- The paper highlights that gradient-based (IG) and attention-driven (Chefer) methods provide the most faithful explanations across diverse clinical tasks.
- The study employs sufficiency and comprehensiveness as key metrics to evaluate interpretability while demonstrating significant computational efficiency gains.
- Implications include design guidelines for integrating attention mechanisms in hybrid architectures to improve both predictive performance and model transparency.
Interpreting Deep Clinical Predictive Models: Benchmarking and Guidelines
Introduction
The interpretability of deep learning models in clinical time-series prediction remains a critical requirement for real-world deployment due to stringent demands for transparency and justification in medical decision-making. This study conducts a rigorous, reproducible benchmark of interpretability methods applied to diverse clinical prediction tasks and model architectures, focusing on the faithfulness and scalability of explanation methods. The analysis spans black-box approaches (SHAP, LIME), gradient-based methods (Integrated Gradients, DeepLIFT, GIM), and attention-based attribution (Chefer) across multiple clinical tasks with models such as StageNet, Transformers, and hybrid architectures.
Benchmarking Interpretability in Clinical Settings
The benchmarking framework systematically evaluates interpretability methods on three large-scale MIMIC-IV tasks: mortality prediction, diabetic ketoacidosis, and length-of-stay, employing distinct deep architectures to probe the interaction of model design and explanation quality. The benchmarking protocol employs sufficiency and comprehensiveness as the core faithfulness metrics, directly quantifying the causal impact of identified features on predictive outputs.
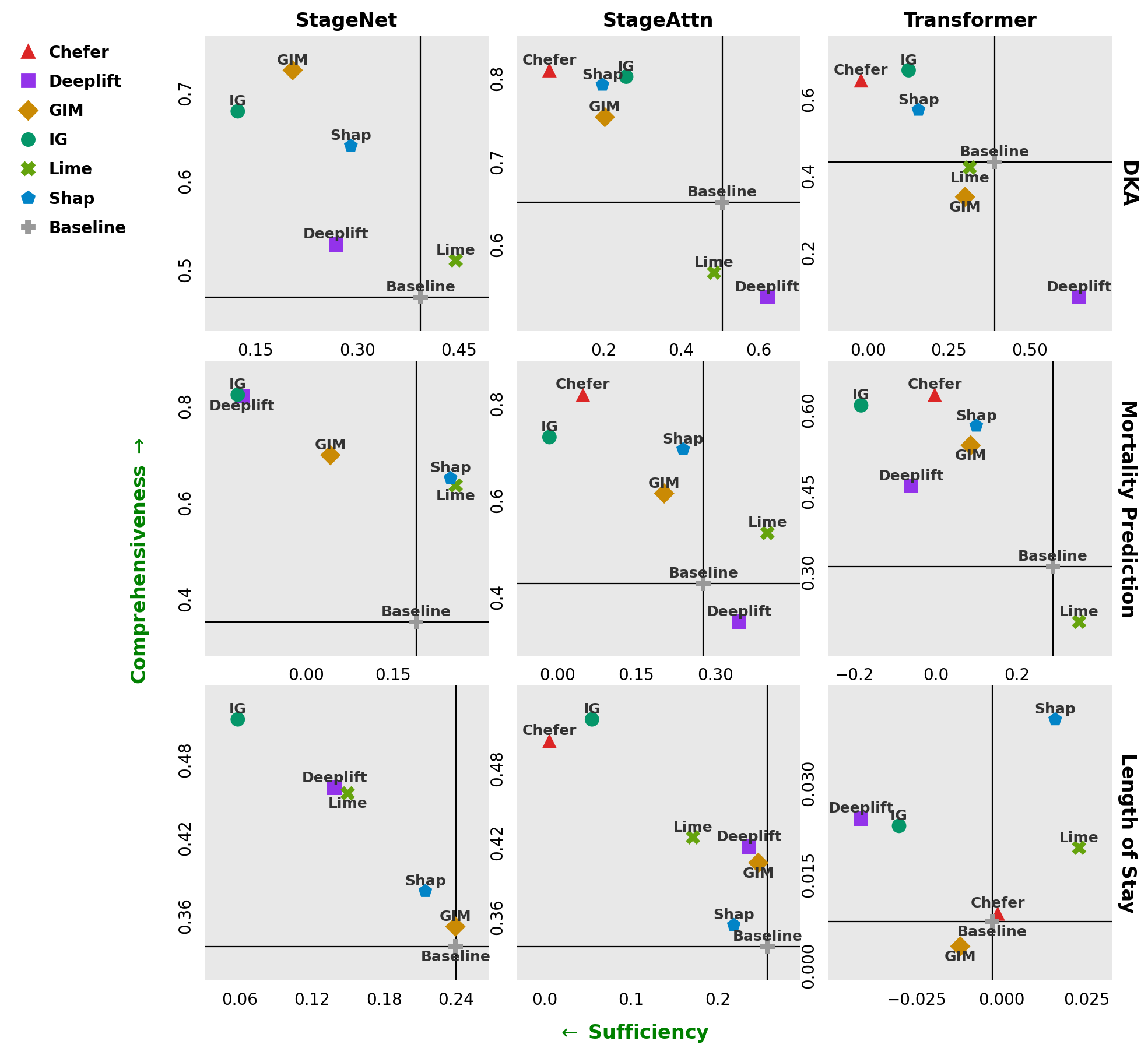
Figure 1: Higher comprehensiveness and lower sufficiency (green arrows) indicate more faithful explanations; Integrated Gradients and Chefer show competitive and robust faithfulness across architectures and tasks.
