MARCUS: An agentic, multimodal vision-language model for cardiac diagnosis and management
Abstract: Cardiovascular disease remains the leading cause of global mortality, with progress hindered by human interpretation of complex cardiac tests. Current AI vision-LLMs are limited to single-modality inputs and are non-interactive. We present MARCUS (Multimodal Autonomous Reasoning and Chat for Ultrasound and Signals), an agentic vision-language system for end-to-end interpretation of electrocardiograms (ECGs), echocardiograms, and cardiac magnetic resonance imaging (CMR) independently and as multimodal input. MARCUS employs a hierarchical agentic architecture comprising modality-specific vision-language expert models, each integrating domain-trained visual encoders with multi-stage LLM optimization, coordinated by a multimodal orchestrator. Trained on 13.5 million images (0.25M ECGs, 1.3M echocardiogram images, 12M CMR images) and our novel expert-curated dataset spanning 1.6 million questions, MARCUS achieves state-of-the-art performance surpassing frontier models (GPT-5 Thinking, Gemini 2.5 Pro Deep Think). Across internal (Stanford) and external (UCSF) test cohorts, MARCUS achieves accuracies of 87-91% for ECG, 67-86% for echocardiography, and 85-88% for CMR, outperforming frontier models by 34-45% (P<0.001). On multimodal cases, MARCUS achieved 70% accuracy, nearly triple that of frontier models (22-28%), with 1.7-3.0x higher free-text quality scores. Our agentic architecture also confers resistance to mirage reasoning, whereby vision-LLMs derive reasoning from unintended textual signals or hallucinated visual content. MARCUS demonstrates that domain-specific visual encoders with an agentic orchestrator enable multimodal cardiac interpretation. We release our models, code, and benchmark open-source.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What the paper is about
This paper introduces MARCUS, a smart computer system that can “look” at heart tests and “talk” about what it sees. It’s built to help doctors diagnose heart problems faster and more accurately by reading three common kinds of tests:
- ECGs (electrocardiograms): recordings of your heart’s electrical signals
- Echocardiograms: ultrasound videos of the beating heart
- CMR (cardiac MRI): detailed heart images from a scanner
Unlike many AIs that handle only one kind of data, MARCUS can understand all three—together—and explain its reasoning in plain language.
The main questions the researchers asked
They wanted to know:
- Can an AI understand and explain ECGs, echocardiograms, and heart MRIs, both one at a time and all together?
- Can it give correct answers and useful explanations, not just short labels?
- Will it work well at different hospitals (not just where it was trained)?
- Can it avoid “mirage reasoning” (making up details about an image that wasn’t actually used)?
How they built and tested MARCUS (in simple terms)
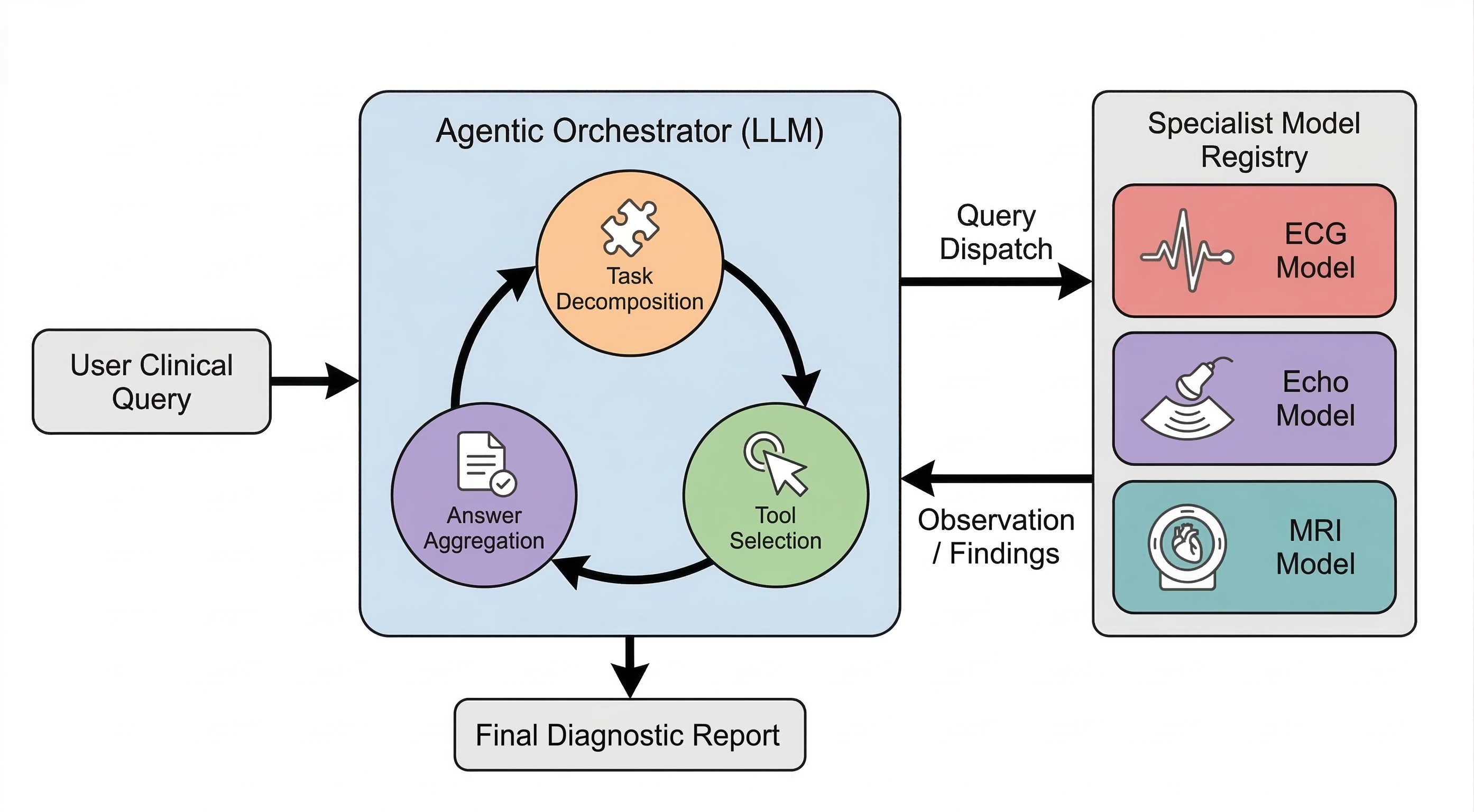
Think of MARCUS as a team:
- Three “expert readers,” each trained for one test (ECG, echo, or MRI).
- A “coach” called the orchestrator that assigns tasks to each expert, gathers their answers, checks for mistakes, and then writes a final, clear report.
