PRISM: Breaking the O(n) Memory Wall in Long-Context LLM Inference via O(1) Photonic Block Selection
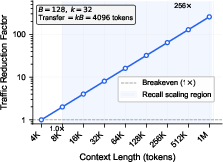
Abstract: Long-context LLM inference is bottlenecked not by compute but by the O(n) memory bandwidth cost of scanning the KV cache at every decode step -- a wall that no amount of arithmetic scaling can break. Recent photonic accelerators have demonstrated impressive throughput for dense attention computation; however, these approaches inherit the same O(n) memory scaling as electronic attention when applied to long contexts. We observe that the real leverage point is the coarse block-selection step: a memory-bound similarity search that determines which KV blocks to fetch. We identify, for the first time, that this task is structurally matched to the photonic broadcast-and-weight paradigm -- the query fans out to all candidates via passive splitting, signatures are quasi-static (matching electro-optic MRR programming), and only rank order matters (relaxing precision to 4-6 bits). Crucially, the photonic advantage grows with context length: as N increases, the electronic scan cost rises linearly while the photonic evaluation remains O(1). We instantiate this insight in PRISM (Photonic Ranking via Inner-product Similarity with Microring weights), a thin-film lithium niobate (TFLN) similarity engine. Hardware-impaired needle-in-a-haystack evaluation on Qwen2.5-7B confirms 100% accuracy from 4K through 64K tokens at k=32, with 16x traffic reduction at 64K context. PRISM achieves a four-order-of-magnitude energy advantage over GPU baselines at practical context lengths (n >= 4K).
 Memory Wall in Long-Context LLM Inference via O(1) Photonic Block Selection")
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What’s this paper about?
This paper looks at why today’s LLMs slow down when they have to handle very long inputs (like whole books or many documents at once). The main problem isn’t the math the model does—it’s all the memory it has to read through at every step. The authors propose a new, light‑based (photonic) gadget called PRISM that quickly picks only the useful chunks of memory to read, instead of scanning everything. That way, the model can keep up even when the context (the amount of text it’s considering) gets huge.
The big questions the paper asks
- Can we stop LLMs from scanning all their stored memories (the “KV cache”) every time they generate a new word?
- Is there a faster way—using light—to find the small set of memory blocks that actually matter for the next step?
- If we do this with light, will it still be accurate and reliable even with real‑world hardware imperfections?
- How much faster and more energy‑efficient is this compared to doing it all on a GPU?
How PRISM works (in everyday terms)
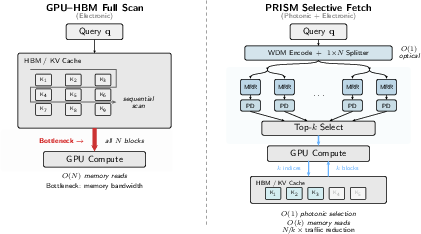
Think of the model’s stored information (the KV cache) as a giant library of “blocks.” Today, for each new word, many systems skim the whole library to score how relevant each block is—this takes lots of time and memory bandwidth.
PRISM changes that by using light to do the “which blocks are most relevant?” part in one go.
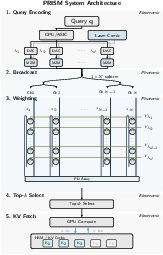
Here’s a simple analogy for PRISM’s five steps:
- Turn numbers into colors of light
- The model makes a short “query sketch” (a small vector that represents what it needs next).
- Each number in this sketch is encoded as the brightness of a different color (wavelength) of light. Imagine a rainbow where each color’s brightness stands for a number.
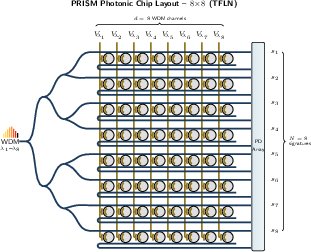
- Split the light to many paths at once
- The rainbow beam is passively split into lots of identical copies—one for each memory block. This is super fast because it’s just light splitting, not reading lots of memory chips one by one.
- Each path has tiny “rings” that act like adjustable knobs
- Along each path, there are microring resonators—tiny circular waveguides that let certain colors through more or less, like a set of volume knobs tuned to specific colors. These knobs are preset to represent each block’s “signature.”
