Optimizing Small Language Models for NL2SQL via Chain-of-Thought Fine-Tuning
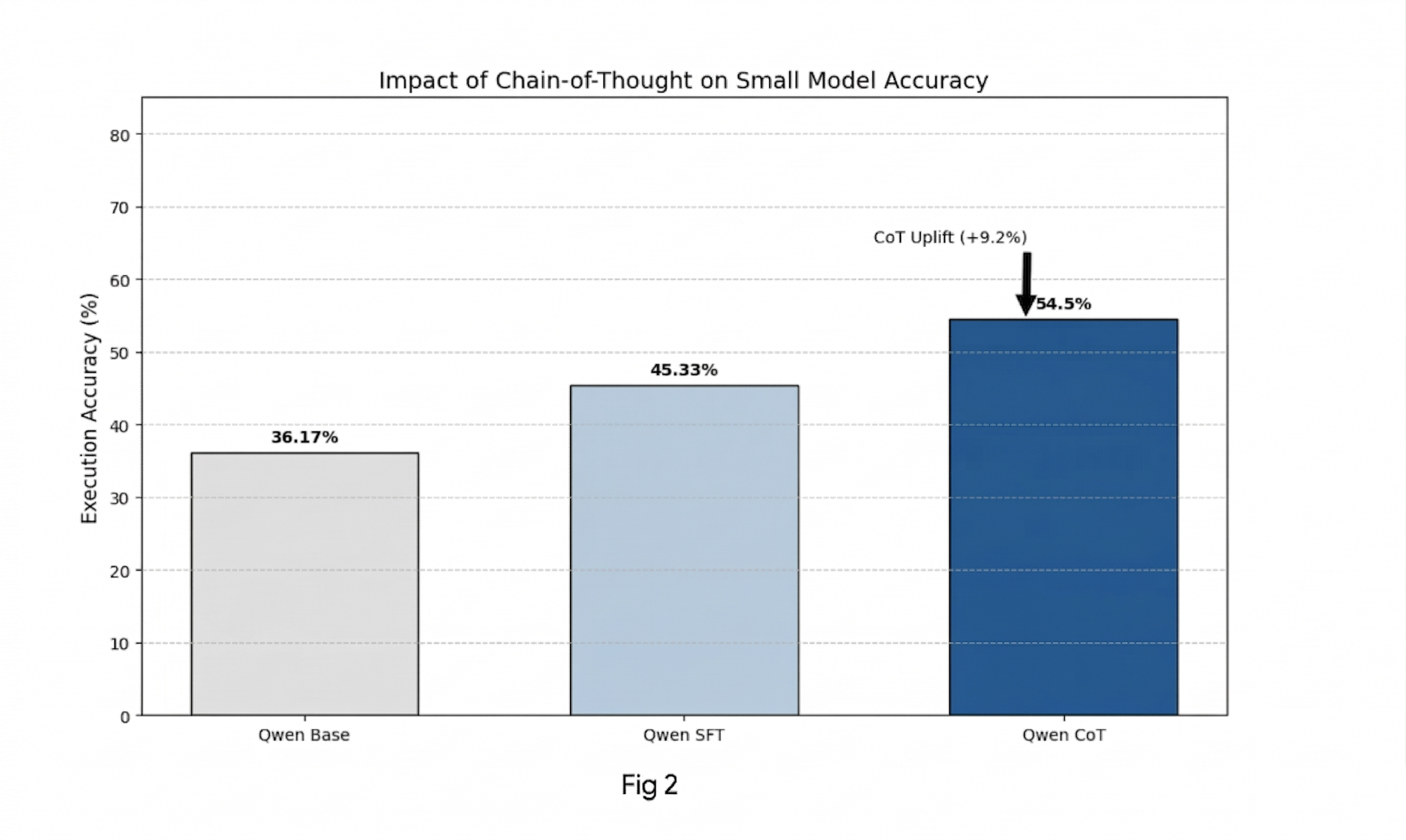
Abstract: Translating Natural Language to SQL (NL2SQL) remains a critical bottleneck for democratization of data in enterprises. Although LLMs like Gemini 2.5 and other LLMs have demonstrated impressive zero-shot capabilities, their high inference costs limit deployment at scale. This paper explores the efficacy of fine-tuning both large and small LLMs on NL2SQL tasks. Our research reveals a counter-intuitive scaling phenomenon. Fine-tuning large models (Gemini 2.5 Flash/Lite) on standard datasets yields negligible returns, often leading to overfitting on complex queries. Conversely, small models (Qwen) show significant gains. Fine-tuning improved the small model baseline from 36% to 45%, and further enriching the dataset with explicit Chain-of-Thought (CoT) reasoning surged accuracy to 54.5%(Fig 2). While this is still lower than the accuracy of large models like Gemini 2.5 , it does serve the business goal of significant cost reduction, latency in inference time and also meeting the business critical performance accuracy threshold.This paper demonstrates that transferring reasoning patterns enables compute-efficient smaller models to approach production-grade performance.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
The paper looks at how to teach computers to turn everyday questions in English into database questions written in SQL (a language used to get information from databases). This task is called “NL2SQL.” The authors ask: can we make smaller, cheaper AI models nearly as good as big, expensive ones by training them the right way?
