Memory as Resonance: A Biomimetic Architecture for Infinite Context Memory on Ergodic Phonetic Manifolds
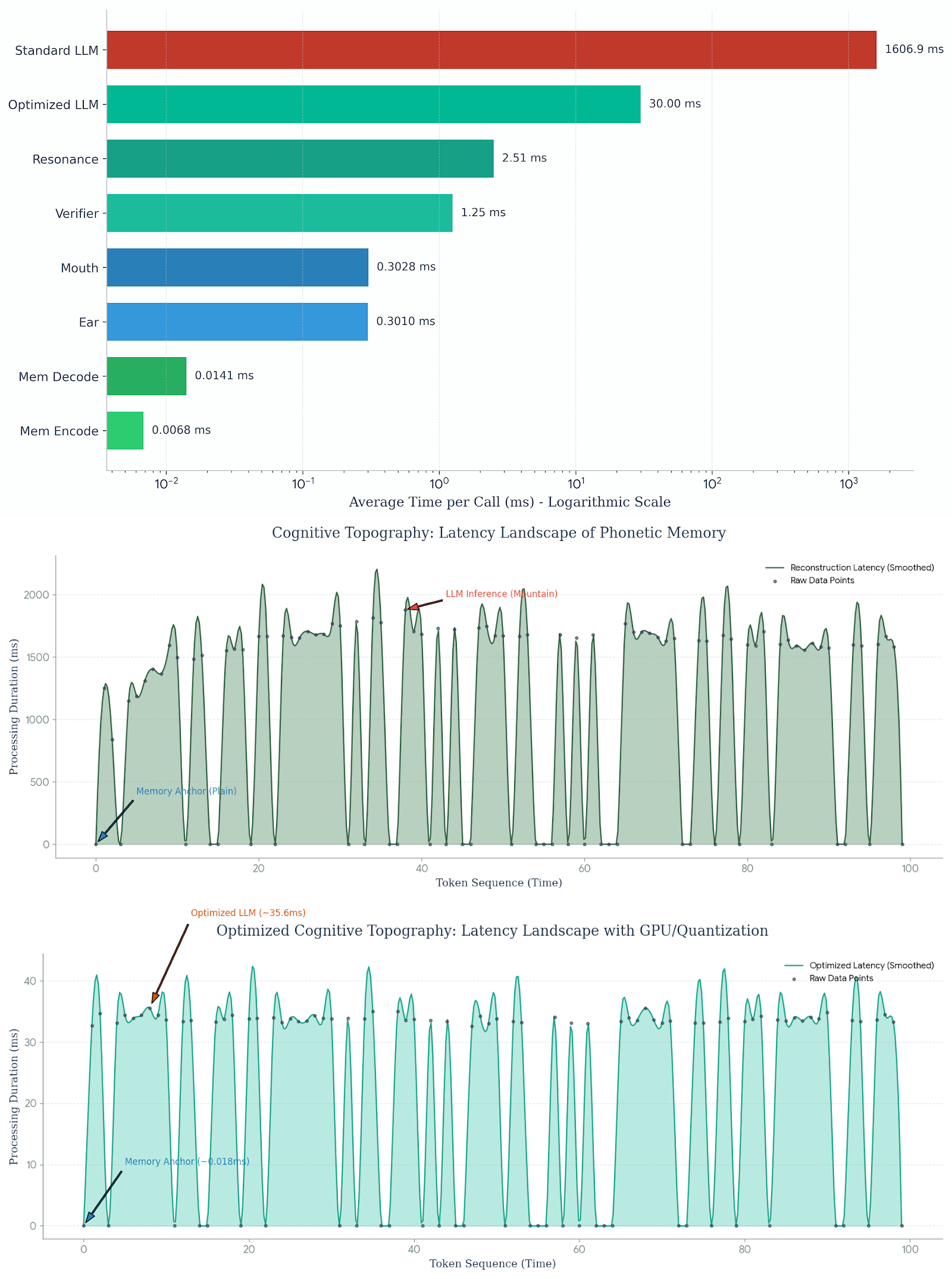
Abstract: The memory of contemporary LLMs is bound by a physical paradox: as they learn, they fill up. The linear accumulation (O(N)) of Key-Value states treats context as a warehouse of static artifacts, eventually forcing a destructive choice between amnesia and latency. We challenge this discrete orthodoxy, proposing that long-term memory is not the storage of items, but the persistence of a trajectory. We introduce Phonetic Trajectory Memory (PTM), a neuro-symbolic architecture that encodes language not as a sequence of tensors, but as a continuous path on an ergodic manifold governed by irrational rotation matrices. By decoupling the navigation (an invariant O(1) geometric signal) from the reconstruction (a probabilistic generative act), PTM achieves a compression magnitude of greater than 3,000x relative to dense caches. We demonstrate that retrieval becomes a process of resonance: the phonetic trace stabilizes the model against hallucination via "Signal Consensus" mechanism, securing up to approximately 92% factual accuracy. While this aggressive abstraction alters generative texture, it unlocks immediate access latency (approximately 34ms) independent of depth. Our results suggest that infinite context does not require infinite silicon; it requires treating memory not as data to be stored, but as a reconstructive process acting on a conserved, undying physical signal.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
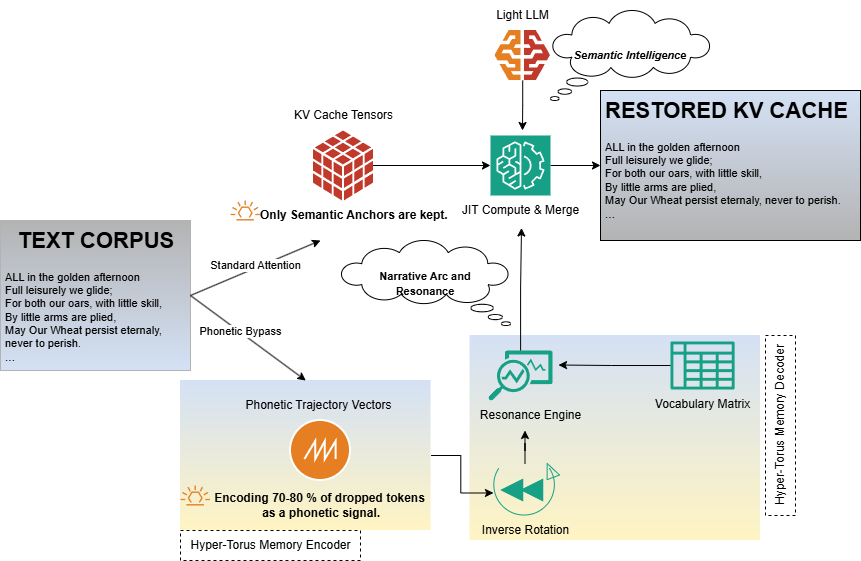
This paper introduces a new way for AI LLMs to remember very long conversations or documents without running out of memory or slowing down. Instead of storing every word like boxes in a warehouse, the authors turn the text into a kind of “song” or “path” on a special shape (a multi‑dimensional donut called a hyper‑torus). The idea is to keep a small, always‑active signal that guides the model to rebuild what was said when it needs it, rather than saving all the details. They call this approach Phonetic Trajectory Memory (PTM).
Key Objectives
The paper asks simple but important questions:
- Can we fit an endless sequence of text into a small, fixed amount of memory without mixing things up or forgetting?
- Can we compress “the bridge words” (like the, and, of) while keeping the key facts (names, numbers) clear?
- Can we keep the memory signal strong over time without it fading?