- Add up the brightness to score similarity
- A photodetector at the end of each path measures the total light (summing across colors). This sum is really a “similarity score,” telling you how well the query matches that block. The magic: all blocks get scored at the same time.
- Pick the top matches and fetch only those
- A small electronic sorter picks the best k blocks (like the top 32), and the system only fetches those from memory. That cuts down the memory traffic a lot.
Why this is powerful:
- In electronics, scanning N blocks takes time that grows with N (this is “O(n)”).
- In PRISM, broadcasting light and measuring happens in a constant swoop (this is “O(1)” for the selection step). As contexts get longer (more blocks), the photonic selection time barely changes.
What did they measure and how?
The authors:
- Built a detailed design for a photonic similarity engine on a thin‑film lithium niobate (TFLN) chip.
- Modeled real hardware imperfections: limited precision (only 4–6 bits), tiny temperature drifts, loss of light in waveguides, detector noise, and crosstalk between colors.
- Tested how well the system can find the right blocks using a “needle‑in‑a‑haystack” task with a real LLM (Qwen2.5‑7B). In that task, the model must find a specific fact hidden somewhere in a long context.
- Explored different ways to make compact “signatures” for each block (like averaging keys or projecting to fewer dimensions), because the photonic engine only needs to rank blocks, not do full exact attention.
Two key ideas they use:
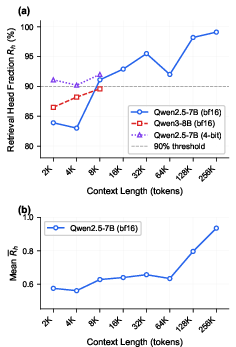
- Only some attention “heads” really look far back in the text (these are “retrieval heads”). PRISM focuses on those heads; the others mainly look at nearby words and can use small, local windows.
- Signatures don’t need super‑high precision—just the right order (rank). That makes the photonic hardware simpler and more practical.
Main findings and why they matter
- Accurate block selection at long contexts:
- On the needle‑in‑a‑haystack test with Qwen2.5‑7B, PRISM’s selected blocks matched full attention accuracy from 4K up to 64K tokens when choosing the top 32 blocks (k=32).
- At 64K tokens, PRISM cut memory traffic by about 16× because it only fetched those top blocks.
- Big energy savings:
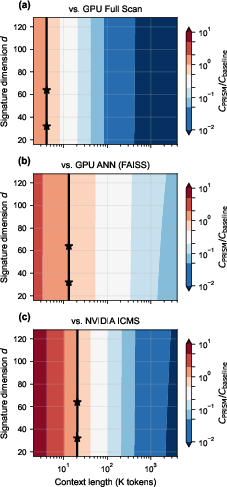
- For realistic, long contexts (≥4K tokens), PRISM’s selection step used roughly 1,000–10,000× less energy than scanning on a GPU (depending on the exact baseline). That’s a huge win for data centers and on‑device AI.
- Very low selection latency:
- The photonic selection itself takes on the order of nanoseconds—much faster than microsecond‑scale electronic scans—so the slow part becomes the actual memory fetch, not the selection.
- Robust to hardware imperfections:
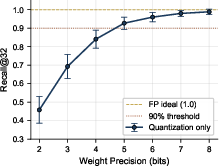
- Even with only 5–6 bits of precision and small device drifts, ranking quality stayed high (recall drop <10% in their models), which is good enough for picking the right blocks.
- Advantage grows with context length:
- The longer the context (more blocks), the worse electronics do (scan time grows), but PRISM’s selection time stays about the same. That means the benefit gets bigger as models read more.
- Most attention “heads” actually benefit:
- Their profiling (for their chosen threshold) found that a large fraction of heads behave like “retrieval heads,” so there’s a “double win”: more heads use PRISM and each one saves more as context grows.
What this could change
- Longer, cheaper contexts: PRISM could make it practical to run LLMs with very long inputs without huge slowdowns or energy bills.
- Better system design: Instead of building ever‑bigger compute, systems can speed up by fixing the real bottleneck—memory access—using a specialized photonic selector.
- Works alongside GPUs/DPUs: PRISM doesn’t replace GPUs; it sits next to them and tells them which blocks to read. That means it can be added to future AI servers to reduce memory traffic and power.
