- The paper introduces CPA, a framework that reframes conditional coverage evaluation as a supervised learning task to accurately audit model reliability in heterogeneous data.
- It establishes theoretical guarantees for the Conditional Validity Index (CVI) and uses extensive simulations to demonstrate high-fidelity recovery of local reliability patterns.
- The framework provides actionable diagnostics, including the Conditional Validity Profile curve, to distinguish undercoverage risks from overcoverage inefficiencies for model selection.
Introduction and Motivation
Conformal prediction (CP) is the leading model-agnostic approach for uncertainty quantification in prediction tasks, granting finite-sample, distribution-free marginal coverage guarantees under exchangeability. However, marginal coverage only ensures validity on average over the population, and empirical evidence demonstrates that CP can suffer severe conditional coverage failures, particularly for underrepresented subpopulations or in the presence of heteroscedasticity and model misspecification. The fundamental impossibility of finite-sample conditional coverage necessitates robust, scalable frameworks for auditing and comparing conditional coverage properties of conformal methods.
This paper introduces Conformal Prediction Assessment (CPA), a unified framework for granular auditing of CP methods’ conditional coverage properties (2603.27189). CPA reframes the conditional validity assessment as a supervised learning task, enabling high-resolution analysis of coverage variation across the feature space via a reliability estimator. CPA provides both theoretical guarantees and empirical protocols for assessing, visualizing, and selecting uncertainty quantification procedures with proven conditional calibration.
Theoretical Foundations: Conditional Coverage and Its Limits
Marginal coverage does not imply conditional validity except under stringent assumptions. Even asymptotically, the limiting conditional coverage function η(x) can systematically deviate from the target 1−α under model misspecification or unmodeled heteroscedasticity, as visualized in the synthetic experiments:
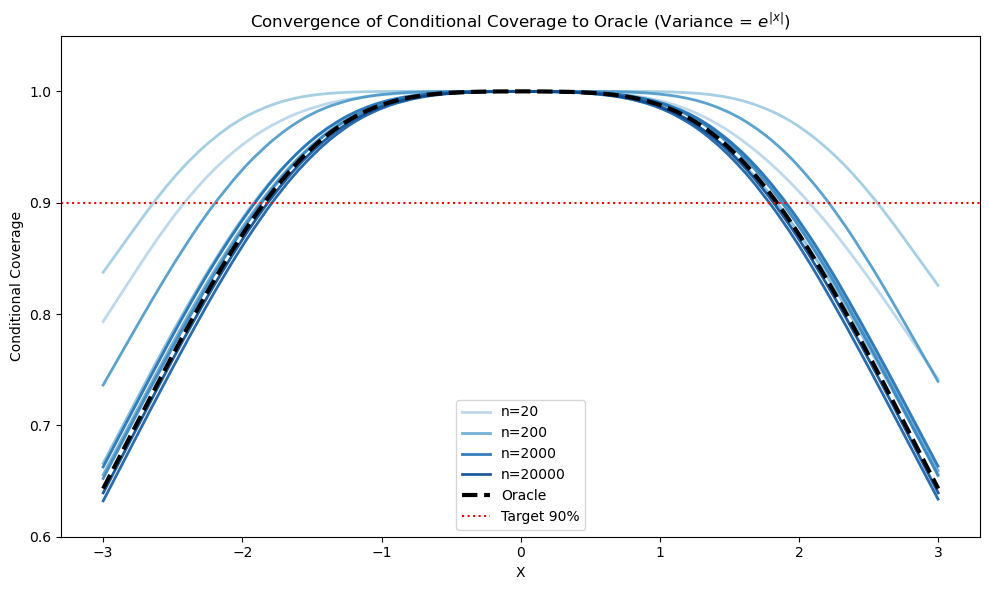
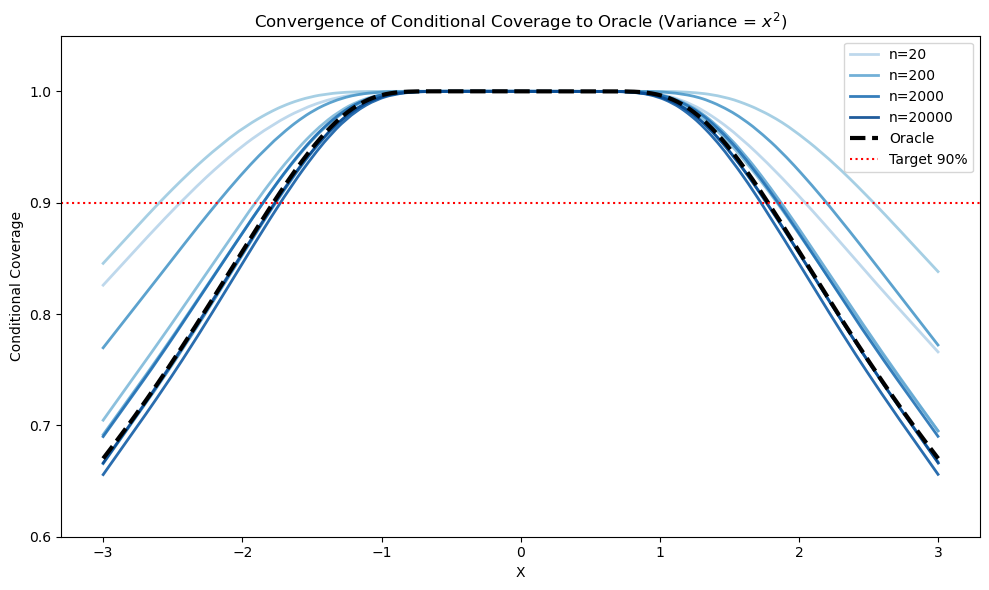
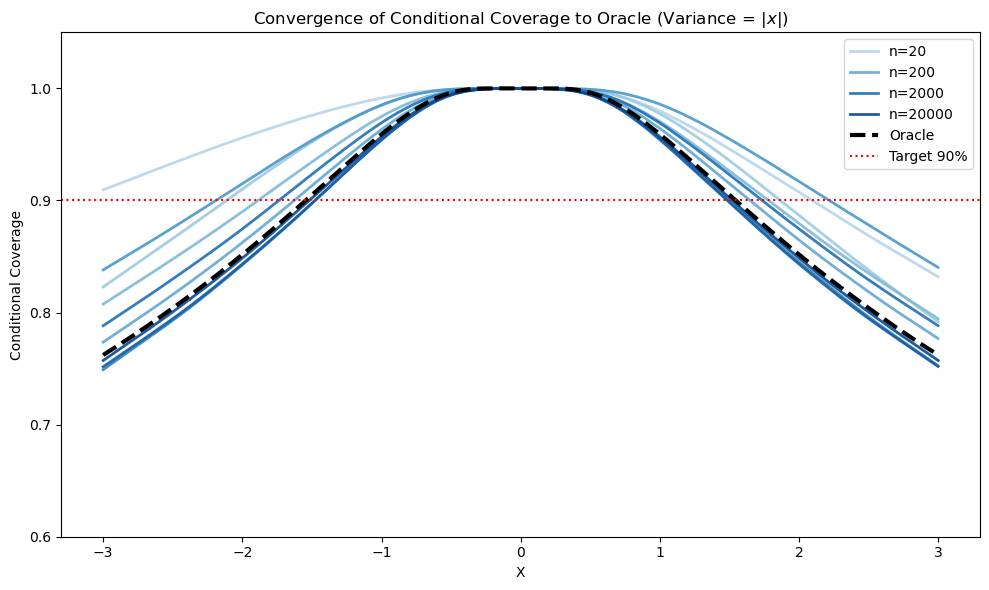
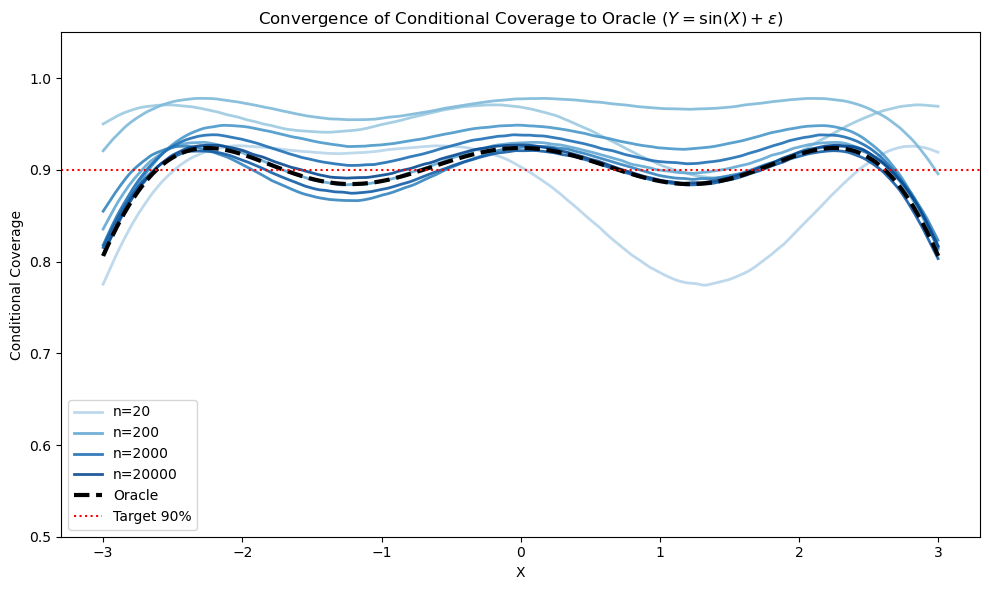
Figure 2: Linear model misspecification and noise heteroscedasticity produce non-uniform limiting conditional coverage η(x), illustrating misalignment with the nominal 1−α even as sample size increases.
