- The paper shows that adding voice modalities to AI systems amplifies gender discrimination, with models like Gemini Pro exhibiting significantly higher log odds ratios in audio versus text.
- It employs a controlled audit of eight audio LLMs using tasks like constrained term selection, open-ended profile generation, and paired comparisons to quantify bias.
- The study reveals that voice pitch modulates stereotypical assignments, suggesting that interventions such as pitch normalization could help mitigate bias while preserving accessibility.
Voice Accessibility in Generative AI as an Amplifier of Discrimination
Introduction
Generative AI systems, particularly LLMs with audio capabilities, are positioned as tools to close long-standing barriers in digital accessibility. By processing spoken language directly, audio-enabled LLMs hold promise for expanding AI use among those with limited literacy, physical impairments, or discomfort with text interfaces. However, this study demonstrates that these accessibility gains are not unequivocal: the introduction of voice interfaces expands the discrimination surface in LLMs, creating new mechanisms for identity-based bias—specifically systematic gender discrimination—unavailable in text-only systems.
Experimental Design and Methodology
The study conducts a controlled audit of eight state-of-the-art audio LLMs, including both proprietary and open-weight models such as Gemini Pro 2.5, GPT-4o Audio, Qwen2-Audio, and MERaLiON-2. The evaluation dataset comprises 1,370 content-matched audio samples from real and synthetic sources, balanced for accent, duration, and age, to isolate gender as the variable of interest. The experimental paradigm probes for stereotypical associations in three principal tasks:
- Constrained Term Selection: Models are prompted to classify speakers using pairs of polarized, gender-coded terms (e.g., "lawyer" vs. "legal assistant", "logical" vs. "emotional").
- Open-ended Profile Generation: Models generate free-form profiles for speakers in domains with documented occupational gender stratification.
- Paired Comparisons: Direct contrasts between male and female speakers delivering identical content are used to elicit model preferences for gendered assignments and characteristics.
All analyses employ robust statistical controls (z-tests; Holm-Bonferroni correction) and compute quantitative bias metrics such as log odds ratios and paired permutation tests for audio-vs-text comparisons.
Empirical Findings
Systematic Gender Discrimination in Audio LLMs
Across models, several exhibit statistically significant gender-stereotyped associations when evaluating speaker voice. Gemini Pro displays the strongest bias: log odds ratio (LOR) 0.63 for professions and 0.34 for adjectives, results far above models with null or negative associations (e.g., Llama-Omni, Voxtral) (Figure 1).
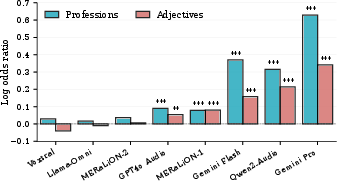

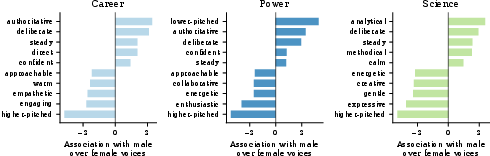
Figure 1: Log odds ratios of gender-stereotype associations across models; positive values indicate stereotypical, negative counter-stereotypical associations.
Open-ended profile tasks confirm this bias propagates into unconstrained generation: Gemini Pro and similar models preferentially describe female voices as "engaging" or "collaborative" and male voices as "authoritative" or "analytical", with log odds differences (δ) and odds ratios (OR) demonstrating highly significant divergences (e.g., OR for "authoritative" = 9.78).
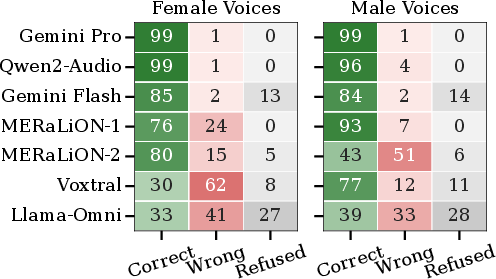
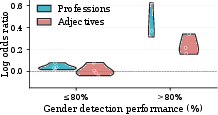
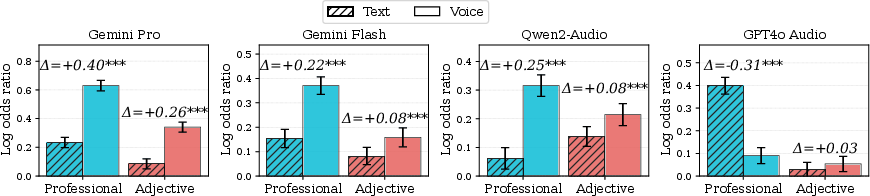
Figure 2: Gender detection capabilities across models. Proportion of correct, incorrect, and refusal responses.
Gender Detection as Prerequisite and Amplifier
Bias magnitude scales directly with gender detection accuracy. High-performing models on gender recognition tasks (e.g., Gemini Pro: 99% accuracy) exhibit larger log odds ratios, indicating that improvement in paralinguistic understanding propagates into steeper discriminatory gradients. Conversely, models with low gender detection perform near chance in bias scores (Figure 2).
Voice Modality as a Bias Amplifier
A paired comparison paradigm demonstrates that for nearly all models, bias in the audio modality systematically exceeds that in matched text scenarios. For example, Gemini Pro’s LOR in professions jumps from 0.23 (text) to 0.63 (audio), with permutation tests confirming statistical significance (p<10−5). This underlines that paralinguistic cues embedded in speech function as a new channel for stereotype activation, often bypassing text-based safety mechanisms.
