Think Consistently, Reason Efficiently: Energy-Based Calibration for Implicit Chain-of-Thought
(2511.07124v1)
Published 10 Nov 2025 in cs.CL, cs.AI, and cs.LG
Abstract: LLMs have demonstrated strong reasoning capabilities through \emph{Chain-of-Thought} (CoT) prompting, which enables step-by-step intermediate reasoning. However, explicit CoT methods rely on discrete token-level reasoning processes that are prone to error propagation and limited by vocabulary expressiveness, often resulting in rigid and inconsistent reasoning trajectories. Recent research has explored implicit or continuous reasoning in latent spaces, allowing models to perform internal reasoning before generating explicit output. Although such approaches alleviate some limitations of discrete CoT, they generally lack explicit mechanisms to enforce consistency among reasoning steps, leading to divergent reasoning paths and unstable outcomes. To address this issue, we propose EBM-CoT, an Energy-Based Chain-of-Thought Calibration framework that refines latent thought representations through an energy-based model (EBM). Our method dynamically adjusts latent reasoning trajectories toward lower-energy, high-consistency regions in the embedding space, improving both reasoning accuracy and consistency without modifying the base LLM. Extensive experiments across mathematical, commonsense, and symbolic reasoning benchmarks demonstrate that the proposed framework significantly enhances the consistency and efficiency of multi-step reasoning in LLMs.
Sponsor
Organize your preprints, BibTeX, and PDFs with Paperpile.
The paper introduces EBM-CoT, a novel approach that calibrates latent thought embeddings with an energy-based model to improve reasoning consistency in LLMs.
It employs Langevin dynamics to refine latent representations, achieving high single-chain accuracy (72.49%-85.95%) across benchmarks like GSM8K and AQuA.
The method is modular and computationally efficient, enabling scalable, resource-constrained inference without modifying base model parameters.
Energy-Based Calibration for Implicit Chain-of-Thought Reasoning in LLMs
Introduction and Motivation
This paper presents a formal approach to enhancing multi-step reasoning abilities in LLMs using an implicit energy-based calibration strategy for Chain-of-Thought (CoT) inference. Traditional explicit CoT relies on discrete token-level mechanisms which propagate local errors, induce rigidity, and suffer from vocabulary-based limitations. Recent implicit CoT solutions, operating in continuous latent spaces, address representational issues but lack explicit global consistency, leading to divergent and unstable reasoning trajectories. The authors propose EBM-CoT, formulating a hierarchical pipeline where latent thought embeddings are dynamically calibrated by a learned Energy-Based Model (EBM) before answer generation, increasing both reasoning accuracy and consistency without any modification of base LLM parameters.
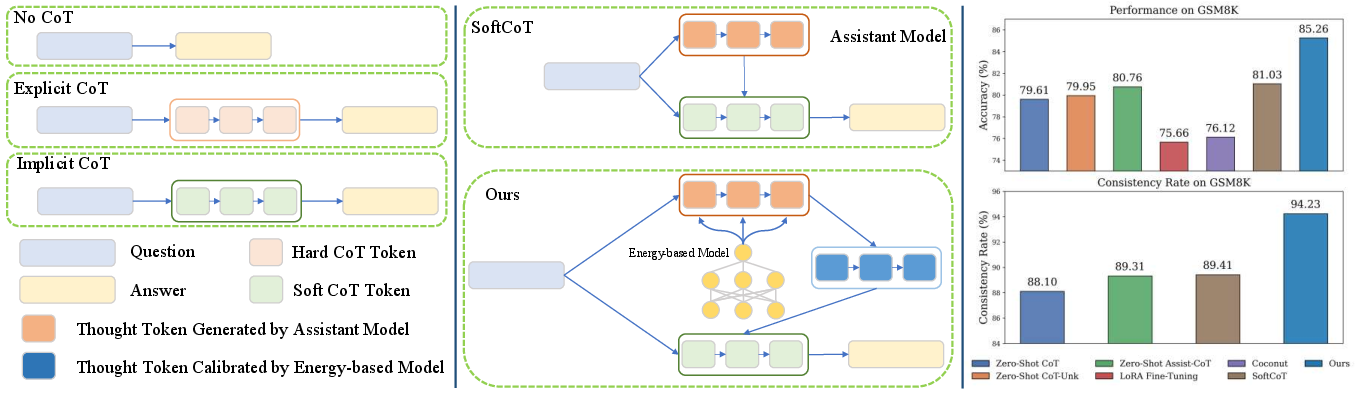
Figure 1: Reasoning paradigms (No CoT, Explicit CoT, Implicit CoT) are compared; energy-based calibration of latent thoughts improves coherence and consistency, with the proposed method demonstrating superior accuracy and consistency versus prior CoT variants on GSM8K.