CPA addresses this by defining the finite-sample conditional coverage function ηn(x) for a given CP procedure and dataset and framing its estimation as a probabilistic classification problem. Theoretical analysis establishes explicit convergence rates for both the reliability estimator and its aggregate metric, the Conditional Validity Index (CVI), under mild regularity and model stability assumptions. The CVI is shown to be a consistent estimator of true conditional miscalibration. Furthermore, CPA provides guarantees for CC-Select, a selection protocol to identify the uncertainty quantification method with optimal conditional validity.
CPA Methodology: Learning and Auditing Reliability
CPA employs a systematic pipeline:
- Split the data into predictor training and reliability evaluation sets.
- Train the CP procedure on the training set.
- For each evaluation sample, obtain the binary coverage indicator and learn a reliability estimator η^(x) using any high-capacity probabilistic classifier, with post-hoc calibration (isotonic regression).
The output η^(x) serves as a high-resolution proxy for the instance-level coverage probability, allowing fine-grained analysis of reliability patterns and failure modes. This enables CPA to circumvent the curse of dimensionality inherent in traditional stratified analysis.
CPA introduces the Conditional Validity Index (CVI) as the mean absolute deviation of local reliability from the target level and further decomposes it into safety (undercoverage risk) and efficiency (overcoverage cost) components. This provides actionable diagnostics, distinguishing dangerous undercoverage from mere inefficiency. To complement scalar metrics, CPA also introduces the Conditional Validity Profile (CVP) curve, which visualizes the entire distribution of conditional coverage estimates, identifying both systematic and tail failure modes:
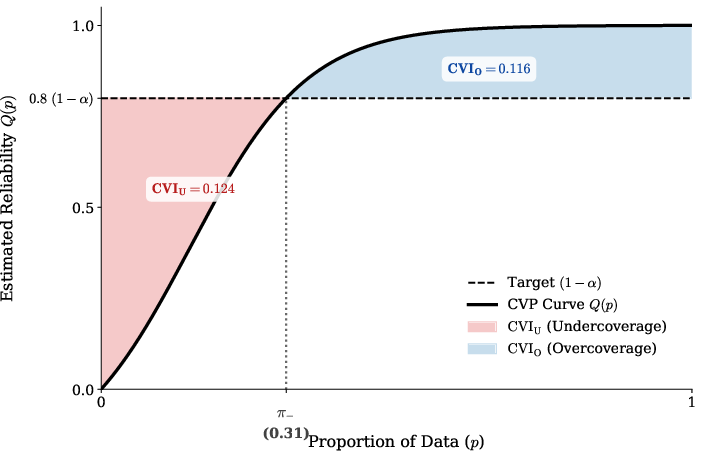
Figure 1: The Conditional Validity Profile (CVP) curve reveals how much of the population lies below, at, or above the target coverage, and quantifies aggregate undercoverage risk and overcoverage cost.
