- The paper introduces a multi-resolution training framework that fuses low- and high-resolution CLIP features for enhanced segmentation accuracy.
- It employs a Multi-Res Adapter and Multi-grained Masked Attention mechanism to restore spatial geometry and capture long-range context.
- Experiments on semantic and panoptic benchmarks show consistent SOTA improvements in mIoU and panoptic quality over existing methods.
MROVSeg: Multi-Resolution Training for Open-Vocabulary Image Segmentation
MROVSeg is presented as a novel multi-resolution training framework designed to address the resolution limitations of VLMs in open-vocabulary image segmentation. The core idea is to leverage both low-resolution (global) and high-resolution (detailed) features extracted from a single pretrained CLIP backbone to improve segmentation accuracy. The authors introduce a Multi-Res Adapter to restore spatial geometry and capture local-global correspondences across image patches, along with a Multi-grained Masked Attention scheme to aggregate multi-grained semantics from multi-resolution CLIP features to object queries. Through experiments on open-vocabulary image segmentation benchmarks, MROVSeg achieves SOTA performance.
Methodological Details
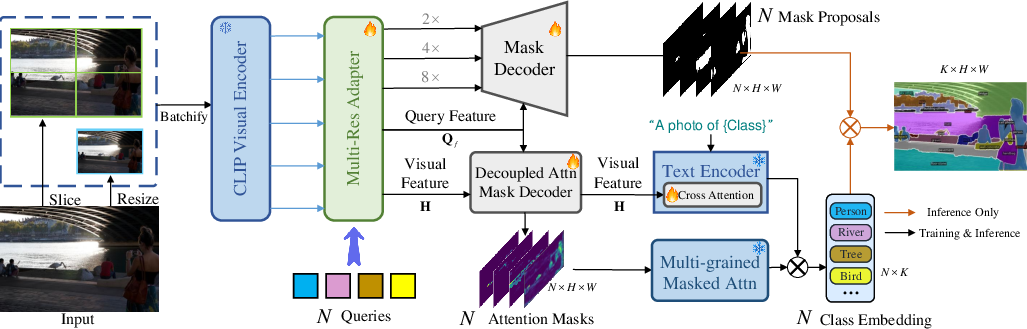
Figure 1: The overall pipeline of MROVSeg. For an high-resolution input image, its downsampled image and are fed into CLIP visual encoder to extract multi-resolution CLIP features. The Multi-Res Adapter adapts these features for mask decoder and attention mask decoder. The generated attention masks are employed to aggregate semantics from the multi-resolution CLIP features.
MROVSeg addresses the challenge of limited size adaptability in pretrained VLMs by processing images at multiple resolutions. The high-resolution image I∈R3×H×W is downsampled to extract global features, while the original high-resolution image is split into slices to capture detailed local features. The framework uses a Multi-Res Adapter and a Multi-grained Masked Attention mechanism to fuse these multi-resolution features.
Multi-Res Adapter
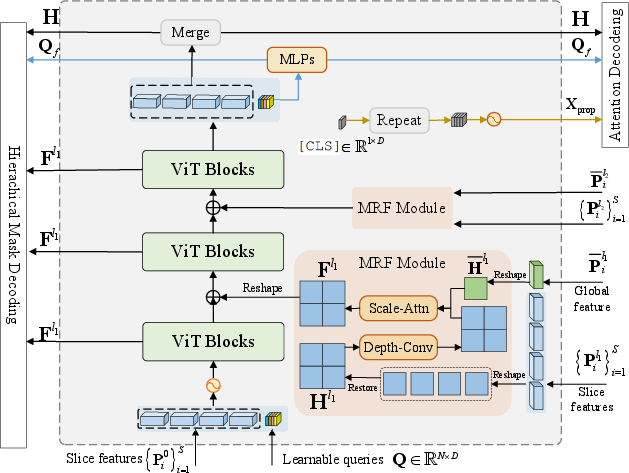
Figure 2: Multi-Res Adapter. The slice features from CLIP layer 0 {Pi0}i=1S are concatenated with learnable queries and fed to ViT Blocks. The slice features from various CLIP layers are first adapted by MRF module to restore spatial geometry and capture long-range global contexts, then are injected to the intermediate ViT Blocks. The final output visual tokens and projected queries are utilized for downstream mask prediction and classification.