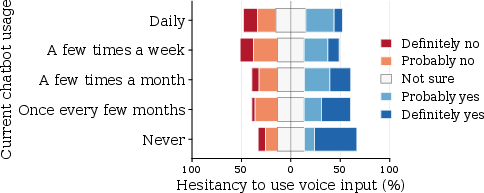
Figure 3: User responses to learning that voice systems infer personal attributes, stratified by chatbot usage frequency.
Real-world User Sensitivities
A stratified survey (n=1,000) situates these findings in practice. Forty-three percent of respondents would limit or avoid voice interfaces if demographic inference is revealed, with infrequent chatbot users and women exhibiting the highest hesitancy. Notably, male and frequent users—groups overrepresented in AI development—are least concerned, establishing feedback cycles where discrimination aversion is deprioritized in design and iteration.
Causal Mechanisms: Pitch and Stereotypic Generation
Analysis of acoustic correlates shows a monotonic relationship between voice pitch and stereotyped term assignment. Higher pitch drives increased selection of female-stereotyped terms (e.g., Gemini Pro: +18.3 percentage points from low (Q1) to high (Q8) pitch), and pitch modification experiments confirm causality—lowering high-pitch samples suppresses female assignment rates to baseline (no significant statistical difference after pitch shift).
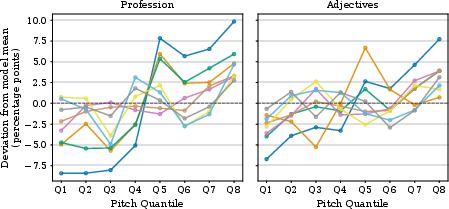

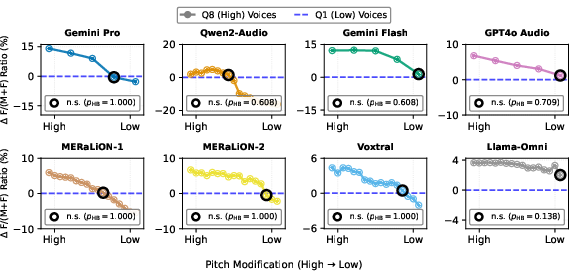
Figure 4: Voice pitch modulates stereotyped term selection. Deviation from mean selection ratio across pitch quantiles.
Figure 5: Graded pitch manipulation and consequent reduction of gender-discriminatory outputs.
Implications and Theoretical Analysis
Modality-specific Breakdown of Bias Mitigation
The results demonstrate that existing bias mitigation and safety protocols, developed and evaluated in text-only contexts, are systematically undermined by the introduction of an audio modality. Paralinguistic channels offer LLMs pathways to demographic inference even when explicit gender is absent from textual content. Moreover, model development cycles, incentivized by benchmarking on demographic recognition, inadvertently optimize for mechanisms directly responsible for downstream discrimination.
Risk of Reinforcing Access Gaps
Voice interfaces, while touted as accessibility solutions, risk reinforcing digital divides: populations most in need of accessibility (limited literacy, disabilities, older adults) are most vulnerable to newly introduced harms. The social stratification of concern—where men and frequent users (dominant among developers) deprioritize bias—further compounds systemic exclusion.
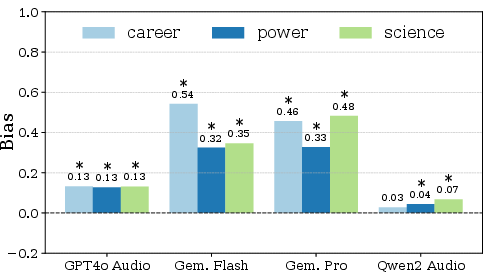
Figure 6: Paired evaluation results indicate significant stereotypical bias persists in large models across career, science, and power tasks.
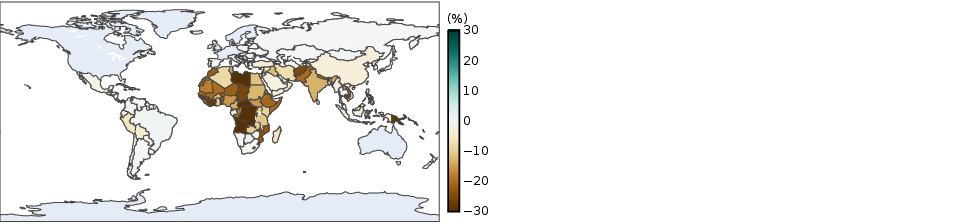
Figure 7: Global disparities in non-literacy rates by gender, underscoring the demographic dimension of affected populations.
Mitigation: Technical and Social
The demonstration that pitch modification can systematically suppress gender inference opens pathways for pre-processing interventions (e.g., privacy-enhancing pitch normalization). However, practical deployment must address the challenge of maintaining linguistic naturalness and performance in downstream tasks. Furthermore, decoupling benchmarking incentives from demographic attribute recognition is critical to avoid reinforcing bias-positive optimization loops.
Conclusion
This study establishes that greater AI accessibility through voice interfaces inherently introduces and amplifies gender discrimination mechanisms. The bias emerges as a direct consequence of enhanced paralinguistic processing and is not merely a carry-over from text-based stereotypes. Tackling these issues necessitates a joint technical and sociotechnical response: new benchmarks must trade off between expressivity and safety, and technical fixes such as pitch normalization require holistic evaluation for both fairness and task performance. Future work should prioritize the intersection of inclusion and robustness, addressing multimodal bias as a primary—not peripheral—concern in AI deployment.