Empirical Validation: Simulation Studies
Comprehensive simulation studies across settings—covering linear, nonlinear, heteroscedastic, and heavy-tailed regimes—demonstrate that CPA reliably recovers the ground-truth conditional validity landscape. Distributional matching between the estimated CVP and the oracle confirms high-fidelity recovery of coverage heterogeneity, while the Wasserstein Distance quantifies tight approximation between estimated and true reliability distributions:
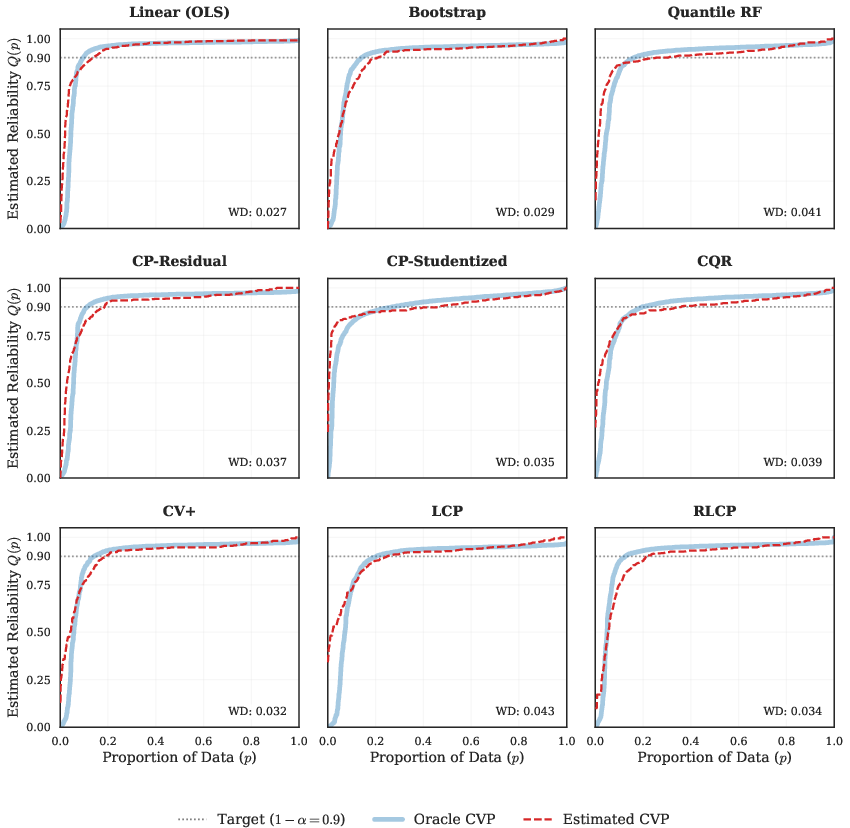
Figure 3: The CPA-estimated CVP (red dashed) closely matches the oracle (blue) in heavy-tailed nonlinear settings, validating the ability of CPA to recover distributional failure structure.
Crucially, robust performance is preserved under a wide array of reliability estimator perturbations, provided sufficient model capacity, with selection utility being largely maintained even under moderate calibration misspecification or estimator simplicity:
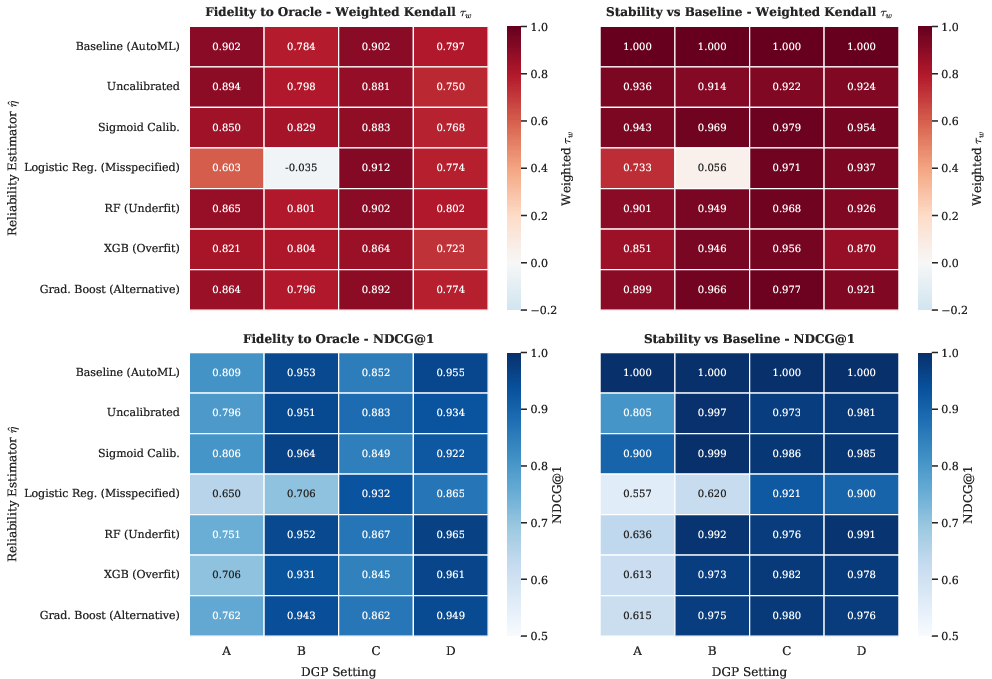
Figure 4: Heatmaps of ranking fidelity and metric stability across reliability estimator variants and data-generating processes: only severe underfitting (e.g., linear classifier in nonlinear setting) degrades selection utility.
