CLT-Forge: A Scalable Library for Cross-Layer Transcoders and Attribution Graphs
Abstract: Mechanistic interpretability seeks to understand how LLMs represent and process information. Recent approaches based on dictionary learning and transcoders enable representing model computation in terms of sparse, interpretable features and their interactions, giving rise to feature attribution graphs. However, these graphs are often large and redundant, limiting their interpretability in practice. Cross-Layer Transcoders (CLTs) address this issue by sharing features across layers while preserving layer-specific decoding, yielding more compact representations, but remain difficult to train and analyze at scale. We introduce an open-source library for end-to-end training and interpretability of CLTs. Our framework integrates scalable distributed training with model sharding and compressed activation caching, a unified automated interpretability pipeline for feature analysis and explanation, attribution graph computation using Circuit-Tracer, and a flexible visualization interface. This provides a practical and unified solution for scaling CLT-based mechanistic interpretability. Our code is available at: https://github.com/LLM-Interp/CLT-Forge.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces CLT-Forge, a free, open-source toolkit that helps researchers “look inside” LLMs to understand how they think. It focuses on a technique called Cross-Layer Transcoders (CLTs), which turn a model’s complicated inner workings into simpler, human-readable pieces called features, and shows how these features influence each other through “attribution graphs.” The toolkit makes it much easier and cheaper to train these CLTs, analyze their features, and visualize how information flows inside an LLM.
What questions is this paper trying to answer?
- How can we represent what an LLM is doing in a way that humans can understand, without getting lost in millions of numbers?
- Can we make these explanations smaller and less repetitive by sharing the same “features” across different layers of the model?
- How do we train and analyze these cross-layer explanations at the huge scales real LLMs require?
- Can we bundle training, analysis, graph building, and visualization into one easy-to-use system?
How did the researchers approach it?
Think of an LLM like a very tall building with many floors (layers). When a word goes in, it travels up floor by floor, getting processed. Inside each floor, there are many little “detectors” (features) that light up when they recognize something (like “negation,” “animal,” or “past tense”). The goal is to find these detectors and show how they connect.
Here’s how CLT-Forge makes that work:
- Cross-Layer Transcoders (CLTs): Instead of giving each floor its own separate set of detectors, CLTs let floors share some detectors. This avoids creating duplicates of the same idea on different floors. It makes the big picture simpler and more compact.
- Attribution graphs: Imagine a flowchart showing which detectors on one floor influence detectors on the next. These graphs capture “who affects whom” across layers, making the model’s behavior traceable like a circuit.
- Activation caching and compression: To train CLTs, you need lots of snapshots (“activations”) of what happens on each floor. That can take up many terabytes. The authors “zip” these snapshots with smart compression (like using int8 or int4 numbers instead of full precision) to cut storage by about 4–12×, while keeping the important information.
- Distributed training with feature sharding: Training CLTs is heavy. The toolkit splits the work across multiple GPUs by dividing the features among them—like a team splitting a big to-do list—so large models can be handled in practice.
- Automated interpretability (“autointerp”): After CLTs are trained, the toolkit automatically searches through lots of text to find the best examples for each feature (the moments it lights up most). It then uses an LLM to draft a plain-language description of what that feature seems to be detecting.
- Circuit-Tracer integration: The toolkit plugs into Circuit-Tracer, a library that efficiently builds and prunes attribution graphs and lets you try “what if” experiments (interventions) on features and circuits.
- Visual interface: A simple, extensible web app (built with Dash) lets you explore features, read their auto-generated explanations, see the attribution graphs, cluster related features, and run interventions.
What did they find, and why is it important?
- Smaller, clearer graphs: Sharing features across layers (with CLTs) reduces repeating the same ideas over and over. This produces cleaner, more interpretable circuits.
- Practical scaling: With feature sharding across 8 large GPUs, they trained CLTs with about 1.5 million features on a 1B-parameter model. Compressed activation caching cut storage from ~20 TB to ~4 TB with only a small accuracy trade-off (a few percent).
