- The paper introduces EBRM, a framework that optimizes structured latent trajectories via energy minimization for iterative neural reasoning.
- It decomposes energy across per-step compatibility, transition consistency, and trajectory smoothness to analyze decoder mismatches.
- It demonstrates that dual-path decoder training can mitigate performance drops in tasks like CNF logic due to encoder-decoder distribution shifts.
Essay: "Reasoning as Energy Minimization over Structured Latent Trajectories" (2603.28248)
Introduction and Motivation
The paper introduces Energy-Based Reasoning via Structured Latent Planning (EBRM), a framework that replaces discrete, token-level iterative reasoning (e.g., chain-of-thought prompting) with continuous optimization over structured latent trajectories. EBRM leverages energy-based models (EBMs) to impose a scalar progress measure on multi-step reasoning, allowing gradient-based optimization of a latent trajectory z1:T under a decomposable energy function E(hx,z). The approach is motivated by the need for scalable, interpretable, and progress-aware reasoning strategies that transcend token-centric paradigms.
Methodology
The EBRM infrastructure comprises five components: encoder, latent trajectory, energy model, planner, and decoder. The encoder maps the input x to a dense representation hx. The latent trajectory z1:T is optimized to minimize the learned energy function E(hx,z), which decomposes into per-step compatibility, pairwise transition, and trajectory smoothness terms:
- Per-step score: Assesses each latent state’s relevance to the context.
- Transition score: Evaluates pairwise consistency between consecutive latent states.
- Smoothness term: Penalizes abrupt changes across the trajectory.
The planner initializes z1 from the encoder, samples subsequent states, and iteratively updates z via gradient descent or Langevin dynamics. A latent anchoring regularizer optionally constrains z to remain close to hx. Separate training routines govern the energy model (contrastive loss with hard negatives) and encoder-decoder (supervised losses). An optional dual-path decoder training addresses distribution mismatch by training on both encoder and planner outputs.
Empirical Evaluation
EBRM is instantiated on three synthetic tasks: graph shortest-path membership (node-wise binary labels), arithmetic expression evaluation (scalar regression), and CNF logic satisfaction (variable assignments).
Endpoint Performance:
Latent planning demonstrates a contradictory effect in logic satisfaction: accuracy drops from E(hx,z)0 (direct decoding) to E(hx,z)1 post-planning, even though planning monotonically decreases energy.
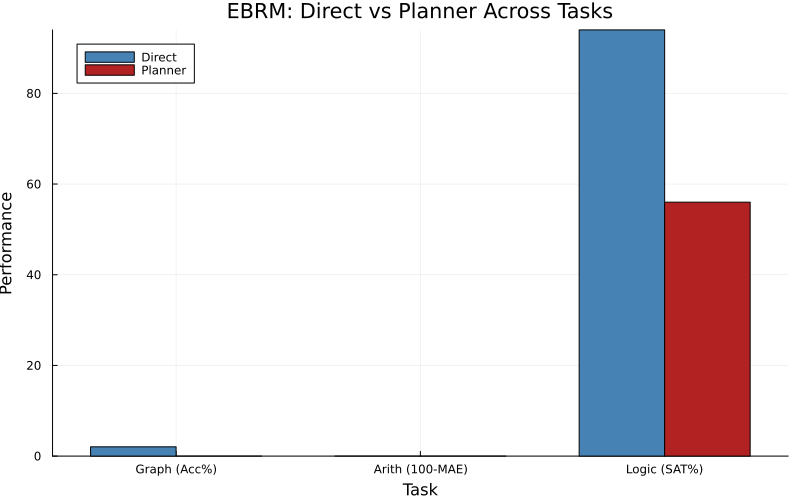
Figure 1: Direct vs planner endpoint performance across tasks. Planning degrades logic accuracy from E(hx,z)2 to E(hx,z)3, highlighting the distribution mismatch issue.
