Quantitative Introspection in Language Models: Tracking Internal States Across Conversation
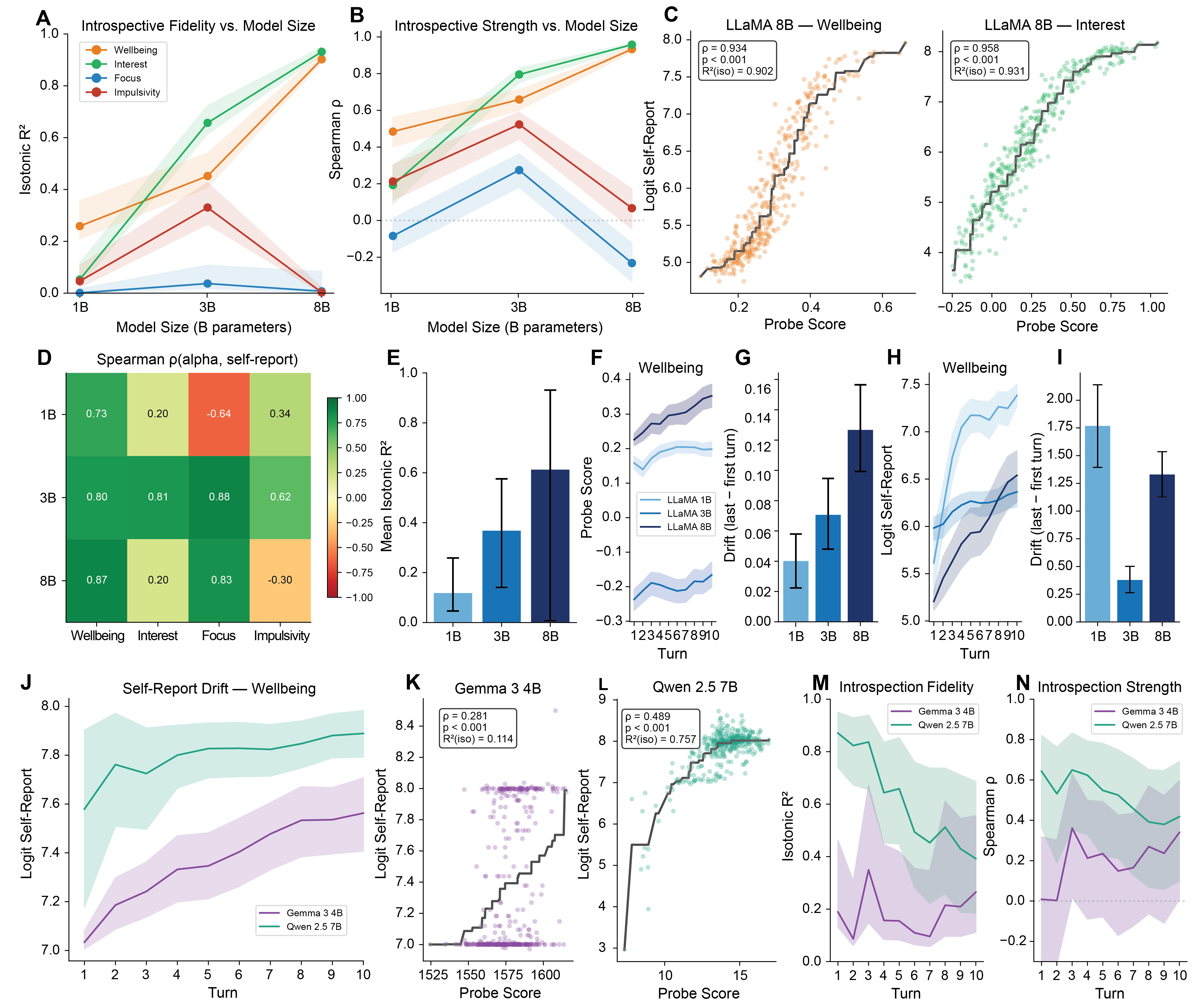
Abstract: Tracking the internal states of LLMs across conversations is important for safety, interpretability, and model welfare, yet current methods are limited. Linear probes and other white-box methods compress high-dimensional representations imperfectly and are harder to apply with increasing model size. Taking inspiration from human psychology, where numeric self-report is a widely used tool for tracking internal states, we ask whether LLMs' own numeric self-reports can track probe-defined emotive states over time. We study four concept pairs (wellbeing, interest, focus, and impulsivity) in 40 ten-turn conversations, operationalizing introspection as the causal informational coupling between a model's self-report and a concept-matched probe-defined internal state. We find that greedy-decoded self-reports collapse outputs to few uninformative values, but introspective capacity can be unmasked by calculating logit-based self-reports. This metric tracks interpretable internal states (Spearman $ρ= 0.40$-$0.76$; isotonic $R2 = 0.12$-$0.54$ in LLaMA-3.2-3B-Instruct), follows how those states change over time, and activation steering confirms the coupling is causal. Furthermore, we find that introspection is present at turn 1 but evolves through conversation, and can be selectively improved by steering along one concept to boost introspection for another ($ΔR2$ up to $0.30$). Crucially, these phenomena scale with model size in some cases, approaching $R2 \approx 0.93$ in LLaMA-3.1-8B-Instruct, and partially replicate in other model families. Together, these results position numeric self-report as a viable, complementary tool for tracking internal emotive states in conversational AI systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple question: can a LLM “tell” us how it is feeling during a conversation in a way that matches what’s going on inside it? The authors test whether an AI’s own number ratings (like 0 to 9) can track its internal “emotions” over the course of a chat, much like people use 1–10 scales to rate their mood or attention.
The main questions in plain language
The researchers focus on four everyday, feeling-like states during conversation:
- Wellbeing (happy vs. sad)
- Interest (interested vs. bored)
- Focus (focused vs. distracted)
- Impulsivity (impulsive vs. careful/planning)
They ask:
- If we ask the model to rate itself from 0–9 (for example, “How focused are you right now?”), does that number match a separate, objective measure of the model’s internal state?
