- The paper introduces SemLoc, a hybrid framework that grounds LLM-generated semantic insights into executable, checkable constraints for fault localization.
- It employs a closed intermediate representation and SSA-based instrumentation to precisely map semantic constraints to code, reducing inspected code to 7.6% and attaining 42.8% Top-1 accuracy.
- Counterfactual verification is applied to validate causal links, yielding a 12% absolute gain in Top-1 accuracy and isolating primary causal constraints in 60.8% of cases.
Problem Statement and Motivation
Fault localization is central to software reliability, especially as semantic bugs—errors violating program intent but not execution structure—become prevalent in the presence of AI systems and numerically sensitive applications. Classical spectrum-based fault localization (SBFL) approaches, which correlate execution structure (coverage, control flow, data dependencies) with test outcomes, are fundamentally limited in this context: for semantic bugs, passing and failing executions often have indistinguishable traces. Consequently, coverage-based suspiciousness signals collapse, causing a sharp loss of discriminatory power.
Recent LLM-based techniques have attempted to remedy this by reasoning semantically (e.g., generating coarse-grained suspicious locations or natural language explanations), but these outputs are stochastic, unverifiable, and difficult to attribute causally. There persists a significant gap: existing methods are unable to systematically convert LLM-inferred semantic knowledge into checkable, program-anchored evidence that can be compared across executions and validated as the actual cause of failures.
Methodology: Structured Semantic Grounding
SemLoc proposes a hybrid framework that grounds LLM-inferred semantic reasoning structurally and operationalizes it as executable, runtime-validated constraints for fault localization. At a high level, the approach consists of three main stages, as illustrated in Figure 1.
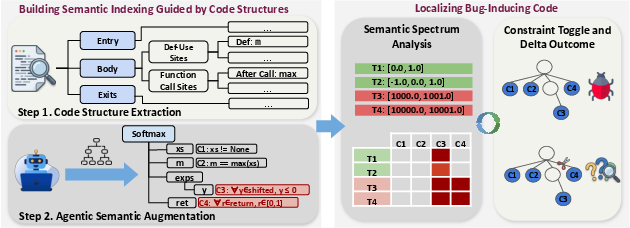
Figure 1: The SemLoc workflow infers semantic constraints, grounds them to program structures, performs semantic spectrum analysis, and applies counterfactual verification.
Semantic Constraint Representation and Structural Grounding
SemLoc introduces a closed intermediate representation (cbfl-ir) for semantic constraints. Each constraint is a tuple containing a category (e.g., precondition, postcondition, value range), an instrumentation region (e.g., after assignment, loop head, function entry), a structural anchor (SSA-versioned variable or program point extracted via Tree-sitter AST and SSA transformation), a boolean predicate expressing the property, and a natural-language intent string.
This schema bounds the inference space and enables the LLM to propose semantic properties that are both checkable and program-positioned. SemLoc instruments the program at precise anchor sites determined by a Tree-sitter–based SSA pass, which enables unambiguous mapping from constraints to code locations, even in the presence of multiple assignments and complex control flow.
Agentic Constraint Inference
Given a buggy target function and a partitioned test suite, SemLoc queries an LLM—using a structured prompt containing the original/SSA-transformed function, definition-use maps, test outcomes, and explicit output schema—to infer semantic constraints. Each constraint anchors to a specific SSA variable or control-flow point, and all expressions are required to be side-effect-free and executable.
Semantic Spectrum Analysis
The instrumented program is run across the test suite. At each anchor, violations of semantic constraints are logged, building a constraint-by-test binary matrix—analogous to coverage spectra, but representing semantic, not syntactic, properties. Suspiciousness scores are computed using SBFL metrics (Ochiai coefficient), ranking program statements based on the frequency and specificity (failing vs. passing tests) of associated constraint violations.
Counterfactual Verification
Semantic signals are susceptible to two major noise types: constraints violated in both passing and failing tests (over-approximate), and cascading violations due to downstream effects of root faults. To address this, SemLoc uses the LLM to synthesize minimal, local candidate repairs (e.g., patching an assignment to fix a violated constraint) and reruns tests to assess causality. A constraint is:
- Primary if its repair resolves all failures—root-cause.