Energy Dynamics:
Energy descent is monotonic for graph and logic, but remains flat for arithmetic, revealing that the energy model fails to shape a meaningful landscape in arithmetic.
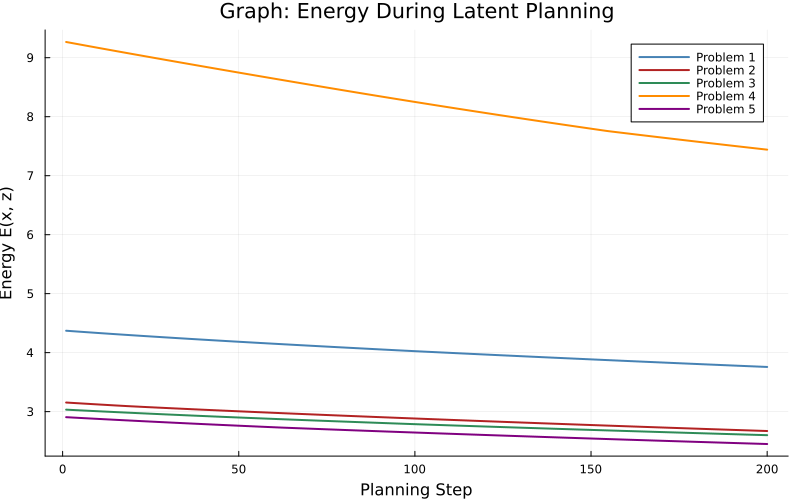
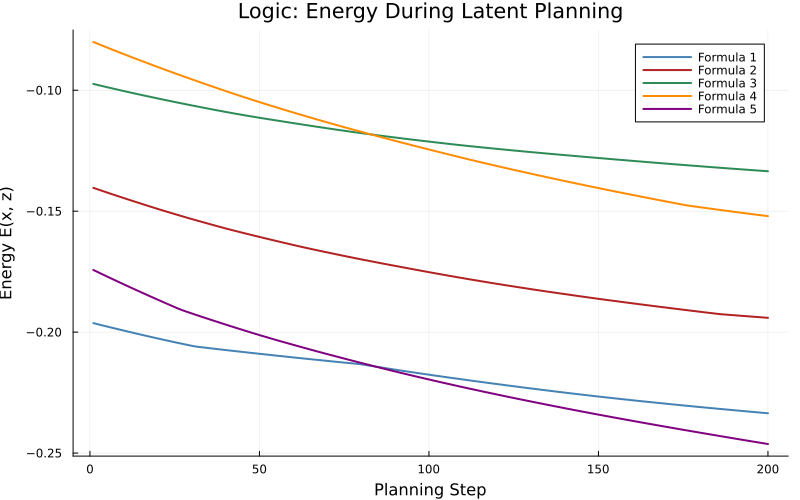
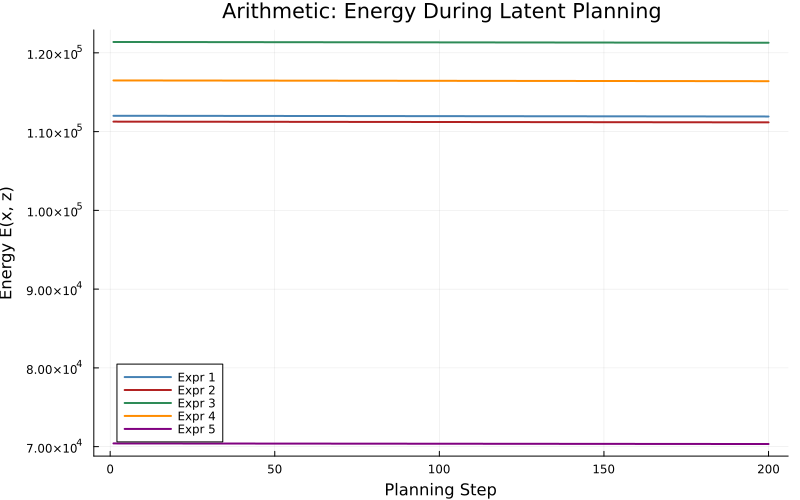
Figure 2: Energy during latent planning. Graph and logic tasks show consistent energy decrease, arithmetic shows negligible descent.
