- The paper introduces an information-theoretic proof that structured table data maintains periodic, non-decaying mutual information, enabling robust long-context reasoning in LLMs.
- The TableLong pipeline synthesizes diverse, multilingual, and multi-table data that stimulates effective RL training, resulting in significant retrieval and multi-hop reasoning improvements.
- Empirical evaluations show average performance gains of around 8% across state-of-the-art models, with near-perfect retrieval accuracy on challenging benchmarks.
Structured Table Data for Long-Context Reasoning: Mechanisms and Empirical Efficacy
Mathematical Foundations of Tabular Dependency
The paper provides an information-theoretic characterization of tabular data's long-context dependencies, contrasting it with natural language. Natural language exhibits power-law decay in mutual information between tokens across distances, resulting in vanishing dependencies at large context lengths. In contrast, the authors mathematically prove that structured table data maintains periodic non-vanishing dependencies due to columnar semantic consistency and distribution distinctiveness. The periodic peaks occur at multiples of the column count, resulting in an asymptotically non-decaying mutual information profile.
These results imply a distinct advantage for training LLMs on tabular data: structured tables can incentivize RL objectives over arbitrarily long contexts without suffering the informational attenuation seen in natural language. Furthermore, the effective dependency distance for tabular data diverges, suggesting infinite recurrence of salient dependencies, whereas text loses them after a threshold.
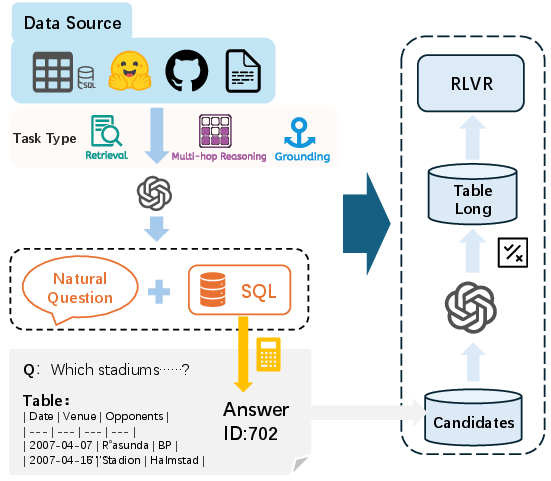
Figure 1: Overview of TableLong: An end-to-end table data construction pipeline for long-context reasoning.
TableLong Pipeline: Scalable Data Construction for RL
Leveraging their theoretical analysis, the authors develop TableLong, a scalable pipeline for synthesizing diverse, verifiable, and structurally rich table data tailored for RL-based long-context reasoning. The pipeline aggregates real-world tables from heterogeneous domains, constructs executable SQL environments, synthesizes a broad spectrum of reasoning tasks (precise retrieval, multi-hop aggregation, multi-table grounding), and applies a consistency-based filter to maximize learning efficacy and eliminate trivial or ambiguous tasks.
TableLong supports multilingual and long-format tables—producing RL samples with context lengths spanning up to 32k tokens and multi-table scenarios for grounding.
Empirical Assessment: Robustness and Generalization
The empirical evaluation covers multiple state-of-the-art backbone models, including Qwen and Deepseek variants, assessed on comprehensive benchmarks: LongBench-v2, Loong, BrowsCompLong, MRCR, GSM-Infinite, Oolong-Synth, Ruler, GPQA-Diamond, AIME 2025, MultiChallenge, and LiveCodeBench. RL post-training with TableLong yields pronounced performance gains in long-context reasoning across all models (average improvement of +8.24% for Deepseek-R1-Distill-32B, +8.93% for Deepseek-R1-Distill-14B), with marked robustness in out-of-domain scaling (+8.06% average OOD improvement).
Significant retrieval improvements are demonstrated by the "Needle in a Haystack" benchmark, where the 32B backbone's accuracy rises from 87.95% to 99.40% (near-perfect), and the 14B backbone from 69.30% to 91.20%. These gains are attributable to the periodic non-vanishing dependencies in table data, as well as induced multi-hop and grounding behavior via token sequence linearization.