Empirical analysis demonstrates that an approximately even data split (ρ=0.5) between prediction and reliability subsets optimally balances approximation and estimation error, with consistent reliable selection achieved with at least 800 samples for regression in moderate dimensions.
Real-World Evidence: Datasets and Diagnostic Utility
CPA was benchmarked on nine diverse real regression datasets covering health, transportation, finance, and chemistry. Reliability diagrams for the ensemble estimator demonstrate consistently low expected calibration error (ECE <0.01 is typical), confirming its use as a practical proxy for true conditional coverage:
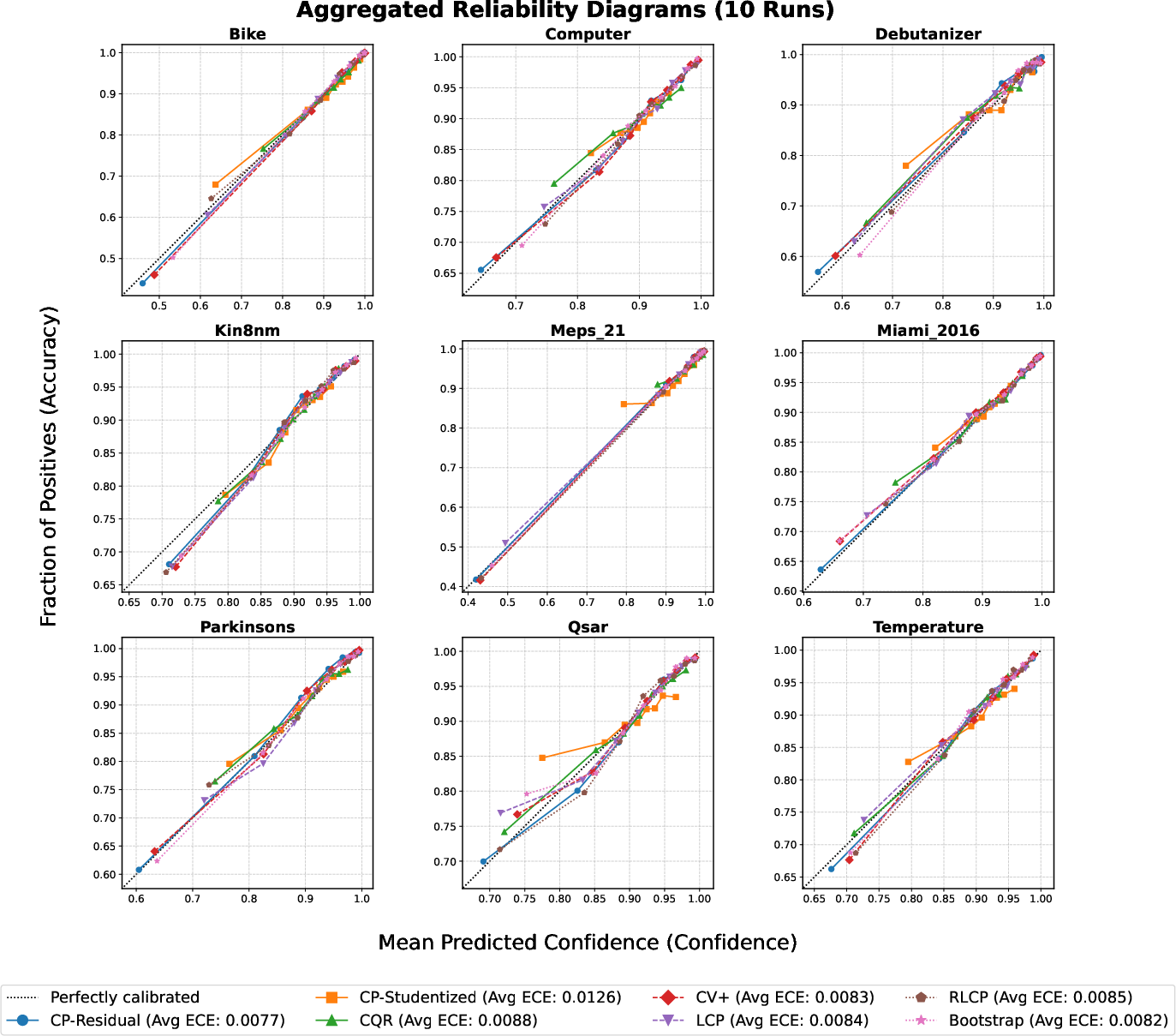
Figure 5: Empirical coverage nearly perfectly matches predicted reliability across all datasets, validating the practical deployment of η^(x) as a trustworthy audit signal.