Their main idea is to teach small models to “show their work” step by step (called Chain‑of‑Thought, or CoT), so they learn how to reason about tables and columns before writing the final SQL answer.
What questions the researchers wanted to answer
The paper focuses on three plain‑language questions:
- Do big AI models (like Gemini 2.5) get better if you fine‑tune them for NL2SQL, or does it hurt them?
- Can a smaller, cheaper model (like Qwen‑7B) get much better with fine‑tuning?
- If we train small models to explain their reasoning step by step (CoT), does that help them write better SQL?
How they studied it (methods explained simply)
To test this fairly, the team set up a consistent way to train and judge different models:
- Models they tried:
- Big models: Gemini 2.5 (Pro/Flash/Flash‑Lite) as strong baselines.
- Small model: Qwen‑7B (a much smaller “brain” that’s faster and cheaper).
- How they trained:
- “Standard fine‑tuning” (SFT): show the model many examples of English questions and the correct SQL answers.
- “Chain‑of‑Thought fine‑tuning” (CoT): show the model the same examples, but also the step‑by‑step reasoning a person would use to get from the question to the SQL (like “what tables do I need?” and “which columns match the request?”).
- They used a parameter‑efficient method called LoRA (Low‑Rank Adaptation), which is like adding small adapters so you don’t have to retrain the entire model.
- What data they used:
- A popular NL2SQL benchmark called Spider, which has lots of databases and questions.
- They reshaped the training and test sets to include more “hard” questions (with nested logic, joins, groupings, etc.) so models wouldn’t just pass by answering the easy stuff.
- They gave the models clear “schema descriptions” (what tables and columns exist, types, and sample values) to reduce silly mistakes.
- How they measured success:
- “Execution accuracy”: instead of checking if the text of the SQL matches exactly, they run the SQL and see if the results match the correct answer. This is fairer because there can be many valid ways to write the same SQL.
Key terms in everyday language:
- SQL: a language to ask questions from databases (like “show me all customers in California”).
- Fine‑tuning: giving an AI extra practice with specific examples so it’s better at one task.
- Chain‑of‑Thought (CoT): teaching the model to explain its steps, like showing your work in math class.
- Overfitting: when a model memorizes its homework examples but then does worse on new, tricky questions.