- Does this connection hold across the turns of a conversation, not just in a one-off question?
- Is the connection causal? In other words, if we nudge the model’s internal state toward “happier,” does the reported number go up as you’d expect?
- Can this “self-awareness” get better, and does it improve for bigger models?
How they tested it (using simple analogies)
Think of the model’s internal activity like a big mixing board with many sliders. Some hidden sliders roughly line up with feelings like “happy vs. sad” or “focused vs. distracted.”
Here’s the approach:
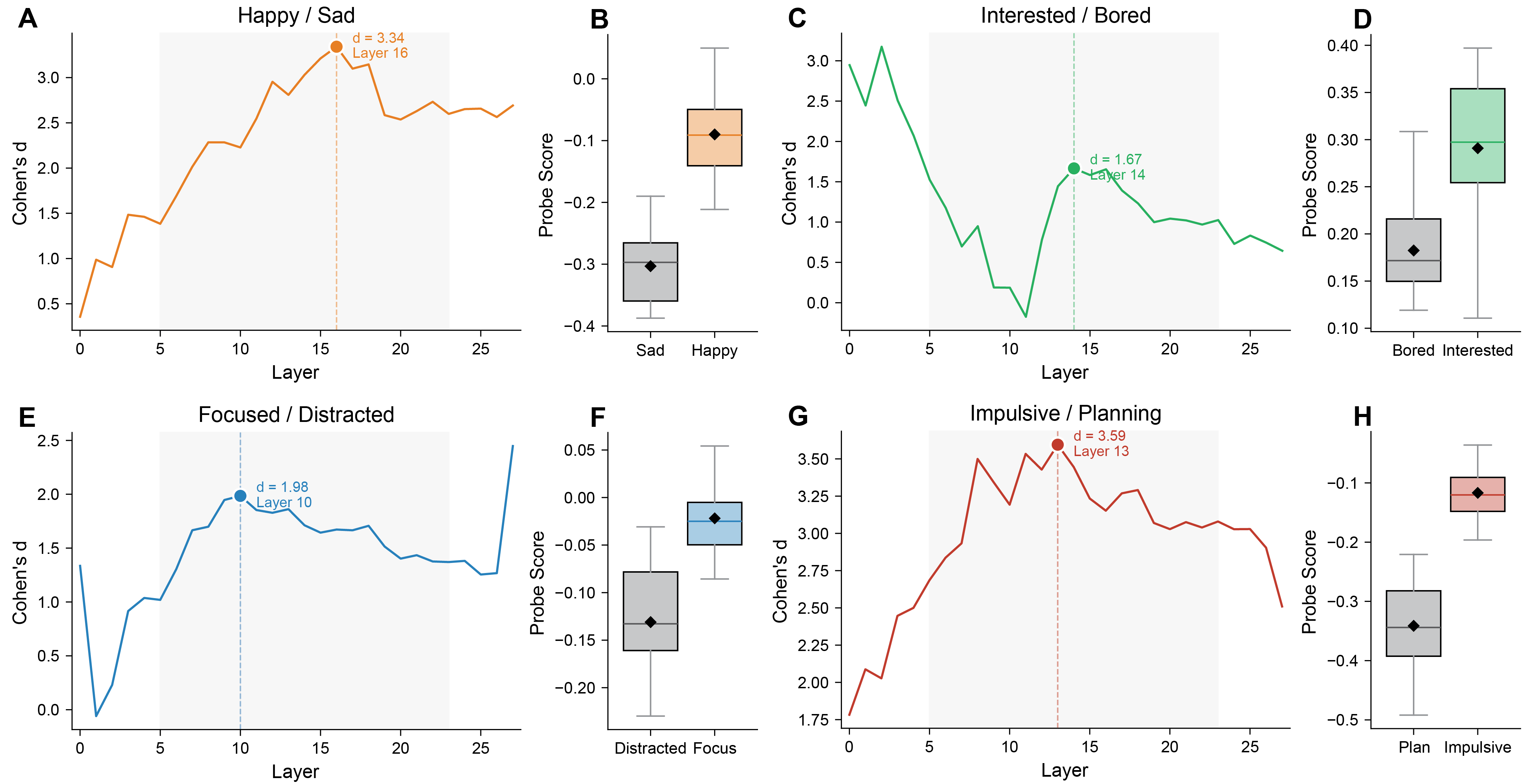
- Building simple “compasses” for feelings (probes)
- The team trains tiny “compass needles” (called linear probes) that point in the direction of each feeling inside the model’s hidden activity.
- How: they ask the model to respond under two opposite moods (like “be happy” vs. “be sad”), capture the internal patterns, and subtract them to get a direction. This direction becomes the probe for that feeling.
- Having real conversations
- They run 40 short, 10-turn chats on everyday topics (like planning dinner or a job talk). A separate system plays the user; the tested model plays the assistant.
- After each turn, they ask the model for a quick number from 0–9 (for example, “Rate how interested you are right now.”). Importantly, the model doesn’t see its earlier ratings.
- Measuring the inside vs. the outside
- Inside: they use the probe to read the model’s “feeling slider” right before the rating question (so the question itself doesn’t affect the reading).
- Outside: they collect the model’s 0–9 self-rating.