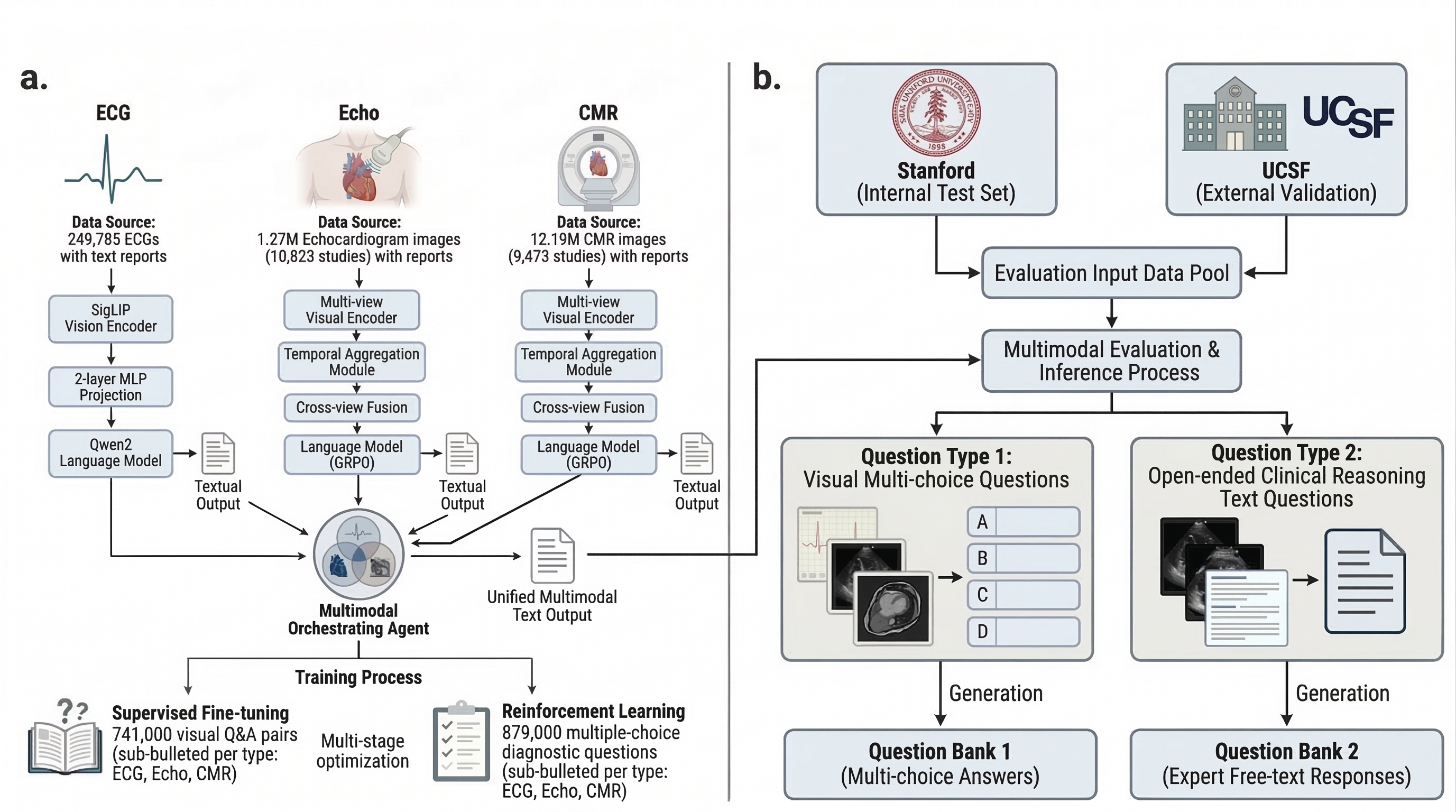
How it learns:
- The experts learned from a very large collection of real hospital data: about 13.5 million images/videos and 1.6 million paired questions and answers.
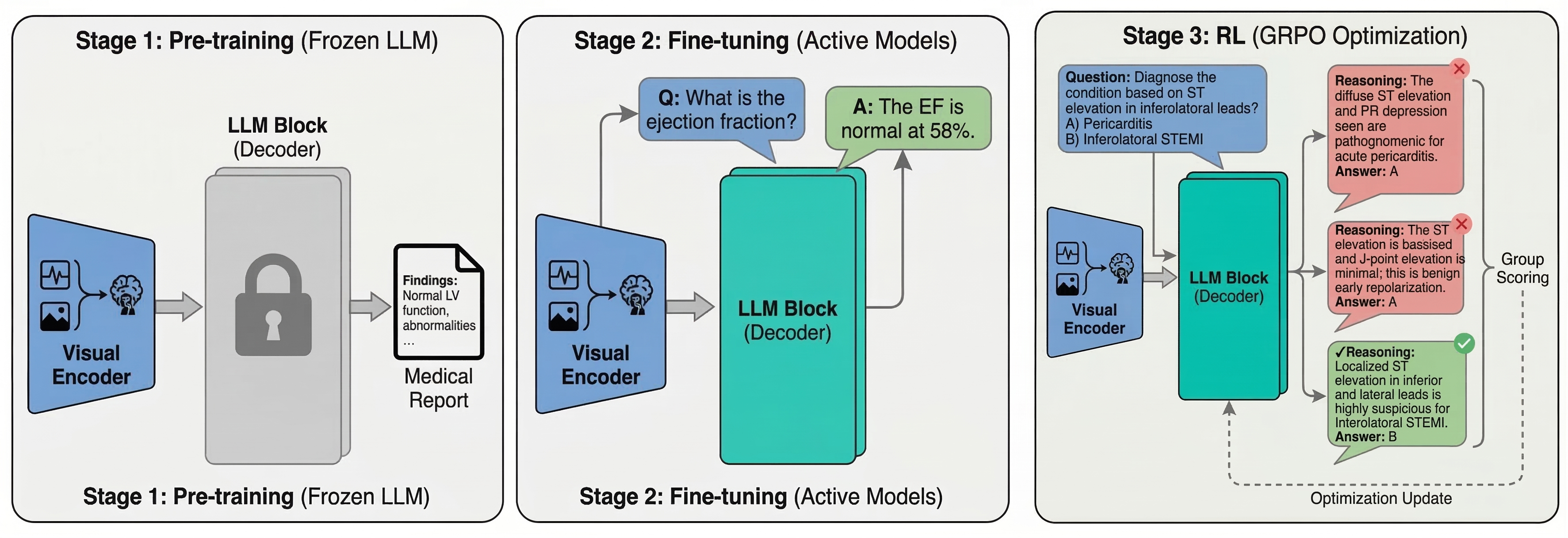
- The team used a three-step training process: 1) First, the vision parts learned to “see” patterns in ECGs and images. 2) Then, the system practiced on many question–answer examples (like flashcards). 3) Finally, it used a reinforcement method (like practicing with feedback) so it improves the steps it takes to reach correct answers.
What “multimodal” means:
- Multimodal = more than one kind of input. Doctors often combine clues from different tests. MARCUS does the same by letting each expert analyze its own test and then having the coach combine the results into one diagnosis.
How they tested it:
- Two kinds of challenges:
- Multiple-choice questions about images/videos (pick the right diagnosis).
- Open-ended questions (write a short clinical explanation, like a mini-report).