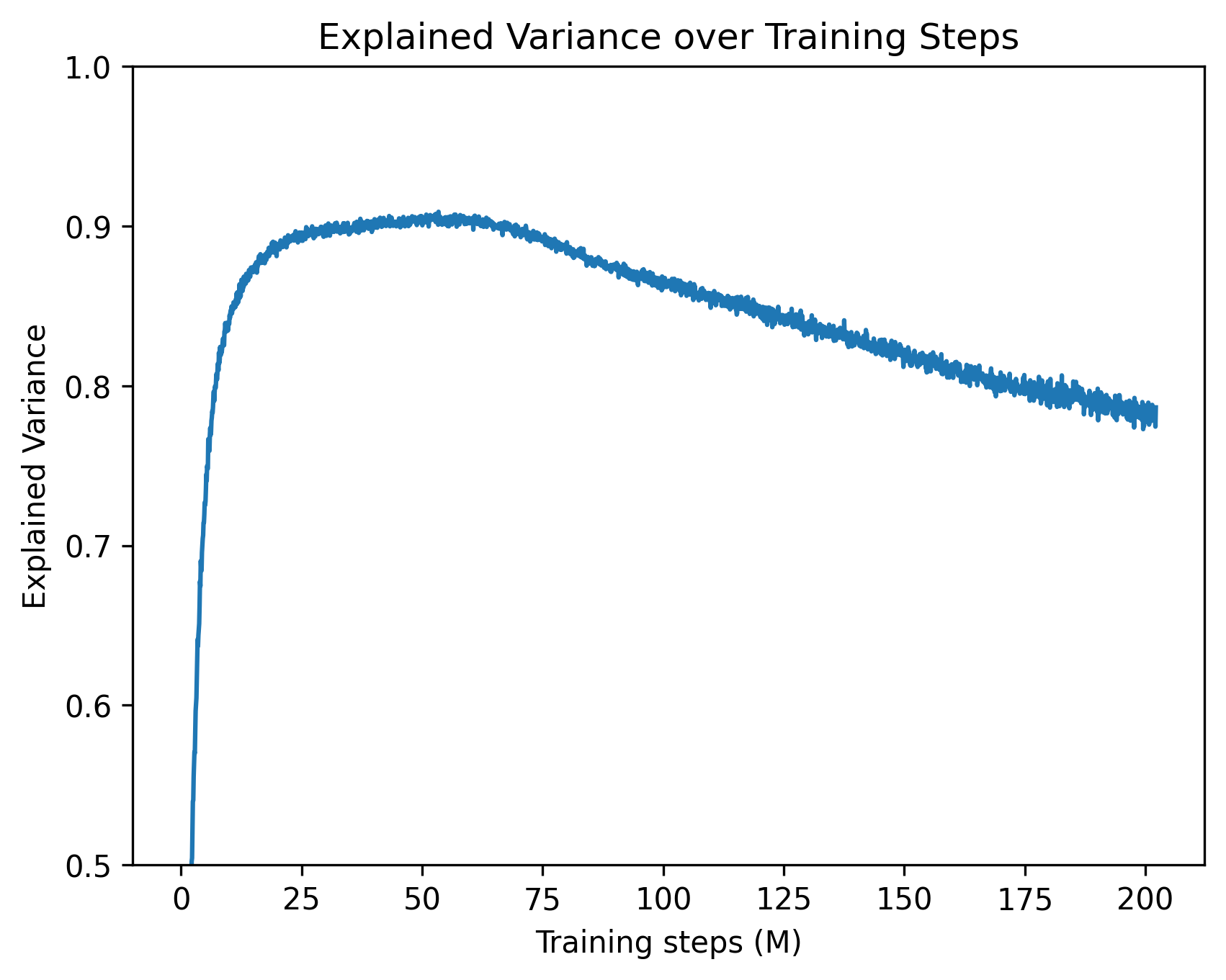
- Strong baseline performance: On GPT-2, their results match prior work: about 0.8 explained variance and ~0.8 replacement score, meaning their learned features and circuits capture much of what the model is doing on common tests (like antonyms or category prompts).
- End-to-end workflow: Instead of juggling many separate tools, CLT-Forge provides one place to train CLTs, auto-explain features, build attribution graphs, and visualize results—speeding up research and making it more reproducible.
What does this work mean for the future?
- Easier, faster mechanistic interpretability: By lowering the compute, storage, and tooling barriers, more researchers can study how LLMs work internally, not just what outputs they produce.
- Better scientific understanding: Clearer, less redundant circuits make it easier to identify which parts of a model handle which tasks, and how information moves across layers.
- Practical tools for safety and debugging: If we can trace and intervene on circuits, we can test model behavior, find failure modes, and potentially guide models toward safer, more reliable reasoning.
- Open questions remain: The authors note that including attention in the graphs, making CLTs more efficient, and directly optimizing better interpretability scores are important next steps.
Final takeaway
CLT-Forge is like a lab kit for opening up an LLM and seeing how its ideas flow and interact. It combines efficient training, smart data compression, automated explanations, circuit tracing, and a visual explorer into one toolkit. This makes it much more practical to study the inner mechanics of large models, helping the community move from “black box” to “glass box” AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues that future work could address:
- Lack of attention attribution: attribution graphs currently freeze attention maps; no implemented method to attribute Q/K/V and attention pathways or to validate their interactions with CLT features at scale.
- Faithfulness of Jacobian-based attribution with frozen nonlinearities remains under-validated across diverse tasks, sequence lengths, and model families; need systematic comparisons to causal interventions and ablation studies.
- Sparse vs dense decoding trade-offs are not explored: no head-to-head comparison of dense CLTs here versus TopK CLTs on fidelity, graph compactness, compute, and interpretability.
- Quantization effects are under-characterized: no thorough study of how int8/int4/int2 activation caching impacts (a) training gradients, (b) decoder weight estimation, (c) attribution edge weights, (d) replacement score; no dequantization-aware training or calibration procedures.
- Storage–accuracy trade-offs lack guidance: no principled criteria for choosing bit-width and chunking that maintain target levels of explained variance and replacement score across models and datasets.
- Limited evaluation breadth: results are mainly on GPT-2 and small prompt suites; no comprehensive benchmarks across larger LLMs (e.g., LLaMA 7B/13B), longer contexts, and varied task families (reasoning, tool use, multilingual, instruction following).
- Replacement score is not directly and stably optimized; no proposed robust surrogate objectives, regularizers, or training curricula that close the proxy gap between reconstruction error and replacement score.
