Hybrid Associative Memories
Abstract: Recurrent neural networks (RNNs) and self-attention are both widely used sequence-mixing layers that maintain an internal memory. However, this memory is constructed using two orthogonal mechanisms: RNNs compress the entire past into a fixed-size state, whereas self-attention's state stores every past time step growing its state (the KV cache) linearly with the sequence length. This results in orthogonal strengths and weaknesses. Self-attention layers excel at retrieving information in the context but have large memory and computational costs, while RNNs are more efficient but degrade over longer contexts and underperform for precise recall tasks. Prior work combining these mechanisms has focused primarily on naively interleaving them to reduce computational cost without regard to their complementary mechanisms. We propose the Hybrid Associative Memory (HAM) layer, which combines self-attention and RNNs while leveraging their individual strengths: the RNN compresses the entire sequence, while attention supplements it only with information that is difficult for the RNN to predict, which is hence the most valuable information to explicitly store. HAM layers enable data-dependent growth of the KV cache, which can be precisely controlled by the user with a single, continuous threshold. We find that this fine-grained control of the KV cache growth rate has a smooth trade-off with loss and performance. Empirically, we show that our hybrid architecture offers strong, competitive performance relative to RNNs and Transformers even at substantially lower KV-cache usage.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces a new kind of “memory” layer for AI models called Hybrid Associative Memory (HAM). It mixes two popular ways computers handle long sequences of information:
- Self‑attention (used in Transformers), which keeps a detailed list of past items so it can look back exactly.
- Recurrent neural networks (RNNs), which keep a short summary of everything so far.
HAM tries to get the best of both: it uses the RNN to summarize things that are easy to predict, and it uses a smaller, smarter “notebook” (the KV cache) to store only the surprising or hard‑to‑predict parts that the RNN might forget. This saves memory and time while keeping strong performance on tasks that need precise recall over long texts.
Key questions the paper asks
- Can we combine RNNs and attention so they work together, not separately, and play to each other’s strengths?
- Can we store fewer tokens in the attention “notebook” without hurting performance too much, by keeping only the important (surprising) ones?
- Can we give users a simple, smooth “dial” to trade memory/computation for accuracy, even after training?
How the method works (in simple terms)
Think of reading a long article:
- An RNN is like keeping a running summary in your head: quick and light, but you might miss details.
- Self‑attention with a KV cache is like keeping every sentence in a binder: you can find anything exactly, but the binder gets heavy and slow as it fills up.
HAM combines both:
- The model tries to predict the next piece using its RNN “summary”.
- It measures how surprising the current piece is (how far the RNN’s guess is from the truth).
- If it’s not surprising, the RNN summary is enough—no need to store it.
- If it is surprising, the model writes that token into the KV cache “notebook” for precise recall later.
- Later, when the model needs to answer, it blends:
- The RNN’s summary (fast, general),
- Plus attention over only the stored, surprising tokens (precise, targeted).
Key ideas explained with everyday analogies:
- KV cache: a notebook of past tokens (keys and values) you can look up exactly.
- RNN state: a running summary in your head that compresses the past.
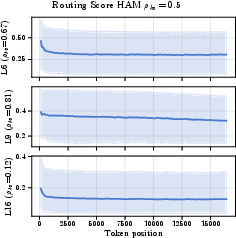
- “Surprise” score (routing metric): a measure of how wrong the RNN’s prediction was. High surprise = “better write this down.”
- Threshold (the “dial”): a single number that decides how surprising something must be to get written down. Turning this up or down changes how big the notebook gets.
- Learned router: instead of (or in addition to) measuring prediction error, the model can learn a small function that judges “Is this worth writing down?” end‑to‑end.
Why this helps:
- The RNN avoids storing everything by summarizing predictable patterns.
- The KV cache stays smaller because it only keeps the truly useful details.
- You can control the cache size precisely with one threshold, per layer or for the whole model.
A bit of intuition on limits:
- Pure RNNs can “smudge” memories when the sequence is very long (too many details crammed into one summary).
- Pure attention remembers everything but costs a lot: compute grows fast (roughly with the square of the sequence length), and memory grows linearly with sequence length.
- HAM cuts memory and compute by keeping only the right details.