Trajectory Geometry:
PCA projections reveal task-dependent trajectory patterns. Graph trajectories diversify from a shared start, while logic trajectories converge to a terminal cluster—suggesting the presence of spurious attractors unrelated to solution quality.
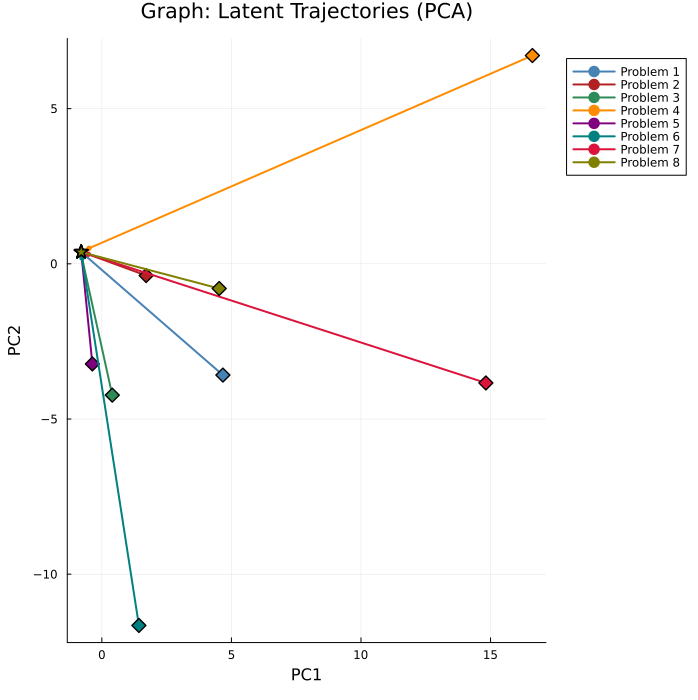
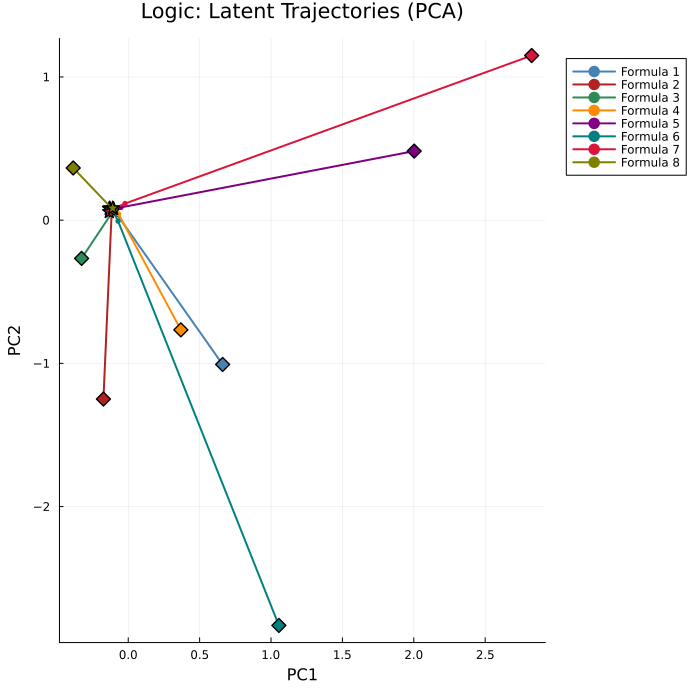
Figure 3: Latent trajectories in PCA space. Graph: diverging trajectories; Logic: convergence to a shared cluster.