- Missing analysis of graph compactness gains: no quantitative comparison of node/edge counts, redundancy, and cross-layer feature reuse versus standard transcoders under fixed fidelity targets.
- No error propagation analysis: how reconstruction error and encoder/decoder misalignment translate into attribution graph mis-specification and intervention failure is not studied.
- Unclear identifiability and stability: no analysis of whether learned cross-layer features are unique, stable across random seeds/datasets, or prone to rotations/merging/splitting across runs.
- Feature canonicalization is manual: no automated procedures to detect, merge, or align near-duplicate features across layers or checkpoints while preserving attribution correctness.
- Limited assessment of LoRA-style low-rank finetuning for CLTs: no study of when low-rank adapters preserve circuits and feature semantics versus drift, and how to constrain them for faithfulness.
- Scaling limits of feature-wise sharding are not quantified: no measurements of communication overheads, latency at aggregation, optimizer state sharding limits, or failure modes beyond 8×80GB GPUs.
- Missing runtime and cost profiling: no wall-clock throughput, GPU-hours, memory peak reports for key pipeline stages (caching, training, autointerp, attribution) to guide practitioners.
- Context-length scaling is unclear: configs show short contexts (e.g., 16); no evaluation of attribution fidelity, memory, and runtime for realistic context windows (2k–32k).
- Dataset effects and domain shift are unstudied: no analysis of how training/caching data composition affects discovered features, attribution graphs, and generalization to new domains/languages.
- Autointerp quality is not validated: no human evaluation, inter-annotator agreement, or robustness checks for LLM-generated feature explanations; no confidence or calibration signals.
- Coverage of rare features is uncertain: top-K mining over fixed corpora may miss sparse/conditional features; no active data collection, elicitation prompts, or search methods to improve coverage.
- Clustering and higher-level structure creation are interface-only: no algorithmic pipeline or metrics for cluster quality, stability, and causal validity of cluster-level interventions.
- Intervention faithfulness is weakly tested: limited evidence that feature- or cluster-level interventions predictably change model outputs across diverse prompts without off-target effects.
- No ablation of activation functions and sparsity schedules: JumpReLU and specific L0 schedules are used but not compared to alternatives (e.g., hard-k, gate L0, elastic nets) for fidelity and interpretability.
- Hyperparameter selection lacks principled criteria: expansion factor, thresholds, sparsity targets, and penalties are not tied to target metrics, compute budgets, or model size through predictive heuristics.
- Replacement score and graph completeness metrics are under-defined here: no formal definitions, statistical uncertainty estimates, or sensitivity analyses to pruning thresholds and graph construction choices.
- Interactions with attention pruning/sparsification are not integrated: how CLT features co-evolve with sparse attention training (or post-training) and the joint effect on circuits is open.
- Robustness under OOD inputs and adversarial prompts is unknown: no tests of attribution stability and intervention reliability under distribution shift or adversarially constructed sequences.
- Transfer across models is unexplored: no methods to map/align CLT features between different architectures or sizes (e.g., 1B → 7B) to study circuit portability.
- Legal and privacy aspects of activation caching are not discussed: guidance for handling proprietary corpora, PII leakage risks in cached activations, and compliant data management is missing.
- Reproducibility artifacts are incomplete: seeds, exact datasets/splits, tokenizer versions, and detailed configs for all reported numbers (including pruning settings) are not fully documented.
- Theoretical grounding is limited: no formal results on when cross-layer feature sharing improves identifiability, sample complexity, or interpretability relative to layer-local transcoders.
- Benchmark suite is missing: no standardized, open protocol that jointly evaluates reconstruction, replacement score, graph compactness, intervention success, and human interpretability across tasks and models.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented with the released CLT-Forge library and its components today.
- Scalable mechanistic interpretability studies (Academia, Industry — Software/AI)
- What: Train and analyze Cross-Layer Transcoders (CLTs) for open-source LLMs (e.g., GPT-2, LLaMA 1B, Gemma 2B) to uncover interpretable features and feature-level circuits.
- How: Use feature-wise GPU sharding, compressed activation caching (int8/int4/int2 + zstd), and the built-in training runner.
- Tools/workflows: CLTTrainingRunner, ActivationsStore, feature-sharded training; reproducible pipelines for explained variance, replacement score, and graph completeness.
- Assumptions/dependencies: Access to model weights and activations; multi-GPU (e.g., 8×80GB for LLaMA 1B scale) and multi-terabyte storage (reduced by 4–12× via quantization); acceptance of the linear representation hypothesis; training cost budget.
- Automated feature interpretation at scale (Academia, Industry — Software/AI, Governance)
- What: Automatically extract top activating sequences/tokens for millions of features and generate natural-language explanations.
- How: Parallelized autointerp over feature dimension with GPU-resident ranking; optional LLM prompting for explanations.
- Tools/workflows: AutoInterp pipeline with per-worker databases merged into a unified store; one-pass processing over 10M+ tokens.
- Assumptions/dependencies: Access to a capable LLM for high-quality descriptions; dataset permissions; careful prompt design to avoid explanation artifacts.
- Attribution graph analysis and targeted interventions (Industry — Safety, Reliability; Academia — Mechanistic research)
- What: Compute and prune feature-level attribution graphs for specific prompts; test circuit-level interventions and replacements.