What the researchers did (approach and experiments)
- Built a HAM layer that:
- Shares the usual query/key/value projections,
- Updates an RNN state on every token,
- Computes a surprise score per token,
- Writes only surprising tokens to the KV cache,
- Combines RNN and KV outputs with learned gates.
- Tried two ways to decide what’s surprising:
- Prediction error (e.g., cosine distance between the RNN’s guess and the true value),
- A small learned classifier (“router”) that decides if a token should go into the cache.
- Gave users a simple knob (the threshold τ) to target a specific fraction of tokens kept in the cache (for example, 50%).
- Trained 800M‑parameter models on a large dataset with 16k‑token contexts and compared:
- Transformers (full attention),
- Modern RNNs (e.g., Gated Delta Networks, “GDN”),
- Hybrids that interleave RNN and attention layers,
- HAM (keeping only a fraction of tokens in the cache).
They tested on:
- Standard language tasks (commonsense reasoning and reading comprehension),
- Long‑context tests (like RULER and “Needle‑in‑a‑Haystack”), which check if the model can find and use details buried far back in the text.
Main findings and why they matter
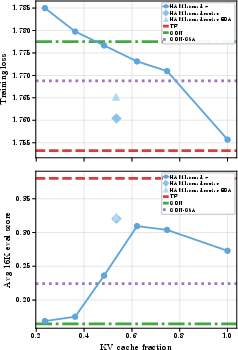
- Strong performance with less memory:
- With only about half the usual KV cache, HAM matched or beat Transformers and RNN‑attention hybrids on many standard tasks.
- On long‑context tasks, HAM with a learned router was especially competitive, often beating other models that used full attention, while using much less cache.
- Smooth trade‑off:
- As you change the cache fraction (e.g., 25%, 50%, 75%, 100%), performance changes smoothly. More cache helps, but even with less cache, performance stays solid—especially with the learned router.
- This means you can “dial in” the memory/accuracy trade‑off to fit your device or budget, without retraining.
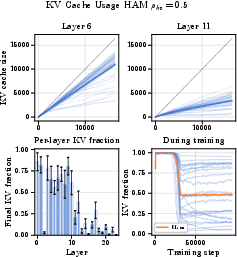
- Per‑layer control:
- You can set different thresholds per layer or globally, so some layers keep more details while others rely more on summaries.
- Better use of the cache:
- Since only surprising tokens are stored, the cache is used more efficiently than methods that either store everything or prune after the fact.
- Simple idea, big impact:
- The core trick—“only write down what the RNN can’t predict well”—is easy to understand and works across tasks.
Why this matters (implications)
- Flexible deployment: The same trained model can run on different hardware by adjusting the threshold to save memory or boost accuracy, no retraining required.
- Long‑context readiness: As apps use longer documents (e.g., research papers, codebases, books), keeping the cache small but useful becomes crucial. HAM helps models scale to longer inputs without blowing up memory.
- Better hybrid design: Earlier hybrids either stacked RNN and attention or ran them in parallel on all tokens, which still kept large caches. HAM coordinates them: the RNN handles the predictable parts, and the cache saves only the critical details.
- Neuroscience‑inspired: It echoes how human memory may use complementary systems—one for fast, precise snapshots (episodic) and one for slow, abstract learning (generalization).
In short, Hybrid Associative Memory is a practical, intuitive way to make AI models remember what matters and ignore what doesn’t—saving memory and compute while keeping (or even improving) performance, especially on long texts.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces Hybrid Associative Memory (HAM) and presents promising results, but it leaves several concrete questions unresolved that future work could address:
- Budget enforcement and worst-case guarantees: The threshold-based routing provides expected control of KV usage, but the paper does not specify a hard enforcement mechanism when many tokens are “surprising.” How can we guarantee a strict per-layer or global memory cap (e.g., via top‑k, knapsack, or learnable Lagrangian constraints) so that holds on every sequence, including adversarial or high-entropy inputs?
- Eviction policy design: If a hard cap is exceeded within a sequence, what eviction policy (e.g., recency, similarity, reservoir sampling, reinforcement‑learned eviction) preserves retrieval accuracy while respecting strict budgets? No mechanism is described for online eviction or token replacement.
- Differentiable routing and optimization details: Routing uses an indicator mask , but the paper does not detail how gradients flow through this discrete decision (e.g., straight-through estimators, Gumbel-Softmax, policy gradients). What training strategy improves stability and credit assignment for learned routers?
