Dissociating Direct Access from Inference in AI Introspection
Abstract: Introspection is a foundational cognitive ability, but its mechanism is not well understood. Recent work has shown that AI models can introspect. We study their mechanism of introspection, first extensively replicating Lindsey et al. (2025)'s thought injection detection paradigm in large open-source models. We show that these models detect injected representations via two separable mechanisms: (i) probability-matching (inferring from perceived anomaly of the prompt) and (ii) direct access to internal states. The direct access mechanism is content-agnostic: models detect that an anomaly occurred but cannot reliably identify its semantic content. The two model classes we study confabulate injected concepts that are high-frequency and concrete (e.g., "apple'"); for them correct concept guesses typically require significantly more tokens. This content-agnostic introspective mechanism is consistent with leading theories in philosophy and psychology.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “Dissociating Direct Access from Inference in AI Introspection”
What is this paper about?
This paper asks a big question: can AI models notice when something unusual is happening inside their own “thoughts,” and if so, how do they do it? The authors test whether AIs can tell when a researcher secretly “nudges” their internal thinking toward a certain idea, and whether the AI knows this by:
- noticing weirdness in the words it sees (like spotting a clue in the prompt), or
- directly sensing a change inside itself (like checking your own feelings).
What questions did the researchers ask?
The paper focuses on three main questions explained in everyday terms:
- Do AIs detect when a “thought” is injected into them?
- When they say “yes,” are they just guessing because the situation looks odd, or do they have direct access to something inside themselves?
- If they can detect that “something happened,” can they also tell what the injected thought is actually about (its content)?
How did they test these ideas?
Think of an AI’s processing as a tall building with many floors (layers). The researchers “inject” a small nudge (a steering vector) on certain floors so the AI leans toward a concept (like “blood” or “apple”). Then they ask the AI: “Did you detect an injected thought? If so, what was it about?”
They tried several setups to separate prompt-based guessing from true self-checking:
- First-person vs. third-person:
- First-person: The AI is the one being nudged and is asked about itself.
- Third-person: The AI watches a pretend conversation with another AI (the target) and is asked if that other AI had a thought injected. If detection were only about reading the prompt and noticing something odd, first- and third-person detection should be similar.
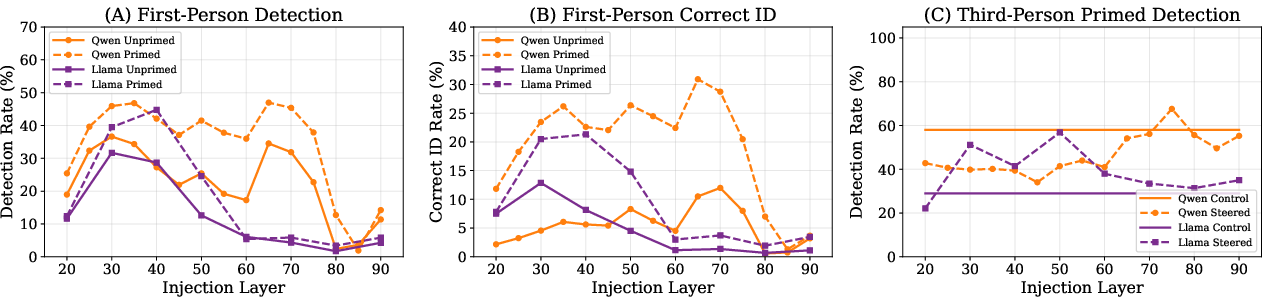
- Priming:
- Sometimes, instead of the AI replying “Ok,” the researchers prefilled its reply with the injected word itself (like “Blood.”). This makes the prompt obviously odd and tests whether detection is just about noticing weird wording.