Energy Landscapes:
The learned energy surfaces are smooth and directional in graph tasks, structured with clear basins in logic, and essentially flat for arithmetic.
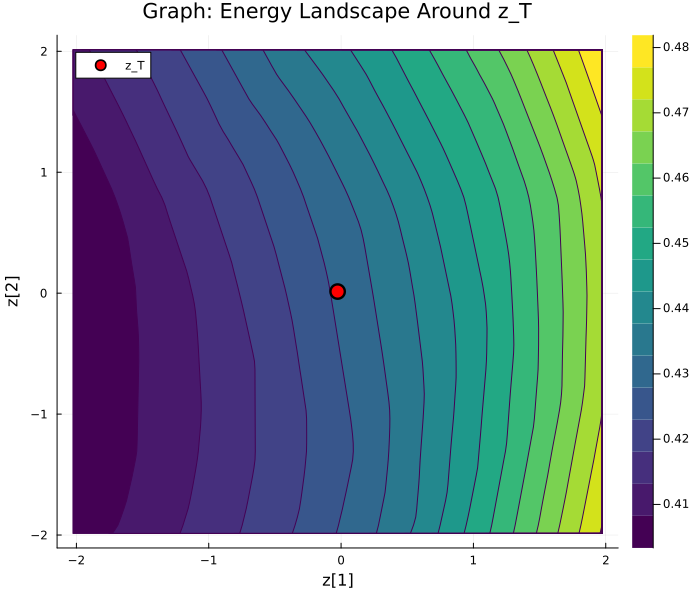
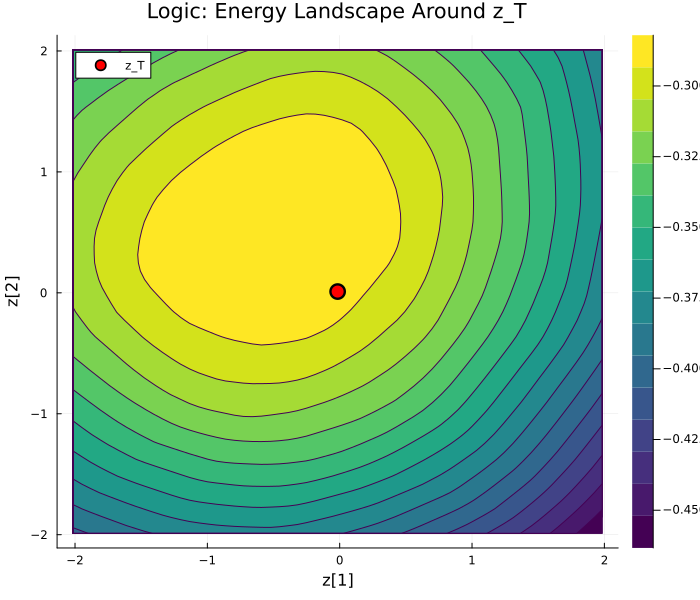
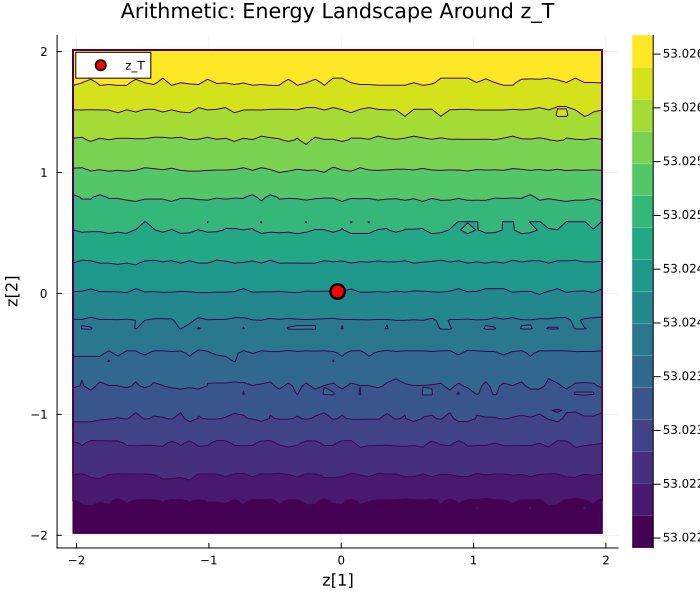
Figure 4: Energy landscapes around E(hx,z)4. Graph: smooth gradients; Logic: distinct basin; Arithmetic: flat landscape.