- Router feature inputs and ablations: The learned router is simplified to , omitting and despite initially motivating state-aware routing. How does performance change when the router conditions on the RNN state, attention projections, or historical routing signals? A thorough ablation is missing.
- Head-wise routing aggregation: Tokens are added only if (i.e., all heads are “surprised”). Would alternative aggregations (e.g., max, mean, per-head KV caches, or a learned aggregator) reduce false negatives and improve long-needle recall?
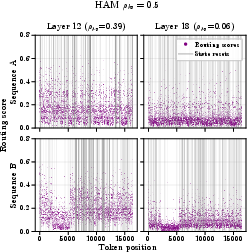
- Span- or segment-level routing: Failures on long-needle tasks (e.g., NIAH single‑3) suggest per-token routing may miss multi-token spans. Can span-level routing (e.g., chunked selection, learned span proposals) better capture long patterns and improve exact retrieval?
- Layer-wise budget allocation: Although HAM supports per-layer thresholds , experiments use a global target and do not study heterogeneous per-layer budgets. How should budgets be allocated across layers to maximize accuracy for a fixed global (e.g., via bilevel optimization or resource‑aware regularization)?
- Within-sequence scheduling: The paper proposes varying within a sequence but does not evaluate it. Can dynamic schedules (e.g., lower thresholds near potential “needles,” or during prefilling vs. decoding) improve performance without increasing average KV usage?
- Stability of learned routers: The authors add exponential decay averaging (EDA) to mitigate “sudden collapses” in deeper layers, but do not analyze failure modes or provide general stabilization strategies. What regularizers (e.g., entropy penalties, KL to a prior, variance control) and training curricula prevent collapse across scales?
- Gate interaction analysis: The per-head gated fusion between RNN and KV outputs is not ablated. How sensitive is performance to gate architectures, normalization choices, or potential gate saturation? Does regularizing gate entropy or adding sparsity constraints help?
- Backbone sensitivity: HAM’s RNN path is essentially a DeltaNet-like linear RNN; the paper does not explore other backbones (e.g., Mamba-2, higher-order SSMs, non-linear RNNs). How does the choice of recurrent module affect routing behavior and overall capacity?
- Cross-layer cache redundancy: KV caches appear to be maintained per layer, but the paper doesn’t quantify duplication of “surprising” tokens across layers. Can cross-layer sharing/deduplication of cached tokens reduce memory while preserving recall?
- Compute and latency characterization: Results report zFLOPs but no wall-clock measurements or memory bandwidth analyses. What are the end-to-end prefill and decode latencies, GPU memory footprints, and kernel efficiencies as functions of and sequence length, including the routing overhead?
- Variability and QoS under data-dependent KV growth: Data-dependent KV growth can introduce unpredictable latency/memory during inference. How large is the variance across inputs, and what mechanisms (e.g., headroom reservation, rate limiting) ensure production-grade QoS?
- Fairness of baselines and matched comparisons: Models are not FLOPs- or memory-matched to the Transformer and GDN. How do conclusions change under compute- and memory-matched comparisons at the same target context length and hardware? Are conclusions robust across different training budgets?
- Comparison to post-hoc KV pruning: Claims about HAM vs. post-hoc methods (SnapKV, PyramidKV, Ada-KV, etc.) are not empirically validated. How does an end-to-end HAM compare to strong KV-pruned Transformers at the same KV budget on the same tasks and hardware?
- Robustness to distribution shift and adversarial inputs: Routing on “surprise” may route high-entropy or noisy tokens, not necessarily useful ones. How does HAM perform under domain shifts, adversarial prompts, or inputs with many rare tokens? Can the router be made utility-aware (e.g., gradient- or loss-improvement-based)?
- Long-context scaling: Experiments go up to 16k tokens at ~800M parameters trained on 50B tokens. Do the smooth memory–performance trade-offs and routing behaviors hold at larger scales (e.g., 3B–70B) and much longer contexts (≥128k)?
- Broader evaluation coverage: Benchmarks focus on zero-shot commonsense and RULER. How does HAM perform on:
- retrieval-intensive ICL tasks requiring exact recall of long spans,
- multi-hop and chain-of-thought reasoning,
- instruction-following and tool/retrieval-augmented tasks,
- multilingual and multimodal settings?