- Can we make reading and recalling faster even when the context is huge?
How It Works (Methods)
Here’s the approach in everyday terms, using analogies to make the ideas clear:
- Memory as a path, not a pile: Imagine you’re not storing every note of a song; you’re keeping the melody’s shape so you can hum it later. PTM encodes text as a path that “winds” around a donut‑shaped space. Because of how it spins, this path never loops back onto itself—so it doesn’t overwrite the past.
- Two rails: anchors and bridges
- Anchors (solid facts): Important, high‑detail tokens (like rare names, exact numbers) are kept in a small, traditional memory so they stay perfect.
- Bridges (connective words): Common words that carry rhythm and grammar get compressed into the path. You don’t store them directly; you store how they “moved” the signal.
- Turning words into sound (phonetics): Instead of treating words as IDs, PTM breaks them into their sounds (using features from the International Phonetic Alphabet). Think of every word as a small push on the donut path based on how it sounds. This “sound push” is simple and repeatable.
- The spinning clock that never repeats: Inside the donut space, the system uses multiple “spinners” (like clock hands) turning at speeds that are special and never line up exactly. Because of this, the path can keep winding forever without overlapping. That means it can remember a lot without running out of space.
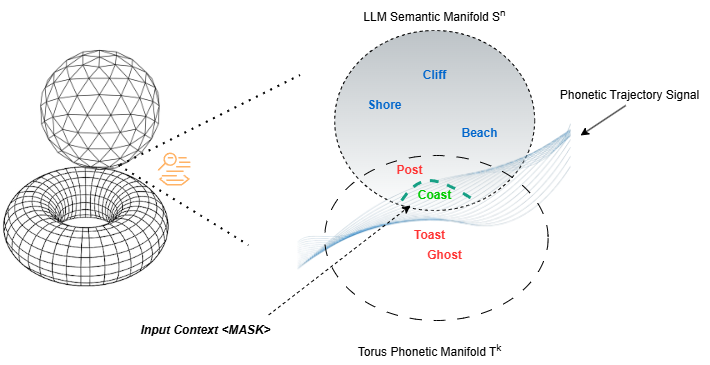
- Retrieval by resonance (like tuning a guitar): When the model needs to recall a word, it doesn’t search a big database. It “plays back” the path to see what sound would have caused the current position on the donut. Then it combines:
- What the LLM thinks is likely (semantic guess),
- With what the path says physically must be true (phonetic evidence).
- The final choice is where both agree—like matching a tuning fork’s vibration to the right note.
- Constant memory and fast access: Because the path lives in a small, fixed‑size state (think: a tiny musical score), it uses the same small amount of memory no matter how long the text. Retrieval is quick because it’s just a small calculation, not scanning through huge history.
Main Findings
The authors tested PTM on a normal computer (not a supercomputer) and report:
- Very high compression: Over 3,000× less memory needed in extreme tests when storing only the path (no anchors).
- Fast recall: Access times around 34–50 milliseconds, even for long histories.