What they found (the results and why they matter)
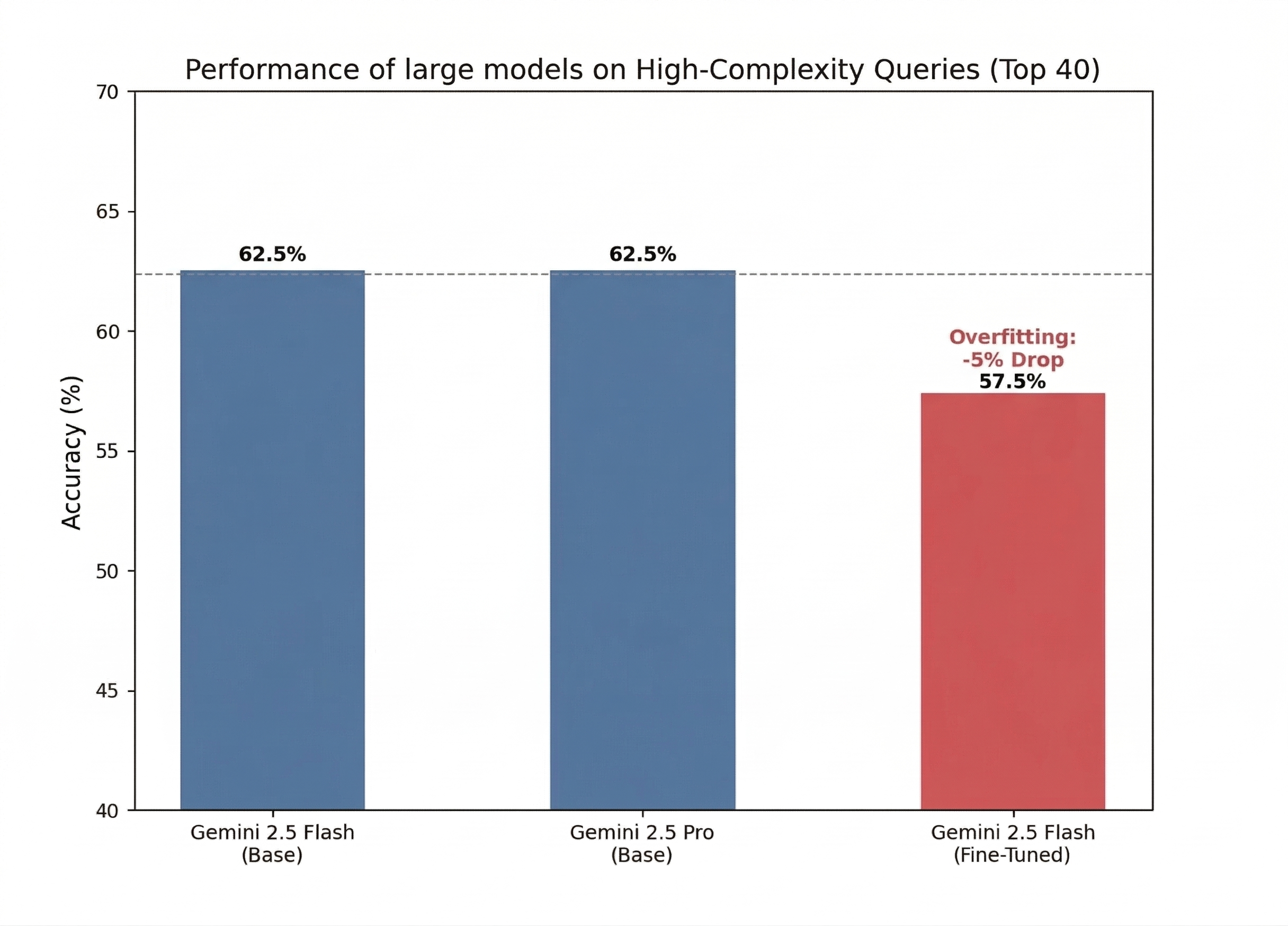
Big surprise: fine‑tuning big models didn’t help, and sometimes made them worse on tough questions.
- Gemini 2.5 Flash:
- Before fine‑tuning: about 73.2% accuracy
- After standard fine‑tuning: about 72.5% (slightly worse)
- Gemini 2.5 Flash‑Lite:
- Before fine‑tuning: about 73.0%
- After fine‑tuning: about 73.8% (tiny improvement)
On the hardest questions, the fine‑tuned big model actually dropped more, suggesting overfitting (memorizing patterns instead of reasoning).
Small model success:
- Qwen‑7B:
- Before fine‑tuning: about 36.2%
- After standard fine‑tuning: about 45.3% (nice boost)
- After Chain‑of‑Thought fine‑tuning: about 54.5% (biggest jump)
Why this matters:
- Teaching the small model to reason step by step helped it tackle complex questions much better.
- Even though 54.5% is lower than the 73% of large models, the small model is much cheaper and faster to run, which is important for real business use at scale.
What this could change (implications and impact)
- Different strategies for different sizes:
- Big models: extra fine‑tuning didn’t help much and could hurt; better to use smart prompts or retrieval methods rather than retraining.