- Token importance vs. “surprise”: The core assumption that “hard-to-predict” tokens are the best to cache is only lightly validated (toy NIAH example). When does “surprise” correlate with future retrieval utility, and when does it not? Can routers be trained to directly predict future usefulness (e.g., via teacher-forced attention maps or retrospective supervision)?
- Sensitivity to positional encodings and attention variants: Only RoPE (base 500K) is used. How do different positional encodings, grouped-query attention (GQA), or multi-query/multi-value schemes interact with routing and KV budget efficiency?
- Prefill vs. decode behavior: The paper does not differentiate routing behaviors and budgets between prefill and decode phases. Are different thresholds or policies required to optimize latency and accuracy in generation?
- Information loss through RNN compression: While HAM claims the RNN absorbs predictable content, there is no quantitative decomposition of how much information is lost to compression vs. rescued by KV. Can mutual information estimates or probing tasks quantify this trade-off per layer?
- Privacy implications: “Surprising” tokens may include PII or sensitive content. How can routers be constrained (e.g., via PII detectors or safety filters) so sensitive tokens are not preferentially cached or exposed?
- Reproducibility and implementation detail gaps: Critical details (e.g., exact gradient handling for routing, per-head KV storage design, failure cases, full training hyperparameters) are deferred to the appendix or omitted in the excerpt. Clearer specifications and open-source kernels would enable replication and rigorous benchmarking.
These gaps suggest concrete next steps: develop hard-cap routing with eviction, evaluate alternative (and state-aware) routers and head aggregations, perform compute-matched baselines and post-hoc pruning comparisons, extend to larger scales and longer contexts with rigorous latency/memory profiling, and broaden evaluations to retrieval-heavy and instruction-following tasks.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, leveraging HAM’s runtime KV-budget control, token-level routing by prediction error or learned routers, and drop-in compatibility with attention/RNN stacks.
- Memory/latency-tunable LLM serving (software/cloud)
- Description: Use HAM’s threshold
τand global KV fractionρ_KVas live “dials” to meet memory and latency SLOs without model swaps (e.g., scale from 25–75% KV usage with smooth accuracy–cost trade-offs). - Potential tools/products/workflows: “HAM-Serve” inference server plugin for Triton/vLLM; autoscaler that adjusts
τby queue depth; policy-based profiles (low-latency vs high-accuracy). - Assumptions/Dependencies: Availability of Flash/FLA and FlexAttention-style kernels; modest accuracy loss at lower KV budgets is acceptable; router calibration is stable across traffic mixes.
- Description: Use HAM’s threshold
- Cheaper long-context applications (legal, customer support, coding assistants)
- Description: Serve 16k-token contexts at ≈50% KV cache (as shown in the paper) to lower memory footprint while preserving competitive retrieval on multi-key/value tasks (RULER).
- Potential tools/products/workflows: Contract summarization, eDiscovery triage, long chat sessions, codebase navigation with capped KV.
- Assumptions/Dependencies: Document types resemble training distribution; task KPIs tolerate the small performance drop vs. full attention; serving infra supports paged/sparse KV.
- SLO-aware inference throttling (platform engineering)
- Description: Dynamically raise
τduring traffic spikes to shrink KV growth and hit tail-latency targets; relaxτduring off-peak hours for better quality. - Potential tools/products/workflows: Admission controller that sets per-request
ρ_KV; SLA policies tied to latency and GPU memory headroom. - Assumptions/Dependencies: Accurate telemetry and feedback loops; router remains well-behaved under rapid
τchanges.
- Description: Dynamically raise
- On-device/edge assistants with extended memory (mobile/embedded)
- Description: Keep critical, “surprising” details on-device via sparse KV while RNN state summarizes the rest, enabling longer contexts within tight RAM budgets.
- Potential tools/products/workflows: Email and meeting summarizers, offline translation with selective KV.
- Assumptions/Dependencies: Quantization-friendly implementations; energy constraints; router precision under low-bit arithmetic.
- Anomaly/surprisal detection from routing scores (security, SRE/ops, finance, IoT)
- Description: Repurpose the per-token prediction error (or learned router score) as a streaming anomaly indicator; store “surprising” events in KV for high-resolution forensics.