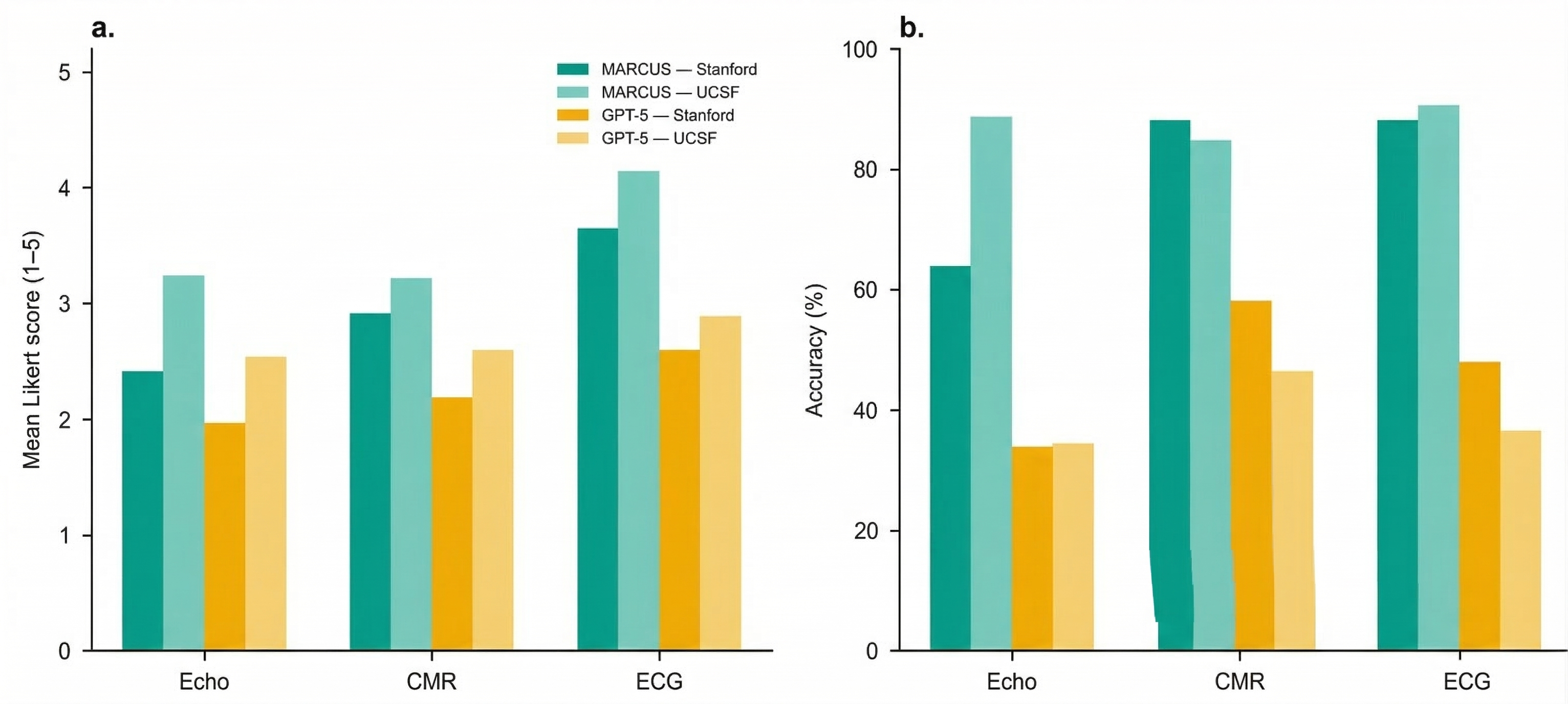
- They tested at Stanford (where it was trained) and at UCSF (a different hospital) to see if it generalizes.
- They compared MARCUS to leading general-purpose AI models (called “frontier models”).
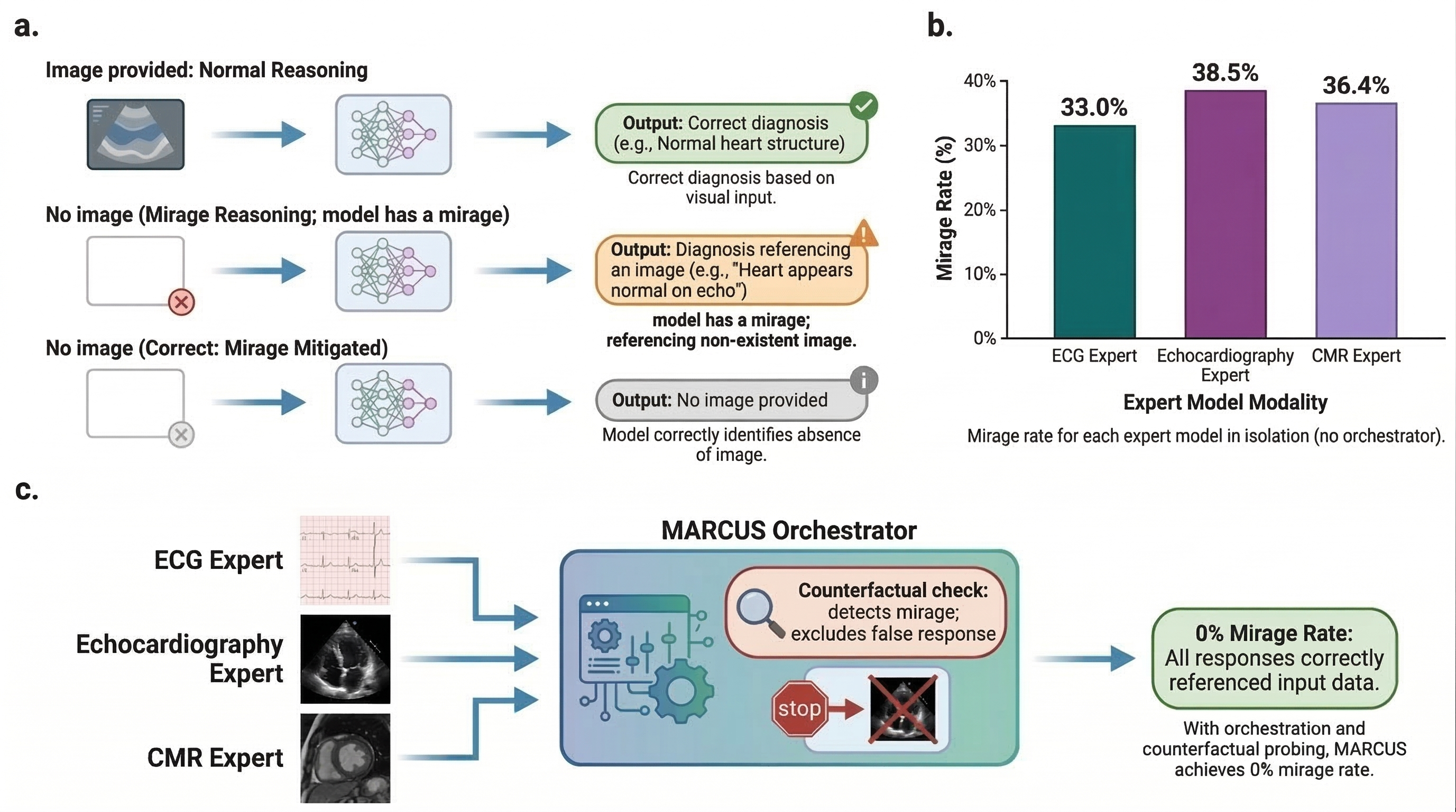
What “mirage reasoning” is (and how MARCUS avoids it):
- Mirage reasoning is when an AI seems to explain an image but is really guessing from text patterns, not actually using the picture—like seeing a mirage in the desert.