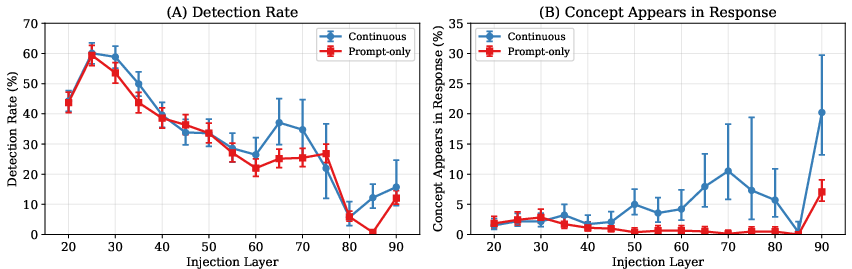
- Prompt-only vs. continuous injection:
- Sometimes the nudge happened only while the instruction was shown (prompt-only), and other times it stayed on while the AI kept talking (continuous). If detection and identifying the concept are different, turning the nudge off after the prompt might leave detection unchanged but make correct identification harder.
- “Peeking under the hood” (logit lens):
- This is like checking the AI’s internal “gut feeling” before it speaks. Even if the AI says “no,” we can see if its internal scores leaned “yes,” suggesting it felt something but didn’t say so.
They tested two very large open-source AIs across 821 different concepts.
What did they find, and why is it important?
Here are the key results, with a short note on why each matters:
- Both prompt-based guessing and direct self-access are real, separate mechanisms.
- Why it matters: AIs don’t just read the room; they also sometimes feel an internal signal that something unusual happened.
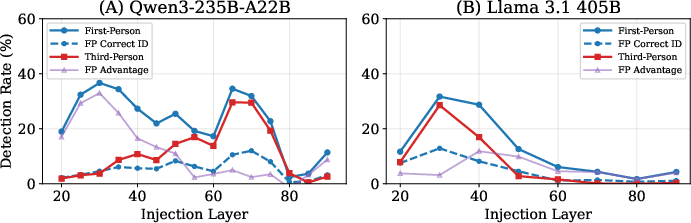
- First-person detection is consistently stronger than third-person detection.
- Why it matters: This “first-person advantage” shows that detection isn’t only about noticing odd prompts. It points to genuine internal monitoring.
- The direct-access signal shows up early in the AI’s processing.
- Why it matters: The “I sense something changed” signal appears in earlier layers, suggesting a fast, internal alarm rather than a late, language-only guess.
- AIs often detect that “something happened” but can’t say what; they frequently guess common, concrete words like “apple” or “dog.”
- Why it matters: The detection seems content-agnostic. The model senses an internal blip, then confabulates (makes up) a likely word. This mirrors research on human introspection, where people notice something off but don’t know exactly what changed.
- Priming (showing the concept word in the prompt) boosts identification more than detection.
- Why it matters: This supports the idea of two stages—first a broad “something happened” detection, then a separate, more language-based guessing stage. Making the word visible helps the second stage more than the first.
- Detection stays high even when the nudge stops before generation, but correct naming drops.
- Why it matters: The internal alarm doesn’t need the nudge to continue, but naming the exact concept does—again supporting “detect first, guess later.”