- Potential tools/products/workflows: Log triage, fraud/spoof detection, observability pipelines that elevate anomalous segments.
- Assumptions/Dependencies: Thresholds correlate with domain anomalies; careful calibration to avoid alert fatigue.
- Training-time budget curriculum (ML research/engineering)
- Description: Train with a scheduled KV fraction (e.g., ramp
ρ_KVfrom 0.25→0.5) to manage training memory/FLOPs and shape a model’s reliance on compressive vs explicit memory. - Potential tools/products/workflows: Flame/DeepSpeed configs with target KV budgets per phase; early-stopping based on KV/loss curves.
- Assumptions/Dependencies: Stable convergence with routed KV; router and thresholds are learnable with the chosen optimizer/hyperparams.
- Description: Train with a scheduled KV fraction (e.g., ramp
- KV cache analytics and observability (MLOps)
- Description: Per-layer KV growth heatmaps, routing-score histograms, and token-level audits to debug memory allocation and data-dependent KV usage in production.
- Potential tools/products/workflows: “KV Budget Dashboard,” per-layer
τoverrides, KV-usage alerts. - Assumptions/Dependencies: Logging hooks and telemetry; low overhead for tracing; privacy-sanitized token analytics.
- Plug-in router for existing hybrids (LLM stack integrators)
- Description: Add the HAM routing gate to hybrid-head or interleaved models to prevent unconditional KV growth, keeping only “hard” tokens.
- Potential tools/products/workflows: Drop-in head that shares QKV projections, plus per-layer
τand gating; minimal parameter increase. - Assumptions/Dependencies: Correct integration with existing attention/RNN heads; regression testing for layer output mixing.
- RAG budget synergy (enterprise search)
- Description: Let RNN compress common patterns while allocating KV to “not-in-index” spans or live user inputs; pair with RAG to minimize redundant KV spending.
- Potential tools/products/workflows: Router-informed chunkers; KV budget prioritization for post-retrieval synthesis and multi-document reasoning.
- Assumptions/Dependencies: RAG latency and hit rates are predictable; router can detect unfamiliar content reliably.
- Academic benchmarking of memory–performance trade-offs (academia)
- Description: Use HAM to quantify how much explicit memory each layer needs on tasks like RULER/NIAH; probe interference vs. recall under controlled KV budgets.
- Potential tools/products/workflows: Reproducible suites sweeping
ρ_KV; layer-wise ablations; open datasets of KV growth traces. - Assumptions/Dependencies: Community adoption of dynamic-KV metrics; standardized reporting of per-layer KV usage.
Long-Term Applications
The following directions need further research, scaling, or systems development but are strongly suggested by HAM’s complementary-memory design and empirical results.
- Dedicated dual-memory accelerators (hardware–software co-design)
- Description: Architect on-device SRAM “scratchpads” for sparse KV plus fused RNN-state updates; hardware support for data-dependent KV writes and masked attention.
- Potential tools/products/workflows: GPU/ASIC kernels specializing in dynamic BlockMask attention and online regression updates.
- Assumptions/Dependencies: Vendor support; generalized kernel APIs for dynamic sparsity; compelling TCO gains at scale.
- Multimodal HAM for video/audio streams (media, surveillance, AR/VR)
- Description: RNN summarizes continuous frames/audio; KV stores eventful segments (scene changes, rare sounds) for precise recall across long sequences.
- Potential tools/products/workflows: Long-horizon video QA, meeting understanding, continuous captioning with sparse KV.
- Assumptions/Dependencies: Robust routers for non-text modalities; scalable memory for very long sequences; labeled datasets for eventfulness.
- Longitudinal EHR/clinical assistants (healthcare)
- Description: Maintain compact patient trajectory in RNN while retaining rare, high-signal events (allergies, outliers) in KV to support clinical decision-making.
- Potential tools/products/workflows: Chart summarizers with KV priority on critical episodes; KV audits for explainability.
- Assumptions/Dependencies: Regulatory approvals (HIPAA/GDPR), clinical validation, strong privacy guarantees for KV traces.
- Continual-memory robotics and autonomy (robotics)
- Description: Real-time control where routine dynamics are compressed in RNN, and infrequent environmental events are stored in KV for rapid recall and planning.