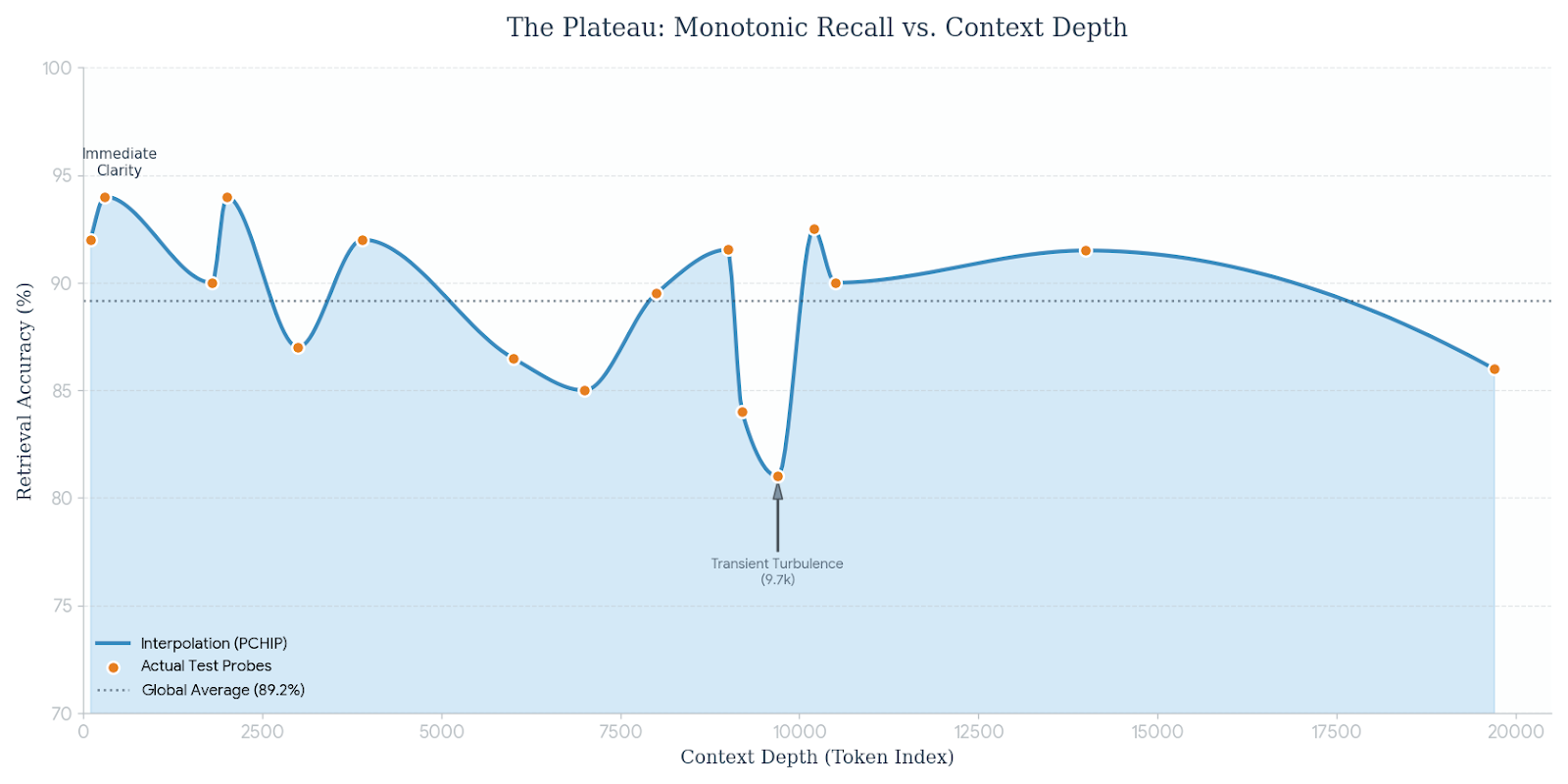
- Stable accuracy over long text: Around 89–92% correct recall on long sequences (including a 20,000‑token test), with accuracy staying stable instead of fading as the text gets older.
- Fewer hallucinations: Because the geometric “sound path” checks what’s physically possible, the model is less likely to invent wrong details. The authors call this “Signal Consensus.”
- Trade‑offs: The compressed path sometimes loses punctuation and exact numbers (for example, changing “twenty‑four” slightly). Rare or unusual words can be missed if they aren’t in the pronunciation dictionary. There was one brief dip in accuracy around the middle of a long test, which quickly recovered.
Why this matters: It suggests you don’t need huge memory to handle long context. If you store a persistent, small signal (the path) and rebuild details on demand, you can keep conversations coherent and factual without heavy hardware.
Implications
- Infinite context with tiny memory: You can remember long stories or chats using a fixed, small memory by treating memory like a path you can replay, not a warehouse you must fill.
- Faster, more efficient AI: This approach could make LLMs work better on everyday devices (like laptops or phones) because they don’t need massive memory or many GPUs for long context tasks.
- Fewer mistakes: The “resonance” check can reduce made‑up facts by forcing the model’s guesses to match a physical signal.
- New design mindset: Memory becomes a reconstructive process—store the address (how to get back) rather than the full content—much like remembering a song by its melody rather than every note written down.
- Future improvements: To make this even better, the authors suggest keeping stronger anchors for punctuation and exact numbers, and expanding the phonetic library for rare words.