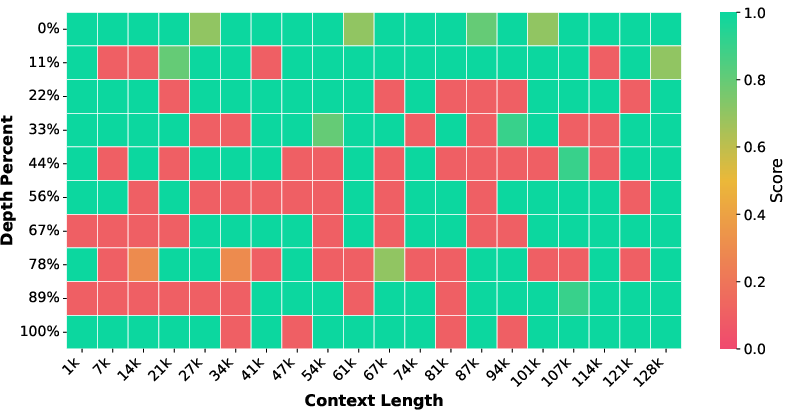
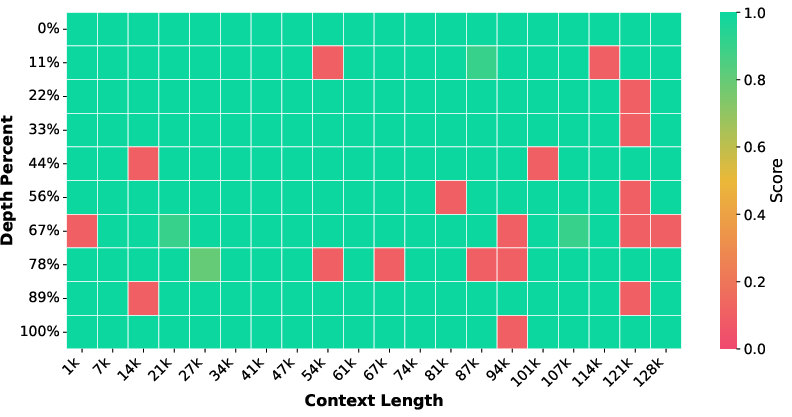
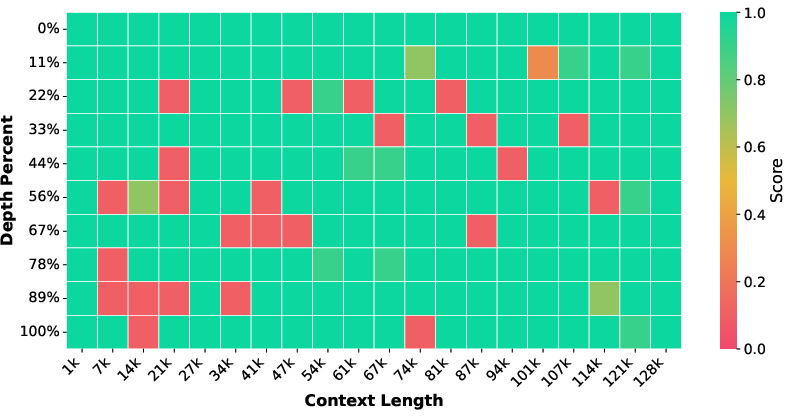
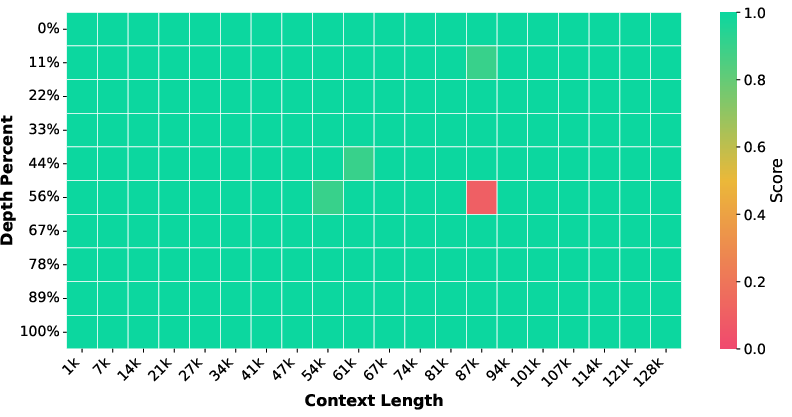
Figure 2: Needle in a Haystack retrieval across document depths. TableLong substantially enhances long-context robustness, boosting model accuracy to near-perfect levels.