- How: Native mapping to Circuit-Tracer to compute causal paths and perform ablations/edits.
- Tools/workflows: AttributionRunner for prompt-conditioned graphs; intervention tooling to measure replacement scores and graph completeness.
- Assumptions/dependencies: Circuit-Tracer integration; fixed attention during attribution (current library limitation); careful interpretation to avoid over-claiming causal significance.
- Internal dashboards for model diagnostics (Industry — MLOps/SWE; Academia — Teaching/Research)
- What: Explore feature sets, activation stats, graphs, and interventions in a Python Dash interface; cluster features and operate at the cluster level.
- How: Launch the CLT-Forge visual interface; integrate with internal logs and A/B evaluation.
- Tools/workflows: Dash-based UI for browsing features, clusters, edges; background jobs for efficient Circuit-Tracer computations.
- Assumptions/dependencies: Hosting and integration into internal platforms; staff familiar with feature-based interpretability.
- Model debugging and regression triage (Industry — Software/AI)
- What: Trace erroneous or surprising model outputs to specific circuits/features to accelerate root-cause analysis across model versions.
- How: Compare attribution graphs and feature activations between model checkpoints; link bugs to circuit changes.
- Tools/workflows: Versioned graph stores; differential attribution analysis; structured bug reports tied to feature clusters.
- Assumptions/dependencies: Access to internal checkpoints; stable evaluation prompts; organizational process buy-in.
- Safety and red-teaming workflows (Industry — Safety; Policy/Compliance)
- What: Identify circuits correlated with jailbreaks, toxic outputs, or prompt injection patterns; design targeted interventions/guardrails.
- How: Use top-activation sequences and attribution graphs to localize harmful circuits, then test interventions’ impact on replacement score and task metrics.
- Tools/workflows: Circuit-level ablation/steering experiments; red-team scenario libraries; dashboards to track risk circuits over time.
- Assumptions/dependencies: Availability of risk prompts; evaluation frameworks for side-effects; risk of false positives/negatives requires careful validation.
- Domain adaptation of CLTs via low-rank finetuning (Industry — Healthcare, Finance, Legal; Academia)
- What: Adapt existing CLTs to domain-specific corpora to accelerate audits of specialized behaviors (e.g., clinical summarization, financial analysis).
- How: Low-rank finetuning of pretrained CLTs to new data without retraining from scratch.
- Tools/workflows: Released low-rank finetuned CLTs; domain-specific autointerp and graph analysis.
- Assumptions/dependencies: Access to domain data; compliance with privacy/PII constraints; domain expert review of interpretations.
- Storage- and compute-efficient activation pipelines (Industry — Infra/ML Platform; Academia — Large-scale experiments)
- What: Reduce activation cache footprint by 4–12× with int8/int4/int2 quantization + zstd; enable practical large-scale CLT/SAE workflows.
- How: Precompute activations in chunks with per-layer symmetric quantization; load on demand during training/analysis.
- Tools/workflows: ActivationsStore with chunked caching and per-layer scales; DDP or feature sharding.
- Assumptions/dependencies: Tolerable 2–3% reconstruction performance trade-off; I/O throughput to sustain training.
- Data governance and memorization triage (Industry — Privacy/Compliance; Academia — Data quality)
- What: Use top-activating sequences for features to flag potential memorization or PII-triggering circuits; assist in decontamination.
- How: Autointerp summary tokens/sequences reveal sensitive patterns; manual or automated flagging pipelines.
- Tools/workflows: Feature-level PII heuristics; sampling and redaction workflows.
- Assumptions/dependencies: Ground-truth labels for PII; privacy review; risk of over-flagging benign features.
- Backdoor/trojan pattern discovery (Industry — Security; Academia — Robustness)
- What: Detect features highly associated with rare trigger patterns; investigate prompt-conditional circuits.
- How: Scan for features with spiky activation distributions and analyze circuits via attribution graphs.
- Tools/workflows: Triggered prompt sets; circuit-level anomaly detection.
- Assumptions/dependencies: Availability of suspected triggers; careful statistical thresholds; expert review.
Long-Term Applications
These applications are enabled by CLT-Forge advances but require additional research, scaling, integration, or standardization before routine deployment.
- Real-time circuit-aware guardrails (Industry — Safety, Product; Software)
- Vision: Use circuit/feature activation monitors at inference time to gate, reroute, or rewrite outputs in low latency.
- Potential workflow: Preselect sentinel features/circuits; compile detectors; integrate into serving stack with budgeted latency.
- Dependencies/assumptions: Robust generalization of circuit detectors; attention attribution integration; efficient on-device activation extraction; rigorous evaluation of side effects.
- Full-path attribution including attention (Academia, Industry — Safety/Debugging)
- Vision: Joint MLP+attention circuit tracing for comprehensive causal graphs of computations.
- Potential workflow: Incorporate attention-tracing methods into CLT-Forge; end-to-end path discovery and pruning.
- Dependencies/assumptions: Methods from ongoing work on attention attribution; computational overhead; validation on large models.
- Mechanistic compliance reporting and standards (Policy/Regulation; Industry — Risk/Legal)
- Vision: Standardized circuit-level audit artifacts for regulatory frameworks (e.g., EU AI Act, sector-specific guidance).