- Scales with the future: As we push toward million‑token contexts, PRISM’s constant‑time selection becomes more valuable.
In short, this paper shows a clever division of labor: let fast, passive optics “look” at everything in parallel to pick candidates, then let electronics do exact attention on just a few blocks. That breaks the “memory wall” that slows long‑context LLMs and opens the door to faster, greener AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up research:
- Hardware validation gap: No fabricated PRISM/TFLN prototype is presented—claims (SNR, recall, latency, energy) are based on models and simulations. Experimental verification of the complete photonic-electronic pipeline (laser comb, splitter tree, MRR banks, balanced photodetection, TIAs/ADCs, top‑k logic) is missing.
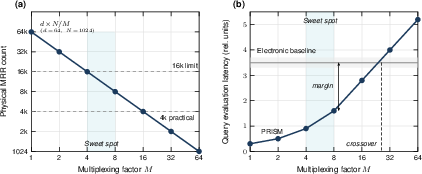
- ADC/TIA scalability and realism: The energy/latency model assumes 2N balanced PD channels with TIAs and ADCs operating at ~1 GHz yet totals only ~100 mW/900 pJ per query for TIAs+ADCs. This appears to undercount power/area for large N (e.g., N=1024 implies ~2k ADCs/TIAs). A realistic accounting of per-channel TIAs/ADCs (power, area, ENOB, bandwidth) and their scaling is needed.
- Top‑k comparator scaling: The assumed ~5 ns latency and modest power for top‑k selection are not validated for large N (103–104). Architecture and synthesis results for scalable partial-sorting hardware, including wire/fan‑in constraints and clocking, are not provided.
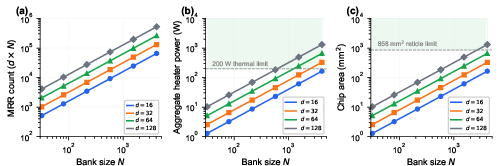
- O(1) claim vs physical scaling: While selection latency is independent of N, the hardware footprint (MRRs, PDs, ADCs, splitters) and likely dynamic power scale with N. A thorough energy/area scaling analysis versus N (including banked designs) is absent, leaving uncertainty about practical limits.
- Laser power and RIN: Link budget assumes high-power laser combs (e.g., 100 mW total) but does not model laser relative intensity noise (RIN), line-to-line power variation, or long-term stability. How RIN and flatness affect ranking reliability and SNR at scale remains unquantified.
- WDM/channel plan feasibility: The choice of MRR radius/FSR, 1.6 nm channel spacing, and d=32–128 within the C-band is presented without a detailed plan for avoiding spectral collisions across periodic resonances as d grows. Crosstalk/isolation targets and ring dispersion over the entire comb are not experimentally verified.
- Closed-loop calibration and drift control: The paper assumes TFLN EO tuning (fast, capacitive) but does not specify per-ring closed-loop control architectures to counter thermal drift, photodiode drift, or laser drift. Practical calibration/update overheads and stability over hours/days are uncharacterized.
- Thermal management at scale: A fixed 1 W TEC overhead is assumed, but the thermal load and stabilization requirements for large N and many banks (and multiple chips) are not quantified. Thermal gradients, crosstalk, and their impact on ring detuning and ranking fidelity remain open.
- Yield and redundancy: No discussion of device yield for tens to hundreds of thousands of MRRs, defective rings, or strategies for remapping/repair (e.g., spare rings, programmable routing) is provided. The recall impact of yield-induced sparsity/crosstalk is unknown.
- Balanced photodetection practicality: Balanced detection doubles PD/TIA/ADC counts and assumes accurate matching and stable common-mode rejection. The paper does not quantify mismatch tolerances, calibration methods, or the latency/energy cost of per-channel balancing.
- Coupling and packaging losses: The model does not include fiber/laser coupling losses, on-chip coupling losses, interposer losses, or parasitics from co-packaged optics. End-to-end insertion loss budgets at system scale are not measured.