Selection experiments show that the CC-Select algorithm, guided by CVI, consistently identifies procedures with superior worst-case slab coverage (WSC) properties, outperforming alternative selection protocols that target only marginal metrics. Notably, on challenging datasets, the disparity between methods can be extreme, justifying the necessity of robust auditing:
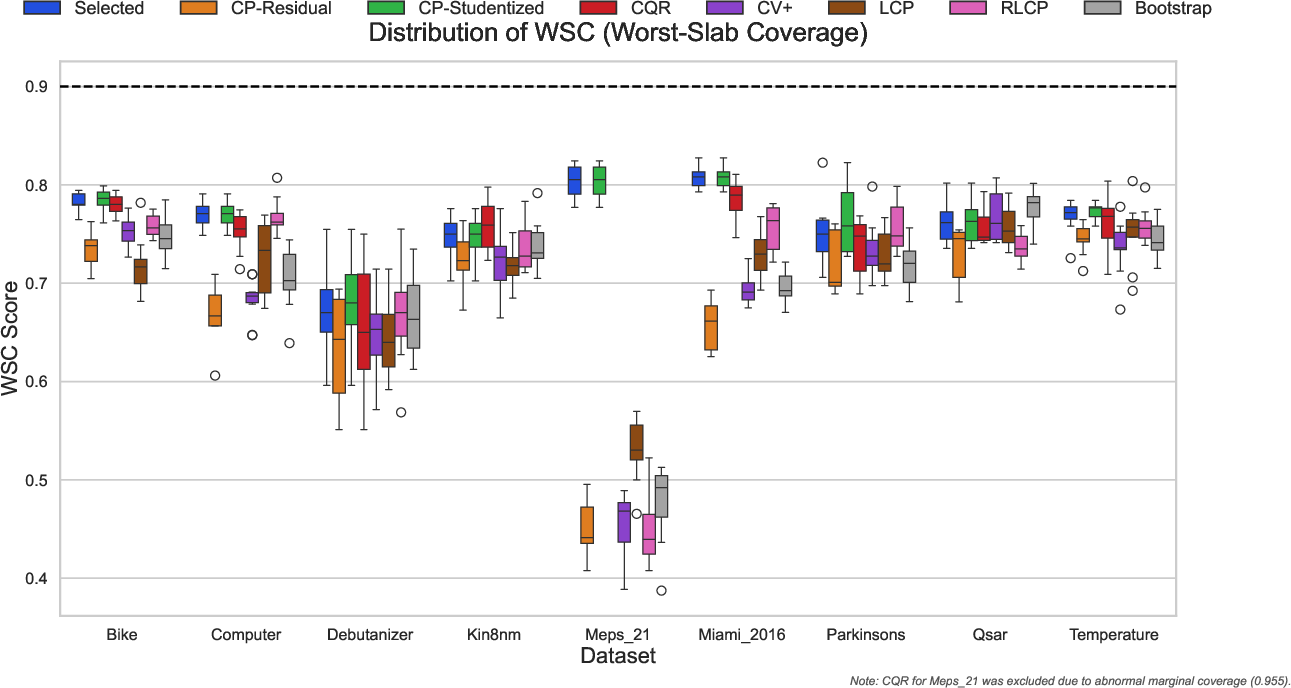
Figure 6: CC-Select (blue) consistently selects procedures with high worst-slab coverage, minimizing conditional failures not visible in marginal metrics.
