation and merging tools, resulting in improved extraction robustness and scalability.
- Experimental results demonstrate significant improvements in dynamic index-content extraction across diverse news and e-commerce web platforms.
Leveraging Multimodal LLMs for Robust Web Scraping: The Webscraper Framework
Introduction
The rapid proliferation of dynamic and interactive web interfaces has rendered traditional HTML-based crawling increasingly inadequate for reliable and scalable information extraction. In "Webscraper: Leverage Multimodal LLMs for Index-Content Web Scraping" (2603.29161), a framework is introduced that integrates Multimodal LLMs (MLLMs) with specialized toolchains for robust, domain-agnostic web scraping. The framework targets sites with the prevalent index-and-content architecture—ubiquitous across news, e-commerce, and social platforms—where information retrieval involves dynamically navigating index pages and extracting structured information from content pages.
System Architecture and Methodology
The core architectural advancement is the orchestration of a general-purpose GUI agent (Anthropic's Computer Use) with custom-designed tools for parsing and merging, all mediated by a structured five-stage prompting protocol. This modular design circumvents the brittleness of rule-based wrappers and the inefficiency of single-purpose LLM agents by empowering the agent to autonomously determine when to invoke visual navigation tools and when to offload parsing to an external code generation backend (GPT-o3).
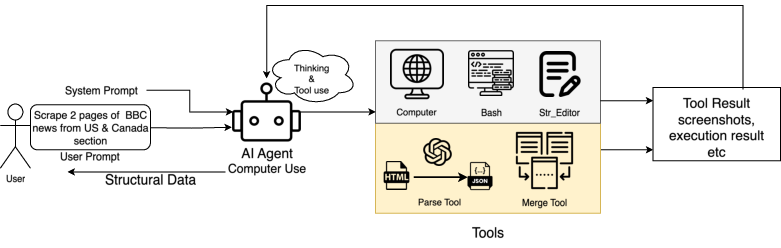
Figure 1: The Webscraper system integrates native environment tools and custom extraction tools, orchestrated by MLLM-driven agents for robust, interactive web data extraction.
The architecture balances native interaction tools—such as mouse movement, scrolling, file editing, and scripting—with specialized scraping components. Notably, the Parse Tool delegates HTML extraction and parsing logic to an upstream LLM (GPT-o3), which generates purpose-built Python scripts executed in a code interpreter sandbox. This decouples low-level parsing complexity from the main agent prompt, preserving context and enhancing robustness for large-scale extraction.
Additionally, the Merge Tool aggregates intermediate results, providing deduplication and consolidation mechanisms essential for distributed multi-iteration extraction and paginated navigation. The system’s operational flow is initiated by a natural language user prompt specifying scope, targets, and required fields, formalizing the extraction task as a structured JSON output.
Experimental Framework
Evaluation Protocols
To empirically assess performance, the framework is evaluated on six heterogeneous news sites encompassing English and Chinese, representing diverse interaction paradigms such as infinite scroll and dynamic content loading. A manually curated ground truth (Golden set) for URLs, titles, and article content ensures robust alignment for result validation.
Performance is quantified with ROUGE-L for title and content fidelity, complemented by a binary Correctness metric requiring both URL exact match and ROUGE-L ≥ 0.8. This dual-layer metric penalizes both under- and over-extractions, providing discriminative granularity over noisy web content.
Experimental Conditions
Three agent configurations are compared:
- Baseline (zero-shot Computer Use agent): Direct unprompted application, no custom tools.
- Webscraper (Prompt Only): Augments the baseline with structured prompting, disables custom tools.
- Webscraper (Prompt + Tool): Full system with both guided prompting and functional toolchain.
Preliminary statistical analysis establishes that 30 runs suffice for metric stabilization, as evidenced by both the elbow point in 95% CI half-width convergence and cumulative average correctness traces.