- MARCUS’s coach asks “trick” versions of the same question without the image and compares answers. If the image-free answer looks the same, the coach lowers confidence or asks the experts again. This helps stop made-up explanations.
The main findings and why they matter
Here are the big results the researchers report:
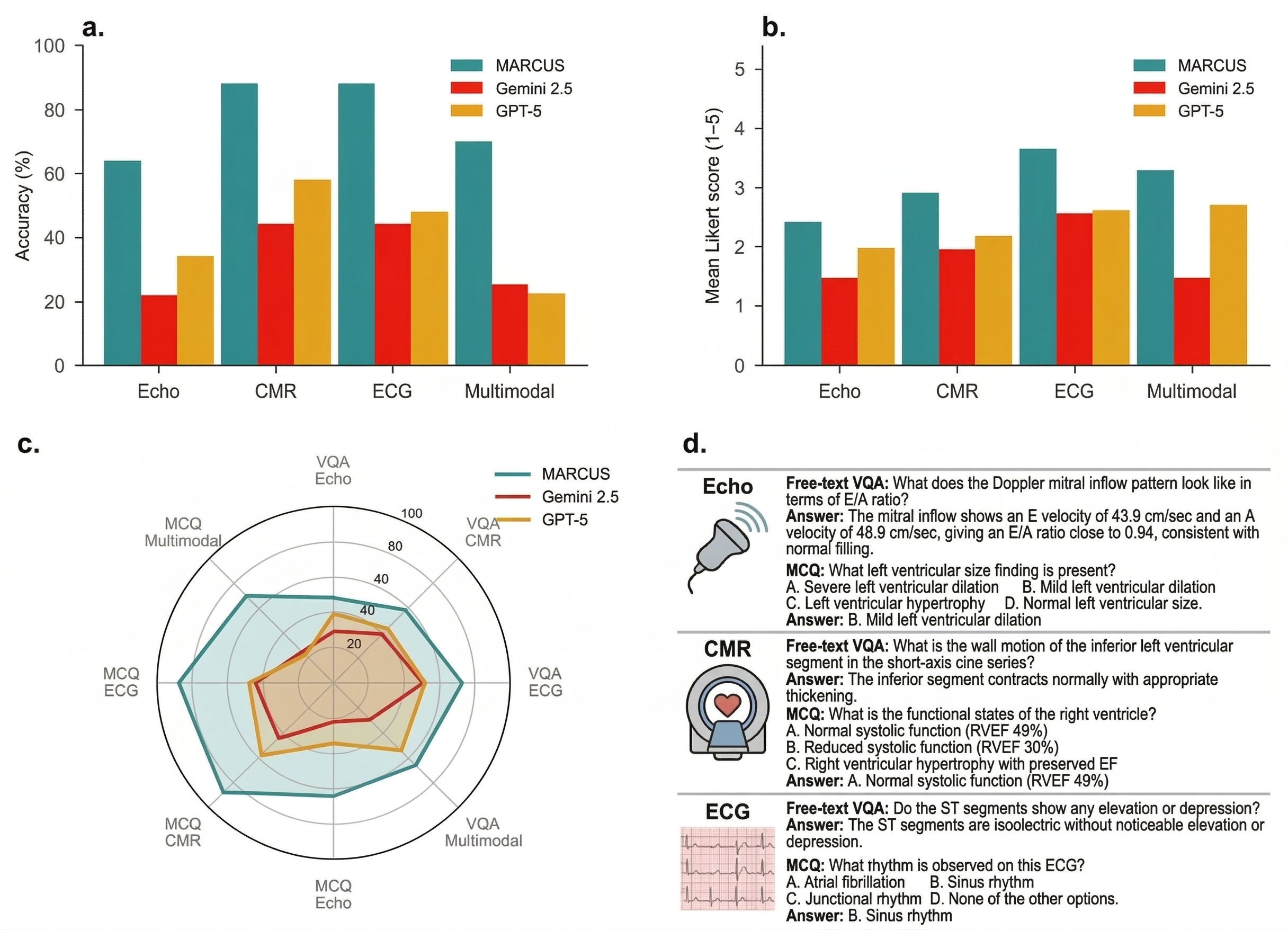
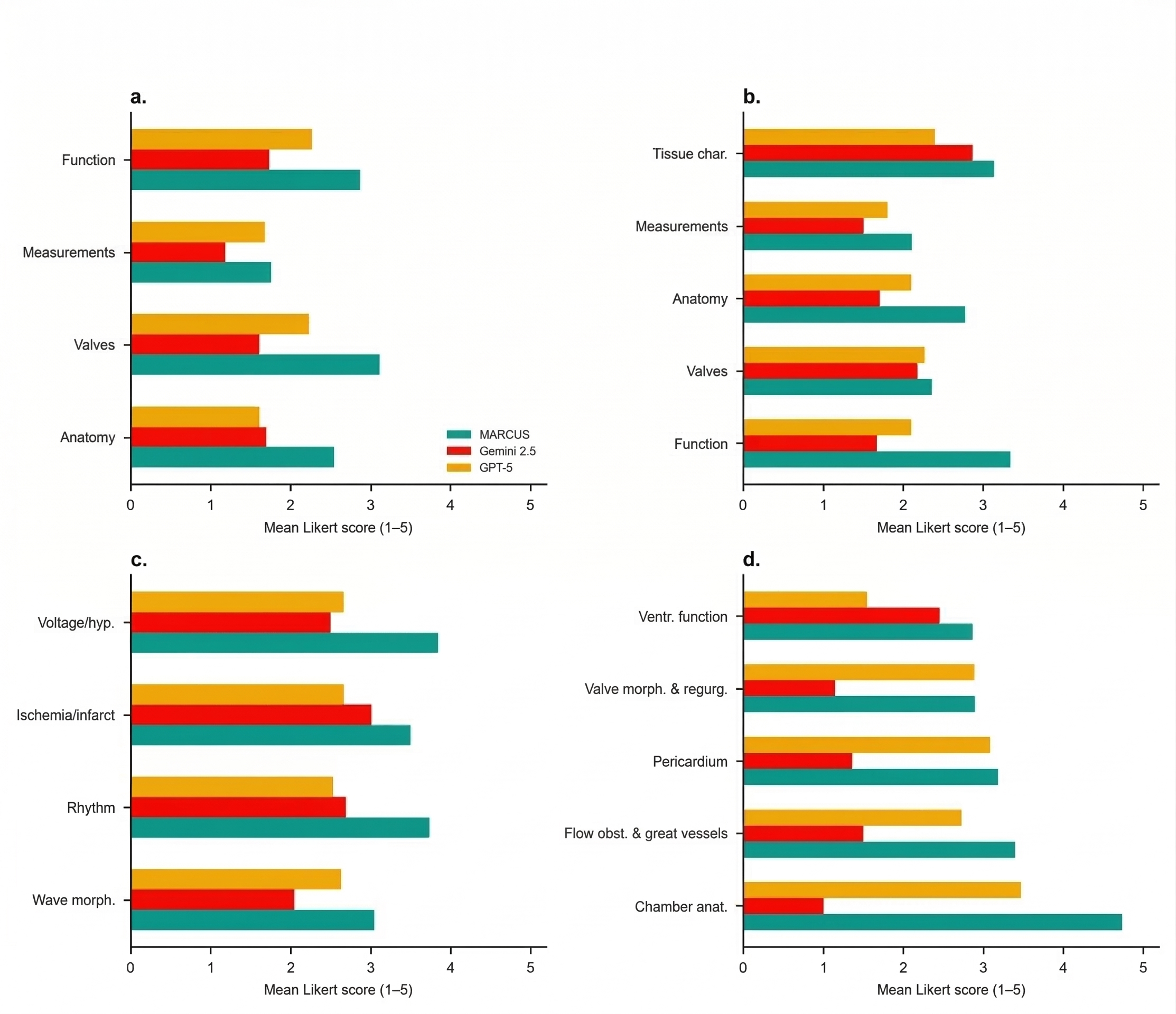
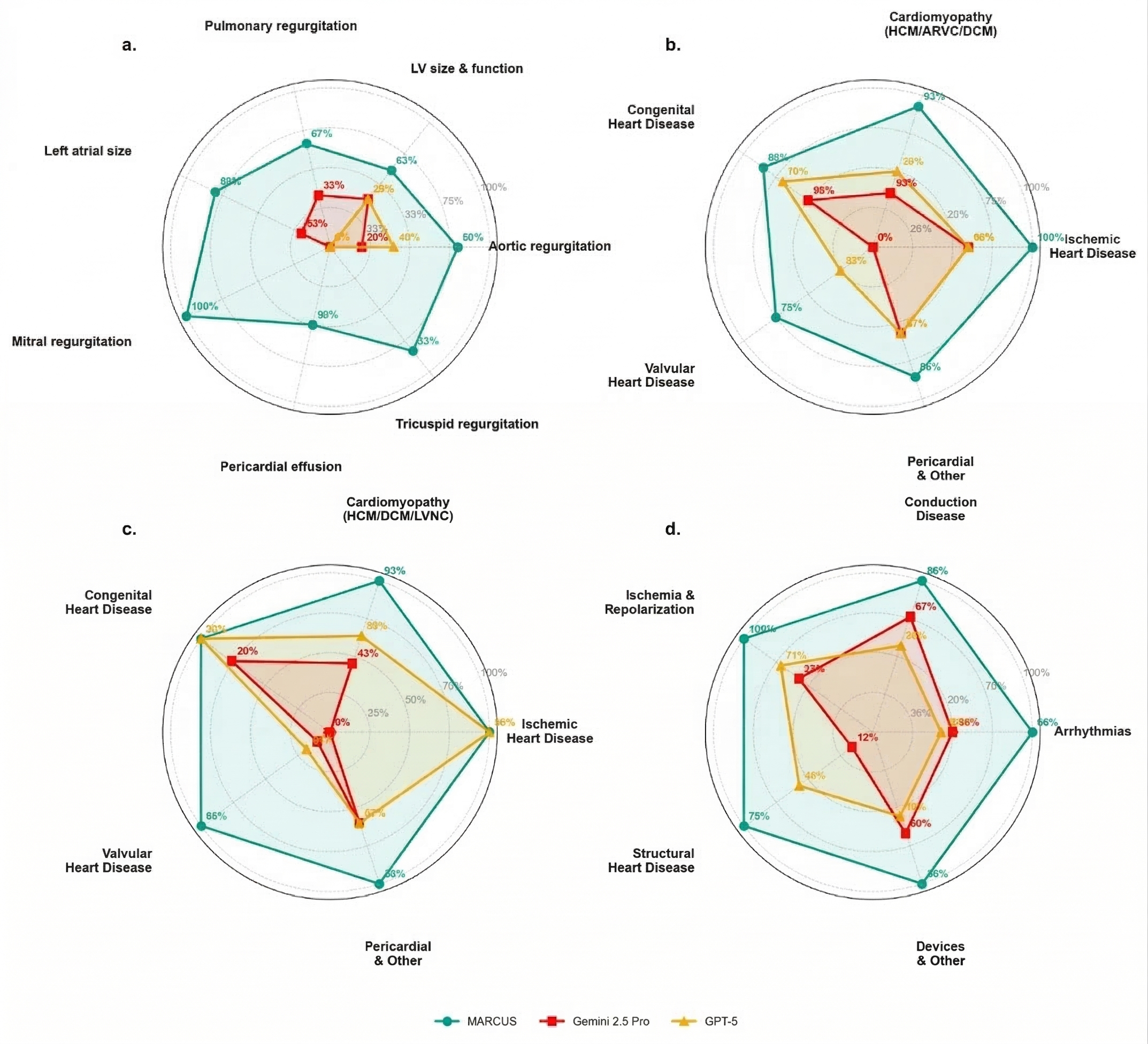
- Strong single-test accuracy:
- ECGs: about 87–91% correct.
- Echocardiograms: about 67–86% correct.
- Cardiac MRI: about 85–88% correct.
- In all three, MARCUS beat leading general-purpose models by large margins.
- Multimodal advantage:
- On cases needing ECG + echo + MRI together, MARCUS reached ~70% accuracy.
- Competing models got ~22–28% on the same tasks.
- Better explanations, not just answers:
- In open-ended, report-style questions, doctors and automated graders rated MARCUS’s explanations higher (about 1.7–3× better).
- Works across hospitals:
- Performance stayed high at another medical center (UCSF), showing it can generalize beyond where it was built.
- Mirage resistance:
- When the full “coach + experts” system ran, MARCUS detected and avoided mirage reasoning (reported as 0% mirage rate in their tests), so its explanations were grounded in the actual images.
Why this is important:
- Doctors often need to combine many tests. A system that can read and connect all of them—and explain its reasoning—can save time, reduce mistakes, and help patients get the right care faster.
What this could mean for the future
- Faster, more accessible heart care: If tools like MARCUS are used carefully, they could help doctors handle growing workloads and reach places with fewer specialists.