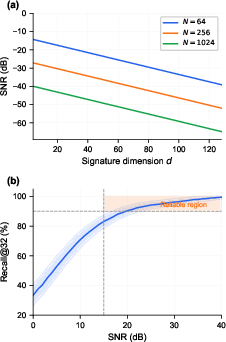
- Score-margin statistics vs N: The reliability of top‑k ranking under analog noise depends on score margins, which typically shrink as N grows. The paper does not analyze how ranking errors scale with N or provide empirical margin distributions at large N.
- ADC resolution and rank stability: The assumption that 4–6 bits suffice for robust ranking is based on small-d/d=N regimes. A systematic study of ENOB, quantization noise, and comparator metastability versus N, k, and task distributions is missing.
- Update bandwidth for signatures: Each block completion triggers weight updates across d rings per block/channel. The system-level bandwidth for updating many blocks across many heads/layers concurrently (including driver fan‑out and programming latency) is not analyzed.
- Layer- and head-level multiplexing: Real LLMs have many layers and (retrieval) heads. The paper does not specify how a single photonic engine is time- or space-multiplexed across layers/heads, how many parallel engines are needed, or the resulting area/energy/latency trade-offs.
- Retrieval-head identification and variability: The “>90% retrieval heads at τ=0.3” claim conflicts with prior studies using stricter criteria. The sensitivity of overall gains to the threshold τ, task/domain changes, and model architecture (MHA/GQA/MQA) requires broader empirical validation.
- Signature quality across tasks/models: The study focuses on mean-key projection and NIAH-style retrieval for Qwen2.5-7B (4K–64K). Generalization to other models (e.g., Llama, Mistral), tasks (summarization, code, multi-hop QA), and longer contexts (≥1M tokens) is not demonstrated.
- Learned projections and training overhead: A learned projection is proposed but not trained/evaluated. The required data, training procedure, stability under drift, and incremental updates (e.g., domain shifts) are unaddressed.
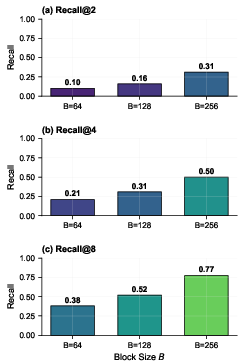
- Block size sensitivity: The impact of block size B (e.g., 64 vs 512 tokens) on signature stability, recall@k, and hardware dimension d (and thus MRR count) is not systematically explored.
- End-to-end impact beyond NIAH: The downstream effects of approximate block selection on perplexity, factual recall, hallucinations, and output quality across standard benchmarks are not measured. NIAH alone may not capture real-world sensitivity.
- Memory system integration: The interaction between photonic selection, GPU fetch, and ICMS/flash prefetch/eviction policies is not evaluated. Queueing effects, contention, and amortized latency in multi-tenant settings require system-level simulations or prototypes.
- Throughput and batching: The paper lacks a throughput model for multi-user, batched inference (varying token rates), including how query encoding/DACs and readout/ADCs are time-shared across many heads/tokens without degrading latency.
- Energy accounting completeness: Some components (e.g., clocking, control logic, calibrators, laser drivers, comb stabilization, monitoring ADCs, and routing) are not included in the energy model. A full-chip bill of materials and power budget is needed.
- Laser safety and reliability: Practical deployment concerns (eye safety, hot-pluggable modules, failure rates, lifetime of TFLN rings and drivers) are not addressed.
- Security and side-channels: Analog photonic processing may introduce optical/electromagnetic side channels. The paper does not consider leakage risks or protective measures.
- Robustness to non-ideal input statistics: The effects of query/keys with heavy-tailed distributions, non-stationarity across documents, or adversarial inputs on ranking stability are not analyzed.
- Offset-bias and normalization: The signed-query encoding via offset-bias assumes near-constant weight sums or easy digital subtraction. Variability in ∑w can bias ranks; the required normalization/calibration pipeline and its cost are unquantified.
- Modulator linearity and dynamic range: The impact of MZM nonlinearity, limited extinction, and DAC non-idealities on inner-product fidelity and top‑k stability is not measured.
- Dispersion and path skew: WDM propagation through deep splitter trees may introduce wavelength-dependent delay/attenuation. Impact on synchronized sampling and inter-wavelength weighting is not characterized.
- Comparator and synchronization across banks: For banked splitter architectures, how scores from multiple banks are time-aligned and merged into a global top‑k without additional latency is unspecified.