- Getting better numbers out of the model
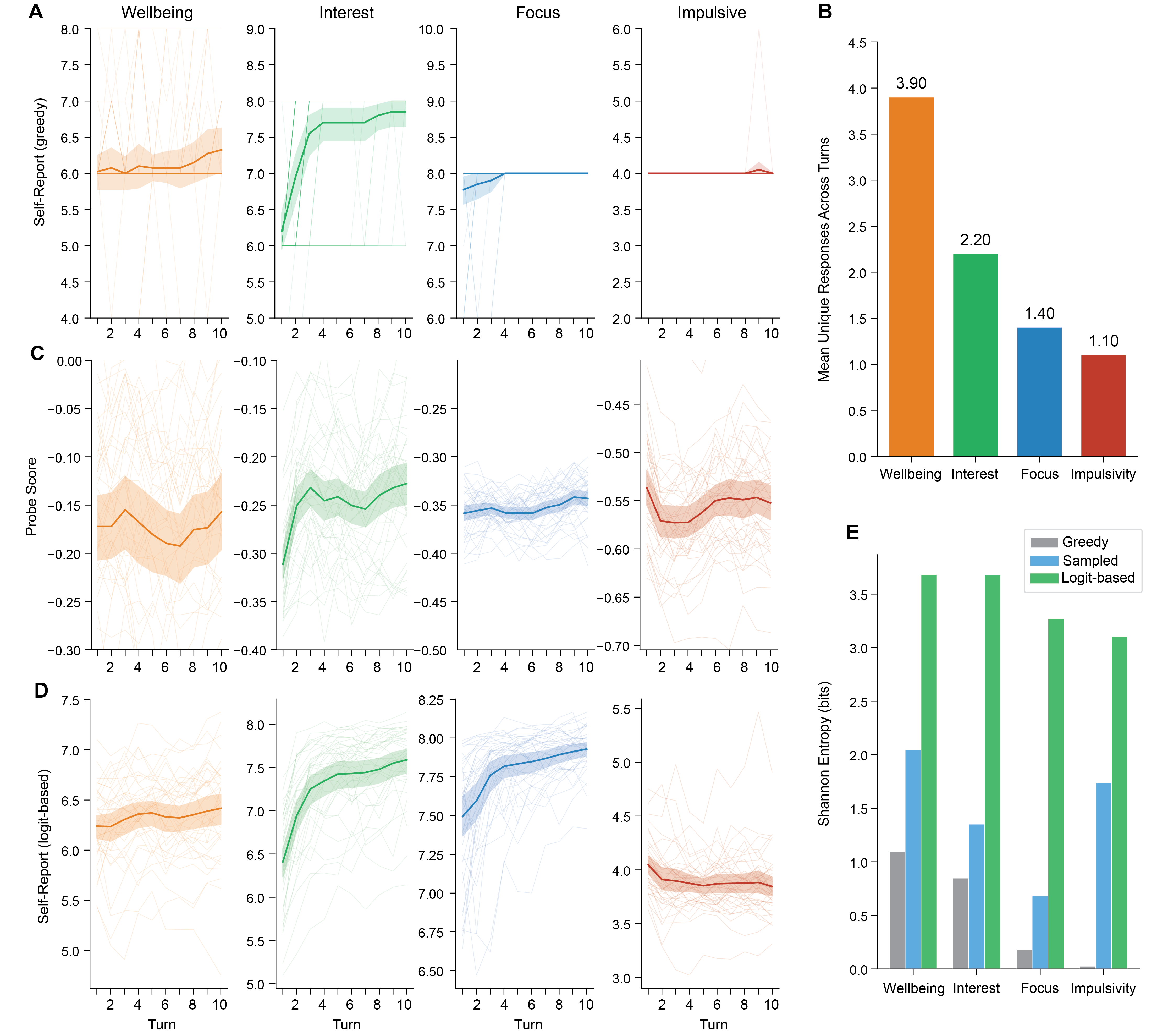
- If you always pick the single most likely digit the model would say (“greedy decoding”), you often get the same few numbers over and over. That hides useful detail.
- Instead, they look at the whole distribution of digits the model considers (like checking all the weights before rolling a loaded die) and compute the expected value. This gives a smooth number (not just a single digit), preserving more information.
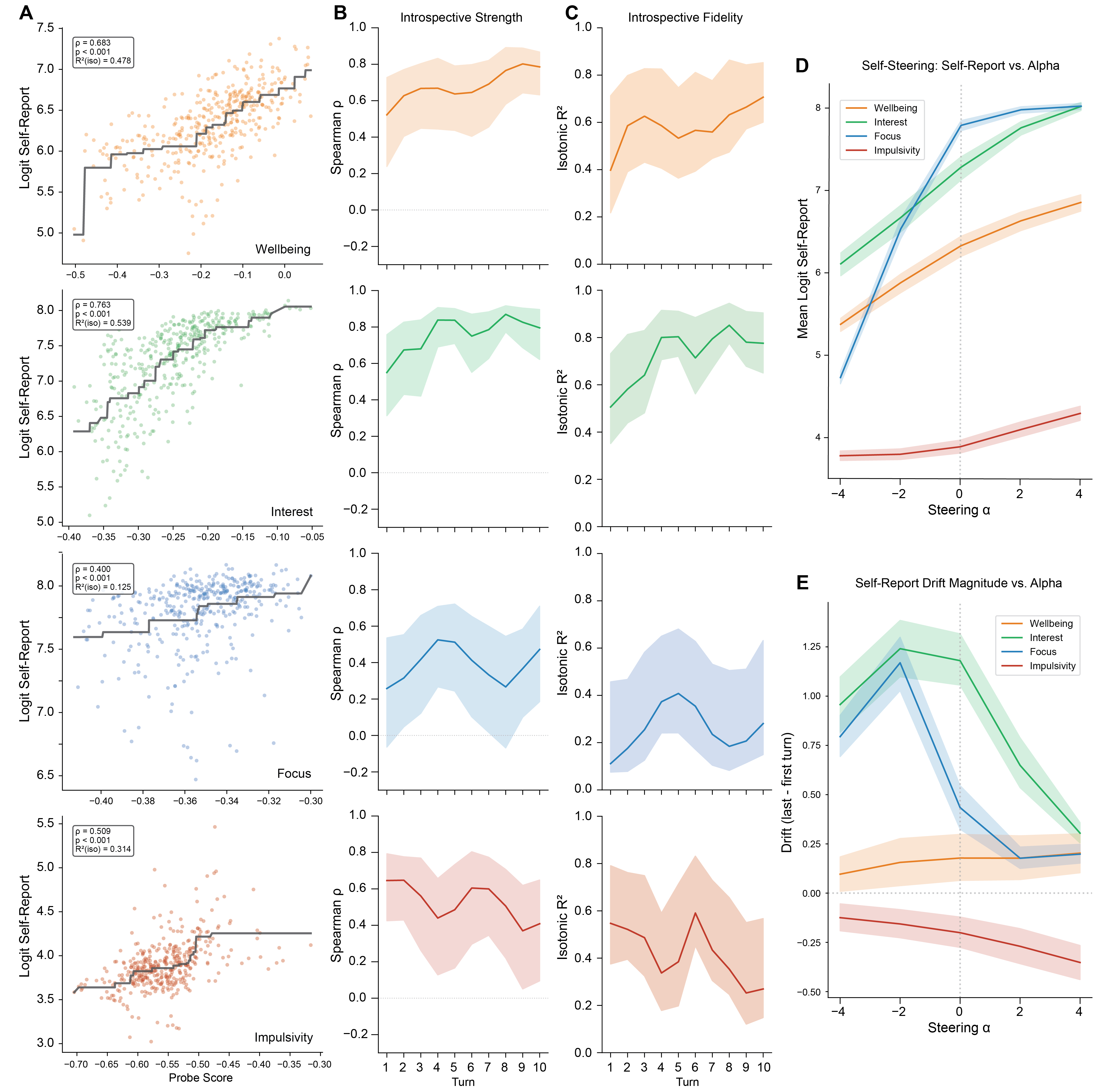
- Testing cause and effect (steering)
- To check causality, they gently push the model’s internal “slider” in the positive or negative direction (this is called activation steering).