In short, the paper argues that long‑term memory for AI should act like a stable, musical path the model can replay, rather than a giant box of saved tokens. That shift keeps memory small, fast, and more reliable, even as context grows very large.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of the key uncertainties and unresolved issues that the paper leaves open, phrased to be concrete and actionable for follow‑up research:
- Empirical generalization: Results are reported on a single small model (gpt2-medium) and limited corpora; there is no evaluation across larger LLMs, multilingual models, code/math domains, or diverse tasks (e.g., QA, long-dialog tracking, program synthesis).
- Baselines and head-to-head comparisons: There is no direct benchmarking against state-of-the-art long-context methods (FlashAttention variants, Mamba/SSMs, RAG pipelines) on standardized datasets, metrics, and hardware.
- Latency scaling and complexity: The “O(1)” retrieval claim conflicts with candidate generation that broadcasts against the full vocabulary matrix M_vocab (O(|V|)); latency vs. |V|, top‑k, and context depth is not measured systematically.
- Anchor detection policy: The paper does not specify how “Anchors” are identified (entropy measure, heuristics, thresholds), how α/γ interact with anchoring, or how the selection impacts accuracy/compression across domains.
- Anchor memory growth: Sparse KV anchors still grow with sequence length; there is no bound, eviction policy, or compression scheme ensuring overall O(1) memory in practice.
- Out-of-vocabulary and multilingual coverage: Reliance on CMU Pronouncing Dictionary and IPA for deterministic synthesis leaves neologisms, domain-specific jargon, non‑English tokens, code, emojis, and special symbols unresolved; strategies for OOV handling and multilingual extension are missing.
- Tokenization–phoneme mismatch: How subword/BPE tokens are mapped to phonetic units (one‑to‑many, many‑to‑one) is unspecified; alignment across multi-token names, hyphenations, contractions, and punctuation is not addressed.
- Structural agnosia: The system degrades on punctuation and exact numerals; concrete methods to detect and anchor structural tokens (e.g., quotation marks, numeric expressions, code symbols) and quantify trade-offs are absent.
- Phrase-level retrieval: Reconstruction is evaluated at token level; handling multi-token entities, phrases, and compositional retrieval (e.g., names, dates, equations) is not analyzed.
- Adaptive coupling: The convex combination parameter α and spectral temperature γ are fixed; there is no learning or adaptive policy (per token/domain/uncertainty) to reduce homophone/semantic drift errors.
- Manifold dimensionality choice: The selection of a 16‑D torus is not justified; sensitivity analysis across dimensions vs. accuracy, collision rate, and compute/memory cost is needed.
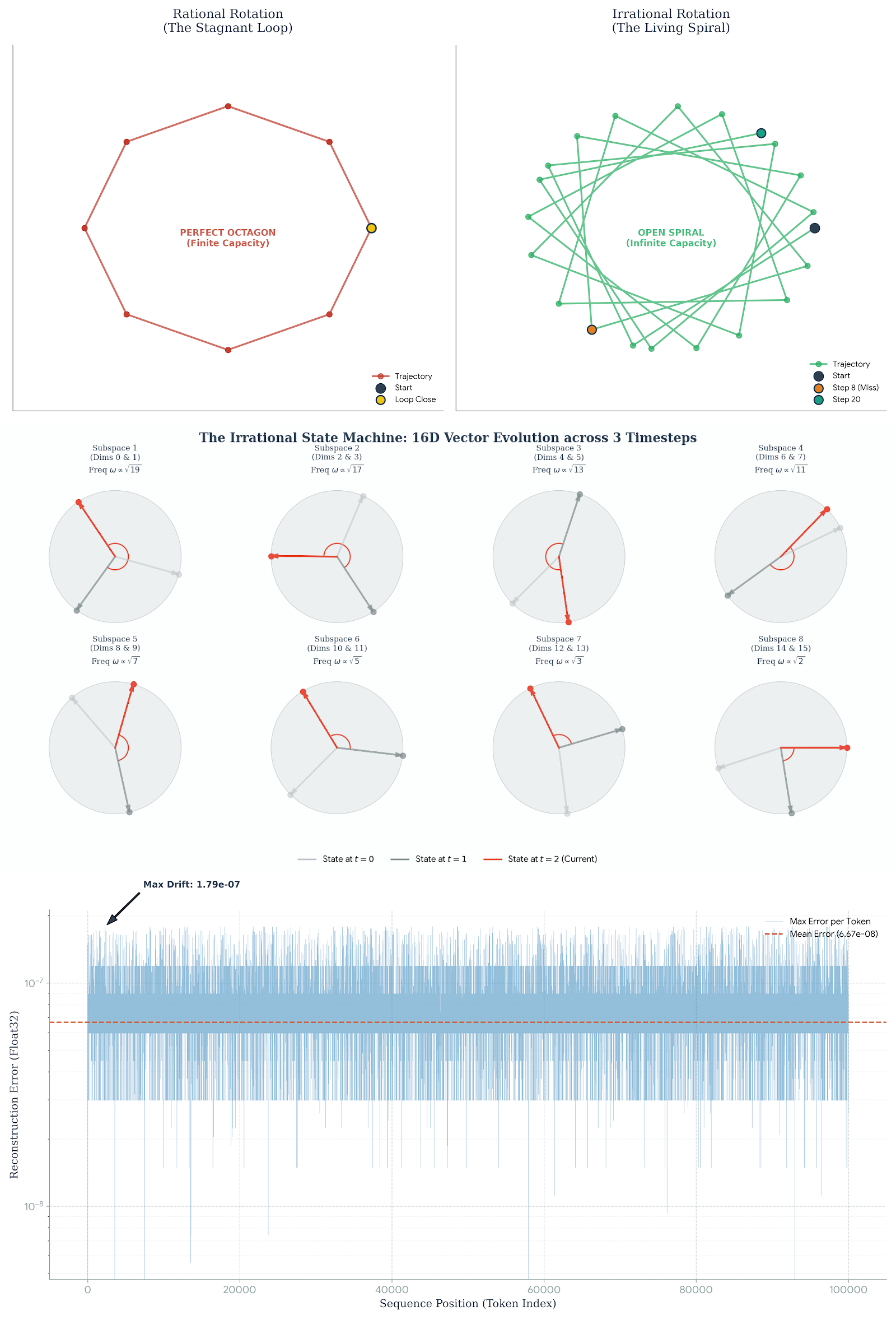
- Frequency selection under finite precision: Using θ_i = π√p_i assumes irrational rotations, but finite-precision sin/cos and modulo arithmetic introduce periodicity; rigorous bounds and empirical tests (≫20k tokens) under FP16/FP32/quantization and GPU kernels are missing.