- Fairness of electronic baselines: GPU/ANN/ICMS energy and latency baselines rely on simplified assumptions (e.g., HBM pJ/byte, IVF-PQ scanning O(√N)). A broader set of tuned baselines and sensitivity analyses are needed to validate claimed 103–104× advantages.
- Cost and manufacturability: There is no discussion of manufacturing cost, yield learning curves, testing/calibration time, or integration with current datacenter packaging ecosystems (e.g., co-packaged optics with GPUs/DPUs).
These gaps suggest a roadmap: fabricate a small-scale PRISM demonstrator; produce rigorous scaling measurements of PD/ADC/top‑k hardware; broaden end-to-end evaluations across tasks/models; and develop robust calibration, multiplexing, and system-integration strategies that hold at N≥104 and million-token contexts.
Practical Applications
Immediate Applications
Below are practical, deployable uses that leverage the paper’s findings on photonic, scan‑free KV block selection for long‑context LLMs. Each item includes sectors and concrete product/workflow ideas, plus key assumptions or dependencies.
- Cloud LLM inference acceleration via photonic KV block selection
- Sectors: software/cloud AI, semiconductors, datacenter infrastructure
- What to deploy:
- A PRISM‑like photonic co‑processor (PCIe/CXL card or co‑packaged) that receives per‑head query sketches and returns top‑k block indices
- Runtime integration for vLLM, TensorRT‑LLM, FasterTransformer to route only “retrieval heads” to the photonic selector and fetch the chosen blocks from HBM/ICMS
- Workflows:
- For each decode step: (1) compute query sketch, (2) send to photonic ranker, (3) receive top‑k blocks, (4) fetch KV blocks from memory, (5) perform exact attention over selected blocks + local window
- Assumptions/dependencies:
- Availability of TFLN photonic modules with 4–6‑bit precision, balanced photodetection, and WDM laser combs
- Head‑level routing in inference stacks; per‑head top‑k API
- Retrieval head fraction is significant; block selection preserves task quality as shown in NIAH at 4K–64K with k≈32
- Enterprise RAG pipelines with lower latency and energy per query
- Sectors: finance (compliance, audit), legal (e‑discovery), healthcare (EHR summarization), media (transcript analytics)
- What to deploy:
- A “coarse ranker appliance” colocated with GPU nodes or DPUs that accelerates vector‑similarity ranking for context selection in RAG
- FAISS/Milvus plugin that swaps in a photonic inner‑product engine for coarse selection (top‑k routing preserved; fine‑grained re‑ranking done on GPU/CPU)
- Workflows:
- Existing two‑stage ANN indexing (IVF‑PQ or HNSW) replaced or front‑ended by photonic inner‑product ranking on compressed signatures, then exact scoring on shortlists
- Assumptions/dependencies:
- Coarse ranking tolerates 4–6‑bit precision; embeddings/signatures update at manageable rates
- Simple gRPC/PCIe interface between the database and photonic module
- Cost and energy reduction for long‑context LLM service tiers
- Sectors: cloud providers, sustainability
- What to deploy:
- New “long‑context” SKU where photonic block‑selection cuts memory traffic by ~N/k (paper reports ~16× at 64K) and reduces selection energy by orders of magnitude
- Energy/cost dashboards that expose per‑token energy savings for green AI reporting
- Assumptions/dependencies:
- Throughput is high enough to amortize fixed TEC/laser overhead; significant contexts (≥4K tokens) and small k/N ratios
- Datacenter operations can integrate fiber/laser safety and maintenance
- DPU/ICMS offload for KV cache management
- Sectors: networking, semiconductors, cloud infrastructure
- What to deploy:
- A photonic block‑selection module co‑packaged with DPUs (e.g., BlueField) or memory switches (ICMS) to reduce scans over HBM/flash‑backed KV tiers
- Workflows:
- Selection near the memory tier (before expensive KV movement); indices returned over high‑speed control path; GPUs fetch only selected KV blocks
- Assumptions/dependencies:
- Vendor cooperation for ICMS/DPU integration; CXL/CXL‑mem aware interfaces
- Thermal and packaging constraints for co‑packaged optics
- Developer tools for retrieval‑head‑aware runtimes
- Sectors: software tooling, MLOps
- What to deploy:
- SDKs that expose a uniform top‑k selection API (CPU emulation + photonic backend); runtime passes that detect and route retrieval heads automatically
- Calibration tools to build/maintain block signatures (mean key, PCA, random, or learned)
- Assumptions/dependencies:
- Accurate retrieval‑head identification at chosen thresholds; stable signature generation with periodic updates (every 64–512 tokens)
- Academic testbeds for photonic similarity search and LLM memory studies
- Sectors: academia, research labs
- What to deploy:
- Small‑scale TFLN broadcast‑and‑weight prototypes (e.g., d=32, N=256) to study recall@k vs. precision/drift/crosstalk