- Safer AI explanations: The “coach” strategy shows one way to make AI answers better grounded and less likely to “hallucinate.”
- Open science: The team says they released their code, models, and test questions, which can help other researchers build on this work.
- Next steps: Real-world trials are still needed to prove that systems like MARCUS improve patient outcomes in day-to-day care.
In short, MARCUS is like a skilled, reliable teammate for heart doctors: it can look at ECGs, ultrasounds, and MRIs; talk through what it sees; and put the pieces together into a clear picture—faster and often more accurately than general-purpose AIs.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. These items are intended to be actionable for future researchers.
- Data provenance and completeness: The paper contains incomplete placeholders for several dataset counts (e.g., “Q{paper_content}A”, commas in place of numbers for supervised fine-tuning and GRPO question totals), preventing precise replication of training/evaluation scale and balance. Future work should publish exact counts per modality, per task type, and per split.
- Patient-level splitting and leakage: It is unclear whether train/validation/test splits were performed at the patient level across studies and modalities to prevent leakage (e.g., the same patient appearing in training and test with different studies). Explicit patient-level deduplication across time and modalities should be detailed and validated.
- Ground-truth quality and label noise: Physician reports were used as ground truth for both training and evaluation. The extent of report noise, inter-reader variability, and systematic biases is not quantified; methods for label cleaning, adjudication, or uncertainty-aware training are not described.