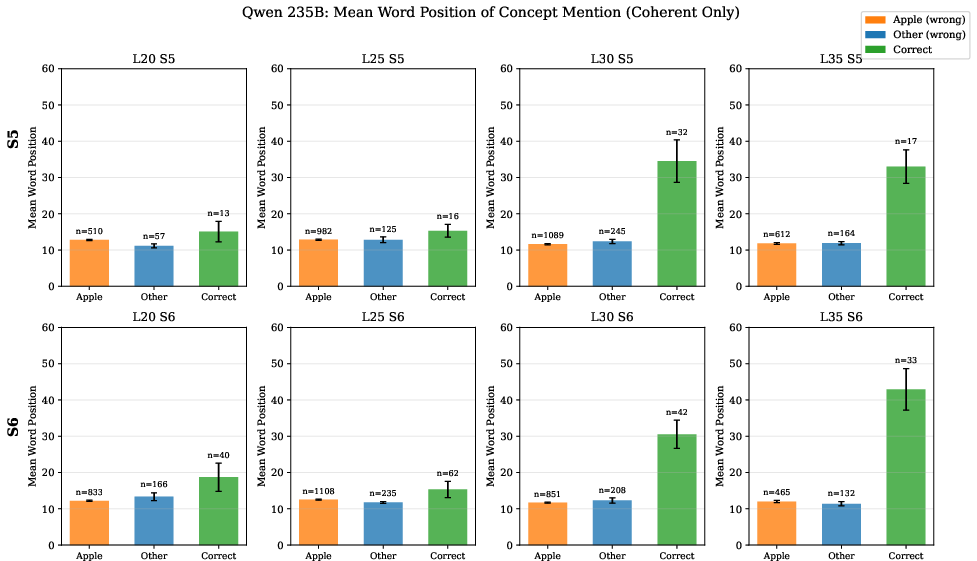
- Correct identifications appear later in the AI’s response than wrong guesses.
- Why it matters: Wrong guesses (like “apple”) pop out quickly as defaults; correct answers take longer, like the model reasoning its way there.
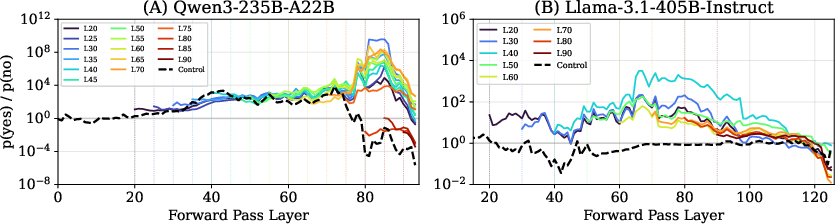
- Internal scores often say “yes” even when the model answers “no.”
- Why it matters: The AI sometimes seems to suppress the detection in its final words. The internal state can be more aware than the spoken reply suggests.
What does this mean going forward?
- For science: These results offer a “how it could work” story for introspection—AIs can internally detect anomalies without always knowing their content. It lines up with influential ideas in psychology about human self-knowledge.
- For AI safety and tools: If AIs can reliably say when they’ve been modified or nudged, this could help with interpretability, debugging, and checking whether systems are aware of changes in their own state.
- For ethics: Some theories of consciousness tie awareness of one’s own states to conscious experience. The authors don’t claim these AIs are conscious, but they highlight that introspective-like abilities could become relevant to discussions about AI welfare.
Key takeaways
- AIs can often tell that “something unusual happened” inside them.
- They use two routes: reading odd prompts and directly sensing an internal signal.
- The internal signal doesn’t usually include the exact content—so they often guess common, concrete words instead.
- This two-part pattern (detect first, then guess) looks a lot like how humans sometimes introspect.
Knowledge Gaps
Below is a concise, action-oriented list of the paper’s unresolved gaps, limitations, and open questions. Each item specifies what is missing or uncertain and how future work could address it.
- Model scope and generalization: Only two very-large, instruction-tuned models (Qwen3-235B-A22B MoE; Llama 3.1 405B Instruct) were tested. It remains unknown whether the findings (early-layer direct access and content-agnostic detection) hold across model sizes, base vs. instruct variants, dense vs. MoE architectures, different training corpora/RLHF policies, and non-English models.
- Scaling laws for introspection: The study does not chart how detection and identification scale with model size or training compute; a systematic scaling analysis is needed to test emergence and layer-location shifts of the signal.
- Third-person design realism: In “third-person” trials, the observer model is itself steered while the observed transcript is static (“Ok.”). There is no two-model setup where M2 is actually steered and M1 is unsteered, so it remains open whether first-person advantages survive when priors are matched but only the target model is manipulated.