CPA also enables covariate-specific diagnosis. On the Bike Sharing dataset, CPA reveals undercoverage of residual-based CP methods during rush hours and extreme temperatures—localized reliability error invisible to global coverage metrics, but critical for operational safety:
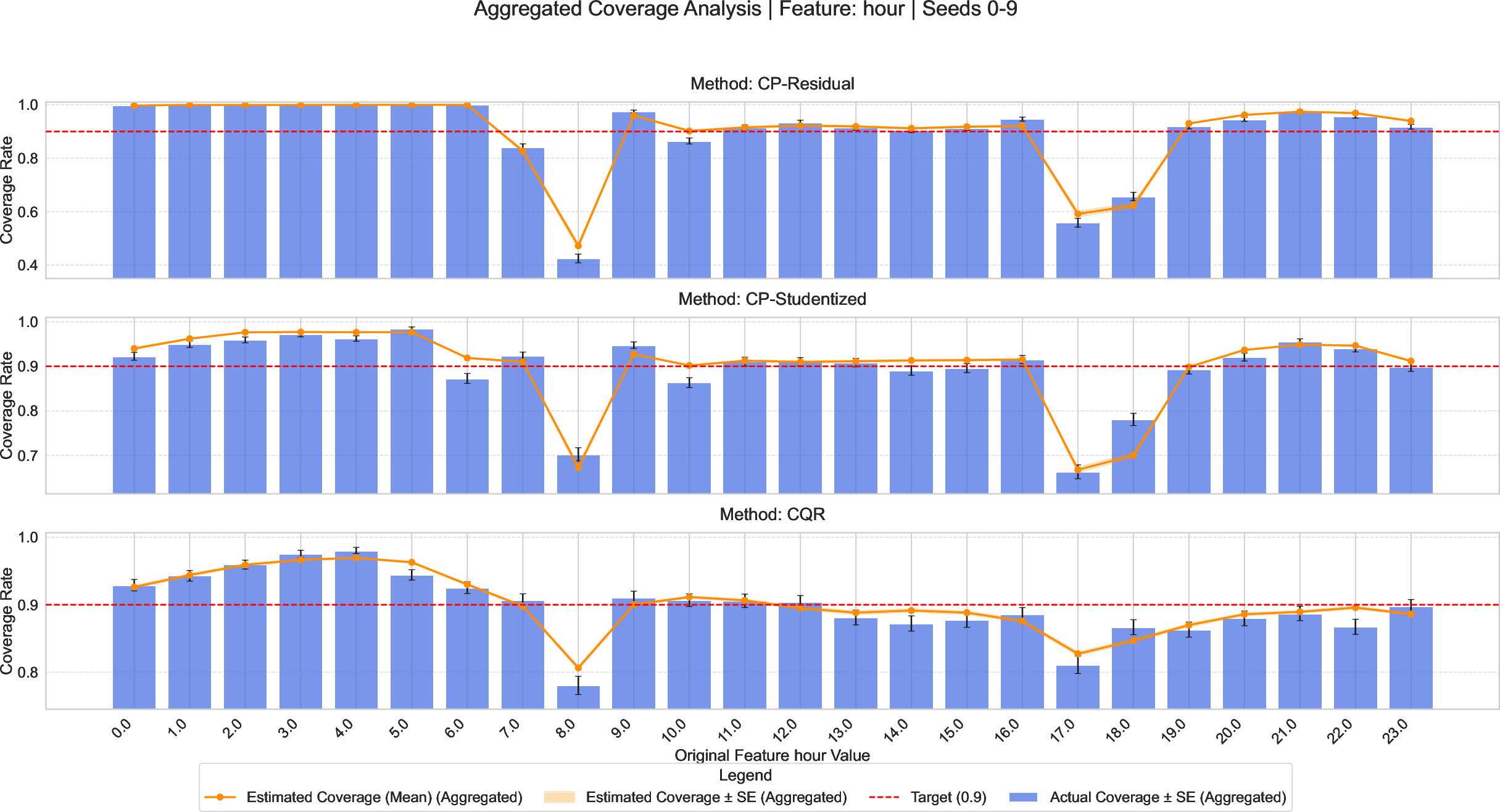
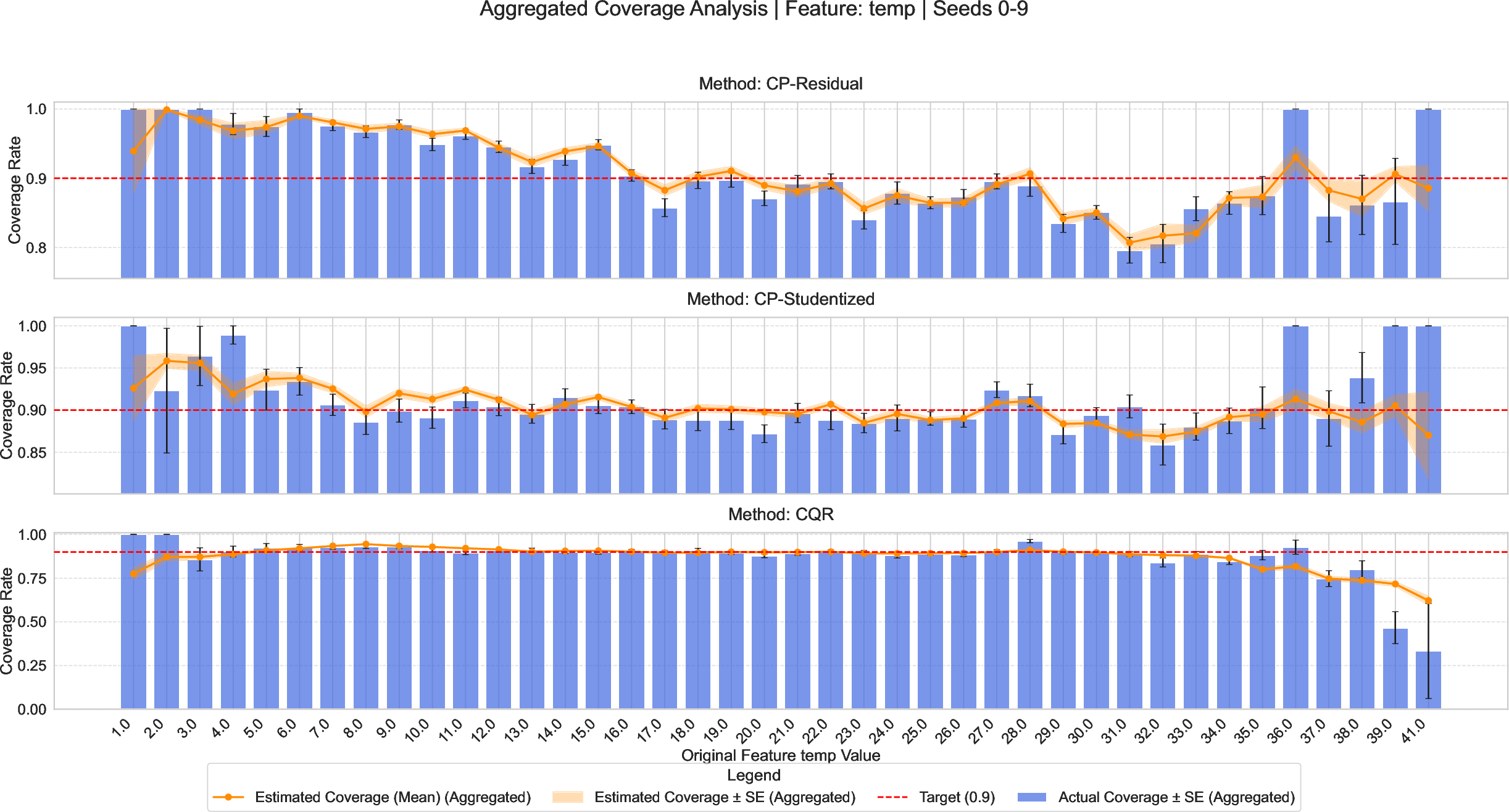
Figure 7: Univariate reliability analysis uncovers elevated undercoverage of residual-based CP during rush hour and temperature extremes, implications concealed by aggregate assessment.
Practical Considerations and Recommendations
- Estimator choice: Use robust, high-capacity classifiers (e.g., AutoML pipelines + isotonic calibration) for the reliability estimator. Sufficient capacity is necessary to avoid masking nonlinearity-induced undercoverage.
- Data split: Empirical analysis suggests a 50/50 split between training and evaluation optimally manages trade-offs in most settings; smaller splits for simple low-SNR regimes.
- Sample complexity: Reliable estimation and discrimination between methods require at least 400-800 evaluation samples, higher in high dimensions.
Implications and Future Directions
CPA formalizes the practice of conditional coverage auditing and model selection, enabling robust uncertainty quantification in safety-critical applications such as medicine, finance, and autonomous systems. The framework’s modularity admits extension to classification, censored data, and online environments. The reliable estimation of instance-wise conditional coverage invites the development of defensive deployment strategies, hybridized model-guard rails, and fair auditing protocols—potentially informing active retraining or dynamic model adaptation for covariate shift. Future work may further integrate CPA with local calibration adaptation, group fairness mandates, and multi-objective efficiency-validity trade-offs, moving toward truly granular, actionable uncertainty control in complex real-world AI systems.
Conclusion
CPA establishes a rigorous, theoretically grounded, empirically validated framework for auditing, visualizing, and optimizing conditional coverage in conformal prediction. By reconceptualizing conditional validity assessment as a supervised learning problem, CPA closes a crucial gap in uncertainty quantification—systematically diagnosing and mitigating coverage failures in heterogeneous and complex data regimes. The framework’s diagnostic, selection, and operational contributions make it a foundational tool for principled uncertainty management in modern ML and AI pipelines.