- Small models: CoT fine‑tuning is a game‑changer. It gives them the reasoning skills they were missing, pushing them closer to “good enough” for many real uses.
- Practical benefits:
- Lower costs: smaller models are far cheaper to run, especially when many queries happen every day.
- Faster answers: small models respond quicker, which is helpful even if they write a few extra “thinking” tokens.
- Closer to production use: hitting around 55% execution accuracy on hard, realistic questions can meet some business thresholds, especially when combined with guardrails, validation, or human checks.
Limitations to keep in mind:
- The tests used the Spider dataset; real company databases can be messier with confusing names and structures.
- Writing out reasoning (CoT) adds extra text, which can slow things a bit; future work could help the model “think silently” without typing every step.
Bottom line
If you want to let people ask databases questions in plain English without huge costs, training small models to show their reasoning steps is a powerful approach. Big models already know a lot and don’t gain much from standard fine‑tuning—but small models learn a ton when you teach them how to think through the problem, not just memorize answers.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored based on the paper.
- External validity beyond Spider: results are only on Spider dev; no evaluation on other NL2SQL benchmarks (e.g., Spider 2.0, BIRD, WikiSQL, SParC) or real enterprise schemas with messy/denormalized structures and idiosyncratic naming.
- Data leakage and split clarity: the 5,500 training set, 500 validation set, and 600-query benchmark are curated from Spider, but the paper does not confirm strict train/val/test isolation or leakage prevention across these subsets.
- Complexity scoring validity: the custom complexity metric (clause-based + recursion) is not validated against human difficulty ratings nor shown to correlate with error rates; important SQL constructs (e.g., window functions, CTEs, set ops nuance) are not clearly captured.
- Distribution-shift risks: rebalancing to 40% “hard” queries in training and evaluation may misrepresent real-world frequency; no study of performance under natural (unbalanced) distributions.
- Generalization to unseen databases: while Spider encourages cross-domain generalization, the curated training/eval setup may reduce difficulty; no per-database breakdown of performance on completely unseen schemas.
- SQL dialect coverage: no assessment across different dialects (PostgreSQL, MySQL, BigQuery, Snowflake) or dialect-specific functions, casting, and date/time semantics.