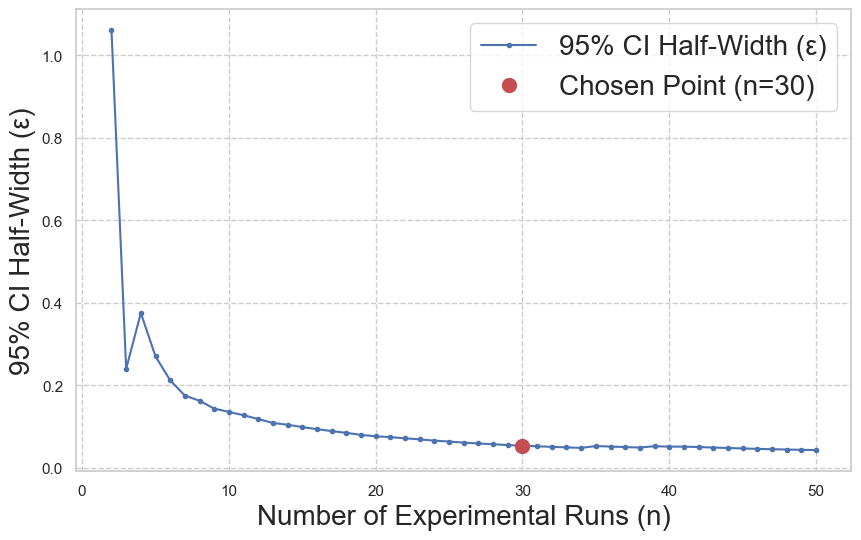
Figure 2: 95% CI half-widths rapidly contract up to n=30 trials, after which additional runs yield diminishing improvements in statistical certainty.
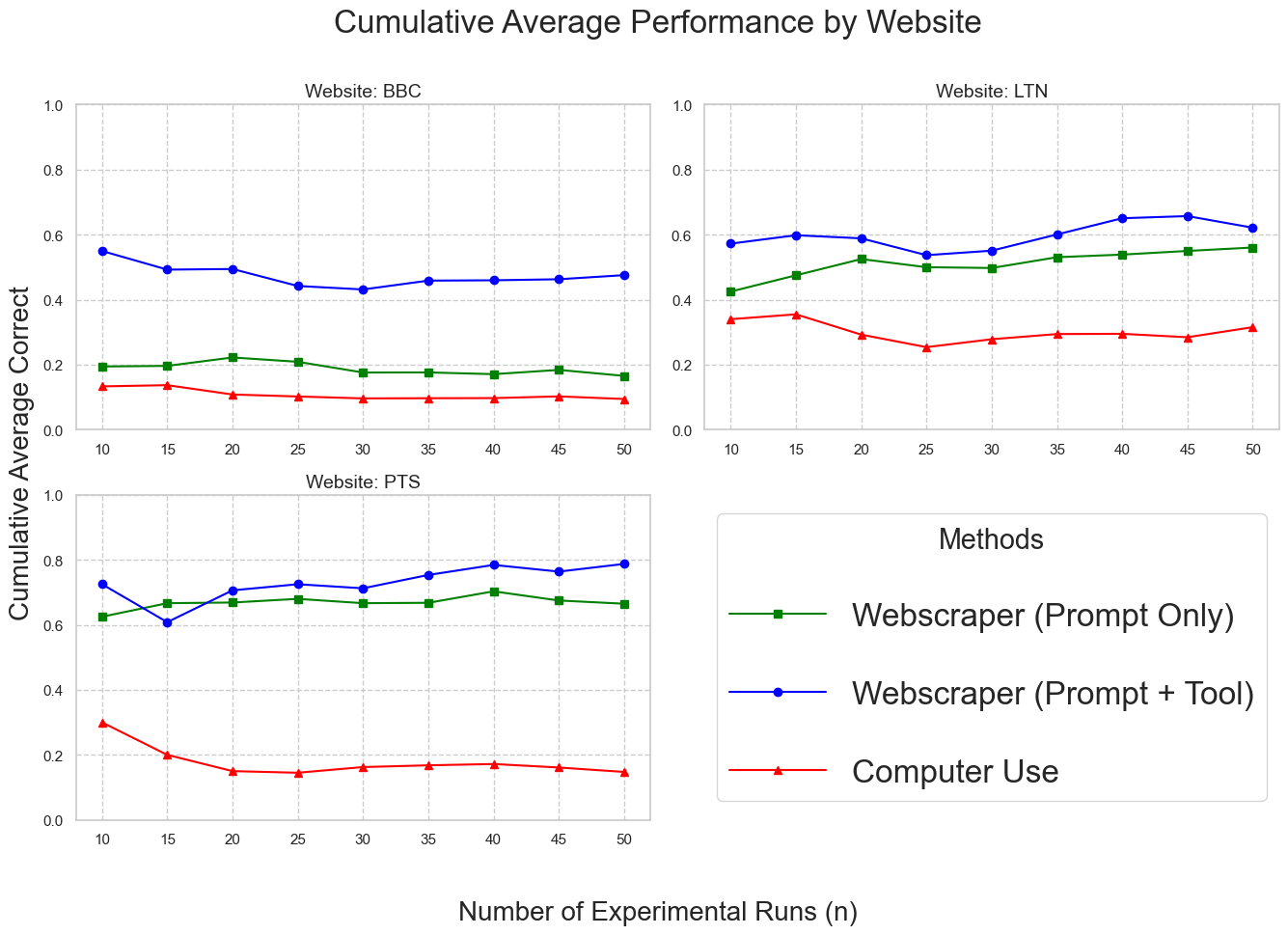
Figure 3: Cumulative average correctness stabilizes after 30 agent runs, validating experimental sample sufficiency.
Main Results and Performance Profile
Webscraper (Prompt + Tool) achieves substantial improvements over both baseline and prompt-only ablations across all six evaluated sites, with greatest gains on sites requiring non-trivial navigation such as pagination. The baseline agent fails on most dynamic interaction tasks, rarely identifying or successfully manipulating multi-page navigation controls.
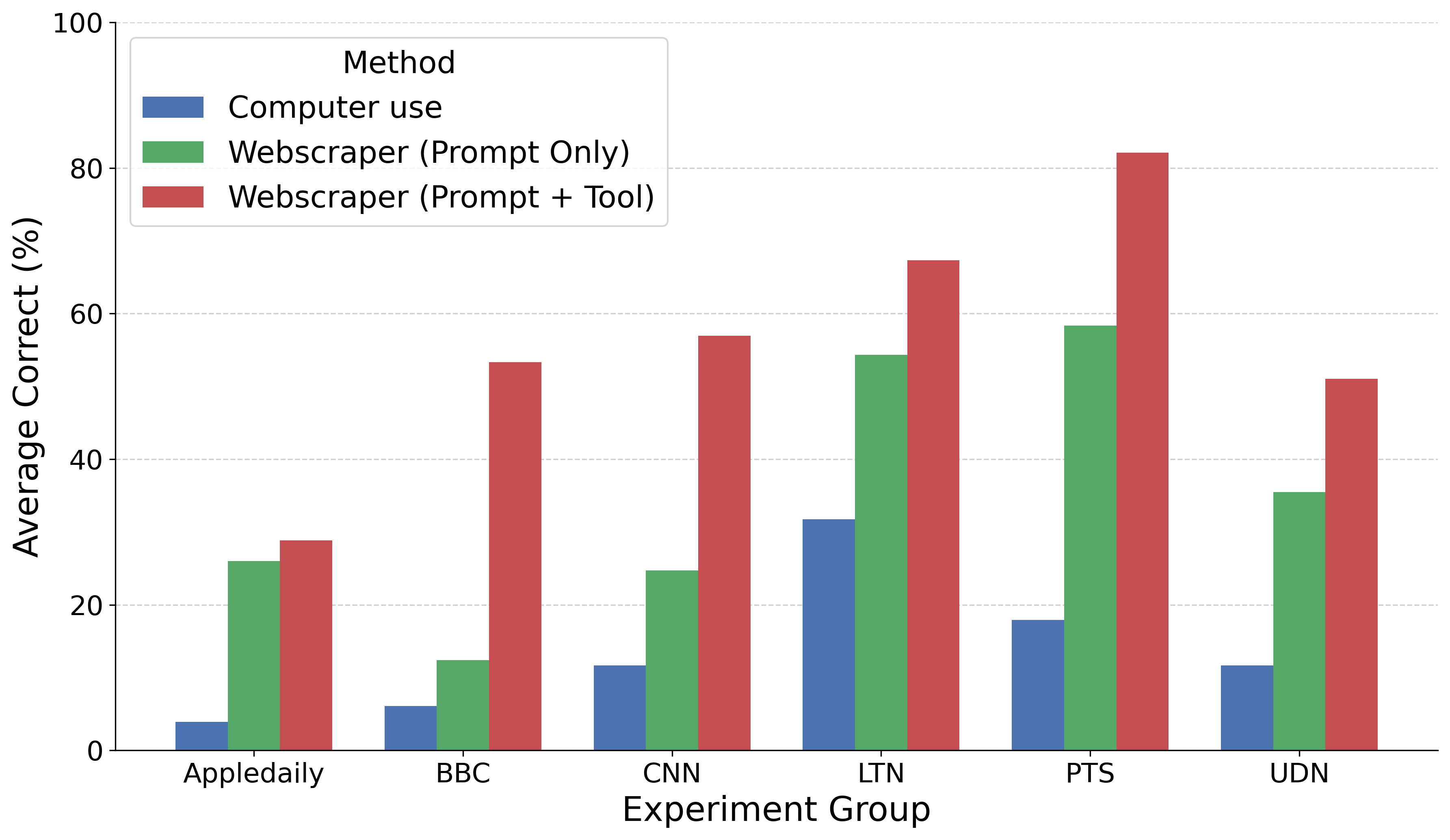
Figure 4: Webscraper (Prompt + Tool) achieves markedly higher extraction accuracy than ablation and baseline agents across all experimental news domains.
The addition of specialized parsing and data merging tools yields further gains over prompt-only guidance, empirically validating the necessity of externalizing complex code generation and consolidation processes.
Domain Generalization: E-commerce Benchmark