- Injectivity with modulo addition: The Strong Unicity proof considers (R − I) but does not rigorously address collisions introduced by additive modulo‑1 wrapping with cumulative injections; full-system invertibility conditions are not provided.
- Collision probability assumptions: The birthday-bound calculation relies on ε=0.1 without justifying its relation to retrieval distinguishability; calibration of ε vs. accuracy and false-positive/false-negative rates is not explored.
- Error/drift model validation: Brownian error growth is assumed; long-horizon empirical stress tests (≥107 tokens), worst-case inputs, and hardware variability (GPU nondeterminism, mixed precision) are not reported.
- Energy conservation with repeated injections: Formal analysis of stability when repeatedly adding normalized phonetic forces under modulo arithmetic (distribution of S_t, saturation risks, aliasing) is absent.
- Vocabulary matrix scalability: Storage, build/update costs, and approximate nearest neighbor options for M_vocab (|V|~100k–1M) are not discussed; domain adaptation and dynamic vocabulary growth remain open.
- End-to-end throughput: The CPU-bound physics engine ensures determinism but may bottleneck throughput; practical GPU implementations, parallelization strategies, and cross-device reproducibility are not investigated.
- Retrieval indexing and random access: Constant-time reconstruction presumes knowing t−k and S_{t−1}; how random access to arbitrary past positions is indexed, cached, or computed without O(T) traversal is unclear.
- Generative texture alteration: The paper notes altered generative “texture” but provides no quantitative or human evaluation of fluency, coherence, factuality, or calibration under PTM vs. baseline transformers.
- Integration with external knowledge (RAG): Since PTM relies on LLM priors for semantics, performance when the model lacks domain knowledge is unknown; hybrid designs that marry PTM with RAG are not explored.
- Security and adversarial robustness: Risks of adversarial phonetic patterns, targeted resonance interference, or privacy leakage via reconstructive memory are not assessed.
- Handling of non-pronounceable inputs: Numbers, formulae, code tokens, byte-level artifacts, and rare symbols may have weak or ambiguous acoustic signatures; dedicated injection/resonance strategies are not proposed.
- Compression–accuracy trade-off curves: Reported compression ratios (>3000×, 4.4×) vary by setup; systematic curves showing accuracy vs. compression vs. anchor rate across domains are missing.
- Training and learnability: The system is largely deterministic/frozen; whether learning the projection, manifold parameters, or coupling improves performance (and how to train it) is an open question.
- Task-level outcomes: Beyond token recovery, there is no evaluation of downstream task success (e.g., long-context QA accuracy, code execution correctness, contradiction detection) under PTM.
- Reproducibility details: Exact hyperparameters (α, γ, top‑k), thresholds for anchor detection, hardware configurations for latency claims (~34–50 ms), and code artifacts enabling replication are not fully specified.
Practical Applications
Below are actionable, sector-linked applications that follow directly from the paper’s findings on Phonetic Trajectory Memory (PTM), its ergodic hyper-torus architecture, and the resonance-based retrieval mechanism. Each item notes practical tooling/workflows and assumptions that affect feasibility.
Immediate Applications
- KV-cache compression middleware for LLM serving
- Sector: software/AI infrastructure
- What: A PTM “Memory Layer” that replaces most dense KV states with the manifold state (Truth Rail) and keeps high-entropy anchors in a sparse cache (Logic Rail); offers O(1) retrieval latency and substantial VRAM/RAM savings (256× for bridges; >3,000× in zero-anchor regimes; ~34–50 ms access).
- Tools/workflows: Python SDK integrating NumPy (deterministic physics engine) + HuggingFace Transformers; anchor detector for proper nouns, numerals, IDs; coupling coefficient α and spectral sharpness γ tuning.
- Assumptions/dependencies: Reliable anchor detection to avoid losing critical facts; deterministic CPU path or deterministic GPU kernels; IPA/phonetic mappings for supported languages; acceptance of minor changes in generative texture; mitigation of “structural agnosia” (punctuation, exact numbers) via anchoring.