- Potential tools/products/workflows: Event-triggered policies, long-horizon teleoperation assistants.
- Assumptions/Dependencies: Low-latency routing on embedded hardware; robust performance under distribution shift; safety certification.
- Federated/on-device learning with adaptive memory (mobile/IoT)
- Description: Learn
τand router locally to reflect user/device patterns, keeping only user-specific “surprises” in KV; sync compressed states centrally. - Potential tools/products/workflows: Privacy-preserving personalization with constrained KV usage.
- Assumptions/Dependencies: Efficient encrypted telemetry; resilience to heterogeneous device performance; fairness considerations.
- Description: Learn
- Safety and privacy controls via memory caps (policy, governance)
- Description: Treat
ρ_KVas a governance control to limit verbatim recall and reduce memorization risks; log routed tokens for audit with differential privacy. - Potential tools/products/workflows: Compliance dashboards that certify KV budgets per task; red-team protocols for memory leakage.
- Assumptions/Dependencies: Empirical linkage between KV budget and memorization risk; accepted testing standards.
- Description: Treat
- Global budgeter/credit allocator across layers (systems research)
- Description: A learned controller that assigns per-layer KV quotas under a global memory budget, optimizing for task reward or SLOs.
- Potential tools/products/workflows: RL/online optimization that tunes
τ_ℓgiven live metrics (latency, accuracy, cost). - Assumptions/Dependencies: Stable credit assignment across layers; reliable reward signals; safe online tuning.
- HAM + RAG + tool-use orchestration (agent systems)
- Description: Agents that decide when to write to KV vs query external tools/corpora; KV serves as a short- to mid-term episodic buffer complementing RAG.
- Potential tools/products/workflows: Planner that weighs KV writes against retrieval/tool latencies and expected value.
- Assumptions/Dependencies: Tool-call costs and latencies are predictable; router learns cross-resource arbitration.
- Explainability and audit via routing traces (governance, risk)
- Description: Use token-level routing decisions as an interpretable signal of what the model found surprising/critical; support post-hoc analysis of decisions.
- Potential tools/products/workflows: “Surprisal Map” visualizations; evidence trails in regulated industries.
- Assumptions/Dependencies: Faithfulness of routing to causal importance; secure storage of routing metadata.
- Cluster-wide KV autoscaling and “memory markets” (cloud infra)
- Description: Allocate KV budgets across tenants/jobs based on SLAs and spot pricing; degrade/upgrade KV fractions elastically.
- Potential tools/products/workflows: Memory schedulers that price KV tokens; preemption-friendly routing checkpoints.
- Assumptions/Dependencies: Multi-tenant safety isolation; robust admission control; predictable effects of KV scaling on QoS.
- Curriculum and pretraining protocols for dynamic memory (academia/industry)
- Description: Train models to generalize across KV regimes, with explicit objectives that reward accurate recall under constrained KV.
- Potential tools/products/workflows: New benchmarks and losses (e.g., interference-penalized retrieval); layerwise KV annealing.
- Assumptions/Dependencies: Task suites that reflect real deployment budgets; scalable training runs to reveal asymptotics.
- Standards and APIs for dynamic-KV models (ecosystem/policy)
- Description: Define portable interfaces for setting/reporting
ρ_KV, per-layerτ, and KV-usage telemetry across frameworks and hardware. - Potential tools/products/workflows: Open spec for dynamic KV; compliance tests bundling accuracy and energy metrics.
- Assumptions/Dependencies: Community coordination; alignment with existing serving frameworks and kernel libraries.
- Description: Define portable interfaces for setting/reporting
These applications exploit HAM’s core capabilities: complementary RNN+attention memory, data-dependent KV growth, and precise, runtime control of memory–performance trade-offs.
Glossary
- Ada-KV: An inference-time method that compresses or prunes the attention KV cache using adaptive heuristics. "Methods such as SnapKV~\citep{li2024snapkv}, PyramidKV~\citep{cai2024pyramidkv}, Ada-KV~\citep{feng2024adakv}, LAVa~\citep{lava2025}, and CAKE~\citep{cake2025} provide layer-wise or head-wise budget allocation by evicting tokens deemed unimportant according to attention-score heuristics."