- Execution Accuracy limitations: the metric may accept semantically different-but-executing queries or be sensitive to data/duplicate rows; no complementary metrics (Exact Match, component-wise matching, syntax-validity rate, exec-guided decoding success).
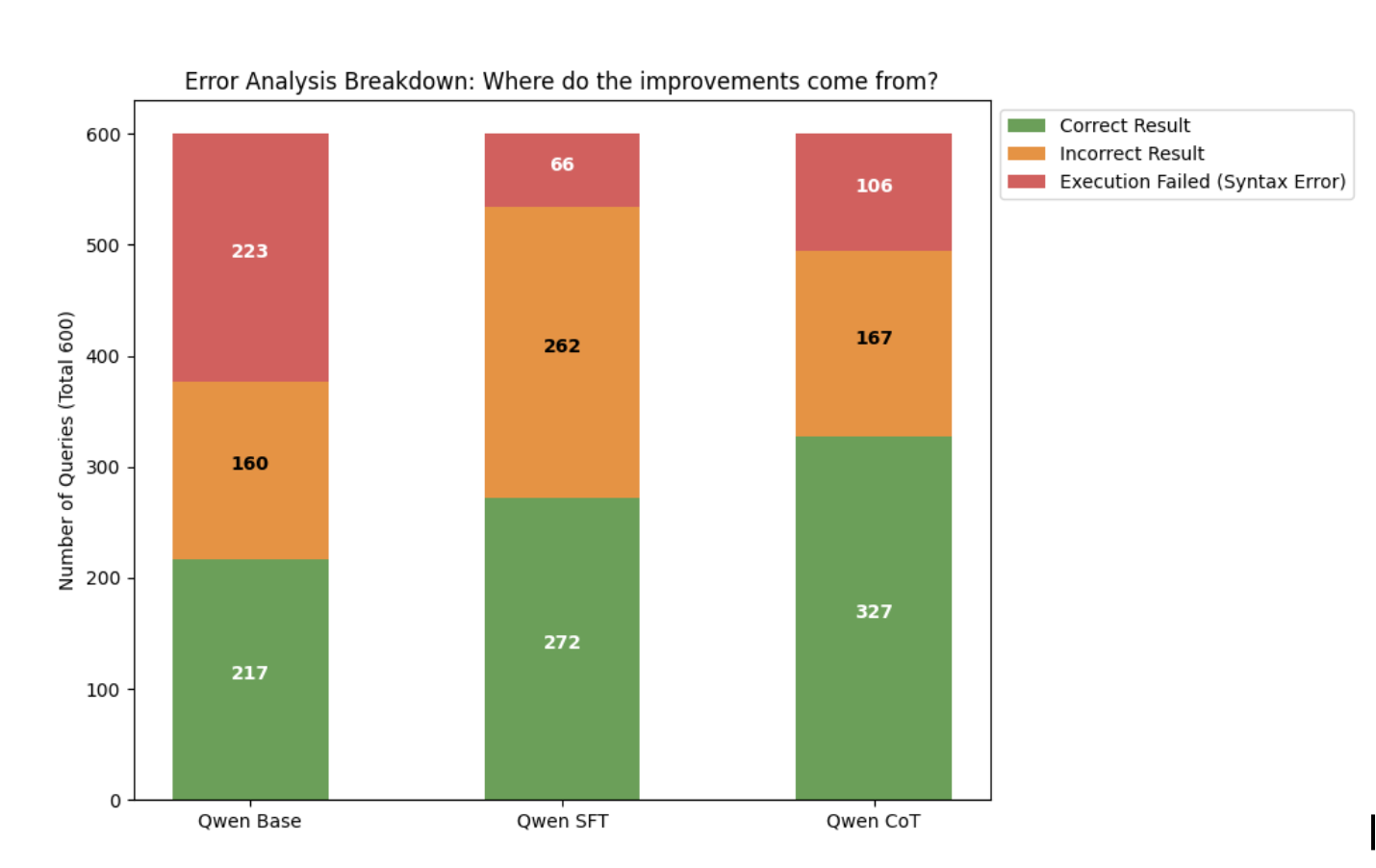
- Error analysis depth: an “Error Analysis Breakdown” figure is referenced without qualitative/quantitative details (e.g., schema linking vs join logic vs aggregation vs nesting errors).
- CoT source and quality control: unclear whether CoT traces are human-written or LLM-generated, how they were verified, and how noisy/incorrect reasoning steps affect learning.
- CoT ablations: no ablation to isolate which CoT components (table selection, join strategy, self-validation) contribute most; no study of CoT length, style, or formatting on performance.
- Inference-time CoT vs latent reasoning: token overhead is acknowledged but not quantified; no experiments with latent/suppressed CoT, distilled rationales, or rationale-free inference after CoT training.
- Token/latency/cost measurements: claims of latency and cost benefits are not backed by measurements (throughput, latency distributions, $/query, tokens/query).
- Variance and significance: single-run results without confidence intervals, multiple seeds, or significance testing; unclear robustness to training randomness.
- Training compute/reporting: missing details on hardware, training time, total tokens, early stopping, and reproducibility constraints (especially for Gemini fine-tuning).
- Large-model fine-tuning hypothesis: “representation collapse” is posited but not experimentally probed (e.g., probing tasks, activation similarity, or CoT-based fine-tuning for large models as a counter-example).
- CoT for large models: only standard SFT is tested; no experiments testing whether CoT fine-tuning mitigates overfitting or degradation in large models.
- Prompt engineering ablations: the impact of schema descriptions and self-correction prompts is not isolated from fine-tuning effects; no controlled ablations across prompting strategies.
- Alternative decoding strategies: no comparison with execution-guided decoding, constrained/grammar decoding (e.g., PICARD), beam search variants, or self-consistency sampling—especially relevant for small models.
- Retrieval and tool-use: no exploration of schema/entity linking retrieval, sample-value lookups, or DB-tool feedback loops (e.g., optimizer errors, dry-run validation) at training or inference.
- Teacher–student distillation: despite references to distillation, no explicit teacher model, generation protocol (temperature, n-samples), or filtering strategy is described for creating CoT traces.
- Model breadth: only Qwen-7B is evaluated; no comparison across other small/medium models (LLaMA, Mistral, DeepSeek-Coder, Phi) to assess generality of CoT benefits.