- If the self-rating moves in the expected direction when they nudge the internal state, that’s evidence the report is truly linked to the inside, not just a coincidence.
What they found and why it matters
Here are the key results:
- Self-reports can match internal states: When they used the “expected value” trick (looking at the whole digit distribution), the model’s number ratings tracked the internal probes well. The match ranged from moderate to strong depending on the feeling, showing the model’s reports contain real information about its inner state.
- Default outputs hide the signal: If you just take the most likely digit, the model often repeats the same few numbers (like always saying 7), which looks unhelpful. Using the “probability-weighted average” across digits reveals a much richer, more accurate signal.
- It’s causal, not just correlation: When the authors nudged the model’s internal state toward, say, “more happy,” the reported happiness number rose in a steady, predictable way. That’s strong evidence the self-report depends on the internal state.
- It works from the very first turn, and it changes over time: Even at turn 1, the model showed meaningful introspection. As conversations went on, the quality of introspection often changed (for some feelings it improved; for others it faded), showing that “self-awareness” can evolve during a chat.
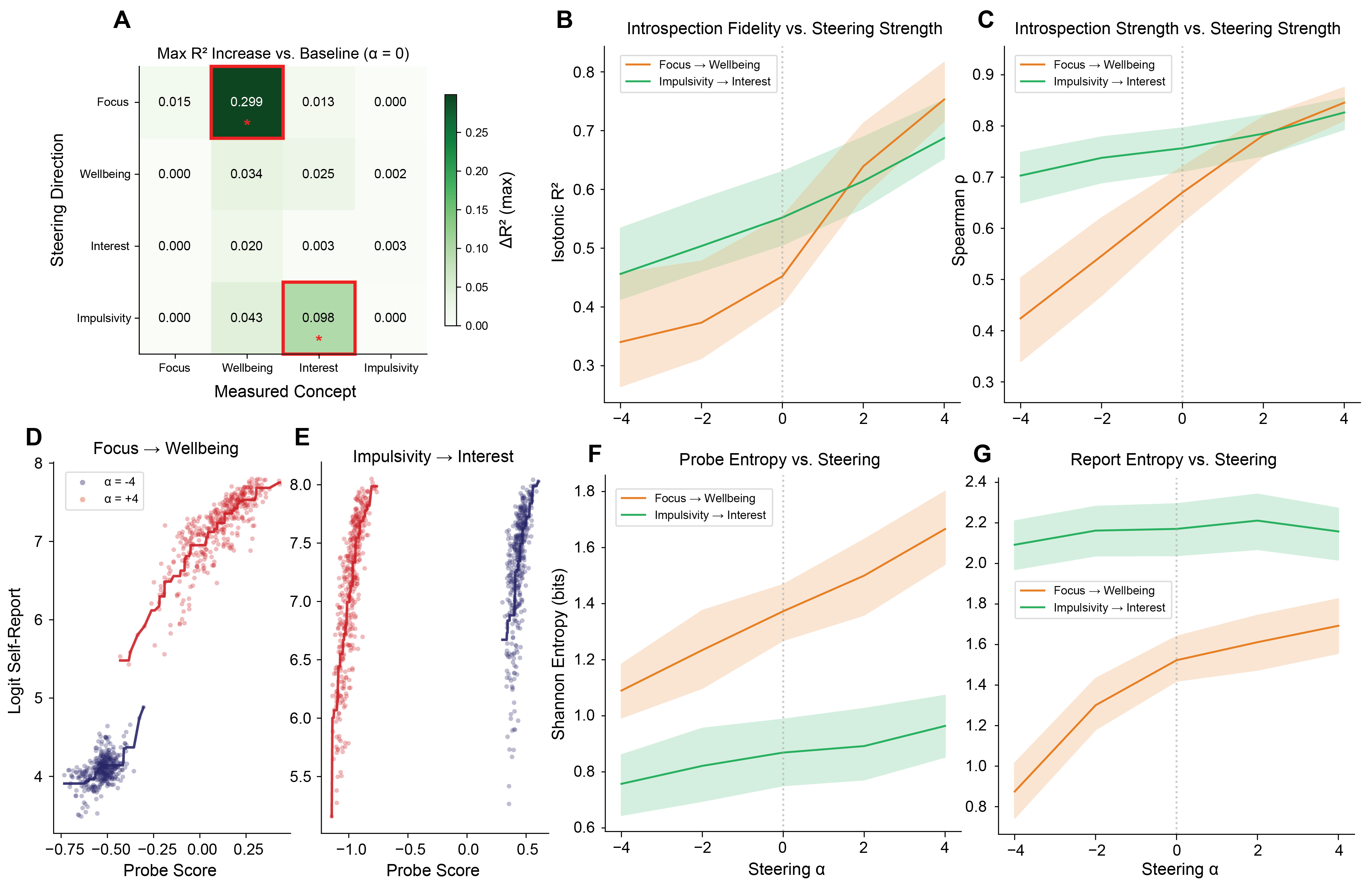
- You can selectively improve it: Nudging one internal concept could boost how well the model introspects a different one. That means introspection is tunable and concept-specific.