- Associative memory: A memory system that retrieves stored items based on similarity or associations to a query. "we take the perspective of sequence-mixing layers like RNNs and self-attention as forms of associative memory"
- BlockMask: A masking structure specifying which blocks of the KV cache are visible to attention for efficiency and sparsity. "implemented using FlexAttention with a custom BlockMask constructor."
- CAKE: A post-hoc KV cache reduction method for Transformers that prunes tokens using attention-based criteria. "Methods such as SnapKV~\citep{li2024snapkv}, PyramidKV~\citep{cai2024pyramidkv}, Ada-KV~\citep{feng2024adakv}, LAVa~\citep{lava2025}, and CAKE~\citep{cake2025} provide layer-wise or head-wise budget allocation by evicting tokens deemed unimportant according to attention-score heuristics."
- Complementary Memory Systems: A neuroscience theory positing distinct fast episodic and slow integrative memory subsystems, inspiring hybrid memory designs. "Our framework aligns well with the rich Complementary Memory Systems theories in neuroscience in which distinct subsystems handle fast, episodic recall and slower, abstract integration of experience"
- Cosine distance: A similarity-derived distance metric based on the cosine of the angle between vectors, used here for routing. "where is a distance metric (e.g., cosine distance\footnote{We base the use of the cosine distance instead of a normalized MSE based on the typical values of and .})."
- DeepSeek DSA layer: A layer that uses a lightweight attention module to select a subset of tokens for a more expensive attention operation. "A recent alternative approach is the DeepSeek DSA layer which uses a cheaper single-head attention to select the top-k tokens for the more expensive full attention to attend to"
- DeltaNet: An RNN-style sequence layer that updates its state via an online regression objective to reduce interference. "The DeltaNet architecture \cite{schlag2021linear,yang2024parallelizing} partially addresses the memory interference issue by framing the RNN state update as an online regression problem."
- EDA (Exponential Decay Averaging): A smoothing technique that exponentially averages signals over layers or time, here applied to routing scores. "The second learned router variant applies exponential decay averaging (EDA) to the routing scores across layers"
- FlexAttention: An attention implementation that allows flexible masking and sparse patterns for efficiency. "The attention over the (dynamic) sparse KV cache is implemented using FlexAttention with a custom BlockMask constructor."
- flash-linear-attention: An efficient GPU kernel implementation for linear-attention-style RNN updates. "The RNN is implemented using flash-linear-attention \cite{yang2024fla} kernels that are modified to handle the routing."
- Gated linear dynamical systems: A class of RNN formulations where linear dynamics are modulated by gates, enabling parallel training. "most of these modern RNN-based models can be succinctly formulated as gated linear dynamical systems"
- GDN (Gated Delta Networks): A gated variant of DeltaNet used as a strong RNN baseline and component in hybrids. "Other notable efforts include the Dragon LLM \cite{dragon2025} and Nemotron-9B \cite{nemotron2025}, which integrate Gated Delta Networks (GDN)."
- GDN-GSA: A hybrid model that interleaves GDN layers with full/global self-attention layers. "We compare the HAM model against the Transformer, GDN, and a hybrid interleaving GDN and {\it full/global} self-attention (GSA) layers, denoted GDN-GSA."
- Global self-attention (GSA): Attention over the full context window without local windowing restrictions. "a hybrid interleaving GDN and {\it full/global} self-attention (GSA) layers"
- H-net: A model with a learnable router that selects which tokens to process, primarily to aid byte tokenization. "Another approach which uses a learnable router to select tokens in a sequence is H-net \citep{hwang2025dynamic}."
- HAM (Hybrid Associative Memory): A layer combining an RNN state with a selectively populated KV cache to leverage complementary strengths. "We propose the Hybrid Associative Memory (HAM) layer"
- Hopfield-like associative memories: Memory models with content-addressable recall and interference properties inspired by Hopfield networks. "From prior work on Hopfield-like associative memories \cite{amit1987statistical,hopfield1982neural,lucibello2024exponential}, we know that for a state with a key dimension the LA retrieval will start to rapidly degrade beyond a sequence length ."