- Open evaluation suites (NIAH, long‑context QA) comparing mean‑key vs. PCA vs. random vs. learned projections under hardware impairments
- Assumptions/dependencies:
- Access to TFLN MRR platforms and balanced PD measurement setups; integration with open LLMs (Qwen/Llama variants)
- User‑facing AI features with snappier long‑context behavior (indirect benefit)
- Sectors: productivity, education, software development
- What to deploy:
- Faster document‑heavy assistants (contract review, multi‑chapter summarization, large codebase copilots) via cloud backends that adopt photonic selection
- Assumptions/dependencies:
- Cloud providers adopt photonic selection; apps do not require client‑side hardware changes
Long‑Term Applications
These opportunities require further R&D, scaling, or ecosystem/standards development before widespread deployment.
- Million‑to‑ten‑million‑token LLM contexts at practical cost/latency
- Sectors: software/cloud AI, scientific computing
- What could emerge:
- “Ultra‑long‑context” service tiers combining ICMS‑like storage, banked photonic splitters, and per‑head routing to maintain O(1) selection latency as N grows
- Assumptions/dependencies:
- Scaling to N≫1024 with adequate SNR (banking/amplification), high‑power/low‑noise comb lasers, and robust thermal management
- Models trained to remain accurate beyond 64K tokens
- General photonic ANN/vector search co‑processors
- Sectors: search/recommendation, retail, finance (risk retrieval), robotics (map/memory recall), geospatial
- What could emerge:
- Photonic similarity “blades” for coarse ranking in vector databases, search engines, recommender candidate generation, and SLAM map recall
- Assumptions/dependencies:
- Dynamic index updates at high QPS; multi‑tenant isolation; APIs/standards for photonic rankers; acceptable precision/recall in each domain
- Co‑packaged optics with GPUs/NPUs for memory‑bound operations
- Sectors: semiconductors, hyperscalers
- What could emerge:
- GPU packages with integrated photonic similarity engines for KV selection, cache prefetch ranking, and other memory‑bound kernels
- Assumptions/dependencies:
- Yield and reliability for large MRR counts (d×N), CPO supply chains, thermal co‑design, and firmware/driver support
- Edge and on‑prem inference appliances for privacy‑sensitive sectors
- Sectors: healthcare (hospital IT), finance (banks), government
- What could emerge:
- Quiet, low‑power LLM appliances with photonic block selection to support long‑context workloads on‑prem without cloud egress
- Assumptions/dependencies:
- Cost/size reduction of photonic modules; robust operation without lab‑grade TECs; compliance/security certifications
- Memory fabrics with photonic similarity at the switch/NIC
- Sectors: datacenter networking, CXL ecosystems
- What could emerge:
- Memory switches that perform in‑network similarity for KV indexing, cache eviction/prefetch decisions, and storage‑tier selection
- Assumptions/dependencies:
- CXL‑mem maturity, NIC/switch silicon that exposes low‑latency control paths to the photonic module, fabric‑wide APIs
- Retrieval‑head‑aware schedulers and compilers
- Sectors: LLM systems software
- What could emerge:
- Compilers/runtimes that co‑schedule retrieval heads on photonic engines across batches and models, and dynamically adjust k based on SNR/recall telemetry
- Assumptions/dependencies:
- Stable identification of retrieval heads across prompts/models; telemetry hooks from photonic hardware
- Standards and policy for photonic AI accelerators
- Sectors: standards bodies, policymakers
- What could emerge:
- APIs for photonic selectors (capabilities reporting, precision, throughput), energy labeling for green AI, and safety/EMI/laser handling regulations
- Assumptions/dependencies:
- Industry consortia participation; alignment with existing MLPerf/MLCommons and datacenter safety frameworks
- Security and reliability hardening
- Sectors: cybersecurity, compliance
- What could emerge:
- Side‑channel analyses and mitigations (optical power leakage, drift‑induced bias), redundancy/checksums for rank correctness, and secure firmware for weight programming
- Assumptions/dependencies:
- Clear threat models for analog accelerators; device‑level health monitoring and failover paths
- Consumer‑grade persistent‑memory assistants (ambitious)
- Sectors: consumer electronics, AR/VR
- What could emerge:
- Always‑on personal assistants with lifelog retrieval over very long contexts, enabled by ultra‑efficient selection in home/edge hubs
- Assumptions/dependencies:
- Miniaturization and cost reduction of photonic stacks; safe, low‑maintenance lasers; local vector stores and privacy‑preserving designs
Cross‑cutting assumptions and dependencies to monitor
- Hardware maturity: TFLN microring quality (Q, extinction), comb laser stability, balanced photodetection, low‑power DAC/ADC availability, packaging yield, TEC overhead and amortization.