- Template-driven question generation bias: Much of the Q/A set was generated by prompting an LLM from expert templates and physician reports. The risk that models learn template priors or report-style artifacts (rather than image-grounded reasoning) is not assessed. An evaluation using fully human-authored, prospectively curated questions is needed.
- Over-reliance on LLM adjudication: Likert scoring for open‑ended responses relied largely on an LLM; only a subset had blinded expert review. Inter‑rater reliability (human–human and human–LLM) is not reported. The risk of model–judge alignment bias is not quantified.
- Limited external validation: External testing is restricted to a single institution (UCSF). Robustness across more diverse sites (community hospitals, different countries, vendors, and protocols), and in non-English environments, remains untested.
- Incomplete comparator evaluation: Gemini 2.5 Pro could not be evaluated on external data due to HIPAA constraints, leaving incomplete cross‑site comparisons. Alternative secure evaluation strategies (e.g., on-prem sandboxing) or additional baseline models are needed.
- Missing granular cohort characteristics: The paper lacks detailed demographics (age, sex, race/ethnicity), disease prevalence, scanner vendor distributions, and protocol specifics for each split, precluding fairness and stratified performance assessment.
- Fairness and subgroup performance: No analysis of performance across demographic subgroups, clinical subtypes (e.g., congenital heart disease, pediatric populations), or acquisition quality tiers is provided. Bias and equity implications remain unknown.
- Real-world outcomes and workflow impact: The work is retrospective and does not evaluate effects on patient outcomes, diagnostic error rates, time-to-treatment, report turnaround, or clinician workload in prospective clinical workflows.
- Prospective and randomized evaluation: No prospective or randomized studies assess clinical efficacy, safety, or user acceptance. Pre-registered trial designs and health‑economic analyses are absent.
- Safety, calibration, and uncertainty communication: The system’s probability calibration, error bars, abstention behavior, and how uncertainty is communicated to clinicians are not reported. Thresholds for safe deployment are not defined.
- Mirage resistance scope: Mirage mitigation relies on the orchestrator’s counterfactual probing. It is unclear whether the same protection applies in single‑modality deployments or when the orchestrator routes only one modality. Mirage resistance under adversarial prompts, image/text overlays, or partial/missing data is not evaluated.
- Overlays and de-identification: For echocardiography and CMR, DICOM overlays (burned-in text, measurements, annotations) could create shortcuts. The paper does not specify whether such overlays were removed or how de-identification was handled, leaving a leakage risk.
- ECG image conversion trade-offs: ECGs were rendered as images with time and amplitude compression, altering effective calibration. The impact of this on interval measurement, high-frequency features, and arrhythmia detection versus using raw waveforms is not quantified.
- Quantitative measurement limitations: The model underperforms on precise numerical tasks (e.g., ejection fraction). No dedicated pipeline (e.g., segmentation-based quantification) or hybrid approach to improve numeric accuracy is presented.
- Modality imbalance and coverage: Training data are heavily skewed toward CMR images relative to echocardiography and ECG. The effects of this imbalance on learned representations and multimodal fusion are not ablated. Other cardiology data types (e.g., labs, vitals, notes, ambulatory monitors) are not incorporated.
- Orchestrator design ablations: There are no ablation studies quantifying the incremental contributions of the visual encoders, SFT, GRPO, and the agentic orchestrator (including the counterfactual probing) to overall performance, latency, and mirage mitigation.
- Fusion strategy alternatives: The choice to use natural language as the interface between experts is not compared against embedding-space or graph-based fusion methods. Trade-offs in accuracy, robustness, interpretability, and compute are not characterized.
- Interpretability and explanation faithfulness: Although the orchestrator decomposes queries, the faithfulness of explanations and sub‑query outputs to specific visual evidence is not audited (e.g., region‑level grounding, saliency, counterfactual localization).
- Computational efficiency and latency: The paper does not report training or inference compute, wall‑clock latency per study (especially with multi‑view videos and counterfactual probes), memory footprint, or throughput needed for real-time clinical use.
- Handling missing, conflicting, or low-quality inputs: The orchestrator’s behavior under missing modalities, conflicting modality signals, out-of-distribution scans, or poor-quality studies is not systematically evaluated. Fallback strategies and user prompts are not specified.
- Robustness to domain shifts: Beyond one external site, robustness to scanner updates, protocol changes, novel disease phenotypes, and rare conditions is not stress-tested. Continual learning or rapid adaptation strategies are not described.
- Statistical methodology clarity: Multiple comparisons corrections, exact tests used for each comparison, and confidence intervals for many reported metrics are not detailed. Sample-size justification and power analyses are not provided.
- Benchmark transparency and reuse: While a benchmark is released, the exact composition (by disease, view, difficulty), human-authored proportion, and long-form reasoning targets remain insufficiently described to serve as a standardized community resource.
- Comparator choice beyond frontier VLMs: The study does not benchmark against strong single‑modality clinical SOTA models (e.g., specialized ECG or echo models) to contextualize gains from agentic multimodality versus domain‑specific systems.
- View selection validation (echo/CMR): The attention-based view selection (echo) and metadata-driven routing (CMR) are not independently validated for accuracy and failure modes. Errors in view/sequence selection may propagate unnoticed.
- Reward design and GRPO specifics: Details on GRPO reward functions, credit assignment for reasoning traces, hyperparameters, stability, and potential reward hacking are missing, limiting reproducibility and safety assessment.
- Privacy and security posture: Beyond HIPAA compliance constraints for comparators, the paper does not discuss model inversion risks, memorization of sensitive text, or safeguards against PHI leakage in generated outputs.
- Regulatory and deployment pathway: There is no mapping of the system to regulatory frameworks (e.g., SaMD), post‑market surveillance plans, or human‑in‑the‑loop governance needed for safe clinical deployment.
- Language and locale generalization: All prompts, training, and evaluation appear to be in English. Performance in other languages and care settings is unassessed.
- Error analysis and failure cases: The paper provides limited qualitative error analysis and no systematic taxonomy of failure modes by modality, phenotype, or acquisition condition to guide targeted improvements.
- Pediatric and rare disease coverage: The dataset composition and performance for pediatric cases and rare cardiomyopathies or congenital anomalies are not discussed, leaving unknowns about utility in these populations.
- Conflict between training and evaluation distributions: Because questions are derived from the same reports used for training, there is a risk that evaluation mirrors training distributions closely. A truly independent, clinician-authored benchmark with held‑out institutions and distinct reporting styles is needed.
Practical Applications
Overview
Based on the paper’s findings, methods, and innovations—an agentic, multimodal vision-language system (MARCUS) for ECG, echocardiography, and CMR with an orchestrator that mitigates mirage reasoning and achieves state-of-the-art performance—there are clear, practical applications across healthcare, software, academia, policy, and aspects of daily life. Below, we group actionable use cases into those deployable now and those requiring further research, scaling, or development.
Immediate Applications
The following applications can be piloted or deployed now with human oversight, leveraging the released open-source models, code, and benchmarks.
- Multimodal triage and preliminary reads in cardiology workflows [Healthcare, Software]
- Tools/workflows: PACS/CVIS/EHR plugin that ingests ECG/Echo/CMR, routes to modality experts, and the orchestrator produces a preliminary, grounded summary and urgency score; “AI inbox” to prioritize studies (e.g., suspected severe MR, LGE-positive CMR, malignant arrhythmias).