To evaluate architectural generalization beyond news domains, experiments are extended to e-commerce sites (Amazon, Momo). The full framework again outperforms both preceding variants, although results on Momo are depressed due to ambiguous field selection arising from multiple, competing price attributes (e.g., promotional vs. market price). Such ambiguity, which is less tractable for prompt-only or baseline agents, highlights the need for advanced visual grounding and field disambiguation.

Figure 5: Momo platform exhibits field ambiguity with visually indistinct pricing attributes, increasing agent extraction complexity.
Stability, Robustness, and Limitations
Temporal robustness is established via re-execution after a seven-day interval, showing less than 5% accuracy variance for Webscraper (Prompt + Tool)—underscoring the method’s reproducibility in live web environments.
Despite its superior performance, the proposed system remains constrained by several architectural factors:
- Visual grounding errors in complex navigation scenarios (e.g., zoom-induced misclicks).
- Occasional buggy Python code generation for anomalous HTML DOMs.
- Limitation to index-content architectures; insufficient for real-time stream-oriented interfaces or advanced virtual scrolling that manipulate the DOM dynamically.
Theoretical Implications and Future Directions
This research formalizes a clear separation between generalist agent interaction proficiency and the requirements for scalable, structured web extraction. By programmatically generating one-off, reusable extraction scripts with LLMs—rather than iteratively controlling a browser for each data point—the approach achieves improved efficiency, context footprint management, and scalability.
Future work should focus on hybrid agents that unify GUI-level manipulation with DOM mutation and network traffic introspection. By enabling the agent to simultaneously monitor page rendering events, DOM changes, and XHR/WebSocket activity, such systems could surmount the architectural bottlenecks of both pure GUI and DOM-level agents. These developments would allow for the one-shot generation of deterministic, maintainable scrapers that directly access site APIs when possible, minimizing LLM dependence during repeated deployments.
Conclusion
The Webscraper framework demonstrates that coupling MLLMs with a domain-general prompt protocol and a judiciously designed toolchain produces significant advances in extraction performance across dynamic web environments. The system generalizes well to various domains exhibiting index-content organization and remains statistically robust over time. Theoretical implications extend to broader agent design, emphasizing that specialized tool integration—rather than exclusive reliance on generalist reasoning—yields substantive practical benefits for modern large-scale information extraction.
Reference: "Webscraper: Leverage Multimodal LLMs for Index-Content Web Scraping" (2603.29161)