- Infinite-context chat, email, and knowledge assistants on commodity hardware
- Sector: productivity/enterprise software
- What: Conversation tools that keep multi-session memory as a compact manifold state with sparse anchors for names, dates, commitments; O(1) recall of long threads without large storage or prefill cost.
- Tools/workflows: Client-side manifold store + session anchor index; resonance-based reconstruction to guide model outputs; “memory hygiene” dashboards (drift/interference monitoring).
- Assumptions/dependencies: Robust anchor policy for identities, amounts, deadlines; multilingual IPA coverage; balancing α to prevent homophone substitution.
- Meeting and call-center transcript memory with hallucination suppression
- Sector: customer support/telecom
- What: Compress long call transcripts into PTM state; use Signal Consensus reranking to reduce hallucinated names, order numbers, and resolutions; maintain continuity across calls.
- Tools/workflows: Deterministic phonetic injection (FFT bins of transcript words), sparse anchors for IDs/amounts; PTM-based reranker atop ASR+LLM pipeline.
- Assumptions/dependencies: Accent-aware phonetic mapping and domain-specific anchor rules; careful handling of low-energy “silent” words; QA for numerical accuracy.
- Legal and policy document review with deep cross-reference continuity
- Sector: legal services, government
- What: Long-horizon analysis that retains statutes/clauses as anchors while folding connective text onto the manifold; fast retrieval across large briefs, filings, and regulations.
- Tools/workflows: “Torus Memory Reader” for contracts; anchor heuristics for citations, section IDs, dates; resonance-aided cross-document linking.
- Assumptions/dependencies: Anchoring of exact cites and figures to counter structural agnosia; audit trails showing geometric evidence used in decisions.
- Signal Consensus reranker for hallucination reduction in critical domains
- Sector: healthcare, finance, education, news
- What: A modular reranker that fuses semantic priors with manifold evidence (Pθ + Pφ) to suppress plausible-but-wrong outputs; empirically yields up to ~92% factual accuracy in tests.
- Tools/workflows: Drop-in reranking component; α tuning per domain; anchor whitelist (drugs, dosages; tickers, amounts; student names).
- Assumptions/dependencies: Coverage for domain-specific terms; strong anchor guardrails for numbers and units; explainability/reporting for regulatory use.
- Edge/on-device assistants with long memory and low storage
- Sector: mobile, IoT
- What: Offline personal assistants that store long histories as PTM states; minimal storage footprint and constant-time recall on CPU.
- Tools/workflows: Lightweight NumPy physics engine; compressed session store; anchor curation (contacts, calendar).
- Assumptions/dependencies: Battery and CPU budgets for FFT/rotation; multilingual IPA; privacy controls for reconstructive memory.
- Resonant RAG: continuity-aware retrieval gating
- Sector: enterprise AI
- What: Use manifold resonance to gate or reorder RAG chunks, favoring passages that phonetically and structurally align with the evolving memory trajectory.
- Tools/workflows: Pre-retrieval phonetic broadcast over candidate chunks; combine with vector similarity; deploy as a RAG “consistency filter.”
- Assumptions/dependencies: Interfaces to your retriever; quality of phonetic features for doc text; tuning α to balance continuity vs. novelty.
- Memory compression for audit/compliance logs
- Sector: finance, regulated industries
- What: Store long operational logs as manifold states with anchors for timestamps, amounts, IDs; reconstruct sequences on demand to evidence continuity while minimizing storage.
- Tools/workflows: Log-to-PTM ingestion; anchor policies for compliance-critical fields; drift/interference monitoring; reproducibility guarantees.
- Assumptions/dependencies: Strict anchoring for numeric precision; determinism when generating evidentiary reconstructions.
- Academic reproducibility and benchmarking for long-context systems
- Sector: academia
- What: Use the deterministic physics engine to create reproducible long-context memory benchmarks; study ergodicity, interference “dips,” and hallucination suppression.
- Tools/workflows: Open-source notebooks (NumPy + Transformers); datasets with controlled entropy; ablation of anchors; metrics for drift/accuracy vs. depth.
- Assumptions/dependencies: Dataset phonetic coverage; standardized evaluation of homophones vs. semantic errors.
Long-Term Applications
- Co-trained infinite-context LLMs with native PTM integration
- Sector: AI research/software
- What: Architectures that train the transformer and the manifold jointly (Truth Rail + Logic Rail) to reduce reliance on post-hoc anchoring; native O(1) retrieval across million-token spans.
- Tools/workflows: Multi-objective training (semantic fluency + geometric fidelity); new attention gates informed by manifold phase; curriculum for anchor minimization.
- Assumptions/dependencies: Training infrastructure; stability of unitary rotations under quantization; scalable datasets with phonetic annotations.
- Cross-lingual and multimodal manifold memory
- Sector: robotics, multimedia, global products
- What: Extend PTM to speech, video, and sensor streams (deterministic feature-to-torus pipelines); support languages without robust CMU/IPA coverage.
- Tools/workflows: Deterministic feature extractors for audio (ASR), vision (phase-encoded motion/edges), and robotics (state vectors); multimodal anchor schemas.
- Assumptions/dependencies: Robust deterministic feature design resilient to noise; IPA or equivalent for diverse languages; careful handling of “silent” or low-energy tokens.