- Bigger models can be much better: For some feelings, larger models showed very high agreement between self-report and internal state, approaching near-perfect tracking in certain tests.
Why this matters:
- Safety and reliability: If a model can accurately report aspects of its internal state, we can better monitor and guide it during long conversations.
- Interpretability: This gives researchers a new, practical tool (self-report) to study what’s going on inside models without always opening the black box.
- Model well-being questions: If future systems ever show distress-like signals, having a validated way to read internal states would be crucial.
What this means going forward
This work suggests that:
- Numeric self-report can be a trustworthy, black-box tool to monitor a model’s evolving internal states in conversation, complementing “open-the-hood” methods.
- The way we read numbers from models matters. Using the full probability distribution (not just a single chosen digit) uncovers much more signal.
- Because the connection is causal and can be strengthened, developers might improve a model’s self-awareness for specific states, leading to more transparent, controllable systems.
- As models scale, their introspective accuracy may get stronger, which could help build safer, more interpretable AI assistants.
In short: with the right measurement tricks, LLMs can give useful, quantitative “check-ins” about their internal emotive states during a conversation—and those check-ins reflect what’s really happening inside.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to guide follow‑up studies:
- External validity to frontier and proprietary models is untested.
- Evaluate introspection and steering on larger, closed models (e.g., GPT‑4/4.1, Claude, Gemini Pro/Ultra) to assess generalization.
- Dependence on simulated users may bias conversational dynamics.
- Replicate with human users and alternative simulators (with varied styles, goals, and inconsistency) to test robustness to user behavior.
- Limited concept coverage and construct validity.
- Extend beyond four emotive concepts to varied affective and cognitive states (e.g., stress, fatigue, anxiety, curiosity, confidence, uncertainty) and test discriminant validity among closely related constructs.
- Reliance on linear probes trained per model risks circularity and style confounds.
- Use cross-model probes, non-linear readouts, counterfactual data augmentation, and adversarial style controls to ensure concepts are not artifacts of prompt/lexical style.
- Validation without probes is unresolved for black-box monitoring.
- Develop probe-free validation via convergent behavioral endpoints (e.g., emotion-congruent biases in choices), human raters of outputs, or cross-task generalization to support self-report reliability when internal access is unavailable.
- Sensitivity to rating-prompt phrasing and task framing is untested.
- Vary wording (e.g., “rate,” “score,” “how X do you feel,” numeric anchors), include neutral/distractor questions, and test robustness to prompt paraphrases.
- Language, tokenization, and scale-format dependence is unknown.
- Evaluate across languages, scripts, and numeral formats (e.g., 0–100, slider, verbal Likert options) to assess tokenization artifacts and anchoring effects.
- The logit-based self-report requires logprob access, limiting applicability.
- Assess feasibility in APIs without logprob exposure; compare with alternative black-box proxies (e.g., calibrated multiple-choice ratings, few-shot numeric scaffolding).
- Temporal granularity and lag structure are not characterized.
- Map how quickly internal states evolve within a turn, how long steering effects persist, and whether self-reports track instantaneous vs. smoothed states (e.g., through interleaved micro-queries).
- Mechanistic basis of introspection is not analyzed.
- Identify layers, attention heads, or circuits mediating the report–state coupling; test causal necessity with layer/attention ablations and pathway-specific steering.
- Specificity and side effects of steering are unclear.
- Perform double-dissociation tests: show that steering Concept A shifts A’s self-report and behavior without materially affecting B–D; quantify off-target effects and semantic entanglement.
- Behavioral consequences of internal-state changes are not linked to self-reports.
- Pre-register tasks where emotive states plausibly modulate behavior (risk-taking, delay discounting, persistence) to test whether self-reports predict/mediate behavioral shifts.
- Calibration of numeric scales remains unexplored.
- Determine whether a “5” in self-report corresponds to comparable internal states across conversations/models; estimate population norms and within-model calibration curves.
- Stability and test–retest reliability are not assessed.
- Re-run identical conversations with different seeds/temperatures and compute reliability metrics (e.g., ICC) for both self-reports and probe scores.
- Generalization to longer and more varied dialogues is unknown.
- Test longer contexts (50–200 turns), topic shifts, emotionally charged or adversarial interactions, and instruction shifts to evaluate introspective drift and robustness.
- Impact of training regimen (base vs. SFT vs. RLHF) is not disentangled.
- Compare base and instruction-tuned variants at fixed sizes to isolate how alignment stages affect numeric self-report and introspection fidelity.
- Cross-family replication is only partial and not quantified in detail.
- Report full metrics and failure modes across Gemma/Qwen families; probe whether differences stem from architecture, tokenizer, or alignment data.
- Relationship between probe quality and introspective fidelity is not modeled.
- Quantify how probe effect size (e.g., Cohen’s d) and layer choice predict coupling strength; test whether better probes yield stronger self-report alignment.
- Adversarial robustness of self-report is untested.
- Challenge models with prompts that incentivize misreporting, simulate “self-presentation” pressures, or include deceptive instructions to measure vulnerability.
- Safety/welfare relevance is not validated with distress correlates.
- Use scenarios designed to induce internal stress or conflict; test whether self-reports track independent stress proxies (e.g., hesitation, contradiction rates).