Architecture and Theoretical Foundations
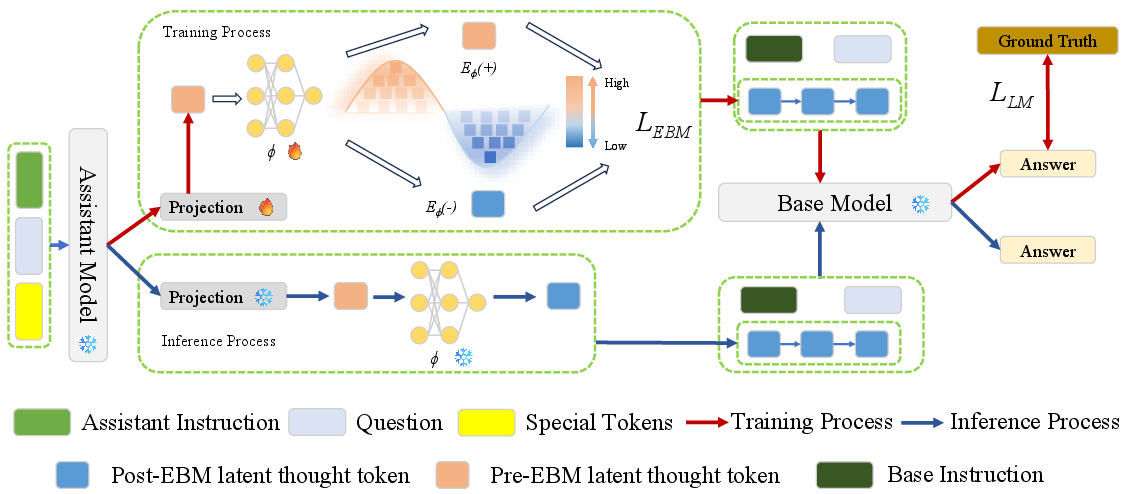
The EBM-CoT architecture hierarchically decomposes the reasoning pipeline into three stages:
Thinking: An assistant LLM produces latent thought embeddings L={l1,…,ln}.
Reasoning: The base LLM utilizes these latent thoughts to generate explicit reasoning steps R.
Answer Generation: The base LLM synthesizes the reasoning trajectory to yield the final answer A.
Calibration is performed in the latent space using an EBM, defined by a scalar energy function Eϕ(l). During both training and inference, Langevin dynamics refines the thought embeddings by moving them toward lower-energy (high-consistency) regions, as:
l(s+1)=l(s)−η∇lEϕ(c,l(s))+2ηε(s),ε(s)∼N(0,I)
where c is the autoregressive context and η is the step size.
Figure 2: The EBM-CoT pipeline, where the assistant generates latent thoughts, these are projected and calibrated via an EBM, and the base model subsequently generates explicit reasoning and answers.
The optimization routine consists of a language modeling loss LLM, an EBM hinge-style contrastive loss Lh (distinguishing lower and higher-energy latent samples), and a consistency regularizationLc, jointly optimized by:
Ltotal=LLM+αLEBM,LEBM=Lh+Lc
Here, α controls the trade-off between calibrating latent trajectories and surface-level token likelihood.
Experimental Results
The framework is evaluated on diverse reasoning benchmarks—GSM8K, ASDiv-Aug, AQuA, StrategyQA, and Date Understanding—using various model configurations (Qwen2.5-7B, Qwen3-8B, LLaMA-3.1-8B, with smaller-scale assistants). The key findings are:
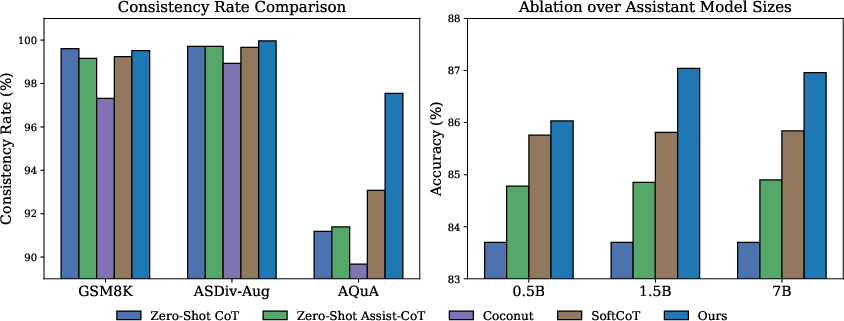
On LLaMA-3.1-8B (single chain, N=1), the method achieves 72.49% average accuracy, closely matching multi-chain (N=10) performance, in contrast to prior methods (SoftCoT, Coconut), where performance drops sharply for N=1. This demonstrates robust single-pass consistency.