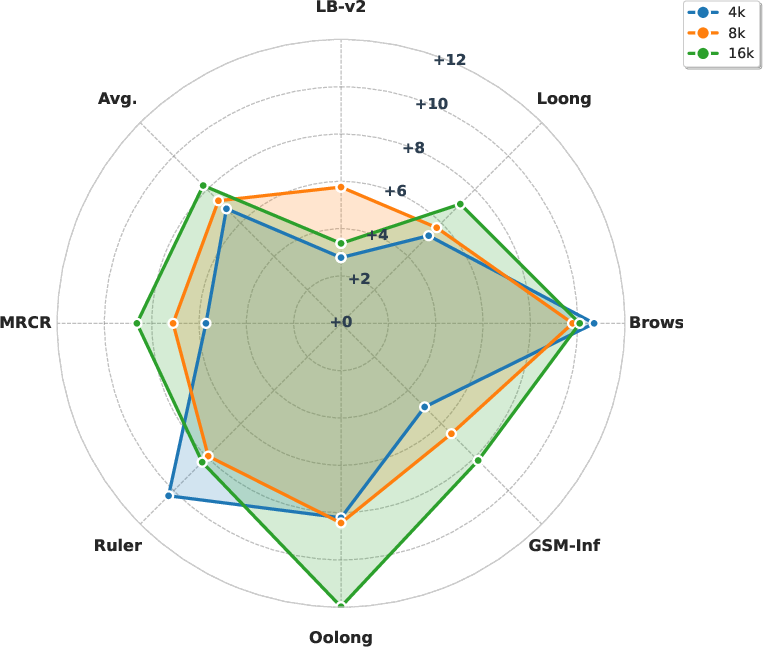
Figure 3: Radar visualization of long-context reasoning benchmarks for DS-R1-Distill-32B, showing consistent improvements with scalable table data.
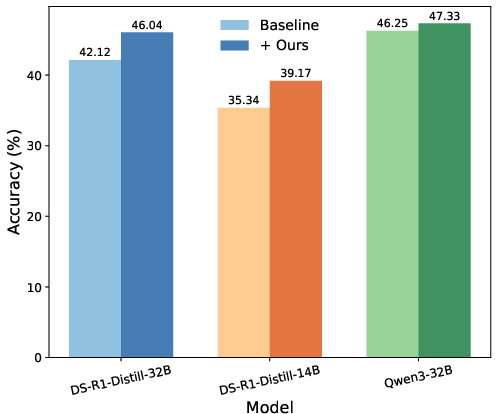
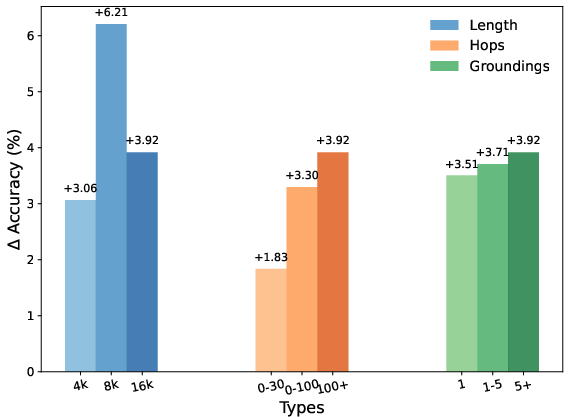
Figure 4: Performance comparison on the 16k+ length range of LongBench-v2, validating length scalability and extrapolation.
Structural Decomposition and Mechanistic Insights
The authors conduct detailed ablation studies to dissect the sources of long-context reasoning gains. Experiments on semantic-agnostic tables reveal that even in the absence of meaningful cell content, structural organization confers a +1.67% improvement relative to baseline, validating the primacy of periodic structure. Semantics, however, are essential for maximal gains, supporting complex reasoning signal propagation. Further, removal of visible delimiters or addition of random noise yields negligible performance drops (<1%), affirming that delimiter visibility is not a critical determinant, and the intrinsic structure dominates RL signal.
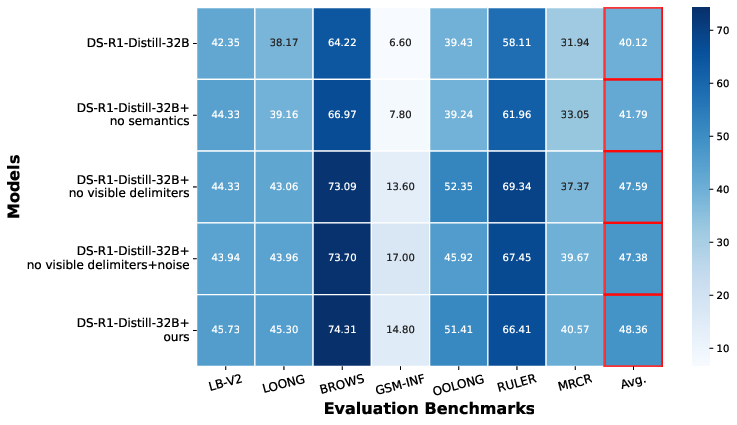
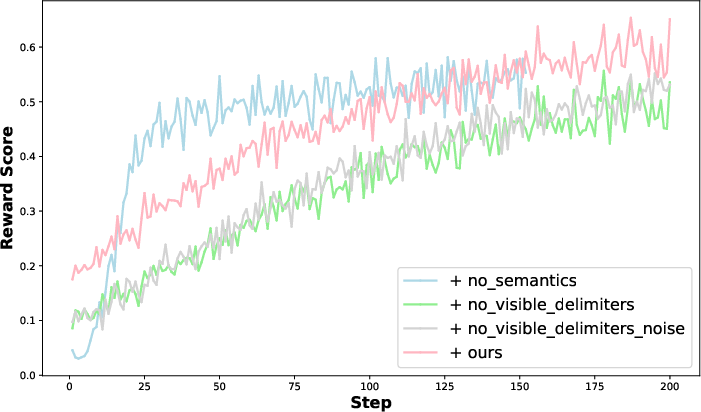
Figure 5: Impact of semantics, delimiters, and noise—structural properties are the primary drivers, with semantics needed for peak results.