The Multi-Res Adapter is designed to restore spatial geometry and capture long-range context. Given slice features {Pil}i=1S and global feature $\Bar{\mathbf{P}_i^l}$, where Pi∈RL×D, the adapter first concatenates the $0$-th slice features {Pi0}i=1S with learnable queries Q∈RN×D and inputs them into ViT blocks. For each target fusion layer l, the slice features {Pil}i=1S and global feature $\Bar{\mathbf{P}_i^{l}$ are fused through a Multi-Res Fusion (MRF) Module, which employs depthwise separable convolutions to retain the spatial geometry of high-resolution features.
The MRF module also incorporates a Scale-aware Attention mechanism [scaleattn] to dynamically adjust the trustworthiness of high-resolution and low-resolution VLM features. The fused feature Fl∈RH×W×D is computed as:
$\mathbf{F}^{l} = Up(a_{l})\odot DConv(\mathbf{H}^{l})+Up((1-a_{l}))\odot \Bar{\mathbf{H}^{l}},$
where al=σ(fAl(Hl))∈[0,1]H×W×D is the scale attention for layer l. The fused features {Flj}j=1Nj are then used for hierarchical mask decoding, and the output queries Q are projected as the query feature Qf=MLPQ(Q).
Multi-grained Masked Attention
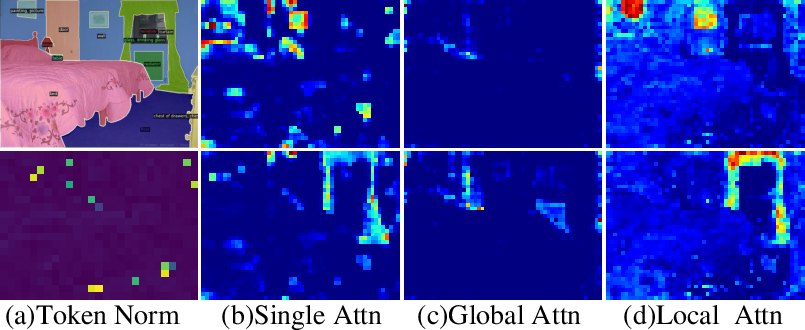
Figure 3: Effect of decoupled attention decoding for multi-grained semantics. With single attention mask decoding, the spatial cues are overwhelmed by background noise (b). Our decoupled attention mask decoding effectively splits the global and local semantics, producing relatively clean global (c) and local (d) attention masks.
The Multi-grained Masked Attention mechanism aggregates semantics from multi-resolution CLIP features by predicting decoupled attention masks. The core idea is that multi-resolution CLIP features hold semantic consistency. The [CLS] token is duplicated to query number N, and learnable positional embeddings $\mathrm{\mathbf{X}_{prop}\in \mathbb{R}^{N\times D}$ are created. The visual feature H is used to extract global contexts with max pooling $\bar{\mathbf{H}=MaxPool(\mathbf{H})$, and MLPs are trained to project them to attention space:
$\mathbf{A}_{\mathrm{local} = MLP^{L}(\mathbf{H}),\quad\mathbf{A}_{\mathrm{global}= MLP^{G}(\bar{\mathbf{H}}),$
where Aglobal∈RH×W×D′,Alocal∈Rm∗H×n∗W×D′ denote the local and global attention features, respectively. The local and global per-head attention masks are decoded by:
$\mathbf{M}_{\mathrm{local} = \mathbf{Q}_{f} \times \mathbf{A}_{\mathrm{local}^{\mathrm{T},\enspace \mathbf{M}_{\mathrm{global} = \mathbf{Q}_{f} \times \mathbf{A}_{\mathrm{global}^{\mathrm{T},$
where Qf is the output query feature.
