- The paper presents a neurosymbolic approach combining embedding models with consistency-driven optimization to extract high-precision API specifications.
- It decomposes the process into transforming documentation into pseudo-logical templates and refining them via logical consistency checks to mitigate neural instability.
- Empirical findings show minimal precision and recall variation under varied temperature settings, highlighting the method’s robustness for static analysis pipelines.
DAInfer+: Neurosymbolic Inference of API Specifications from Documentation via Embedding Models
Introduction
DAInfer+ addresses the automated inference of API aliasing specifications from natural language library documentation, unifying LLM-driven semantic parsing with formal neurosymbolic optimization. Accurate API specification inference is critical for the precision and scalability of downstream static program analyses, including alias/pointer analysis, information flow, and security auditing. However, documentation contains high-entropy, underspecified, and often ambiguous descriptions, challenging existing mining and inference approaches. DAInfer+ leverages a neurosymbolic approach, integrating embedding models with consistency-driven optimization, to infer latent API specifications that are robust and suitable for high-assurance static analyses.
Neurosymbolic Inference Methodology
DAInfer+ formulates API specification inference as a process of joint semantic alignment and constraint optimization. The technique is decomposed into a two-stage pipeline:
- Stage 1: Textual descriptions from documentation are transformed into pseudo-logical specification templates using a neural embedding model. This maps free-form language to a constrained space of specification skeletons.
- Stage 2: Candidate specifications are instantiated and scored via a symbolic consistency oracle, which checks the compatibility of explanations across the corpus and enforces adherence to documented behavioral contracts.
This decouples the fuzziness of neural embedding from the formality of logical specification, improving both precision and robustness compared to purely neural or symbolic baselines.
Temperature Sensitivity and Self-Consistency
DAInfer+ empirically investigates the stability of its LLM-driven components with respect to the sampling temperature parameters t1 and t2 in its dual-stage prompting. Precision and recall exhibit only minor degradation as the temperatures increase across both stages, indicating low sampling stochasticity sensitivity. The ranges of observed precision and recall are tightly bounded: less than 1% and 4.55% absolute variation, respectively.
Incorporating the self-consistency strategy (repetitive LLM queries with majority voting, as advocated in [DBLP:conf/iclr/0002WSLCNCZ23]) at each stage further validates DAInfer+'s insensitivity to temperature, with precision and recall remaining at 79.70/79.86% for (0.7,1.3) and 79.36/80.16% for (1.3,0.7). The results demonstrate that both base and ensemble modes yield congruent performance envelopes; thus, DAInfer+ mitigates the sample inefficiency and instability issues typical of prompt-sensitive LLM-driven pipelines.
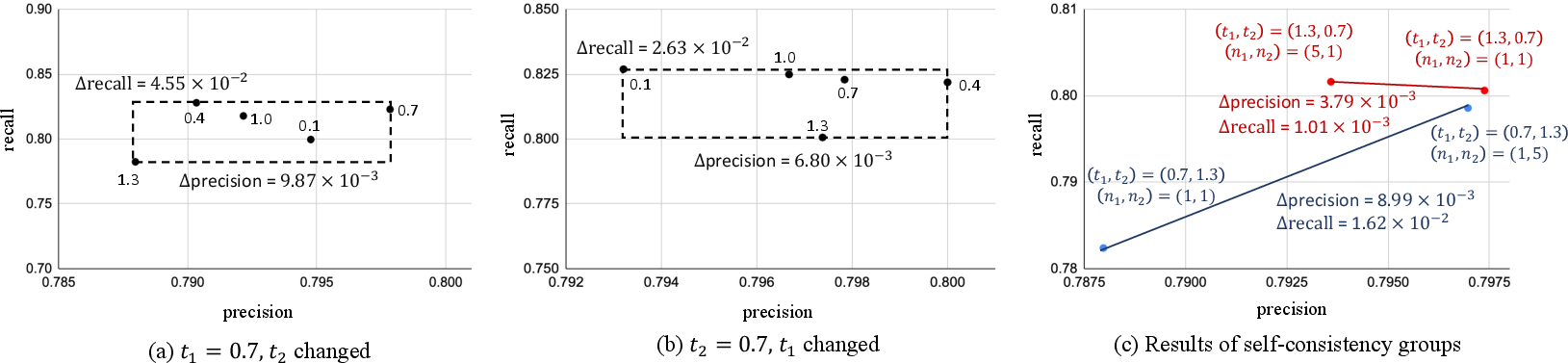
Figure 1: DAInfer+'s precision and recall under various temperature configurations, demonstrating bounded sensitivity and high robustness.
Positioning and Relations to Existing Work
DAInfer+ advances the state of LLM-based code analysis by providing guaranteeable, reusable, and verifiable API specifications inferred from unstructured or semi-structured documentation. Previous systems (e.g., DocFlow [docflow], LLMDFA [LLMDFA10.5555/3737916.3742097], APIGen [APIGen], method name recommendation [methodNameRecommendation1]) have shown LLMs or neural models can support code intent extraction or API mining, but often lack formal guarantees or are brittle to prompt parameterization and context selection. DAInfer+'s neurosymbolic framework provides a robust semantic bottleneck and enables validation against aggregate knowledge and consistency checks, minimizing hallucination and non-deterministic failures—an open problem in LLM-powered code analysis [usenixCodeAnalysisLLM, codeintentwithllm, fuse-documentation, binarytaint10.1145/3711816].
The temperature-sensitivity result (see Figure 1) distinguishes DAInfer+ from LLM-driven approaches that have problematic prompt instability, suggesting the design is amenable to scalable batched inference and integration into static analysis pipelines without introducing stochastic specification drift.
Implications and Future Directions
Practically, DAInfer+ enables the derivation of alias-aware, high-precision specifications for complex APIs, which are prerequisite artifacts for advanced static analysis tools (e.g., flow- and context-sensitive value-flow, pointer, and taint analyses). This facilitates automation of traditionally manual or error-prone specification engineering, especially in fast-evolving or poorly-documented libraries and frameworks, and can also be extended to concurrent, framework-based, or cross-language APIs.
Theoretically, this neurosymbolic approach demonstrates that LLM-generated candidate specifications can be rendered robust and verifiable under formal consistency oracles, potentially leading toward a new class of LLM-guided, verifiable program analysis pipelines. Future work should generalize self-consistency strategies to other static analysis tasks (precondition inference, loop invariant generation, typestate discovery) and explore cross-modal joint inference (code, documentation, usage, and test synthesis interplay).
Conclusion
DAInfer+ provides a neurosymbolic architecture for extracting robust, alias-aware API specifications from natural language documentation using LLM-based embedding, with minimally temperature-sensitive, self-consistent performance. By integrating neural semantic extraction with logical consistency constraints, DAInfer+ offers a scalable and automatable solution for specification mining, addressing both the spectrum of neural instability and symbolic brittleness inherent in prior work. The observed empirical bounds on performance under stochastic sampling reinforce its applicability in industrial-strength code analysis and its foundational relevance for future AI-augmented static analysis systems.