- Hybrid head: An intra-layer design that combines attention and recurrence in parallel within the same layer. "a family of hybrid models implements a ``hybrid head'' where the KV cache and RNN are combined within a single layer"
- Indexer: A component that selects a subset of tokens (e.g., via attention) for further processing; here it incurs quadratic compute. "However, the entire KV cache needs to be stored at each layer and the indexer itself is quadratic in compute"
- KV cache: The stored keys and values from past tokens that attention uses for retrieval during long-context processing. "the context memory (KV cache) grows linearly with sequence length, "
- KV cache usage (): The fraction of tokens retained in the KV cache relative to the sequence length. "We define to denote the KV cache usage for a sequence."
- Learned router: A trainable mechanism that scores tokens for inclusion in the KV cache, rather than using a fixed metric. "The final two variants use learned routers and also employ learned thresholds to achieve the same final KV cache usage"
- Linear Attention (LA): An attention variant that replaces the softmax kernel with a (possibly transformed) dot product, yielding a fixed-size state. "let us consider the {\it Linear Attention} (LA) layer"
- NIAH (Needle-in-a-Haystack): Evaluation tasks that test exact retrieval of a small “needle” embedded in long “haystack” contexts. "All models excel at NIAH single 1"
- Online regression: Sequentially updating a model to fit incoming data points on the fly, used here for RNN state updates. "implement a form of online regression"
- Perplexity: A language modeling metric measuring the model’s uncertainty over sequences (lower is better). "the perplexity-scored tasks, WikiText and LAMBADA"
- Pre-norm: A transformer/RNN block design applying normalization before the main sublayer, improving training stability. "and pre-norm."
- PyramidKV: A method for hierarchical or structured KV cache pruning during inference. "Methods such as SnapKV~\citep{li2024snapkv}, PyramidKV~\citep{cai2024pyramidkv}, Ada-KV~\citep{feng2024adakv}, LAVa~\citep{lava2025}, and CAKE~\citep{cake2025} provide layer-wise or head-wise budget allocation by evicting tokens deemed unimportant according to attention-score heuristics."
- RoPE (Rotary Positional Embeddings): A positional encoding scheme that rotates query/key vectors by position-dependent angles. "We use RoPE with a base of 500K for all inputs to self-attention"
- RMSNorm: Root-mean-square normalization applied to activations to stabilize training without mean-centering. "We normalize each head output (RMSNorm) and combine via input-dependent head-wise gates:"
- RULER: A long-context evaluation suite probing recall and reasoning at scale. "we evaluate on RULER \cite{hsieh2024ruler}, which tests a model's ability to effectively use its entire context window"
- Sliding-window attention: An attention mechanism limited to a fixed-size window around each token to reduce cost. "which uses sliding-window attention interleaved with the GDN."
- SnapKV: An inference-time KV cache compression method that selects important tokens based on attention heuristics. "Methods such as SnapKV~\citep{li2024snapkv}, PyramidKV~\citep{cai2024pyramidkv}, Ada-KV~\citep{feng2024adakv}, LAVa~\citep{lava2025}, and CAKE~\citep{cake2025} provide layer-wise or head-wise budget allocation by evicting tokens deemed unimportant according to attention-score heuristics."
- Softmax (retrieval): The exponential weighting mechanism in attention that sharpens key–query similarities for precise recall. "and uses the exponential of the key-query similarity for retrieval."
- State-space models (SSMs): Sequence models defined by continuous/discrete linear dynamics used as alternatives to attention. "or based on state-space models \cite{dao2024transformers,gu2024mamba}"
- SwiGLU: A gated MLP activation function (SiLU-gated linear unit) improving expressivity and training. "All models use SwiGLU MLP blocks \cite{shazeer2020glu}"
- Threshold : A scalar cutoff controlling whether a token is stored in the KV cache based on a routing score. "We route tokens to the KV cache using a threshold that can be learned end-to-end or adjusted to control the KV cache budget."
- Top-k: Selecting the k highest-scoring tokens for further processing to reduce computation. "select the top-k tokens for the more expensive full attention to attend to"
- zFLOPs: A reported unit of (scaled) floating-point operation counts used for training cost comparisons. "require 0.3511, 0.2467 (), 0.4592 (), and 0.3429 () zFLOPs to be trained"
- Routing metric: A scoring function that determines which tokens are “surprising” and should be written to the KV cache. "The choice of which tokens to route to the KV cache is defined by a routing metric."
Collections
Sign up for free to add this paper to one or more collections.