- Software integration: Runtime support for head‑level routing; stable signature generation (mean key/PCA/random/learned); APIs for top‑k indices; fallbacks to electronic selection.
- Model behavior: Sufficient fraction of retrieval heads; block‑sparse attention preserves quality; signature dimensions (d≈32–64) maintain recall; k kept small vs. N for benefits.
- Scaling limits: SNR vs. splitter loss as N grows; banked architectures or amplification; thermal drift management and calibration frequency.
- Operational considerations: Datacenter safety for lasers/fibers; maintenance procedures; multi‑tenant QoS and isolation; observability (telemetry for recall/SNR/latency).
- Economics: CAPEX of photonic modules vs. OPEX savings (energy, latency); per‑query volume needed to amortize fixed power (TEC).
Glossary
- add-drop MRR: A microring resonator configuration with both through and drop ports, enabling selective wavelength filtering. "Through-port and drop-port transmission of a single add-drop MRR (, ER~\,dB)."
- ANN (approximate nearest neighbor): Algorithms that approximate nearest neighbor search to reduce scan cost in high-dimensional retrieval. "GPU ANN (FAISS IVF-PQ) reduces the full-key scan to \SI{5}{\micro\joule}"
- arithmetic intensity: The ratio of computation (FLOPs) to data movement (bytes), indicating how compute- or memory-bound a workload is. "The arithmetic intensity (FLOPs per byte) is "
- attention sinks: Positions or tokens that absorb a significant portion of attention despite limited relevance, often near the current token. "streaming heads that attend primarily to nearby tokens and ``attention sinks.''"
- autoregressive decoding: Token-by-token generation where each step conditions on all previously produced tokens. "As autoregressive decoding generates one token at a time"
- balanced photodetector: A differential detection setup using two photodiodes to subtract signals (e.g., through and drop ports) for signed measurements and noise rejection. "A balanced photodetector pair measures the differential photocurrent"
- broadcast-and-weight (B{paper_content}W) paradigm: A photonic computing approach that broadcasts input signals to many channels and applies per-channel weights with optical summation. "broadcast-and-weight (B{paper_content}W) paradigm"
- coherent Mach--Zehnder meshes: Photonic interferometer networks (MZI meshes) used for matrix operations with coherent light. "achieving over 200 POPS for full attention via coherent Mach--Zehnder meshes"
- dense WDM (DWDM): A wavelength-division multiplexing scheme with closely spaced channels to increase spectral density. "using standard dense WDM (DWDM) laser combs and MRR filter banks."
- drop-port: The port of an add-drop ring resonator where resonant wavelengths are extracted. "through-port and drop-port outputs simultaneously."
- DPU (data processing unit): A processor specialized for data movement, networking, and storage tasks offloading from CPUs/GPUs. "the BlueField-4 data processing unit (DPU)"
- extinction ratio (ER): The ratio of transmitted powers between on- and off-resonance (or logical states), indicating filter/modulator contrast. "(, ER~\,dB)."