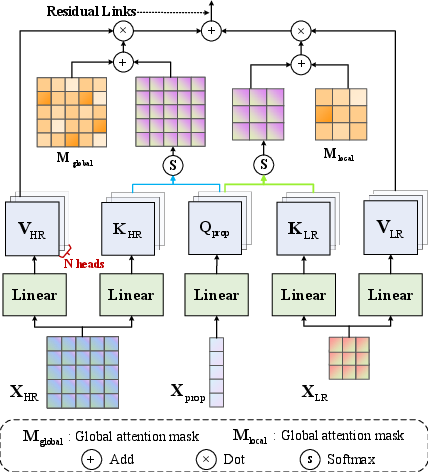
Figure 4: Multi-grained Masked Attention. Object [CLS] tokens $\mathrm{\mathbf{X}_{prop}$ perform cross attention with high- and low-resolution CLIP features XLR and XHR with decoupled attention masks.
Cross attention is performed to update $\mathrm{\mathbf{X}_{prop}$ with multi-resolution CLIP features, using the predicted attention masks $\mathbf{M}_{\mathrm{local}$ and $\mathbf{M}_{\mathrm{global}$:
$\!\!\mathbf{X}^{l+1}_{prop}\! =\! softmax(\mathbf{Q}^{l}_{prop}\!\!\left[\arraycolsep=1.0pt\defarray{1.5}\begin{array}{c}\mathbf{K}^{l}_{LR} \ \mathbf{K}^{l}_{HR}\end{array}\right]^{\!\mathrm{T}\!\!\!\!+\!\notag\left[\arraycolsep=1.0pt\defarray{1.5}\begin{array}{c} \mathbf{M}_{\mathrm{global} \mathbf{M}_{\mathrm{local}\end{array}\right]^{\!\mathrm{T}\!\!\!)\!\left[\arraycolsep=1.0pt\defarray{1.5}\begin{array}{c}\mathbf{V}^{l}_{LR} \ \mathbf{V}^{l}_{HR}\end{array}\right]\! +\mathbf{X}^{l}_{prop} ,$
where $\mathbf{Q}_{prop} = \mathbf{W}_{\mathrm{q}^\mathrm{T}\mathbf{X}_{prop}$ is the query embedding. The final output proposal logits Xprop are projected to the shared vision-language space to compute cosine similarity with text embeddings, obtaining proposal logits C∈RN×K: $\mathbf{C}=\mathbf{X}_{prop}\mathbf{W}_{\mathrm{visual}\mathbf{W}_{\mathrm{text}^{\mathrm{T}\mathbf{X}_{text}^{\mathrm{T}$. The final segmentation map S∈Z+K×H×W is produced by:
$\mathbf{S} = \mathbf{C} \times \mathbf{M}_{mask}^{\mathrm{T}.$
To generate discriminative text embeddings for similar categories, the text embeddings are conditioned with learnable cross attention layers between text embeddings and regional pooling visual features: Xtext=CrossAttnLayer(Xtextori,MaxPool(H)).
Experimental Results
MROVSeg was evaluated on several open-vocabulary semantic segmentation and panoptic segmentation benchmarks. The results demonstrate that MROVSeg achieves SOTA performance, outperforming previous methods. Ablation studies validate the effectiveness of the Multi-Res Adapter and Multi-grained Masked Attention components.
Semantic Segmentation
The semantic segmentation performance of MROVSeg was compared with current SOTA methods. MROVSeg outperforms other methods on most open-vocabulary semantic segmentation benchmarks. Specifically, MROVSeg surpasses CAT-Seg with the same CLIP backbones on four benchmarks, with gains of +0.9% mIoU for ADE-847, +0.2% mIoU for PC-459, +0.6% mIoU for ADE-150, +1.2% mIoU for PC-59, and +1.2 for VOC-20 with the CLIP ViT-B backbone. Compared to methods with additional image backbones, MROVSeg outperforms EBSeg by +2.7,+3.0,+4.1,+4.1,+1.4 mIoU\% for ADE-847, PC-459, ADE-150, PC-59, and VOC-20, respectively.