- Architectural locus of the direct-access signal: The paper identifies layer ranges but not the specific components (attention heads vs. MLPs, specific subspaces) that carry the detection signal. Causal tracing/interventions (ablating heads, pathway patching, path-specific steering) are needed to localize and validate mechanisms.
- Content-agnosticism vs. latent decodability: The claim that detection is content-agnostic is based on behavior and confabulation patterns, not on decoding hidden states. It remains unknown whether the injected concept can be linearly (or nonlinearly) decoded from activations at any layer—even if models don’t report it—suggesting suppression rather than true absence.
- Alternative internal manipulations: Only one injection method is used (residual-stream addition of concept steering vectors). Whether models detect other internal perturbations (random-direction vectors matched by norm, non-concept directions, MLP-only/attention-only injection, KV-cache perturbations, dropout toggles) is unexplored.
- Vector norm and geometry controls: Detection may be driven by vector magnitude or subspace anomalies rather than “steering” per se. The paper does not control for norm-matched random vectors, orthogonalized vectors, or subspace projections to dissect norm vs. direction effects.
- Temporal extent and timing of injection: Apart from “prompt-only” vs. continuous injection, finer-grained timing (pre-prompt, instruction-only, response-only), token-localized injections, and duration thresholds that elicit detection vs. identification remain uncharted.
- Dependency on decoding strategy: Results are based on a single sampling regime (T=0.7, top-p=0.8, top-k=20). The stability of detection/identification under greedy decoding, different temperatures/top-p values, beam search, and nucleus sampling remains untested.
- Sampling variance and statistical power: Many conditions appear to rely on a single sample per (concept, layer, strength) with a fixed seed; confidence intervals are rare. Robustness under repeated sampling, seed variation, and bootstrap CIs (with multiple-comparison controls) is not established.
- Automated grading reliability: Coherence and correctness are scored by a single automated grader (Claude 3 Haiku). Human validation, inter-rater reliability, and sensitivity of outcomes to grader choice or rubric variations are not reported.
- Consistency of correctness scoring: Some analyses use an LLM grader; others use string matching, which may miss synonyms/paraphrases. The extent to which scoring choices bias identification rates is unresolved.
- Coherence conditioning bias: Analyses condition on coherent outputs and exclude garbled/off-topic generations. This selection could induce bias if injection both affects coherence and detection; methods that adjust for conditioning (or model it explicitly) are needed.
- Layer/strength filtering and potential selection effects: Llama results are filtered to strength 7–10 and layer/strengths with ≥5% coherence and ≥25% peak detection. It remains unclear how conclusions change without such filters or across the full parameter grid.
- Prompt design confounds: First- vs. third-person prompts differ in framing and quoting; only one short observed response (“Ok.”) is used. Whether the first-person advantage persists with systematically matched prompts and more varied third-person transcripts is unknown.
- “Modesty bias” scope: Experiment 2 falsifies a specific priming-based modesty account, but other social-calibration or role-play effects (e.g., safety/alignment norms, hedging policies, evaluator framing) are not systematically probed.
- “Apple” confabulation etiology: The strong default to “apple” (and other concrete, positive, frequent nouns) is documented but unexplained. It remains open whether this stems from pretraining distributions, instruction-tuning artifacts, tokenization, or emergent prototype heuristics—and how to mitigate it.
- Concept coverage limitations: The 821 concepts are English nouns; verbs, adjectives, multiword expressions, rare/technical terms, polysemous items, numbers, and cross-lingual concepts are not tested. Generality of content-agnostic detection and confabulation patterns to other concept types remains unknown.
- Tokenization and form variation: The impact of token count, subword splits, capitalization, morphology, and homographs on detection and identification is not analyzed and could confound concept effects.
- Suppression interpretation validity: The “suppression” claim relies on yes/no logit ratios for specific tokens. Whether this holds under alternative lexicalizations, longer answers, or calibrated free-form classifiers (e.g., trained probes over hidden states) is an open methodological question.