Failure Mode Analysis
The primary cause of performance degradation is encoder-decoder distribution mismatch: the planner moves E(hx,z)5 into regions unseen during decoder training. Per-step decoding and latent drift tracking confirm that SAT% is maximal at initialization (E(hx,z)6) and decreases as trajectories progress.
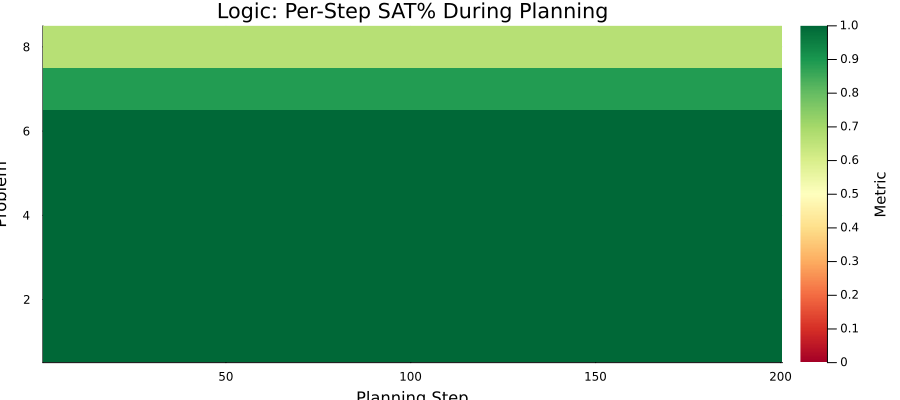
Figure 5: Logic: per-step SAT% during planning. SAT% is highest at step 1 and degrades, confirming spurious attractor presence.
The energy model is not aligned to decoded output quality, as demonstrated by weak energy-solution correlations and monotonic energy descent without improvement in SAT%.
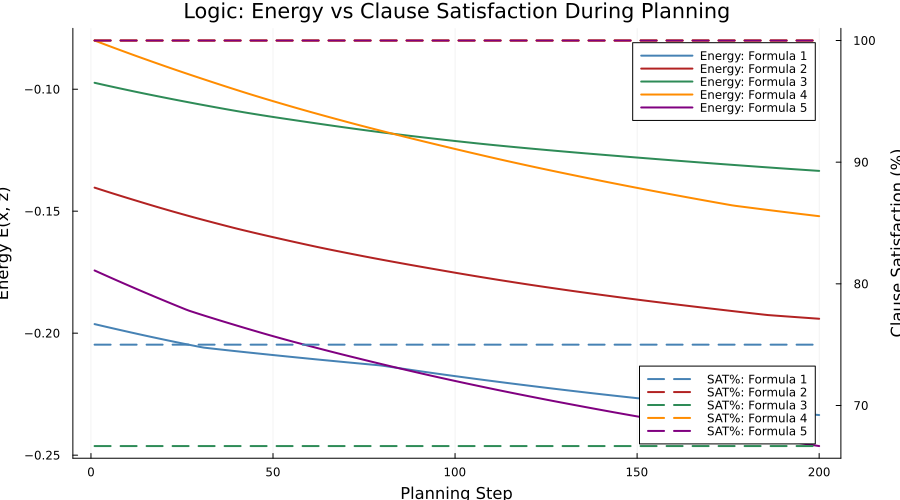
Figure 6: Logic: energy vs clause satisfaction during planning. Energy decreases, but SAT% remains flat.