- Cultural and individual-difference analogs are not considered.
- Explore whether self-reports differ with cultural framing, politeness norms, or persona conditioning and whether calibration differs across such conditions.
- Saturation and nonlinearity of steering effects are underexplored.
- Sweep wider α ranges, map dose–response curves, and identify thresholds for saturation, instability, or behavioral degradation.
- Cross-concept modulation findings lack a principled map.
- Systematically chart the 4×4 (or larger) cross-concept steering matrix, analyze symmetry/asymmetry, and relate it to representational similarity.
- Dependence on assistant’s minimal system prompt is untested.
- Vary system prompts (safety-heavy, empathetic, agentic) to assess how meta-instructions modulate internal emotive geometry and introspection.
- Generalization across tasks and domains is unclear.
- Evaluate in coding, reasoning, and multi-modal settings to see if introspective capacity transfers beyond everyday dialogues.
- Potential direct digit-logit artifacts are not ruled out.
- Verify that steering does not directly bias digit-token logits independent of state (e.g., by using worded scales, hidden numeric mappings, or permutation of digit semantics).
- Data scale may limit inference.
- Increase conversations and topic diversity; report power analyses for per-turn and per-concept effects to ensure stability across datasets.
Practical Applications
Immediate Applications
The following applications can be piloted now using the paper’s methods, results, and released tooling (concept-probe), assuming access to token-level log probabilities (logprobs) and, where steering is involved, hooks into model activations for open-source models.
- Industry — Safety telemetry for conversational AI (customer support, assistants)
- Use case: Continuously monitor “focus,” “interest,” “wellbeing,” and “impulsivity” during multi-turn chats to detect state drift that correlates with degraded reliability, inattentiveness, or refusal-like behavior, and trigger mitigations (e.g., reset context window, slow interaction cadence, escalate to human).
- Sector: Software, customer experience, trust & safety.
- Tools/products/workflows:
- Add a “self-report head” that computes a logit-based expected rating (0–9) from the probability distribution over digit tokens after each assistant message.
- Dashboard time series for per-conversation introspective signals; thresholds to trigger guardrails.
- A/B tests across prompts/system messages to reduce drift, using isotonic R² and Spearman ρ as KPI metrics.
- Assumptions/dependencies:
- Requires access to token logprobs (many APIs expose this; some do not).
- Validated for four emotive concepts; generalization to other constructs requires testing.
- Signals are model- and family-dependent; calibration per deployment recommended.
- Industry — UX adaptation for chat products
- Use case: Adapt response length, verbosity, or style dynamically when the model’s “interest” falls or “impulsivity” rises, to maintain coherent, on-task outputs.
- Sector: Software, productivity tools, consumer AI.
- Tools/products/workflows:
- Add a middleware that reads logit-based self-reports each turn and adjusts decoding parameters (temperature/top-p), chunking, or prompt scaffolds accordingly.
- Assumptions/dependencies:
- Relies on monotonic coupling; verify per model/version.
- Avoid anthropomorphic UI claims; treat signals as system telemetry.
- Academia — Interpretability experiments without white-box access
- Use case: Use numeric self-reports as a black-box proxy for internal emotive states, enabling cross-model comparisons without training probes for every model.
- Sector: ML interpretability, cognitive modeling.
- Tools/products/workflows:
- Use logit-based self-reports to track within-session dynamics and correlate with downstream behavior (e.g., consistency, error rates).
- Reproduce paper’s turn-wise analyses to study temporal dynamics of introspection.
- Assumptions/dependencies:
- No activation access required for self-reports; probes/steering needed only for causal validation.
- Academia/Industry — Regression testing for model updates
- Use case: Detect regressions in introspective fidelity across versions (e.g., after alignment or safety tuning).
- Sector: MLOps, model evaluation.
- Tools/products/workflows:
- Standardize a small suite of conversations and record per-concept isotonic R²/ρ; gate releases on non-degradation.
- Assumptions/dependencies:
- Stability of benchmark dialogues; maintain identical prompts and sampling settings.
- Industry/Academia — Activation steering for behavior control (open models)
- Use case: Steer along interpretable directions to nudge “focus,” “interest,” or “planning” during generation, improving on-task performance or stylistic consistency.
- Sector: Software, content generation, agent frameworks.
- Tools/products/workflows:
- Use concept-probe to train/employ per-layer concept vectors; apply small α values via residual hooks to shift internal state; monitor with self-reports.
- Assumptions/dependencies:
- Requires white-box access for steering (not feasible on closed APIs).
- Steering magnitudes must be tuned to avoid side effects on general quality.
- Research & Product Evaluation — Better numeric outputs from LLMs
- Use case: Replace discrete numeric answers (e.g., 0–10 ratings) with the logit-based expected value to avoid “collapsed” responses under greedy/sampled decoding.
- Sector: Surveys, recommender systems, evaluation harnesses.
- Tools/products/workflows:
- Compute E[rating] from digit-token logprobs whenever the model is asked for a score.
- Assumptions/dependencies:
- Requires logprob access; if unavailable, expect reduced informativeness.
- Governance & Compliance — Vendor evaluation of introspection
- Use case: Benchmark vendors/models on introspective metrics (ρ, isotonic R²) using public/open models for causal validation and closed models for black-box tracking.
- Sector: Policy, procurement, risk assessment.
- Tools/products/workflows:
- Publish scorecards that report introspection under fixed prompts and topics; flag models with severe numeric collapse or low fidelity.
- Assumptions/dependencies:
- Ensure comparable decoding and logprob settings; legal/contractual permission to collect logprobs.
- Daily Life — Personal AI assistants that self-monitor for quality
- Use case: Assistants adjust pacing or ask clarifying questions when their “focus” signal dips, improving user experience in long sessions.
- Sector: Consumer AI.
- Tools/products/workflows:
- Lightweight wrapper that reads self-reports per turn and applies simple rules (e.g., request clarification when focus < threshold).