On Qwen3-8B, EBM-CoT consistently outperforms all baselines, exceeding SoftCoT (+2.1%) and achieving 85.95% accuracy with self-consistency sampling.
Consistency rates are substantially improved across GSM8K, ASDiv-Aug, and AQuA; the model approaches near-perfect consistency rates, even when the number of reasoning chains N is minimized.
Figure 3: Left: Consistency rate advantage for EBM-CoT over SoftCoT and baselines on GSM8K, ASDiv-Aug, AQuA; Right: Performance scales favorably with assistant model size, but is robust across model scales.
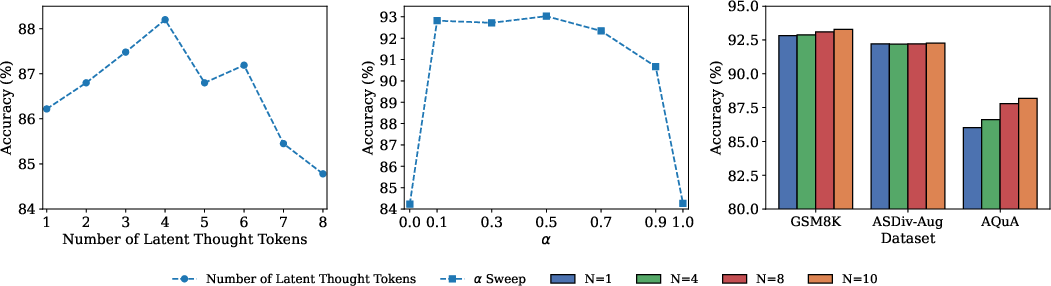
Ablations demonstrate that accuracy improves with additional latent thought tokens up to a threshold, after which optimization becomes unstable. The optimal EBM loss weight α is around 0.5, and high single-chain performance (N=1) is maintained, reducing the need for multi-chain aggregation.
Figure 4: Left: Accuracy saturates as the number of latent tokens increases. Middle: Optimal regularization strength boosts performance; extremes are detrimental. Right: Single reasoning chain (N=1) is sufficient for high accuracy, limiting sampling cost.
Methodological Trade-offs and Scalability
Computational Overhead: Langevin refinement is lightweight (S=3 steps) but may scale unfavorably in extremely large or deep models, or for sequences with numerous tokens.
Expressiveness: The EBM is currently a shallow MLP, which may limit modeling of high-order latent dependencies; extension to hierarchical or structured energy functions is a potential direction.
Deployment: Both base and assistant models remain frozen throughout training and inference, enabling efficient deployment in resource-constrained environments and avoiding catastrophic forgetting associated with full-model fine-tuning.
Implications and Perspectives
The explicit calibration of latent thought trajectories via EBMs provides a principled mechanism for aligning global reasoning consistency in LLMs. The demonstrated improvements in single-chain accuracy and stability, even when compared against multi-chain self-consistency baselines, are strong numerical evidence that latent-space calibration mitigates stochastic deviation and error propagation inherent to both explicit and prior implicit CoT paradigms. The approach is robust across model architectures, scalable in terms of assistant model size, and remains efficient in terms of additional compute.
This framework bridges the theoretical apparatus of energy-based modeling and practical reasoning enhancement, suggesting that further advances may be gained via more expressive energy parameterizations, adaptive Langevin refinements, or integration with preference-optimized reward models. The general principle—the calibration of internal reasoning states along a learned energy landscape—is likely to inform future research across alignment, deliberative reasoning, and model-based control in AI systems.
Conclusion
The energy-based calibration strategy for implicit Chain-of-Thought inference introduced here formalizes the refinement of latent thought embeddings in LLM reasoning pipelines. Empirical results highlight substantial gains in consistency and accuracy, rendering multi-chain sampling largely unnecessary. The method is architecturally modular, computationally efficient, and theoretically grounded, representing a promising advance in the design of robust, efficient reasoning systems in large-scale LLMs. Future work should expand on energy landscape modeling and scalable inference strategies, with potential extensions to general model alignment and controllable reasoning.