- Secondary if it reduces, but does not eliminate, failures.
- Irrelevant if it does not impact test outcomes.
Final rankings retain only primary constraints, providing precise, causally validated line-level fault localization.
Numerical Results and Empirical Evaluation
SemLoc was evaluated on SemFault-250, a diverse benchmark of 250 real-world Python programs containing single semantic faults—curated from established repositories and filtered to contain bugs violating semantic but not syntactic properties (e.g., off-by-one errors, normalization bugs, wrong relational operator).
Key baselines include SBFL (Ochiai, Tarantula), delta debugging, coverage-based slicing, and LLM static prediction techniques (e.g., AutoFL).
SemLoc achieves:
- Top-1 line localization accuracy: 42.8%
- Top-3 line localization accuracy: 68.0%
- Inspection set: 7.6% of executable lines (5.7× reduction over SBFL)
- Counterfactual verification provides a further 12% absolute gain in Top-1 accuracy and isolates a primary causal constraint in 60.8% of cases.
In contrast, SBFL-Ochiai yields only 6.4%/13.2% for Top-1/Top-3 accuracy, flagging 43.6% of code for inspection. Delta debugging fails to prioritize correctly under worst-case tie-breaking. An LLM-only line prediction baseline (SemLoc without semantic indexing) achieves 37.6% Top-1 accuracy but with poor recovery—statistical localization plateaus due to lack of test-based semantic evidence.
Ablation and region-weighted analyses show Line-anchored constraints are the highest-value signals, but non-Line anchors (definitions, branches, loops, returns) contribute significant recall, collectively improving Top-3/Top-5 metrics by 2–4 percentage points each.
On real-world BugsInPy cases, a two-stage SemLoc/AutoFL pipeline (function navigation by AutoFL, line localization by SemLoc) achieves up to 57.1% Top-1, 85.7% Top-3, and 100% Top-5 accuracy (youtube-dl subset). This demonstrates the practical integrability of such approaches even for complex, multi-module projects.
Implications and Theoretical Insights
SemLoc introduces a shift from coverage- or static-spectrum–based approaches to explicit semantic spectrum analysis: localization moves from the question "where does control/data flow diverge?" to "where are program semantics violated in failing but not passing executions, and can those violations be causally validated?" This paradigm is robust to faults that evade syntactic analysis but still admit a specification via operationalized constraints.
By casting the LLM as a semantic-intent generator and grounding its reasoning structurally—and by systematically validating the effect of candidate semantic repairs—SemLoc enables the following:
- Attributable and checkable semantic reasoning: Unlike free-form LLM suggestions, constraints are runtime-executable, test-discriminative, and structurally indexed.
- Scalable, interpretable diagnosis: The pipeline is compatible with existing CI/test harnesses and can be integrated atop repository-scale navigation agents. Constraint and patch explanations (in SSA-anchored, natural-language form) are interpretable and actionable.
- Theoretical generalization: This approach can accommodate richer semantic signals, including invariants learned from traces, domain-specific specifications, and cross-execution property mining. Integration with dynamic invariant inference systems or further training of LLMs to improve property generation (e.g., discriminative constraint mining) is a plausible future direction.
Limitations and Future Directions
Limitations include imperfect LLM constraint generation (irrelevant or imprecise constraints), the need for a sufficient test suite to ensure violation matrix discriminability, and dependence on the accurate mapping of SSA-anchors. In multi-fault scenarios (not the focus of the study), root-cause isolation may become ambiguous, requiring further causal disambiguation.
Potential next steps encompass leveraging richer semantic signals, integrating contract/documentation mining, extending to inter-procedural and multi-module contexts, and applying data-driven refinement of constraint generation (e.g., reinforcement learning for discriminative constraints).
Conclusion
SemLoc reframes fault localization around checkable, structurally-grounded program semantics inferred by LLMs and operationalized as runtime-executable constraints. Semantic spectrum analysis and causally validated counterfactual reasoning address the inherent ambiguity of free-form LLM suggestions, yielding strong empirical improvements on semantic bug localization—substantially narrowing developer inspection effort and localizing failures elusive to coverage-based and purely statistical methods. This work marks a move toward systematic, semantically-aware program analysis that extends naturally to future developments in AI-assisted debugging.