- Longitudinal EHR memory with reconstructive recall
- Sector: healthcare
- What: Patient-level “torus memory” that compresses years of notes, labs, and meds into a continuous state; resonance-guided recall to support clinical decision-making.
- Tools/workflows: Anchor enforcement for vitals, dosages, dates; domain-specific α/γ calibration; auditability and clinician-in-the-loop checks.
- Assumptions/dependencies: Regulatory compliance (HIPAA/GDPR); exact numeric anchors to avoid dosage errors; strong explainability and validation.
- Autonomous robotics mission memory
- Sector: robotics/automation
- What: O(1) retrieval of long trajectories and state histories; collision-resistant manifold indexing for missions and rehearsals.
- Tools/workflows: Sensor-to-torus adapters; safety-certified deterministic kernels; resonance-based recovery for rare events.
- Assumptions/dependencies: Real-time guarantees; robustness to sensor noise; certification and failover strategies.
- Resonant ledgers and lifelong transaction analysis
- Sector: finance
- What: Continuous memory of transactions, positions, and narratives; suppress hallucinations in analyst copilots and compliance tools via geometric evidence.
- Tools/workflows: Ledger-to-PTM ingestion; anchors for amounts, instrument IDs; resonance gating in reporting/generation.
- Assumptions/dependencies: Accuracy for numbers (must anchor); governance and auditability; integration with existing risk systems.
- Energy-efficient AI inference and new hardware primitives
- Sector: cloud, energy/sustainability, semiconductors
- What: Reduce prefill/VRAM costs via PTM; develop hardware blocks for unitary rotations and toroidal arithmetic to improve speed and determinism.
- Tools/workflows: Inference schedulers that leverage O(1) memory; deterministic GPU kernels; hardware IP for SO(2) rotors and modulo-1 operations.
- Assumptions/dependencies: Vendor support for deterministic reductions; benefits persist under quantization/low precision.
- Privacy-preserving “memory-as-signal” vaults
- Sector: privacy/security
- What: Store only geometric memory signals (plus minimal anchors) rather than raw text; reconstruct on demand while limiting direct data exposure.
- Tools/workflows: Policy on anchor content; controllable reconstruction with α to avoid overdisclosure; redaction via anchor pruning.
- Assumptions/dependencies: Careful analysis of semantic leakage via reconstructive processes; legal standards for compressed representations.
- Standards for deterministic memory and explainable reconstruction
- Sector: policy/regulation
- What: Guidelines for reproducible long-context memory, drift/precision reporting, and resonance-based explainability in regulated AI.
- Tools/workflows: Reference metrics (drift, collision probability, homophone rates); documentation templates for inspections; compliance checklists.
- Assumptions/dependencies: Cross-industry consensus on metrics; acceptance of geometric evidence alongside semantic priors.
- Archival compression for libraries and museums
- Sector: cultural heritage/archival science
- What: Compress large corpora into torus states with anchors for citations and dates; reconstruct narratives for research queries.
- Tools/workflows: Manifold archival pipelines; anchor catalogs for canonical references; resonance-based research assistants.
- Assumptions/dependencies: Long-term bit-precision management; policies for reconstructive accuracy; multilingual support.
- Personalized tutors with lifelong memory
- Sector: education
- What: On-device tutors that remember learning trajectories, misconceptions, and goals across semesters with minimal storage.
- Tools/workflows: Student-profile anchors (skills, scores); resonance-guided remediation suggestions; privacy-preserving local memory.
- Assumptions/dependencies: Strong anchors for grades and concepts; fairness and bias checks; parental/educator oversight.
- Creative tools for story continuity and franchise bibles
- Sector: media/entertainment
- What: Writers’ assistants that keep expansive lore as compact manifold states; maintain continuity over seasons and spin-offs.
- Tools/workflows: Anchor policies for canonical facts; resonance-based correction of drift; collaborative memory stores across teams.
- Assumptions/dependencies: Editorial acceptance of generative texture shifts; strict anchoring to prevent canon errors.
Cross-cutting assumptions and dependencies to watch
- Phonetic coverage and determinism: IPA/CMU mappings must cover languages, accents, neologisms; deterministic synthesis and FFT binning are critical.
- Anchor quality: Proper nouns, numerals, IDs, citations, and units often must be anchored to avoid structural agnosia and numeric errors.
- Parameter tuning: Coupling coefficient α and spectral sharpness γ require domain-specific calibration to balance fluency vs. geometric fidelity.
- Deterministic compute: CPU NumPy path or deterministic GPU kernels are needed to preserve reproducibility and avoid cycle aliasing effects.
- Acceptable texture shift: Some applications can tolerate phonetic/semantic substitutions (e.g., homophones), others cannot—set policy accordingly.
- Privacy and governance: Reconstructive memory can still leak semantics; governance should specify what anchors are stored and who can reconstruct.
Glossary
- Acoustic Injection: A deterministic mapping from discrete tokens to a continuous phonetic signal injected into the manifold state. "The Acoustic Injection ()"
- Associative Recall: The ability to retrieve specific items via associative cues, which can degrade when compression blurs high-frequency details. "often struggling with ``Associative Recall.''"