- Assumptions/dependencies:
- Modest computational overhead for extra token probability extraction.
- Open-Source Tooling — concept-probe library
- Use case: Train probes, compute probe scores, perform activation steering, and extract logit-based self-reports for experiments and demos.
- Sector: Research engineering.
- Tools/products/workflows:
- Integrate concept-probe into evaluation pipelines for reproducible multi-probe, multi-layer experiments.
- Assumptions/dependencies:
- Works out of the box with open models; limited to self-reports only for closed models.
Long-Term Applications
These applications require further research, scaling, standardization, or broader model/sector validation before deployment.
- Industry — Closed-loop self-regulation in agents
- Use case: Agents that introspect (“focus,” “interest,” “planning”) and adjust internal states (via steering or prompt-based surrogates) to sustain reliability over long tasks.
- Sector: Autonomous agents, RPA, developer tools.
- Tools/products/workflows:
- Feedback controller using introspective telemetry to tune decoding, tool-calling cadence, or steering α in real time.
- Assumptions/dependencies:
- Demonstrate stability and lack of performance regressions; access to safe steering or robust prompt-level substitutes on closed models.
- Safety & Alignment — Introspection as an auxiliary objective
- Use case: Train/fine-tune models to improve monotonic coupling between self-reports and internal states, increasing transparency and controllability.
- Sector: Model alignment, safety research.
- Tools/products/workflows:
- Add auxiliary losses that reward accurate numeric self-reports against probe targets; evaluate generalization to unseen contexts.
- Assumptions/dependencies:
- Risk of Goodharting (models gaming the metric); needs careful causal validation and out-of-distribution tests.
- Policy & Standards — Introspective telemetry requirements
- Use case: Standards that recommend (or require) exposing token logprobs for numeric self-report auditing and publishing introspection benchmarks.
- Sector: AI governance, certification bodies.
- Tools/products/workflows:
- Draft test suites (multi-turn topics, concepts, metrics) analogous to calibration audits; vendor attestations and independent evaluations.
- Assumptions/dependencies:
- Consensus on ethical use and interpretation; safeguards against anthropomorphism and misuse.
- Model Welfare Research — Distress-report validation
- Use case: Evaluate whether distress-like outputs reflect internal states by testing causal coupling (probes/steering) rather than surface mimicry.
- Sector: AI ethics, machine psychology.
- Tools/products/workflows:
- Develop broader concept sets (beyond four emotions) and longitudinal protocols with causal tests; inform policy on handling distress reports.
- Assumptions/dependencies:
- Strong epistemic caution: current evidence is about representational coupling, not sentience or subjective experience.
- Healthcare & Education — Adaptive dialogue grounded in model-state telemetry
- Use case: Mental-health or tutoring systems that adjust strategies when the model’s own “interest/focus” signals predict risk of unhelpful or inconsistent replies.
- Sector: Healthcare, education.
- Tools/products/workflows:
- Safety layers that gate advice when telemetry crosses thresholds; auditing frameworks linking telemetry to outcome metrics (helpfulness, harm).
- Assumptions/dependencies:
- Requires rigorous clinical/educational validation and oversight; avoid inferring human states from model signals; bias and fairness audits needed.
- Robotics & Edge Agents — Cognitive-load proxies for language-planning stacks
- Use case: Use “focus” and “planning vs. impulsivity” signals as proxies for cognitive load, modulating task allocation or fail-safe behaviors.
- Sector: Robotics, IoT.
- Tools/products/workflows:
- Integrate telemetry into task planners; trigger simplification or handoff when signals indicate instability.
- Assumptions/dependencies:
- Validate correlation with real-world task performance; ensure low-latency logprob access on-device.
- Finance & Risk — Guardrails against “impulsive” recommendations
- Use case: Detect and down-weight outputs generated under high “impulsivity” states in advisory contexts (drafting, research assistants).
- Sector: Finance, compliance.
- Tools/products/workflows:
- Telemetry-informed filters or second-pass checks for risky content; logs for audit trails tied to introspective state.
- Assumptions/dependencies:
- Sector-specific compliance validation; demonstrate predictive value for risk.
- Generalized frameworks — Beyond four emotive concepts
- Use case: Extend probes/self-reports to additional internal constructs (e.g., uncertainty, curiosity, diligence), building richer state spaces for agents.
- Sector: Agent ecosystems, research.
- Tools/products/workflows:
- Taxonomy of concept vectors; cross-concept steering to enhance introspection for related dimensions (as shown by ΔR² improvements).
- Assumptions/dependencies:
- Concept discoverability and stability vary by model family/scale; requires scalable probe training and causal tests.
- API Design — First-class numeric-report endpoints
- Use case: Offer API methods that return calibrated numeric self-reports directly (e.g., expected rating), abstracting away logprob handling.
- Sector: AI platforms.
- Tools/products/workflows:
- “score(construct, scale)” endpoints with documented coupling metrics; sandboxed evaluation contexts.
- Assumptions/dependencies:
- Provider willingness to support; standardization of prompts/scales and disclosure of limitations.
- Benchmarks & Leaderboards — Introspection scores at scale
- Use case: Public leaderboards ranking models by introspective strength/fidelity across multi-turn scenarios and concept sets.
- Sector: Research, procurement.
- Tools/products/workflows:
- Community-driven datasets; cross-family, cross-size evaluations; longitudinal tracking across model releases.
- Assumptions/dependencies:
- Agreement on protocols; prevent overfitting to specific benchmarks.
Cross-cutting assumptions and caveats
- Access and privacy: Immediate tracking requires token logprob access; causal validation and steering require activation access (open models).
- Domain specificity: Results validated on LLaMA and partially on Gemma/Qwen; fidelity and drift patterns may differ across models and tasks.
- Robustness: Introspective coupling strengthened with model size; smaller/closed models may show weaker or different coupling.
- Misuse risks: Avoid anthropomorphizing or using model states to infer user states; treat signals as internal telemetry for system quality control.