- Adapter and hyperparameter ablations: limited exploration of LoRA rank, learning rates, epochs, or adapter placement; no learning curves to study data/compute scaling laws for CoT.
- Robustness and adversarial tests: no evaluation on noisy/ambiguous queries, paraphrases, OOD vocabulary, or adversarial perturbations common in user queries.
- Interactive/multi-turn NL2SQL: the system does not handle clarifying questions or iterative refinement, which is often required in enterprise usage.
- Safety and permissions: only SELECT-like tasks are implied; no consideration of preventing harmful DML/DDL, injection risks, or permission-aware generation.
- Cascaded systems: no exploration of hybrid pipelines (e.g., small-model first, large-model fallback for hard cases) or routing policies to optimize cost–quality trade-offs.
- Data and code release: reproducibility is limited without public access to the curated datasets, CoT traces, prompts, and evaluation harness.
- Enterprise evals: no pilot or A/B deployment with real analysts to validate the “production-viable” claim or to define the stated “business critical performance accuracy threshold.”
Practical Applications
Immediate Applications
The following applications can be deployed with current methods, tools, and benchmarks described in the paper.
- Cost-optimized NL2SQL copilots for BI/analytics platforms Sectors: software, finance, retail, healthcare, manufacturing Tools/workflows: Embed a CoT–fine-tuned small model behind dashboarding tools (e.g., Looker, Tableau, Power BI) and data warehouses (BigQuery, Snowflake, Databricks) to translate natural questions into SQL; use execution-accuracy checks against a shadow DB before running on prod; route failures to a larger LLM. Dependencies/assumptions: Up-to-date schema extraction; secure shadow databases; RBAC/encryption; availability of CoT traces for domain schemas; licensing for model use (e.g., Qwen-7B).
- On‑prem/edge NL2SQL assistants for regulated environments Sectors: healthcare, finance, government Tools/workflows: Containerized microservices with LoRA adapters on CPUs/edge GPUs; internal schema prompts + self-correction; local execution sandboxes to validate queries. Dependencies/assumptions: Hardware sizing for token overhead of CoT; data residency/compliance (HIPAA, SOX, GDPR); secure model serving.
- “SQL Copilot” in developer data IDEs Sectors: software/DevTools Tools/workflows: VS Code/DataGrip extensions that introspect DB schemas, generate CoT reasoning plus SQL, and run execution tests; offer quick-fix suggestions on syntax/column mismatches. Dependencies/assumptions: Stable plugin APIs; DB connectivity and permissions; latency budgets that tolerate CoT token cost.
- NL2SQL cascade routing to cut inference costs Sectors: enterprise software, finance, telecom Tools/workflows: A policy that first tries the small CoT model with self-correction; if execution fails or confidence is low, fall back to a large model; log execution accuracy for continuous improvement. Dependencies/assumptions: Confidence heuristics or execution-based gating; robust logging and telemetry; SLA-aware routing.
- Domain fine‑tuning service using LoRA + CoT Sectors: data services/consulting, SaaS vendors Tools/workflows: Repeatable pipeline that applies complexity-based data curation, adds schema-aware prompts, generates CoT traces with a larger LLM for client schemas, and fine-tunes a small model with LoRA. Dependencies/assumptions: Access to representative in-domain queries (or synthesis); cost/legal permissions to use a larger LLM for distillation; MLOps for versioning and rollback.
- Query validation and auto-correction middleware Sectors: software, finance, retail Tools/workflows: Middleware that enforces “execution accuracy before production” by running queries in a sandbox; auto-corrects column/table errors via self-correction prompts; blocks destructive operations. Dependencies/assumptions: Safe test datasets or sampling; SQL sanitizer/rewriter; governance approvals for automated corrections.
- NL2SQL tutors with step-by-step explanations Sectors: education, upskilling programs, MOOCs Tools/workflows: Interactive learning portals using CoT outputs to teach SQL reasoning (table/column selection, join logic, validation); adaptive difficulty using the paper’s complexity scoring. Dependencies/assumptions: Verified solutions to avoid propagating errors; alignment with curricula; classroom integration.