Figure 5: Qualitative comparison with SAN [san] and EBSeg [ebseg].
Panoptic Segmentation
The panoptic segmentation performance of MROVSeg was evaluated on the ADE benchmark. MROVSeg surpasses previous methods on panoptic quality (PQ) and recognition quality (RQ), achieving new SOTA open-vocabulary panoptic segmentation performance. Close-set panoptic segmentation results indicate that training the MROVSeg model does not lead to severe overfitting on the base dataset.
Efficiency Analysis
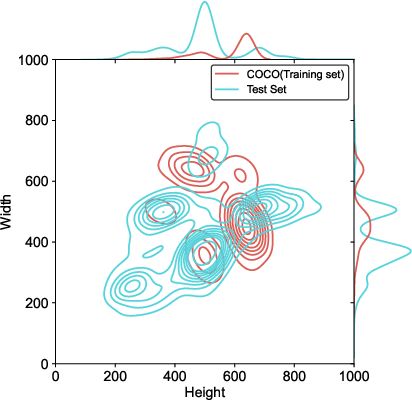
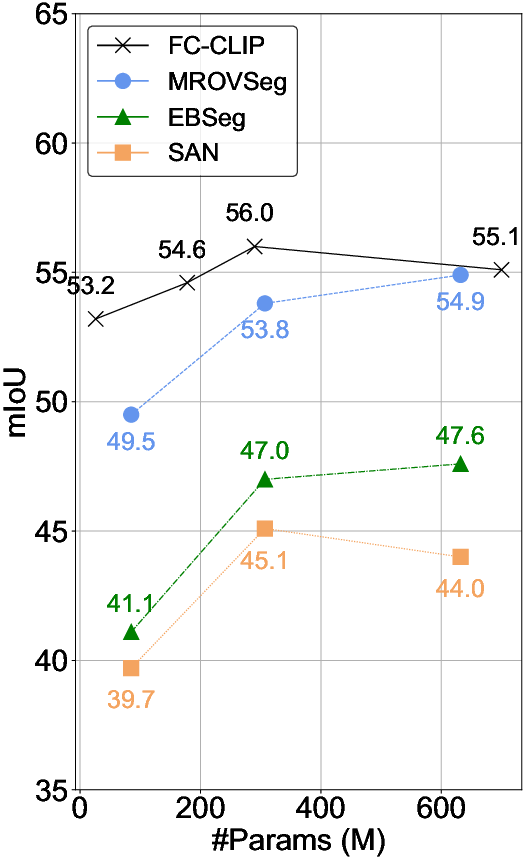
Figure 6: Visualization of image resolution distribution histogram of the datasets in Tab.1.
The computation overhead of MROVSeg was compared with recent methods. The method exhibits strong efficiency in terms of both training and inference. This efficiency is achieved by using a single CLIP backbone and employing a slice-then-input strategy to avoid quadratic computation cost with regard to the input image size.
Ablation Studies
Ablation experiments were conducted to assess the contribution of each component in MROVSeg. The baseline model uses single-resolution CLIP plain ViT features for mask decoding and MaskPooling for mask class recognition. The introduction of multi-resolution CLIP features marginally outperforms the baseline. The Multi-Res Adapter significantly outperforms the baseline, with gains of 4.8\%, 5.1\%, 2.3\%, 7.2\%, and 1.5\%. Integrating Masked-Attention slightly outperforms MaskPooling. Finally, integrating Multi-grained Masked Attention results in a performance boost, outperforming the baseline by 6.4\%, 7.0\%, 3.9\%, 8.4\%, and 2.2\%.

Figure 7: Effects of decoupled attention decoding for multi-grained semantics. The t-SNE [van2008visualizing] visualization shows that decoupled attention masks can further split the query embedding from different classes, making clear classification boundaries.
Conclusion
MROVSeg is a multi-resolution training framework that enhances open-vocabulary image segmentation by leveraging multi-resolution VLM features. The quantitative and qualitative results on well-established open-vocabulary segmentation benchmarks demonstrate its effectiveness and versatility. The method presents a strong baseline for future research in the area.