- Potential workflow: Templates for circuit inventories, intervention tests, risk circuit dashboards, and reproducible reports.
- Dependencies/assumptions: Regulator-accepted metrics (e.g., replacement score), community consensus on evidence standards; third-party audit platforms.
- Model editing and steering via feature-level optimization (Industry — Product Safety/Reliability; Academia)
- Vision: Stable, generalizable editing of behaviors by reinforcing, suppressing, or re-targeting specific feature circuits.
- Potential workflow: Training loops that penalize/encourage activation patterns; cluster-level steering with rollback and evaluation.
- Dependencies/assumptions: Robust objectives (replacement-score optimization is currently unstable); safeguards against collateral damage; guarantees on behavior persistence.
- Interpretability-driven pruning, compression, and efficiency (Industry — Inference/Serving; Academia)
- Vision: Use circuit insights to remove redundant pathways, prune neurons, or design compressed modules with retained behavior.
- Potential workflow: Identify low-contribution features/circuits; prune and re-evaluate; iterative fine-tuning.
- Dependencies/assumptions: Reliable contribution metrics; preservation of accuracy/safety; transferability across distributions.
- Automated dataset repair and decontamination (Industry — Data Ops; Academia)
- Vision: Systematically identify data artifacts that drive undesirable circuits and repair or rebalance training sets.
- Potential workflow: Trace circuits to high-activation examples; curate/weight data; retrain or post-train with targeted fixes.
- Dependencies/assumptions: Data access and provenance; scalable retraining; clear measures of improvement.
- Cross-modal and robotics circuit tracing (Industry — Robotics, Vision-Language; Academia)
- Vision: Extend CLT-Forge’s methods to VLMs and policies to trace perception–language–action circuits.
- Potential workflow: Adapt activation caching, sharding, and attribution to multi-stream architectures; intervention on policy circuits.
- Dependencies/assumptions: Architectural extensions; real-world safety validation; synchronization across modalities.
- Domain-assured reasoning in high-stakes settings (Industry — Healthcare, Finance, Legal; Policy)
- Vision: Validate that model reasoning adheres to domain constraints by inspecting and auditing domain-specific circuits.
- Potential workflow: Domain-tuned CLTs; curated evaluation prompts; clinician/analyst-in-the-loop review; deployment checklists.
- Dependencies/assumptions: Strong domain datasets; privacy-preserving pipelines; rigorous outcome validation and governance.
- Community knowledge bases of circuits (Academia, Open-Source; Industry — Shared Safety)
- Vision: Shared repositories of circuits, features, and interventions across models and tasks to accelerate discovery and reuse.
- Potential workflow: Standardized schemas for feature stores and graphs; contribution guidelines; federation with Neuronpedia-like platforms.
- Dependencies/assumptions: Licensing, data-sharing agreements; quality control; sustainability models.
- Benchmark ecosystem and objective development (Academia, Industry)
- Vision: Leaderboards and standardized tasks for replacement score, graph completeness, and intervention robustness; improved objectives for training CLTs.
- Potential workflow: Public benchmarks, reproducible pipelines, and shared baselines integrated with CLT-Forge.
- Dependencies/assumptions: Community consensus on metrics; compute resources; iterative improvements in training stability.
- Privacy-preserving mechanisms via circuit detection (Industry — Privacy/Security; Policy)
- Vision: Detect and suppress circuits associated with memorized secrets or PII leakage before deployment.
- Potential workflow: Feature-level privacy risk scoring; automated suppression/intervention policies; monitoring in production.
- Dependencies/assumptions: Reliable memorization detection; minimal performance impact; alignment with privacy regulations.
- Energy- and cost-aware large-scale interpretability (Industry — Infra/Sustainability; Academia)
- Vision: Use activation caching, quantization, and sharding patterns to reduce energy/cost footprints of interpretability at scale.
- Potential workflow: Reusable cache repositories; scheduling to minimize I/O; greener experiment planning.
- Dependencies/assumptions: Further algorithmic efficiency; organizational incentives to prioritize sustainability.
Glossary
- Activation caching: Precomputing and storing intermediate neural activations to accelerate training or analysis workflows while reducing repeated compute. "activation caching with quantization and compression for memory efficiency."
- Automated interpretability (autointerp): An automated pipeline that collects activations, summarizes top activations, and prompts an LLM to generate feature explanations. "Built-in workflow for automated interpretability (autointerp) with flexible visual interface"
- Automatic mixed precision (AMP): Training technique that mixes floating-point precisions to improve speed and memory usage with minimal accuracy loss. "we use automatic mixed precision (AMP) with scaling when using float16."
- Attribution graph: A graph whose nodes are features and whose edges capture causal influence across layers and positions, used to explain model computations. "compute and prune the attribution graph and perform interventions when needed."
- Attribution score: A scalar measuring the contribution of one feature to another across positions/layers, typically via decoder/encoder vectors and a Jacobian term. "Following \citep{ameisen2025circuit}, the attribution score between feature at layer and position , and feature at layer and position is:"
- bfloat16: A 16-bit floating-point format with an 8-bit exponent that preserves dynamic range, often used for stable and efficient training. "we find that training in bfloat16 is stable."