- Procurement/evaluation guidelines for NL2SQL systems Sectors: policy, enterprise IT governance Tools/workflows: Adoption of “execution accuracy” instead of strict string match; require shadow-DB evaluation and complexity-stratified benchmarks; avoid unnecessary SFT for large models; prefer prompt+RAG. Dependencies/assumptions: Internal benchmark creation; availability of shadow schemas; buy-in from stakeholders.
- Spreadsheet add‑ins for natural‑language queries over databases Sectors: daily life, SMBs, nontechnical teams Tools/workflows: Excel/Google Sheets plugins that connect to data sources and translate questions to SQL via the small CoT model; preview results with execution checks. Dependencies/assumptions: Secure connectors; limited query budgets; user education on data access policies.
- Open-source reference pipeline for NL2SQL MLOps Sectors: academia, OSS community, startups Tools/workflows: Release of code templates for complexity-based dataset curation, schema-driven prompting, execution-accuracy harnesses, and LoRA training; reproducible Spider-based benchmarks. Dependencies/assumptions: Data licenses; maintainers; reproducible compute environments.
Long-Term Applications
These opportunities need further research, scaling, robustness improvements, or standardization before widespread deployment.
- Latent (non-verbalized) reasoning to cut token overhead Sectors: software, cloud, mobile Tools/workflows: Train small models to “think in latent space” and emit only final SQL; combine with self-verification via execution checks to preserve accuracy with lower latency. Dependencies/assumptions: New training objectives; access to paired CoT and non-CoT traces; evaluation of hidden-chain reliability.
- Robust generalization to messy enterprise schemas Sectors: all data-heavy industries Tools/workflows: Schema normalization, column alias/semantic mapping, ontology grounding; automated schema summaries using RAG from data catalogs (Alation/Collibra). Dependencies/assumptions: High-quality metadata; ontology availability (e.g., ICD/CPT in healthcare, GAAP/IFRS in finance); change-management for evolving schemas.
- Verticalized NL2SQL models grounded in domain ontologies Sectors: healthcare, finance, energy, education Tools/workflows: CoT training augmented with domain vocabularies, compliance rules, and KPI templates (e.g., readmission rates, risk exposure); curated “hard” query curricula per sector. Dependencies/assumptions: Domain datasets and subject-matter expert review; regulatory constraints on model behavior and data access.
- Privacy-preserving CoT distillation at scale Sectors: policy, cloud, enterprise IT Tools/workflows: Generate/sanitize CoT traces with differential privacy or synthetic data; federated distillation where CoT stays on-prem and only adapter updates are shared. Dependencies/assumptions: DP techniques that maintain utility; federated orchestration; cross-org governance.
- Federated, continual learning from user feedback and execution signals Sectors: SaaS analytics, multi-tenant platforms Tools/workflows: RL from execution accuracy and human edits; client-specific adapters; safe replay buffers that exclude sensitive content. Dependencies/assumptions: Privacy-safe logging; robust off-policy RL; drift detection and rollback.
- Standards and certification for NL2SQL safety and accuracy Sectors: policy/regulatory bodies, enterprise governance Tools/workflows: Industry benchmarks specifying execution-accuracy thresholds by complexity tier; certifications for safe query generation (e.g., non-destructive defaults, PII-aware filters). Dependencies/assumptions: Multi-stakeholder consensus; conformance test suites; third-party auditors.
- Multimodal schema comprehension Sectors: software, education, data engineering Tools/workflows: Use ER diagrams, sample rows, data dictionaries, and lineage graphs to improve table/column selection; RAG pipelines that pull relevant artifacts for each query. Dependencies/assumptions: Unified metadata stores; format converters; latency-aware retrieval strategies.
- Cross-warehouse NL2SQL layer with dialect adaptation Sectors: enterprise software, data platforms Tools/workflows: Dialect-aware generation (PostgreSQL, Snowflake, BigQuery) with automatic translation and execution validation; schema snapshotting and caching. Dependencies/assumptions: Dialect test suites; versioned schema registries; transactional guards.
- Curriculum scheduling driven by complexity scoring Sectors: academia, training platforms, MLOps Tools/workflows: Adaptive training that increases exposure to difficult structures (nested queries, HAVING, set operators); automated generation of “hard” examples. Dependencies/assumptions: Reliable difficulty estimators across domains; synthetic data generators that preserve semantics.