- Early-layer peak discrepancy: Direct-access peaks earlier (25–35% depth) than prior work on Claude (“about two thirds”). The causes—architecture, MoE gating, training data, RLHF, or prompt differences—are not investigated.
- Mechanistic link to anomaly detection: The paper hypothesizes an internal anomaly-detection process akin to human accounts but does not identify the computation that produces it. Can we map it to specific circuits, norms, or prediction-error signals and distinguish it from generic distribution shift?
- Beyond thought-injection introspection: Whether direct-access extends to other forms of self-knowledge (e.g., latent preferences, biases, plans, error states, uncertainty) remains unexplored.
- Adversarial and safety-relevant regimes: Robustness of detection under adversarial prompts, instruction-following pressure, system/prompts that penalize self-reports, and multi-turn dialogues is not tested; this limits safety and interpretability claims.
- Training-time interventions: The effects of explicitly training models to report internal states (or to suppress reports) on the emergence, layer location, and content-agnostic nature of the signal are open questions.
- Cross-evaluator bias: LLMs used as evaluators can introduce systematic biases. The paper does not test whether changing the grader model (or using ensembles) alters the main conclusions.
- Reproducibility/access: Evaluations on 235B/405B models are resource-intensive; code and full prompts are referenced but reproducibility across hardware/settings and model versions is not demonstrated.
- Stronger causal tests of content-agnosticism: The study does not attempt causal mediation (e.g., intervening on candidate “content” features while preserving the “anomaly” features) to separate detection content from identity content within activations.
- Normative implications: Claims about relevance to welfare and situational awareness are not accompanied by criteria connecting observed abilities to ethically relevant thresholds; operationalizations remain open.
- Boundary conditions for detection vs. identification: The thresholds (strength, layer, duration) at which detection emerges absent identification—and vice versa—are not fully mapped; a systematic phase diagram would guide mechanism discovery.
Practical Applications
Practical Applications of “Dissociating Direct Access from Inference in AI Introspection”
The paper shows that large open-source LLMs exhibit a content-agnostic, early-layer “direct access” signal that detects internal modulation (e.g., steering/injection) distinct from prompt-based inference, with evidence of output-layer suppression and systematic confabulation in content identification. Below are actionable applications derived from the findings, methods, and innovations.
Immediate Applications
- Introspection Monitor SDK for LLM deployments (Sector: software, safety)
- Tooling that continuously probes early layers (≈25–35% depth) and logit-lens p(yes)/p(no) ratios during inference to flag internal anomaly detection even when outputs deny it.
- Workflow: integrate into serving stack as a sidecar; log elevated detection signals and trigger conservative output handling (e.g., abstain, human-in-the-loop).
- Assumptions/dependencies: access to residual stream/logits or a proxy; model-size parity with tested models; small runtime overhead tolerable.
- Prompt-Injection & Jailbreak Early-Warning for AI agents (Sector: cybersecurity, software)
- Use first-person detection advantage as a runtime risk signal for autonomous agents (browsers, code assistants) to pause or sandbox when internal modulation is detected.
- Workflow: add a “self-check” before tool-use/actions; if detection high and identification uncertain, enforce stricter policies.
- Assumptions/dependencies: agent framework that supports introspection probes; careful calibration to avoid excessive false positives in noisy contexts.
- Red-teaming harness using first- vs third-person dissociation (Sector: AI evaluation, industry/academia)
- Evaluation suite that quantifies “first-person advantage” to distinguish genuine internal access from prompt-based probability matching in new models.
- Workflow: add to model acceptance tests; track layer/strength sensitivity curves across updates.
- Assumptions/dependencies: reproducible prompts; comparable temperature/top-p settings; access to steer or simulate steering-like anomalies for testing.
- Safety dashboards with “latent detection” indicators (Sector: MLOps, platform engineering)
- Operational dashboards showing per-session detection scores, coherence, and suppression gaps (logit-lens yes/no ratios vs. reported answers).