Multi-hop reasoning and grounding capabilities are also quantified. Table linearization induces non-adjacency, requiring models to attend to widely separated tokens, thereby simulating multi-hop reasoning. Scaling up the number of involved cells or tables improves performance on OOD benchmarks, confirming that increasing complexity and distributed grounding signals stimulate attention and reasoning over long contexts.
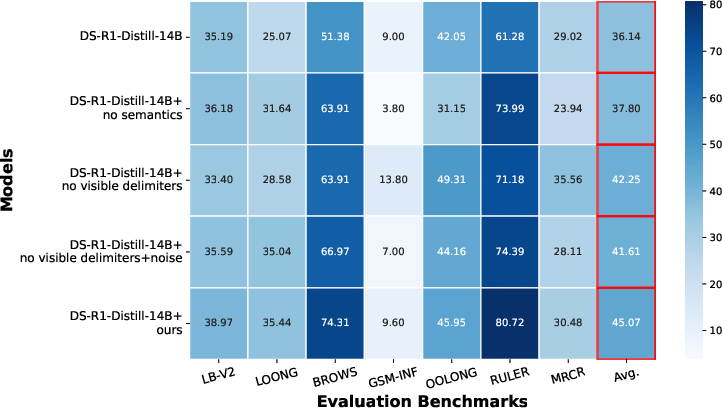
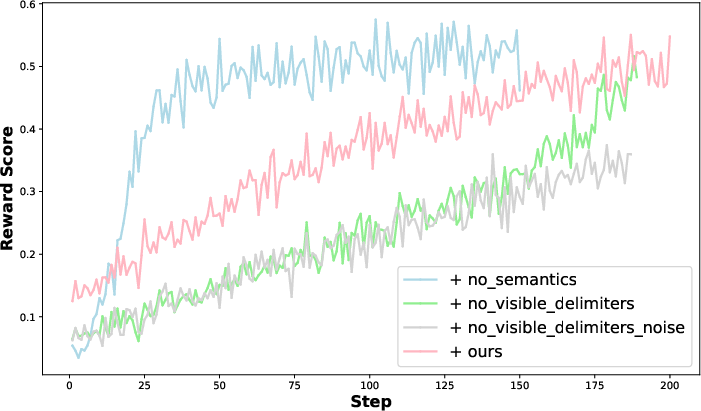
Figure 6: Decomposition experiments: structure remains key for long-range dependencies, while semantics drive complex reasoning. Delimiters and noise minimally affect intrinsic structural gains.
Practical and Theoretical Implications
The presented results substantiate table data's efficacy as post-training material for scaling LLMs' long-context reasoning capability within RL frameworks. These insights indicate that careful data design—beyond generic pre-training or synthetic text—can unlock superior retrieval, grounding, and extrapolation abilities in LLMs. Practically, TableLong provides a blueprint for scalable verifiable data synthesis supporting multi-domain and multilingual RL objectives.
Theoretically, the mutual information analysis predicts that other data modalities with structured, periodic, or non-decaying dependencies (e.g., graphs, document hierarchies) could similarly enhance long-context reasoning, inviting future explorations beyond tabular formats.
Conclusion
This work delivers a rigorous information-theoretic perspective on the structural advantages of table data for long-context reasoning in LLMs. Through mathematical proof and comprehensive empirical study, it demonstrates that scalable structured tables—when synthesized and filtered via TableLong—produce significant gains in retrieval, multi-hop reasoning, and OOD generalization. The findings establish periodic non-vanishing dependency as a key property for RL post-training. Future research should generalize these principles to other structured modalities and algorithmic paradigms to further advance robust long-context capabilities in LLMs.