- FAISS IVF-PQ: A specific ANN indexing method (inverted file system with product quantization) implemented in FAISS for fast similarity search. "GPU ANN (FAISS IVF-PQ) reduces the full-key scan to \SI{5}{\micro\joule}"
- free spectral range (FSR): The wavelength spacing between consecutive resonances in a resonator. "FSR8.3\,nm"
- GQA (grouped-query attention): An attention variant where multiple queries share keys/values to reduce memory. "grouped-query attention, GQA~\cite{Ainslie2023GQA,Shazeer2019MQA}"
- HBM (High Bandwidth Memory): A high-throughput memory stacked near processors, used by GPUs for fast data access. "sequentially reads all KV blocks from HBM to compute attention"
- ICMS (Intelligent Connectivity and Memory Switch): NVIDIA’s memory-tiering component that manages large KV caches with flash and prefetch logic. "Intelligent Connectivity and Memory Switch (ICMS)"
- intrinsic quality factor (Q_i): The resonator’s quality factor excluding coupling and external losses, reflecting material and fabrication limits. "intrinsic --"
- Johnson--Lindenstrauss (JL) lemma: A result ensuring distances are approximately preserved under random projections to lower dimensions. "The Johnson--Lindenstrauss (JL) lemma guarantees that a random Gaussian matrix"
- laser comb: A multi-wavelength laser source producing evenly spaced spectral lines for WDM encoding. "A WDM laser comb encodes a -dimensional query onto co-propagating wavelengths"
- loaded quality factor (Q_L): The overall resonator Q including coupling/external losses, determining resonance sharpness in-system. "(, ER~\,dB)."
- Mach--Zehnder modulator (MZM): An electro-optic modulator using interference to encode electrical signals onto optical carriers. "driving a Mach--Zehnder modulator (MZM)"
- microring resonator (MRR): A compact ring-shaped optical resonator used for filtering and weighting in photonic circuits. "a bank of microring resonators (MRRs) on thin-film lithium niobate (TFLN) applies programmable weights"
- mixture-of-experts architecture: A model design that routes inputs through a subset of expert networks to improve capacity and efficiency. "with a mixture-of-experts architecture"
- needle-in-a-haystack (NIAH): A benchmark where a single relevant item must be retrieved from a large distractor set. "needle-in-a-haystack (NIAH) evaluation"
- noise-equivalent power (NEP): A photodetector metric indicating the input optical power that yields unity signal-to-noise in 1 Hz bandwidth. "NEP $\sim \SI{10}{\pico\watt/\sqrt{Hz}}$"
- PCA (principal component analysis): A dimensionality reduction technique projecting data onto directions of maximum variance. "Principal component analysis over the key distribution yields a projection matrix"
- Pockels effect: A linear electro-optic effect allowing fast, low-power refractive index modulation for tuning resonances. "matching fast MRR electro-optic programming (Pockels effect)"
- POPS: Peta-operations per second, a measure of extreme compute throughput. "achieving over 200 POPS for full attention"
- random projection: Dimensionality reduction by multiplying with a random matrix that approximately preserves distances. "Random projection is attractive because it requires no training"
- RAG (retrieval-augmented generation): Techniques that augment model inputs with retrieved documents to improve factuality and context. "retrieval-augmented generation (RAG) workloads"
- retrieval heads: Attention heads that focus on long-range context rather than local windows. "retrieval heads that attend to tokens far from the current position"
- signal-to-noise ratio (SNR): The ratio of signal power to noise power, indicating reliability of analog measurements. "signal-to-noise ratio (SNR) requirements"
- thin-film lithium niobate (TFLN): An integrated photonics platform leveraging LiNbO3 for high-speed, low-loss electro-optic devices. "a thin-film lithium niobate (TFLN) similarity engine"
- top-: Selecting the k highest-scoring items from a set. "A compact electronic top- comparator selects the highest-scoring block indices"
- transimpedance amplifier (TIA): An amplifier converting photodiode current to voltage with low noise for high-speed detection. "assumes a transimpedance amplifier (TIA) front-end"
- through-port: The port of an add-drop resonator where non-resonant wavelengths continue to propagate. "through-port and drop-port outputs simultaneously."
- wavelength-division multiplexing (WDM): Encoding multiple data channels on distinct optical wavelengths within a single waveguide. "Prism encodes the query sketch onto WDM wavelength channels"
Collections
Sign up for free to add this paper to one or more collections.