For arithmetic, final energy scores are nearly uncorrelated with prediction error (E(hx,z)7), highlighting a documented negative result: the energy model does not induce meaningful gradients for arithmetic reasoning.
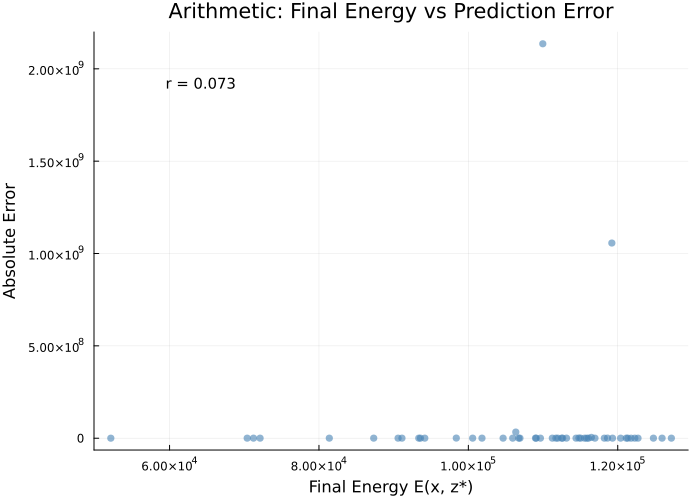
Figure 7: Arithmetic: final energy vs prediction error (E(hx,z)8). Energy fails to predict answer quality.
Ablation Studies and Architectural Remedies
Six ablation protocols systematically investigate component contributions, trajectory length, planner dynamics (step count, learning rates, Langevin noise), initialization strategies, decoder training distributions, and anchor weights. Core findings:
- Removing planning restores direct decoder accuracy in logic.
- Increasing trajectory length or planner steps increases distribution drift and degrades logic performance.
- Dual-path decoder training and latent anchoring constrain drift, directly closing the distribution gap.
- Larger anchor weights trade off planner exploration for decoder compatibility, improving performance within bounds.
Latent Dynamics and Gradient Analysis
Per-step decoding and PCA metrics visualize latent drift: encoder outputs cluster in high-SAT regions, planner endpoints migrate to low-SAT clusters. Gradient decomposition shows step scorer dominance early on, with smoothness growing near terminal attractors.
Limitations
Methodologically, EBRM faces energy-decoder misalignment, inference-time latent distribution shift, scalability constraints, and initialization sensitivity. Experimental limitations include reliance on synthetic data, MLP-only architectures, small-task configurations, and insufficient seed variance analysis. The generalization of EBRM to natural language or real-world reasoning remains untested.
Implications and Future Directions
EBRM presents a principled mechanism for continuous, progress-aware latent reasoning. The distribution mismatch uncovered in logical reasoning tasks underscores the necessity for decoder-aware planning and joint optimization of energy landscapes and output decoders. Practical implications include the potential for reasoning systems with built-in error metrics, but deployment in real-world settings requires robust mitigation of latent drift and deeper energy–answer coupling.
Theoretically, the documented negative results in arithmetic reasoning suggest energy-based methods may be task-sensitive. The extension of EBRM to modular compositional tasks, flexible-length trajectories, or transformer-based encoders and decoders is a compelling direction. Further, the integration of learned stopping criteria and decoder-driven negative sampling could enhance the method’s reliability.
Conclusion
EBRM models reasoning as energy minimization along structured latent trajectories, introducing decomposable energy functions, gradient-based planners, and targeted training procedures. The main empirical finding is that latent planning can degrade performance when the decoder is not aligned to the planner’s output distribution, particularly in logic satisfaction tasks. Dual-path decoder training and latent anchoring are promising remedies, but deeper coupling between energy function and solution quality is required. The analysis provides actionable diagnostic tools and ablation designs, supporting future work on scaling EBRM to more complex, real-world reasoning tasks.