The experimental matrix reveals strong performance for both Integrated Gradients (IG) and the Chefer method. IG exhibits robust, consistent faithfulness across architectures and clinical tasks, while Chefer—based on gradient-weighted attention aggregation—yields the highest faithfulness, especially in attention-augmented and transformer variants. In contrast, methods like DeepLIFT and LIME display high variance and occasionally underperform even compared to a random attribution baseline, particularly in attention-based architectures.
Computational Efficiency and Practicality
Interpretability approaches are also assessed for computational tractability given the massive scale of electronic health record data. The analysis reveals a clear trade-off between explanatory power and runtime cost, with black-box methods such as KernelSHAP and LIME incurring prohibitive computational overhead when extrapolated to entire patient populations.
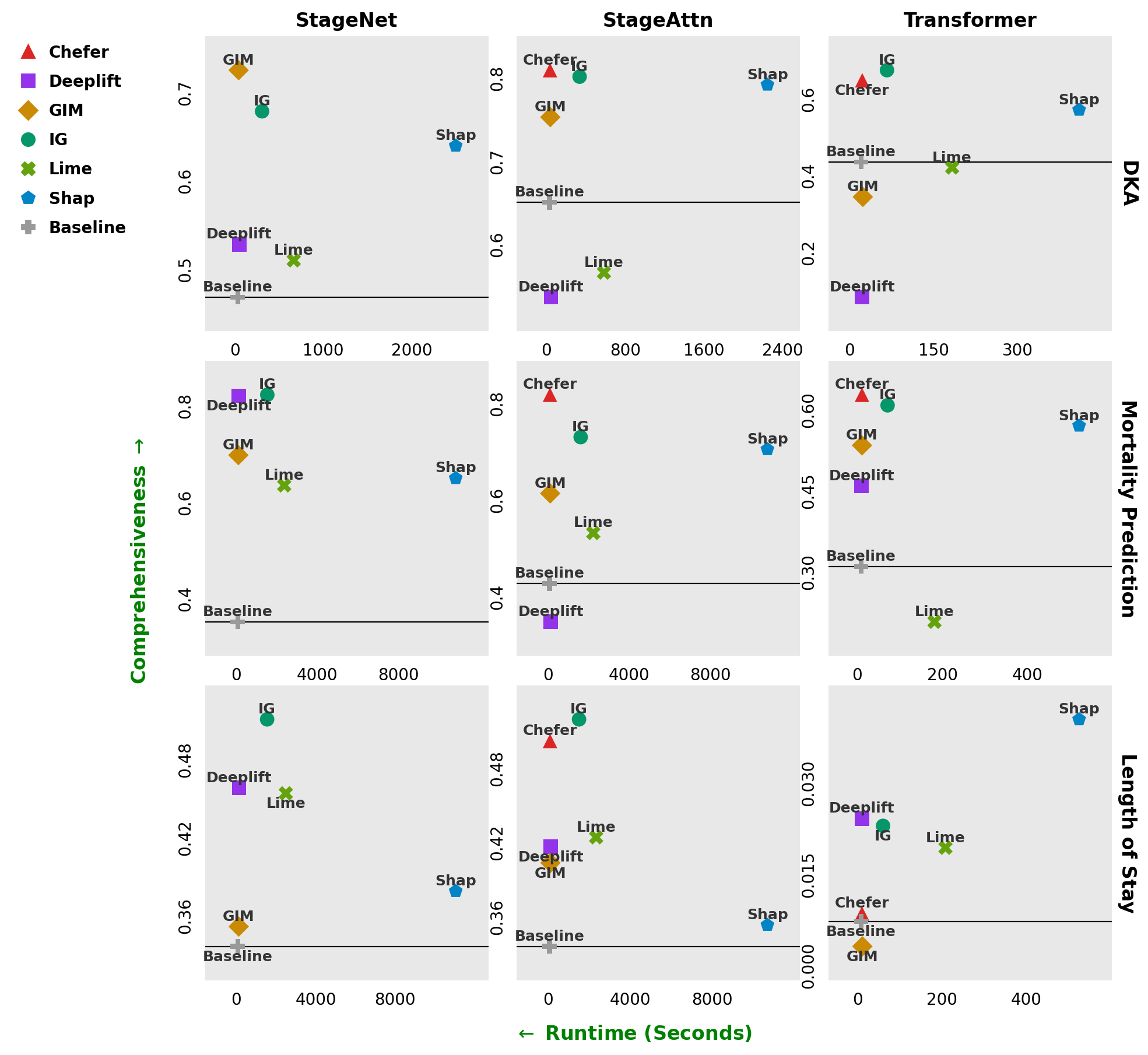
Figure 2: Chefer and Integrated Gradients maintain high comprehensiveness with significantly lower runtime than SHAP or LIME, making them feasible for high-throughput clinical interpretation pipelines.
Specifically, interpreting all instances in the largest task would require hundreds of compute hours for SHAP and over 60 hours for LIME, compared to the much leaner processing times for Chefer and IG. These measurements directly inform recommendations against deploying black-box interpreters at scale in clinical pipelines; gradient-based and attention-driven attributions offer better scalability with no loss—and often an improvement—in faithfulness.
Attention Mechanisms and Model Design
A focal experimental question is whether model design choices influence interpretability. The introduction of attention mechanisms via hybrid architectures (e.g., StageAttn) preserves or improves downstream predictive performance while enabling highly faithful and efficient explanation generation with the Chefer method. Unlike a full Transformer, which underperforms in some clinical tasks, incorporating attention atop recurrent structures yields a synergistic advantage in interpretability without accuracy degradation. This signals a practical design pathway for future clinical models requiring both high trust and operational efficiency.
Limitations of Popular Interpreter Methods