- Autonomous analytics agents beyond SQL generation Sectors: business intelligence, operations Tools/workflows: Agents that chain NL2SQL with result interpretation, visualization creation, and narrative summaries; cost-aware planning that chooses small vs large models. Dependencies/assumptions: Stable tool-use frameworks; guardrails for business logic; human-in-the-loop approvals.
- Energy-efficient, large-scale deployments of small NL2SQL models Sectors: cloud, edge/IoT, sustainability initiatives Tools/workflows: Model compression, quantization, and low-power serving for large fleets of data apps; fleet-wide telemetry to tune CoT verbosity vs accuracy. Dependencies/assumptions: Hardware support (e.g., INT4/INT8); ops maturity for fleet management; acceptance of accuracy–latency trade-offs.
- Procurement policies that disfavor unnecessary SFT of large models Sectors: policy, enterprise IT Tools/workflows: Codify the paper’s finding that SFT can degrade large-model NL2SQL performance; require prompt-engineering/RAG baselines and AB tests before fine-tuning approval. Dependencies/assumptions: Organizational change management; transparent evaluation reports; vendor cooperation.
Glossary
- Chain-of-Thought (CoT): A prompting/fine-tuning approach where models generate intermediate reasoning steps before the final answer to improve logical performance. "explicit Chain-of-Thought (CoT) reasoning"
- cross-domain generalization: The ability of a model trained on certain schemas or domains to perform well on unseen databases and domains. "cross-domain generalization"
- development split: The portion of a dataset reserved for validation during experimentation, separate from training and test sets. "Spider dataset's development split."
- edge deployment: Running models on resource-constrained or on-premise/edge devices rather than centralized servers or cloud. "allows for cost-effective edge deployment."
- encoder-decoder architectures: Neural sequence-to-sequence models with a distinct encoder to process inputs and a decoder to generate outputs, common in NLP tasks. "encoder-decoder architectures"
- Exact Match: A strict evaluation metric that checks for textually identical outputs, often penalizing semantically equivalent SQL with different formatting. "``Exact Match''"
- Execution Accuracy: An evaluation metric for NL2SQL that executes generated SQL against a database and compares result sets to ground truth. "Execution Accuracy"
- in-context learning: The ability of LLMs to adapt to tasks by conditioning on examples provided in the prompt without parameter updates. "in-context learning"
- Knowledge Distillation: A training paradigm where a smaller “student” model learns to mimic the behaviors or reasoning of a larger “teacher” model. "Knowledge Distillation"
- latent space: The internal, continuous representation learned by a model where reasoning can occur without explicit textual steps. "reason in latent space"
- Low-Rank Adaptation (LoRA): A parameter-efficient fine-tuning method that injects low-rank update matrices into pretrained weights to reduce training costs. "Low-Rank Adaptation (LoRA)"
- overfitting: When a model learns dataset-specific patterns too closely, harming performance on harder or unseen examples. "leading to overfitting on complex queries."
- RAT-SQL: A specialized NL2SQL architecture that encodes relations in database schemas to improve text-to-SQL parsing. "RAT-SQL"
- representation collapse: A degradation where fine-tuning reduces a model’s diverse reasoning pathways to shallow pattern matching. "``representation collapse.''"
- RAG: Retrieval-Augmented Generation; augmenting model responses with retrieved external documents to improve accuracy and grounding. "Prompt engineering and RAG are more effective levers."
- set operators: SQL operators such as UNION/INTERSECT/EXCEPT that combine results from multiple queries. "set operators"
- shadow database: A non-production database instance used to execute and evaluate generated SQL safely. "shadow database"
- Spider-1.0: A widely used benchmark dataset for cross-domain, complex text-to-SQL tasks. "Spider-1.0"
- Standard Supervised Fine-Tuning (SFT): Updating model parameters on labeled input-output pairs without explicit intermediate reasoning traces. "Standard Supervised Fine-Tuning (SFT)"
- token overhead: The additional tokens (and thus latency/cost) produced when models output detailed reasoning before the final answer. "The "token overhead" of CoT is non-negligible."
- zero-shot: Model performance on a task without any task-specific fine-tuning or examples beyond the prompt. "Zero-shot"
Collections
Sign up for free to add this paper to one or more collections.