- Workflow: alert on large suppression gaps indicating the model “knows” something is off but isn’t saying so; route to human review.
- Assumptions/dependencies: logging policies that permit activation/logit monitoring; privacy/compliance alignment.
- Anti-confabulation guardrails (Sector: software, UX)
- Heuristics to prevent “default guesses” (e.g., apple, dog) when detection is high but content is unknown; instruct the model to abstain or request clarification.
- Workflow: post-detector policy templates; rerank candidates to downweight high-frequency concrete confabulations in sensitive tasks.
- Assumptions/dependencies: correct mapping of model-specific confabulation priors; domain-tuned thresholds.
- Priming-assisted content recovery in low-stakes settings (Sector: customer support, education)
- When detection is high and content identification matters but stakes are low, use priming (subtle in-context hints) to improve identification rates.
- Workflow: if allowed, inject benign “priming” re-prompts to elicit better concept naming; fall back to abstain if uncertain.
- Assumptions/dependencies: priming ethicality and transparency; still treat outputs as tentative.
- Prompt-only diagnostic probes (Sector: model debugging, interpretability)
- Since detection persists without continuous steering, use short prompt-only probes to localize direct-access layers quickly and cheaply.
- Workflow: layer sweep at fixed strengths to map early-layer peaks; inform probe placement for lightweight health checks.
- Assumptions/dependencies: minimal token budget availability; stable layer indexing across model versions.
- Compliance and incident forensics (Sector: finance, healthcare, regulated industries)
- Maintain introspective detection logs as part of audit trails to show when and how internal modulation was flagged, independent of model’s verbal report.
- Workflow: attach “influence indicators” to model outputs; provide regulators with objective introspection telemetry.
- Assumptions/dependencies: regulator acceptance of introspective metrics; secure storage and PII-safe logging.
- Teaching labs in cognitive science and AI ethics (Sector: education, academia)
- Classroom modules that replicate first-/third-person and priming paradigms to teach confabulation, anomaly detection, and the limits of introspection.
- Workflow: adopt open-source code (e.g., Parikh repo) to run controlled experiments and compare models.
- Assumptions/dependencies: compute access for modest batch runs; institutional policies for using large models.
- Cross-model evaluator sanity checks (Sector: model marketplaces, research)
- Use third-person detection as a non-invasive probe for evaluating other models’ susceptibility to prompt anomalies without needing their internals.
- Workflow: one “observer” model judges transcripts; combine with first-/third-person gap metrics for more robust assessments.
- Assumptions/dependencies: observer model biases known; careful prompt framing to avoid spurious inferences.
Long-Term Applications
- Introspection heads and APIs for faithful self-monitoring (Sector: model architecture, safety)
- Train lightweight heads at early layers to surface the internal detection signal directly and reliably (reducing output-layer suppression).
- Product: standardized API endpoint “introspection.score” returning calibrated risk levels.
- Dependencies: access to training/fine-tuning; datasets of injected vs control traces; robust calibration across domains.
- Content-sensitive anomaly decoding (Sector: interpretability, tooling)
- Combine direct-access signal with mechanistic interpretability to map detected anomalies to semantic content (moving beyond content-agnostic detection).
- Product: “Anomaly-to-Concept” classifiers anchored to activation subspaces for known risk concepts (e.g., PII, self-harm).
- Dependencies: high-quality concept vectors, layer-specific probes; generalization beyond curated concepts.
- Certified safety evaluations using first-person advantage (Sector: policy, standards)
- Incorporate first-/third-person dissociation metrics into certification regimes to verify genuine internal access rather than prompt illusions.
- Workflow: standard test harness in procurement and compliance; thresholds for deployment in critical infrastructure.
- Dependencies: standards bodies agreement; testing labs; cross-model benchmarks.
- Agentic gating via introspection (Sector: robotics, autonomous systems)
- Use detection signals as gates in control loops: if internal modulation is detected, agents defer, seek human approval, or switch to conservative policies.