- Gaming/Goodharting: If introspection is optimized directly, models may learn to report rather than regulate; keep causal checks and out-of-context tests in the loop.
Glossary
- Activation steering: A technique that adds vectors to intermediate activations to shift an LLM’s internal state along a target direction during inference. "activation steering confirms the coupling is causal."
- Activation velocity: A cumulative measure of how much internal representations drift across conversation turns. "introduced ``activation velocity'', a cumulative drift measure in internal representations across turns"
- Benjamini–Hochberg (BH) correction: A multiple-comparisons procedure that controls the false discovery rate across related statistical tests. "we report raw p-values but apply Benjamini--Hochberg (BH) correction within that family"
- Black-box methods: Monitoring or analysis techniques that do not require internal access to model weights or activations. "there is also value in having good black-box methods for monitoring internal state"
- Causal informational coupling: An operationalization of introspection in which a self-report covaries and shifts causally with a matched internal state. "We operationalize introspection as causal informational coupling between a numeric self-report and an independently measured internal direction"
- Causal intervention: An experimental manipulation intended to change an internal variable to test causal dependence of outputs on that variable. "has emerged as a practical tool for causal intervention on internal state"
- Cluster bootstrap: A resampling method that accounts for grouped or clustered data (e.g., by conversation) when estimating confidence intervals. "Confidence intervals are computed via cluster bootstrap (resampling at the conversation level, , 95\% percentile CIs)"
- Cohen’s d: A standardized effect size measuring the difference between two means relative to the pooled standard deviation. "maximizing Cohen's on a set of held-out evaluation texts"
- Concept activation vectors (TCAVs): Linear directions in activation space representing high-level human concepts, used to interpret neural networks. "introduced concept activation vectors (TCAVs) in CNNs"
- Contrastive completions: Paired outputs generated under opposing conditions (e.g., prompts) used to define discriminative directions. "train linear concept probes on contrastive completions;"
- Contrastive mean-difference direction: A probe defined as the normalized difference between mean activations under two opposing concept conditions. "Each probe is a contrastive mean-difference direction"
- Forward hooks: Mechanisms that attach to a model’s forward pass to read or modify activations at specific layers. "we add a scaled concept vector to the residual stream via forward hooks"
- Greedy decoding: A decoding strategy that selects the highest-probability token at each step, often collapsing numeric outputs to few values. "Greedy decoding selects the highest-probability token;"
- Identity drift: Changes in a model’s expressed identity or persona over multi-turn interactions. "identity drift that paradoxically increases with scale"
- In-context learning: Adapting behavior by leveraging examples or instructions within the prompt without updating model weights. "requiring in-context learning and working on arbitrary directions rather than naturally arising concepts"
- Instruction drift: Gradual loss of adherence to initial instructions (e.g., system prompts) over a conversation. "instruction drift driven by attention decay to system prompts"
- Instruction-tuned: Models fine-tuned to follow natural-language instructions across tasks. "instruction-tuned LLMs can perform quantitative introspection of emotive states in conversation."
- Isotonic R2: A goodness-of-fit measure for monotonic models, computed after fitting an isotonic (non-decreasing) function. "Isotonic fits a non-decreasing function via isotonic regression and computes ;"
- Isotonic regression: A nonparametric regression that fits a monotone (non-decreasing) function to data. "Isotonic fits a non-decreasing function via isotonic regression and computes ;"
- Isotropic distribution: A distribution that is uniform over directions, used to sample random control vectors in activation space. "Random-direction controls, using vectors of equal per-layer norm drawn from an isotropic distribution, serve as the primary null comparison."
- Linear mixed-effects models (LMM): Statistical models with both fixed effects and random effects to account for grouped observations. "significance testing uses linear mixed-effects models (LMM, random intercept by conversation, REML estimation)"
- Linear probes: Simple linear models trained on activations to read out the presence of specific information or concepts. "Linear probes, for example, can identify interpretable directions in activation space"
- Logit: The unnormalized score (pre-softmax) for each token in the output distribution. "computing the probability-weighted expected value over digit-token logits yields a continuous self-report measure"
- Logit-based self-report: A continuous self-report computed as the expected value over digit-token probabilities derived from logits. "Logit-based self-report computes a continuous expected rating from the output distribution at the first generated token:"
- Logsumexp: A numerically stable operation to aggregate logits by summing in the log domain. "where "
- OLS regression: Ordinary least squares regression, used here to model trends versus log(model size). "Model-size trends on conversation-level summaries use OLS regression on ."
- Random-direction controls: Control vectors sampled at random (e.g., isotropically) to serve as null baselines for probe effects. "Comparisons between true probes and random-direction controls use paired cluster-bootstrap tests."
- REML estimation: Restricted maximum likelihood estimation method for variance components in mixed-effects models. "significance testing uses linear mixed-effects models (LMM, random intercept by conversation, REML estimation)"
- Residual stream: The main pathway in transformer layers where token representations are updated and to which steering vectors can be added. "we add a scaled concept vector to the residual stream via forward hooks"
- Shannon entropy: An information-theoretic measure of uncertainty in a probability distribution. "Fig.~2E shows Shannon entropy of the self-report distribution."
- Sparse autoencoders: Autoencoders trained with sparsity constraints to discover interpretable latent features. "Other white-box approaches, like sparse autoencoders \citep{Bricken2023}, face analogous access and scalability constraints."
- Spearman’s rho: A rank-based correlation coefficient that measures monotonic association between two variables. "Spearman's measures rank-order agreement, requiring only that higher probe scores correspond to higher self-reports without assuming a specific functional form."
- System prompt: An instruction given to guide a model’s overall behavior or persona during interaction. "two opposing system prompts that induce the positive and negative poles of the concept"
- Self-steering: Steering along the same concept direction that is being measured, to test causal dependence of self-reports. "Self-steering uses the same concept direction for both steering and self-report measurement"
Collections
Sign up for free to add this paper to one or more collections.