- Circuit-Tracer: An open-source library for computing and pruning feature-level attribution graphs and running interventions. "This workflow has been open-sourced in the Circuit-Tracer library \citep{hanna2025circuit}."
- Cross-Layer Transcoders (CLTs): Transcoder models that share a feature space across layers while allowing layer-specific decoding, yielding compact, interpretable representations. "Cross-Layer Transcoders (CLTs) address this issue by sharing features across layers while allowing layer-specific decoding \citep{ameisen2025circuit}."
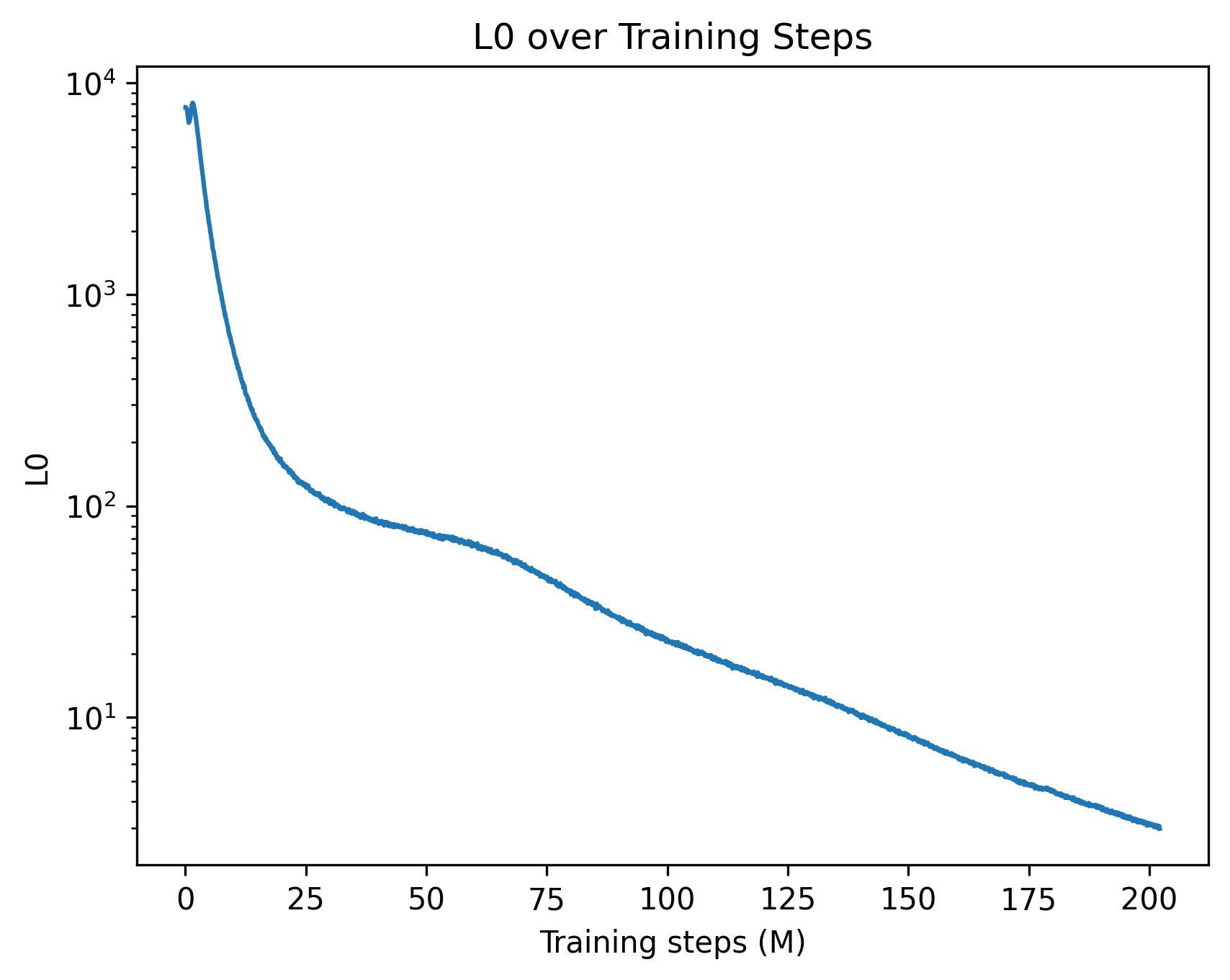
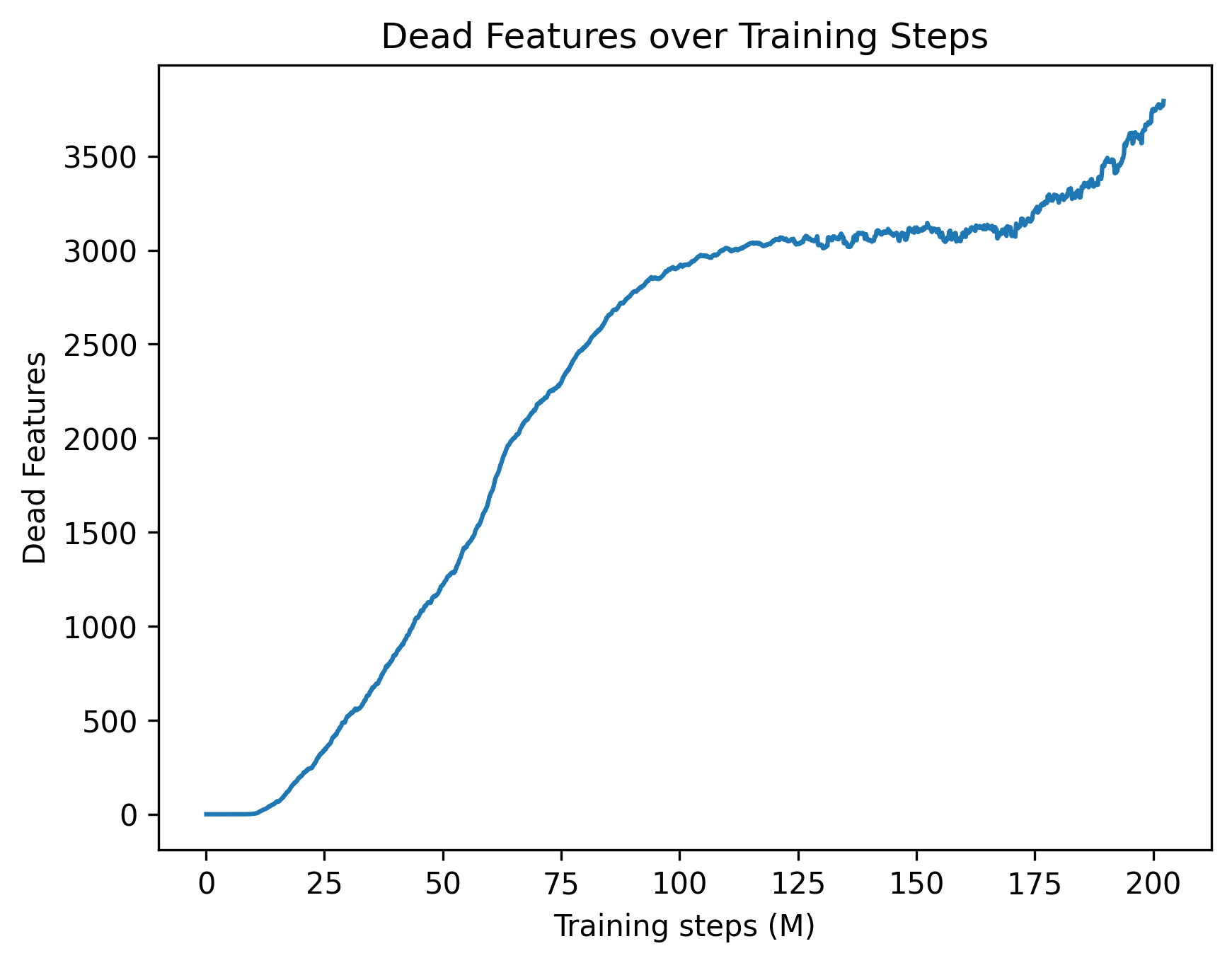
- Dead features: Learned features that rarely activate and thus contribute little; often penalized or revived via regularization. "d) Number of dead features on average per layer."
- Dictionary learning: Methods that learn sparse, interpretable basis features (a “dictionary”) to represent activations or computations. "Recent approaches based on dictionary learning and transcoders enable representing model computation in terms of sparse, interpretable features"
- Distributed Data Parallel (DDP): A multi-GPU training strategy that replicates model parameters across devices and synchronizes gradients via data parallelism. "Other libraries support CLT training for smaller-scale models (e.g., GPT-2) using Distributed Data Parallel (DDP)"
- Explained variance: Fraction of variance in target activations reconstructed by a model, used to assess reconstruction fidelity. "achieving 0.8 explained variance at total "
- Expansion factor: The multiplicative ratio by which the feature dimension exceeds the model dimension in a transcoder/CLT. "we reach an expansion factor of 48 (approximately 1.5 million features)"
