- The paper introduces a novel hybrid architecture that combines Transformer attention with Mamba-based SSMs to enhance performance and computational efficiency.
- It employs flexible channel allocation and advanced hyperparameter tuning to optimize inference speed and memory usage.
- The models achieve state-of-the-art results on benchmarks in reasoning, mathematics, and multilingual understanding through efficient pretraining strategies.
Overview
The Falcon-H1 series introduces an innovative hybrid architecture combining the strengths of Transformer-based attention mechanisms and Mamba-based State Space Models (SSMs). This architectural design is optimized for performance and computational efficiency across various use cases. The models offer flexible configurations, including base and instruction-tuned models at different parameter scales—ranging from 0.5B to 34B—with quantized versions available. The series demonstrates notable performance benchmarks, with the flagship Falcon-H1-34B-Instruct model competing with larger models despite using fewer parameters and less training data.
Architecture
The Falcon-H1 architecture adopts a parallel hybrid design where attention and SSM mechanisms run concurrently, allowing optimal adjustment of attention and SSM channels within each block. This contrasts with classical sequential architectures, enhancing inference speed and memory efficiency.
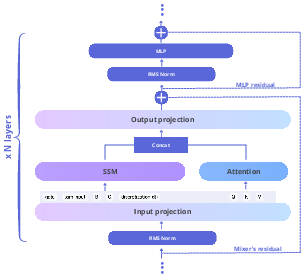
Figure 1: Falcon-H1 architecture. Attention and SSM run in parallel within each block; their outputs are concatenated before the block’s output projection. The number of SSM/Attention heads can be flexibly tuned.
Channel Allocation
Channel allocation in Falcon-H1 is a critical aspect, providing flexibility in varying the number of attention and SSM channels independently. Different strategies of allocation were tested, leading to the optimal semi-parallel block configuration (SA_M).
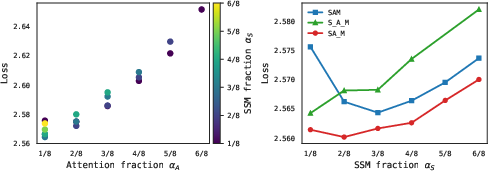
Figure 2: (Left): The loss of fully parallel SAM hybrid block configuration for all possible (\alpha_S,\alpha_A,\alpha_M) channel allocations.
SSM-Specific Parameters Ablations
Various hyperparameters within the Mamba2 architecture, such as head dimension, state size, and convolution kernel size, were meticulously evaluated to determine their effects on performance. Larger head dimensions and optimal convolution sizes showed significant efficiency improvements.
RoPE Base Frequency and Width-Depth Trade-offs
The use of a large RoPE base frequency (b=1011) significantly improves performance during long-sequence training. Moreover, deeper architectures in the Falcon-H1 series demonstrate superior accuracy compared to wider configurations at similar parameter counts, underscoring the importance of depth for complex reasoning tasks.
Pretraining Strategy
Falcon-H1 models are pretrained using carefully curated and high-quality datasets, with a data mixture that emphasizes knowledge density over volume. The data sources include multilingual corpora, code, mathematical datasets, and synthetic data, strategically organized to optimize training efficacy.
Data Sources
The pretraining corpus encompasses diverse sources spanning web data, curated databases, mathematical datasets, and synthetic data strategically generated to complement model capabilities across different tasks and languages.
Training Dynamics
Falcon-H1 series benefits from several innovations in training dynamics, including maximal update parametrization (μP), batch scaling, and learning rate strategies like the Effective Power Scheduler (EPS), ensuring optimal training trajectories and parameter efficiency.
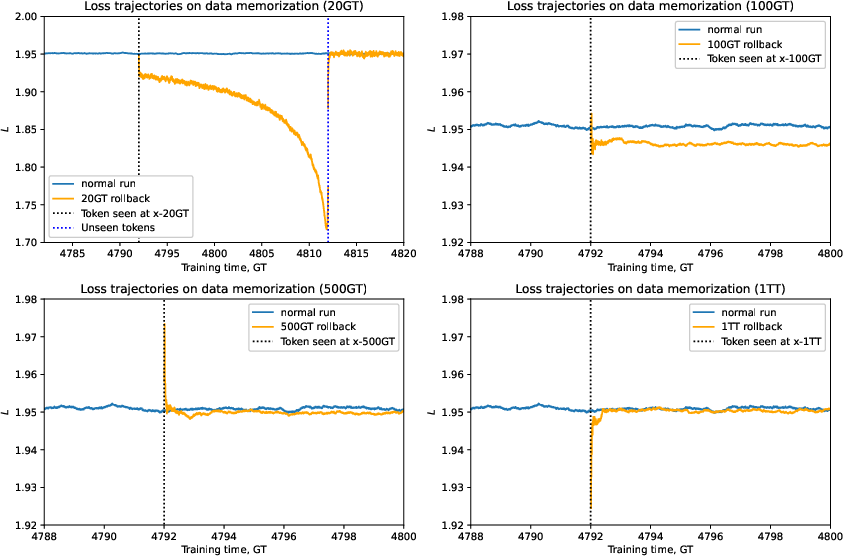
Figure 3: Model's memorization window and loss trajectories.