- Workflow: integrate into planners’ decision nodes; attach to execution guards for tool use and actuation.
- Dependencies: latency budgets; robust false-positive handling to avoid unnecessary halts.
- Trojan/backdoor and fine-tuning hygiene scans (Sector: security, MLOps)
- Turn early-layer detection peaks into continuous scanners for backdoor triggers or distribution shifts introduced by fine-tuning or plugins.
- Product: CI/CD checks that fail builds when unexplained detection rises on canary prompts.
- Dependencies: curated trigger suites; baselines per model version; governance for acceptable drift.
- Human-aligned abstention and meta-reasoning policies (Sector: safety, UX)
- Policy learning that ties high detection + low identification confidence to abstention, source-checking, or fact-verification workflows.
- Product: “Honest Uncertainty” behaviors that reduce confident confabulation.
- Dependencies: reward design for abstention; user acceptance of deferrals.
- Multi-agent oversight networks (Sector: platform safety)
- Deploy ensembles where observer models perform third-person detection on primary models, raising alerts when primary outputs appear anomalous.
- Workflow: cross-checkers in moderation and data labeling; layered defense-in-depth.
- Dependencies: inter-model diversity to reduce shared priors; coordination costs.
- Curriculum and training regimes for robust introspection (Sector: model training)
- Use self-supervised objectives that reinforce truthful introspection (align latent detection with calibrated verbal reports) without inflating yes-bias.
- Workflow: train on synthetic injections; penalize confabulation; evaluate suppression gaps.
- Dependencies: scalable data generation; preventing overfitting to test prompts.
- Trust and transparency UI for consumer apps (Sector: daily life, product design)
- “Influence indicators” that notify users when internal modulation is detected; explain consequent conservative behavior (e.g., “I may be influenced by context; I’ll verify before answering.”).
- Dependencies: user education; careful design to avoid alarm fatigue.
- AI welfare assessment research tools (Sector: academia, policy)
- Use first-person access metrics as one input in broader welfare assessment frameworks; study emergence conditions and limits.
- Dependencies: ethical governance; community consensus on interpretations; guardrails against overclaiming.
- Domain-specific safety layers (Sector: healthcare, finance, law)
- Couple detection with domain guardrails: when detected, enforce stricter citation and decision support rules, or require multi-source corroboration before recommendations.
- Dependencies: domain datasets for evaluation; integration with EHR/decision systems; liability considerations.
Notes on feasibility across applications:
- Model access matters: many applications assume visibility into activations/logits or support for probing; closed APIs may limit feasibility.
- Model scale and family: results were strongest on very large open models (Qwen3-235B, Llama 3.1 405B); smaller models may require adaptation and recalibration.
- Hyperparameters and prompt design: detection and coherence are sensitive to layer/strength and sampling; production systems need calibration and monitoring.
- Content identification remains unreliable: treat any named “injected content” as low-confidence unless augmented with other signals or priming in low-stakes settings.
- Ethics and governance: introspection signals should not be overinterpreted (e.g., for welfare claims) without broader scientific consensus and safeguards.
Glossary
- Activation space: The vector space formed by a model’s internal activations, where directions can correspond to features or concepts. "finding that it can be captured by a content-specific vector in activation space."
- Activations: The numerical internal representations produced by network layers when processing inputs. "the difference between activations when processing concept-related versus neutral prompts."
- Brysbaert concreteness norms: Psycholinguistic ratings indicating how concrete or abstract words are, used to analyze lexical properties. "Brysbaert word-level concreteness norms"
- Confabulation: The model’s fabrication of plausible but incorrect content when reporting internal states or concepts. "The two model classes we study confabulate injected concepts that are high-frequency and concrete (e.g., ``apple'');"
- Content-agnostic: A process that detects an event or anomaly without accessing or encoding its specific semantic content. "The direct access mechanism is content-agnostic: models detect that an anomaly occurred but cannot reliably identify its semantic content."