- Feature-wise sharding: A parallelization scheme that partitions features across devices, aggregating outputs after per-shard computation. "we instead adopt a feature-wise sharding approach, where features are split across multiple GPUs."
- Fully Sharded Data Parallel (FSDP): A training approach that shards model states, gradients, and optimizer states across devices to reduce memory usage. "Although Fully Sharded Data Parallel (FSDP) could help in this front, it remains suboptimal for CLT architectures"
- Graph completeness: A metric indicating how fully an attribution graph captures the relevant mechanisms needed for a task or behavior. "graph completeness of 0.95 on standard prompts"
- Jacobian: The matrix of partial derivatives mapping changes in one layer’s outputs to another layer’s inputs, used for attribution. "The term is the Jacobian mapping the MLP output at to the MLP input at ."
- JumpReLU: A sparsifying activation function designed to improve reconstruction fidelity in sparse autoencoders/transcoders. "In practice, we use JumpReLU as ."
- Linear representation hypothesis: The idea that semantic features correspond to linear directions in a network’s activation space. "the linear representation hypothesis, which posits that semantic features are encoded as directions in the activation space of neural networks"
- Low-rank finetuning: Adapting a large model by training low-rank parameter updates, reducing compute/memory compared to full retraining. "we incorporated low-rank finetuning for efficient adaptation of pretrained CLTs without computationally expensive retraining."