Evaluation
Falcon-H1 models are evaluated across a suite of benchmarks in various domains such as general knowledge, mathematics, science, code generation, and multilingual understanding, consistently demonstrating state-of-the-art performance. The models excel particularly in reasoning-intensive tasks, confirming their architectural and training advantages.
Deployment Strategies
Falcon-H1 models are integrated into key AI frameworks, including vLLM and Hugging Face Transformers, facilitating seamless adoption in diverse applications. The architecture’s efficiency is showcased in long-context scenarios, with significant throughput improvements over traditional models.
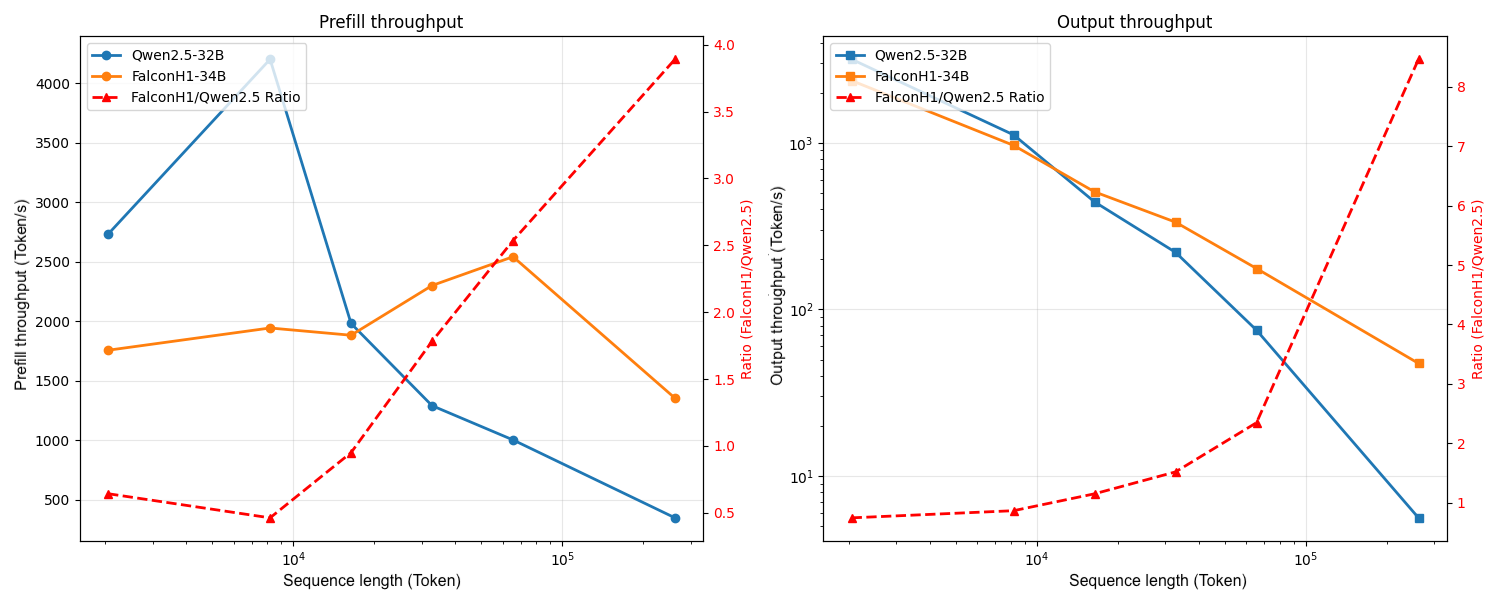
Figure 4: Model efficiency comparison between Falcon-H1-34B and Qwen2.5-32B.
Conclusion
The Falcon-H1 series represents a significant advancement in hybrid-head LLM design, achieving high efficiency and leading performance metrics with reduced computational resources. The models' adaptability across various scales and tasks positions them as versatile solutions for challenging AI applications. Therefore, Falcon-H1 effectively balances model complexity and learning efficiency, presenting a robust option for deploying high-performance AI systems with practical relevance.