- Block-diagonal matrix: A matrix composed of independent blocks along the diagonal, used here to assemble multiple planar rotors for rotations. "a block-diagonal matrix in the special orthogonal group :"
- Brownian motion: A random-walk process modeling how rounding errors accumulate proportionally to in unitary rotations. "the error in a unitary rotation follows a brownian motion \cite{wangTheoryBrownianMotion1945} model:"
- CMU Pronouncing Dictionary: A standardized lexical resource mapping words to phoneme sequences to ensure reproducible acoustic fingerprints. "Using the CMU Pronouncing Dictionary as the ground truth,"
- Convex combination: A weighted sum of probabilities whose weights sum to one, used to fuse semantic and geometric evidence. "is defined as the convex combination of these two densities:"
- Ergodic manifold: A manifold on which measure-preserving dynamics produce dense, non-repeating trajectories. "as a continuous path on an ergodic manifold governed by irrational rotation matrices."
- Ergodic operator: A transformation whose orbits densely cover the state space without repetition, preserving measure. "An ergodic operator governed by irrational rotation matrices."
- Fast Fourier Transform (FFT): An algorithm to efficiently compute the discrete Fourier transform of signals. "We apply a Fast Fourier Transform (FFT) to the signal,"
- FlashAttention: An optimized attention mechanism that reduces memory and compute overhead for long sequences. "Methods such as FlashAttention \cite{NEURIPS2022_67d57c32},"
- Generalized Birthday Problem: A probabilistic framework for estimating collision likelihood among many samples. "Applying the Generalized Birthday Problem for a context window of tokens,"
- Hyper-Torus Manifold: An n-dimensional torus (product of circles) used as a compact, bounded state space for memory. "By projecting the input sequence onto an ergodic Hyper-Torus Manifold"
- IEEE 754: The floating-point standard that governs numeric representation and determinism on modern hardware. "guarantee ``IEEE 754 Determinism''."
- International Phonetic Alphabet (IPA): A standardized phonetic notation encoding articulatory features of speech sounds. "based on the International Phonetic Alphabet (IPA) features (place, manner, voicing)."
- Irrational rotation matrices: Rotation operators with irrational angles that produce dense, non-periodic orbits. "governed by irrational rotation matrices."
- Key-Value (KV) cache: The attention memory storing keys and values for previously seen tokens in transformer models. "the Key-Value (KV) cache."
- Kronecker’s Theorem: A result ensuring dense torus orbits for rotations with incommensurate (irrational) frequencies. "we invoke Kronecker's Theorem \cite{hardyIntroductionTheoryNumbers1979,waltersIntroductionErgodicTheory2000}."
- Least Common Multiple (LCM): The smallest common multiple of several integers, used to estimate combined cycle lengths. "the Least Common Multiple (LCM) of the 8 independent planar cycles."
- Lee Distance: A wrap-around metric on the torus that accounts for modular boundaries when measuring differences. "as the Lee Distance \cite{boseLeeDistanceTopological1995} (Toroidal Distance)"
- Machine epsilon: The smallest distinguishable increment in floating-point arithmetic for a given precision. "The machine epsilon for standard float32 ()."
- Mamba: A selective state space model architecture achieving constant-time inference by compressing history into a fixed-size state. "Architectures like Mamba \cite{liuVisionMambaComprehensive2025}"
- Neuro-Symbolic Architecture: A system that integrates neural probabilistic models with symbolic or geometric mechanisms. "a neuro-symbolic architecture that encodes language"
- Neuro-Symbolic Relay: A mechanism that preserves critical semantic anchors as repeaters to maintain long-range dependencies under compression. "We introduce the Neuro-Symbolic Relay \cite{xinSmartDecisionOrchestration2025},"
- Prefill phase: The initial computation stage where the model processes and caches the context before generation. "reading" it (the Prefill phase),"
- Retrieval-Augmented Generation (RAG): A technique that augments LLMs with external document retrieval from vector databases. "Retrieval-Augmented Generation promises theoretical infinity."
- Ring Attention: A blockwise attention mechanism that scales to long sequences by organizing computation in a ring structure. "Ring Attention \cite{liuRingAttentionBlockwise2023},"
- Semi-orthogonal projection matrix: A projection matrix with orthonormal columns (or rows) used to map features to a lower dimension. "Where is a semi-orthogonal projection matrix."
- Special orthogonal group (SO(d)): The group of rotation matrices with determinant 1, representing rotations in dimensions. "the special orthogonal group :"
- State-Space Models (SSMs): Models that summarize past inputs in a fixed-size hidden state updated over time. "Unlike State-Space Models that enforce ``forgetting'' to manage infinite streams,"
- Symplectic inverse rotation: A time-unwinding operation that preserves geometric structure during resonance-based retrieval. "executes the symplectic inverse rotation () to unwind time."
- Toroidal Distance: A wrap-around distance metric on a torus equivalent to Lee distance. "Lee Distance \cite{boseLeeDistanceTopological1995} (Toroidal Distance)"
- Unitary Manifold: A state space where evolution preserves the norm (energy) of signals, preventing decay over time. "PTM operates on a Unitary Manifold where the signal magnitude is invariant."
- Weyl’s Equidistribution Theorem: A theorem stating that sequences with irrational rotations are uniformly distributed modulo 1. "By applying Weylâs Equidistribution Theorem to irrational rotations on a Hyper-Torus,"
Collections
Sign up for free to add this paper to one or more collections.