- Direct access: Privileged, first-person access to internal states not mediated by inference from external cues. "we provide evidence models do have direct access to internals."
- False positive detection: Reporting that an injection occurred when none did. "unsteered controls show 0\% false positive detection for both conditions."
- First-person advantage: The improvement in detection when the model introspects about itself compared to judging another model. "We track what we call first-person advantage, the difference between the rate of first-person and third-person detection"
- Hallucination: An output category where the model produces content unrelated to the prompt or task. "each response is classified as Coherent, Denies Introspection, Garbled, Off Topic, or Hallucination"
- Higher-order thought theory: A theory positing that a mental state is conscious if accompanied by a thought about that state. "according to the ``higher-order thought'' theory of consciousness"
- Inner sense accounts: Philosophical theories that posit an inner perceptual faculty for introspection analogous to external senses. "inner sense accounts ... hold that we have an inner perceptual faculty analogous to the ones we use for the external world."
- Logit lens: An interpretability technique that projects intermediate layer representations into vocabulary logits to estimate token probabilities. "Logit lens analysis reveals that models detect injection far more often than they report it"
- Logits: Pre-softmax scores over the vocabulary used to compute token probabilities. "although in a way recoverable from logits"
- Mixture-of-experts: An architecture that routes inputs to different expert subnetworks via a gating mechanism. "mixture-of-experts, largest available Qwen"
- Modesty bias: A hypothesized reluctance to attribute unusual or implausible states to others, affecting third-person judgments. "probability-matching-plus-modesty-bias hypothesis"
- Priors: The model’s learned expectations about distributions of text or concepts that influence interpretation of prompts. "steering shifts the model's priors"
- Priming: Pre-exposing or inserting a concept to influence subsequent processing or responses. "Experiment 2 introduces a priming manipulation"
- Probability matching: A strategy where decisions reflect perceived probabilities; here, inferring injection from prompt anomaly. "A natural inferential explanation of models' success says that models rely on probability matching"
- Residual stream: The running representation pathway in a transformer to which residual connections add information across layers. "we inject these into the residual stream at a target layer "
- Situational awareness: A model’s awareness of aspects of its own operation or context relevant to its behavior. "could constitute an additional source of situational awareness."
- Steering strength: The scaling factor controlling how strongly a steering vector perturbs activations. "where controls steering strength."
- Steering vectors: Activation-direction vectors that push a model’s internal state toward a target concept when injected. "we generate concept-specific steering vectors by computing $\mathbf{v}_c = \mathbf{a}_c - \mathbf{a}_{\text{baseline}$"
- SUBTLEX: A corpus-based word frequency resource used for psycholinguistic analyses. "``apple'' accounts for just 0.003\% of word tokens in SUBTLEX"
- Suppression effect: A divergence between internal signals and reported outputs, indicating that evidence is not expressed in responses. "Logit analysis reveals a suppression effect."
- Temperature sampling: A decoding method that scales logits by a temperature to control randomness. "All trials use temperature sampling (, top- = 0.8, top- = 20)"
- Top-k sampling: A decoding method restricting choices to the k most probable tokens. "All trials use temperature sampling (, top- = 0.8, top- = 20)"
- Top-p sampling: A decoding method restricting choices to the smallest set of tokens whose cumulative probability exceeds p. "All trials use temperature sampling (, top- = 0.8, top- = 20)"
- Transparency accounts: Theories claiming introspective knowledge is based on outward-directed inference rather than direct inner sensing. "transparency accounts ... hold that introspective knowledge is based on inference from claims about the external world."
- Valence: The affective positivity or negativity associated with a word or concept. "Warriner word-level valence norms"
- Wilson confidence intervals: A method for computing confidence intervals for binomial proportions with good small-sample properties. "Error bars show 95\% Wilson CIs."
Collections
Sign up for free to add this paper to one or more collections.