- Model sharding: Splitting a model’s parameters across devices to fit memory limits and enable larger-scale training. "efficient distributed training with optimal model sharding, or activation caching with quantization and compression for memory efficiency."
- Replacement score: A metric evaluating how well reconstructed activations can replace originals without degrading downstream performance. "a replacement score of 0.8"
- Sparse autoencoder (SAE): An autoencoder trained with sparsity constraints to discover interpretable features in model activations. "such as an SAE or a CLT"
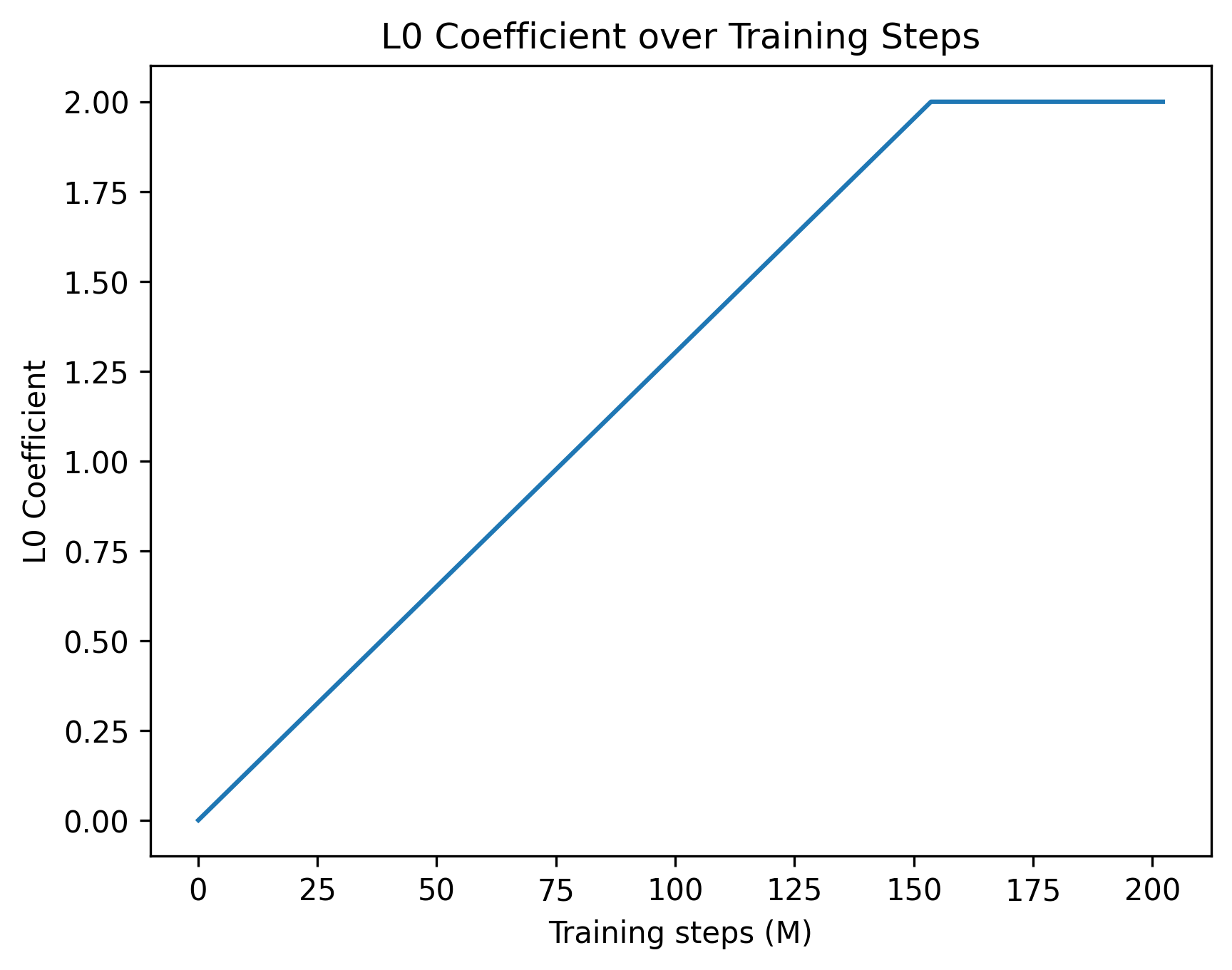
- Sparsity schedulers: Training schedules that modulate sparsity regularization over time to control feature activation density. "we support multiple sparsity schedulers while using JumpReLU as the activation function."
- Stop-gradient operation: A technique that prevents gradients from flowing through certain operations, effectively freezing nonlinearities during attribution. "nonlinearities have been frozen with a stop-gradient operation."
- Symmetric per-layer quantization: Quantization that uses a symmetric scale per layer (based on max absolute value) to compress activations. "we apply symmetric per-layer quantization, which involves computing a scale factor from the maximum absolute activation per layer, followed by zstd entropy coding."
- TopK CLTs: A CLT variant that decodes using only the top-K most active features, enforcing decoding-time sparsity. "their work focuses on TopK CLTs, where only a small subset of features is active during decoding."
- zstd entropy coding: A compression algorithm applied to quantized data to reduce storage via entropy coding. "followed by zstd entropy coding."
Collections
Sign up for free to add this paper to one or more collections.