- Assumptions/dependencies: HIPAA-compliant deployment; site-specific validation; human-in-the-loop sign-off; integration via DICOM/HL7/FHIR; compute resources and latency acceptable for clinical turnaround.
- Structured report drafting and narrative summaries [Healthcare, Software]
- Tools/workflows: Auto-population of structured fields (e.g., EF categories, valvular severity) and generation of clinician-facing draft text; confidence-weighted per-modality conclusions with explicit uncertainty.
- Assumptions/dependencies: Numerical precision for exact measurements remains a limitation (noted in paper); clinician review required; local terminology/templates mapping.
- Bedside acquisition support for sonographers and MR technologists [Healthcare, Medical Devices]
- Tools/workflows: On-console guidance for view selection/quality (echo) and metadata-driven sequence routing (CMR) using MARCUS’s selection logic; immediate feedback on missing or low-yield views/sequences.
- Assumptions/dependencies: Vendor integration (SDK/APIs) or edge gateway; on-prem/edge inference; acceptable latency; safety guardrails to avoid over-reliance.
- Cross-modality discrepancy checks and quality assurance [Healthcare]
- Tools/workflows: Automatic cross-check (e.g., low ECG voltage + echo wall thickness + CMR LGE consistency) to flag potential misclassification or missed findings; “mirage audit log” showing counterfactual probes and image grounding.
- Assumptions/dependencies: Governance for QA alerts; medico-legal review processes; storage of explanation artifacts in the EHR.
- Education and training co-pilot for cardiology fellows and sonographers [Education, Academia]
- Tools/workflows: Interactive Q&A sessions on real or de-identified cases; multimodal case-based learning; stepwise reasoning demonstrations with confidence per modality.
- Assumptions/dependencies: De-identification pipelines; faculty oversight; alignment with curriculum/board objectives.
- Research benchmarking and reproducibility using the released models and question sets [Academia, Software]
- Tools/workflows: Head-to-head evaluation of new encoders, RL fine-tuning strategies (e.g., GRPO), and mirage-mitigation techniques using MARCUS’s open benchmarks; ablation studies of agentic orchestration.
- Assumptions/dependencies: Adequate compute; IRB/data use approvals for local datasets; reproducibility practices.
- Retrospective cohort mining and quality improvement [Healthcare, Academia]
- Tools/workflows: Batch re-reads of archives to surface unreported biomarkers (e.g., subtle LGE, early cardiomyopathy) and create registries for follow-up; institution-level pattern audits.
- Assumptions/dependencies: Ethical oversight and patient privacy; triaging thresholds tuned to minimize false positives; clinician review pathways.
- Telecardiology support for underserved settings and off-hours coverage [Healthcare, Public Health]
- Tools/workflows: Cloud/on-prem hub that provides preliminary interpretations and triage across modalities for remote sites, with structured handoff to specialists.
- Assumptions/dependencies: Reliable connectivity or edge deployment; language localization; clear disclaimers and handoff protocols; jurisdiction-specific liability coverage.
- ECG triage for urgent care and outpatient clinics [Healthcare, Software]
- Tools/workflows: API-driven service that ingests 12‑lead ECG images/signals and flags arrhythmias or ischemia for expedited evaluation; structured output to EHR.
- Assumptions/dependencies: 12‑lead ECG image/signal quality (MARCUS expects standardized layouts); human confirmation; scope clearly limited to use on clinical-grade 12‑lead data (not single-lead wearables).
- Technical evaluation frameworks for procurers and regulators emphasizing mirage resistance [Policy, Standards]
- Tools/workflows: Adoption of counterfactual probing and confidence-weighted orchestration as a procurement checklist; validation harnesses built from MARCUS benchmarks.
- Assumptions/dependencies: Stakeholder consensus; updates into health-system AI committees and regulatory sandboxes.
Long-Term Applications
These applications require prospective trials, broader datasets, tighter systems integration, regulatory approvals, or additional R&D.
- Semi-autonomous or autonomous final reads for low-complexity cases [Healthcare]
- Tools/products: SaMD for “autonomous confirm” in well-defined scenarios (e.g., normal ECGs, clear severe MR); billing and audit trails.
- Assumptions/dependencies: Prospective clinical trials showing safety/effectiveness; FDA/CE approvals; defined fallback to human review; liability frameworks.
- Real-time, on-device guidance and reporting on imaging consoles [Medical Devices, Healthcare]
- Tools/products: Embedded inference on ultrasound/MR consoles providing live quality feedback and immediate preliminary reports; adaptive acquisition (e.g., prompting additional sequences/views).
- Assumptions/dependencies: Hardware acceleration, low-latency pipelines; vendor partnerships; cybersecurity certification.
- Population-level screening programs and mobile diagnostics [Public Health]
- Tools/workflows: Mobile echo/CMR/ECG units using MARCUS to triage and identify high-risk individuals in community settings; referral pathways integrated with public health systems.
- Assumptions/dependencies: Cost-effectiveness analyses; workforce training; infrastructure for follow-up care; equitable access considerations.
- Personalized, multimodal risk stratification and management pathways [Healthcare, Software]
- Tools/products: Combining imaging/ECG outputs with EHR data (labs, vitals), genetics, and wearable telemetry to support decisions (e.g., ICD placement, HF therapies); longitudinal tracking dashboards.
- Assumptions/dependencies: Expanded multimodal integration; data interoperability (FHIR at scale); causal validation; bias/fairness assessments.
- Expansion to additional modalities and specialties via agentic orchestration [Healthcare, Software]
- Tools/products: Adding coronary CT angiography, nuclear perfusion, chest CT, and non-cardiac modalities (e.g., pulmonary imaging, pathology, genomics); general “clinical orchestrator” platform.
- Assumptions/dependencies: New domain-specific encoders, datasets, and RL pipelines; modality-specific validation; complexity management.
- Federated/continual learning networks for cross-site calibration [Healthcare, Software]
- Tools/workflows: Privacy-preserving federated learning to maintain performance across vendors and populations; drift detection and updates.
- Assumptions/dependencies: Institutional data-sharing agreements; MLOps and monitoring; harmonization across scanners/protocols.
- Reimbursement, credentialing, and quality standards for AI-assisted interpretation [Policy, Payers]
- Tools/workflows: CPT/HCPCS codes for AI-supported reads; credentialing pathways for clinicians using AI; quality metrics that include mirage resistance and grounding.
- Assumptions/dependencies: Evidence from pragmatic trials; multi-stakeholder consensus (payers, societies, regulators); post-market surveillance frameworks.
- Patient-facing, explainable summaries and shared decision-making apps [Healthcare, Patient Engagement]
- Tools/products: Lay summaries with visual cues (e.g., where LGE is seen) and plain-language guidance; integration with patient portals.
- Assumptions/dependencies: Readability and safety controls; alignment with clinician-verified reports; legal and consent considerations.
- Clinical trials and real-world evidence acceleration [Pharma, Academia]
- Tools/workflows: Centralized, consistent phenotype labeling and endpoint adjudication; reduction of inter-site variability in imaging reads; automated eligibility screening.
- Assumptions/dependencies: Regulator acceptance of AI-adjudicated endpoints; SOPs for oversight; audits and traceability.