Several widely-adopted interpretability approaches are demonstrated to be unreliable in the clinical time-series context. DeepLIFT exhibits inconsistent and often unfaithful attributions for attention-augmented models, consistent with documented incompatibilities between its layer-wise difference propagation and the self-repair mechanism of attention. GIM, although powerful for LLMs, shows limited benefit within the scale and architecture of clinical models tested here. LIME's explanations are particularly volatile and computationally expensive, further limiting its practicality.
Implications, Guidelines, and Future Directions
The evidence collectively leads to explicit guidelines: gradient-based methods like IG and, for models with attention, gradient-weighted attention schemes like Chefer, are recommended for scalable, faithful, and efficient interpretability in deep clinical predictive modeling. Pure black-box post-hoc interpreters are not suitable for large-scale deployment in the medical domain.
The findings underline the importance of model-architecture alignment with interpretability objectives. The hybridization of recurrent nets with attention enables both robust predictive performance and superior, reliable explanations. The open-source release via PyHealth establishes an extensible ecosystem for systematic evaluation and reproducibility of interpretability research within the clinical setting.
Future work should address the domain-specificity of interpretability: the generalizability of these conclusions across multimodal (e.g., text, imaging) clinical data is open, as methods such as GIM may demonstrate task/architecture-dependent efficacy. Compositional and ensemble interpretability frameworks, capturing complementary explanatory signals, represent another avenue. Large-scale, community-driven benchmarks will further clarify domain best practices.
Conclusion
This study provides the most rigorous-to-date comparative assessment of interpretability methods for time-series deep clinical predictive models, highlighting robust, reproducible guidelines for both model selection and interpretability pipeline design. Attention-based attributions, especially Chefer, offer the optimal trade-off between faithfulness and computational efficiency, with Integrated Gradients as a reliable alternative in non-attention models. These results inform both immediate deployment in clinical decision-support systems and future research on scalable, trustworthy, and multimodal interpretability approaches.
Reference: "A Practical Guide Towards Interpreting Time-Series Deep Clinical Predictive Models: A Reproducibility Study" (2603.24828)