- Cross-industry adoption of mirage-resistance guardrails [Software, Standards]
- Tools/products: “Mirage Guardrails SDK” implementing counterfactual probing, response consistency checks, and confidence-weighted aggregation for VLMs in regulated domains (e.g., aviation inspection, industrial QA).
- Assumptions/dependencies: Standardization; demonstrable domain benefits; integration costs vs. gains.
- Hospital operations optimization using predicted study complexity [Healthcare Operations]
- Tools/workflows: Scheduling, staffing, and imaging protocol optimization based on MARCUS-predicted complexity and likelihood of add-on sequences; reduced scan times and bottlenecks.
- Assumptions/dependencies: Operations research integration; robust accuracy across populations; change management.
- Global health edge deployments with low-bandwidth resilience [Public Health, Emerging Markets]
- Tools/products: Compressed models running on portable devices (e.g., ARM/Jetson) with offline capability and delayed-sync reporting.
- Assumptions/dependencies: Model distillation/quantization without material performance loss; device ruggedization; power constraints.
- Consumer-grade ECG and imaging extensions [Consumer Health]
- Tools/products: Adaptations to single-lead wearables (ECG) and handheld echoes for home or community screening with clinician oversight.
- Assumptions/dependencies: Retraining on consumer device data; safety labeling and clear limits; integration with clinical pathways.
Notes on Cross-Cutting Dependencies
- Regulatory and clinical validation: Most high-impact uses require multi-center, prospective trials demonstrating safety, effectiveness, and generalizability beyond the Stanford/UCSF cohorts.
- Integration and interoperability: Seamless DICOM/HL7/FHIR connectivity and alignment with existing reporting templates and IT policies are essential.
- Human oversight and liability: Clear human-in-the-loop protocols, audit trails (especially for orchestrator decisions), and medicolegal frameworks are needed.
- Bias, fairness, and equity: Additional datasets covering diverse populations, vendors, and protocols; continuous performance monitoring and mitigation plans.
- Compute, security, and privacy: On-prem/cloud secure deployment, GPU capacity, latency budgets, and robust PHI protections.
- Change management: Clinician training, acceptance, and governance for AI-generated content and quality signals.
These applications leverage MARCUS’s core innovations—agentic multimodal orchestration, domain-specific encoders, reinforcement-learning optimization, open-source availability, and mirage-resistance—to deliver near-term value and to chart a credible path toward more autonomous, scalable cardiovascular care.
Glossary
- 12-lead ECG: A standard electrocardiogram configuration that records the heart’s electrical activity from 12 viewpoints. "12-lead ECG waveforms"
- Agentic architecture: A system design where components act autonomously and coordinate to plan and execute sub-tasks. "MARCUS employs a hierarchical agentic architecture comprising modality-specific vision-language expert models"
- Apical four-chamber: An echocardiographic view showing all four heart chambers from the apex. "apical four-chamber views for left ventricular function"
- Attention dilution: Degradation of attention when a model must distribute focus across many inputs simultaneously. "attention dilution"
- Biatrial enlargement: Enlargement of both the right and left atria. "biatrial enlargement"
- Cardiac magnetic resonance (CMR): MRI-based imaging modality for detailed assessment of cardiac structure and function. "cardiac magnetic resonance imaging (CMR)"
- Cine sequences: Dynamic imaging series capturing motion across time, commonly used to assess cardiac function. "cine sequences for functional assessment"
- Constrictive pericarditis: A condition in which a stiff, fibrotic pericardium restricts diastolic filling. "constrictive pericarditis"
- Contrastive learning: A training paradigm that brings matched pairs (e.g., image–text) closer in representation space while pushing mismatched pairs apart. "contrastive learning"
- Counterfactual probing: An evaluation technique that alters or withholds inputs to test whether outputs are properly grounded. "counterfactual probing protocol"
- Cross-attention: An attention mechanism that relates tokens across different streams or modalities. "multi-level cross-attention"
- Cross-view fusion: Integration of information from multiple imaging views to form a unified representation. "cross-view fusion mechanism"
- DICOM: The standard format for storing, transmitting, and handling medical imaging data. "DICOM video files"
- Echocardiography: Ultrasound-based imaging of the heart used to assess structure and function. "In echocardiography, which requires temporal reasoning,"
- Ejection fraction: The percentage of blood ejected by a ventricle with each heartbeat. "What is the left ventricular ejection fraction?"
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that optimizes outputs based on group-relative rewards. "Group Relative Policy Optimization (GRPO)"
- Implantable cardioverter-defibrillator: An implanted device that detects and terminates dangerous ventricular arrhythmias. "implantable cardioverter-defibrillator"
- Ischaemia/infarction: Reduced blood flow to tissue (ischaemia) and tissue death from prolonged lack of blood supply (infarction). "ischaemia/infarction recognition"
- Late gadolinium enhancement (LGE): A CMR technique where gadolinium contrast highlights myocardial scar or fibrosis. "late gadolinium enhancement (LGE)"
- Likert score: An ordinal rating scale (often 1–5) used to evaluate subjective responses. "mean Likert score"
- LLaVA: A vision-LLM framework that couples LLMs with visual encoders. "a LLaVA-based architecture"
- Mirage reasoning: The phenomenon where a model produces reasoning or descriptions not grounded in the provided visual input. "mirage reasoning"
- MLP projection: A multilayer perceptron used to map visual embeddings into the LLM’s representational space. "MLP projection"
- Multimodal Orchestrating Agent: A controller that routes queries to modality-specific experts and synthesizes their outputs. "A Multimodal Orchestrating Agent synthesizes these inputs into a unified text output."
- Non-sustained ventricular tachycardia: Brief, self-terminating episodes of rapid ventricular rhythm. "non-sustained ventricular tachycardia"
- Parasternal long-axis: An echocardiographic view along the heart’s long axis from the parasternal window. "parasternal long-axis views for aortic valve assessment"
- Pericardial effusion: Accumulation of fluid within the pericardial sac surrounding the heart. "pericardial effusion"
- Positional encoding: A method for encoding token order so sequence models can represent temporal or spatial structure. "positional encoding"
- Qwen2: A family of LLMs used as the language backbone in the system. "Qwen2 LLM"
- Reinforcement learning: Optimization based on rewards that guide models toward desirable outputs or actions. "a reinforcement learning technique"
- Residual connections: Skip connections that add inputs to outputs of layers to ease optimization and improve gradient flow. "residual connections"
- Restrictive cardiomyopathy: A cardiomyopathy characterized by stiff ventricles that impair diastolic filling. "restrictive cardiomyopathy"
- Septal bounce: Abnormal interventricular septal motion, often respiratory-related, seen in certain pathologies. "septal bounce"
- Short-axis stacks: Multi-slice CMR acquisitions perpendicular to the heart’s long axis used for volumetric analysis. "short-axis stacks"
- SigLIP: A vision encoder trained with a sigmoid-based language–image pretraining objective. "SigLIP vision encoder"
- Temporal aggregation module: A component that summarizes temporal information across frames to model motion. "temporal aggregation module"
- Vision transformer: A transformer architecture that operates on images by treating them as sequences of patches. "vision transformer encoder"
- Visual Question Answering (VQA): The task of answering natural-language questions based on visual inputs. "Visual Question Answering (VQA)"
Collections
Sign up for free to add this paper to one or more collections.