Facts as First Class Objects: Knowledge Objects for Persistent LLM Memory
Abstract: LLMs increasingly serve as persistent knowledge workers, with in-context memory - facts stored in the prompt - as the default strategy. We benchmark in-context memory against Knowledge Objects (KOs), discrete hash-addressed tuples with O(1) retrieval. Within the context window, Claude Sonnet 4.5 achieves 100% exact-match accuracy from 10 to 7,000 facts (97.5% of its 200K window). However, production deployment reveals three failure modes: capacity limits (prompts overflow at 8,000 facts), compaction loss (summarization destroys 60% of facts), and goal drift (cascading compaction erodes 54% of project constraints while the model continues with full confidence). KOs achieve 100% accuracy across all conditions at 252x lower cost. On multi-hop reasoning, KOs reach 78.9% versus 31.6% for in-context. Cross-model replication across four frontier models confirms compaction loss is architectural, not model-specific. We additionally show that embedding retrieval fails on adversarial facts (20% precision at 1) and that neural memory (Titans) stores facts but fails to retrieve them on demand. We introduce density-adaptive retrieval as a switching mechanism and release the benchmark suite.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at how AI chatbots (like big LLMs) remember things over long projects. Today, most systems “remember” by stuffing facts into the chat window every time (the prompt). The authors show why that breaks down in real life and propose a simpler, sturdier way to store facts called Knowledge Objects (KOs). Think of it like this: instead of making the AI reread your whole notebook every time, you give each fact its own labeled index card in a box, so you can grab exactly what you need in one quick move.
What questions did the researchers ask?
They asked five plain questions:
- How well do current AIs recall exact facts when you pack lots of them into the prompt?
- What happens when the prompt gets so full that you have to summarize (compress) old info to make space?
- Do important rules and goals (like “don’t use this tool” or “only deploy in Europe”) get lost over time when you keep summarizing?
- Can standard search-by-embedding (finding “similar” text) be tricked by look‑alike facts that differ in the details (like numbers)?
- Is there a better memory setup that stays accurate, stays cheap, and works even when the fact collection is huge?
How did they test their ideas? (In everyday terms)
To keep things fair and measurable, they built simple, structured facts—like “Erlotinib inhibits EGFR with IC50 = 2.3 nM.” Each fact is like a tiny record with four slots: (subject, predicate, object, plus notes about where it came from).
They ran four kinds of tests:
- In‑prompt memory test: They kept adding facts (from 10 up to 10,000) into the AI’s chat window and asked it to recall specific values exactly, even when many facts looked almost the same on the surface.
- Summary (compaction) test: When the chat window filled up, they had the AI summarize thousands of facts into a tiny summary, then checked how many original facts survived.
- Goal‑drift test: They planted 20 realistic “rules of the project” across a long conversation (like “never use Redis,” “deploy only in EU”), then simulated multiple rounds of summarizing, like what happens in long-running projects, to see how many rules got silently forgotten.
- Retrieval tests outside the prompt:
- Embedding retrieval: Like searching by “similar meaning.” They built “adversarial” sets—facts that look and read almost identically but have different numbers—to see if similarity search picks the right one.
- Knowledge Objects (KOs): They stored each fact as a small, exact, key‑value entry—like a labeled index card: (subject, predicate) → object—with a unique “barcode” (hash) for instant lookup. The AI first parses the user’s question into (subject, predicate), grabs the matching card in constant time (one step), then writes the answer.
- Density‑adaptive retrieval: If the first pass finds a crowd of near‑identical candidates (like a bunch of twins), the system notices the crowd and switches from “similarity” to “exact key match” on the (subject, predicate) slots.
Useful analogy:
- In‑prompt memory = making the AI reread your whole notebook each time.
- Summarization = squeezing your notebook into a few paragraphs; the details fall out.
- Embedding retrieval = “find texts that feel similar.”
- Adversarial facts = twins wearing the same clothes but with different birthdays.
- Knowledge Objects = labeled index cards in a box; you go straight to the card by its label.
- Density‑adaptive retrieval = if too many twins show up, switch to checking the ID card.
What did they find, and why does it matter?
Here are the headline results and what they mean:
- Inside the window, it works great—until it doesn’t:
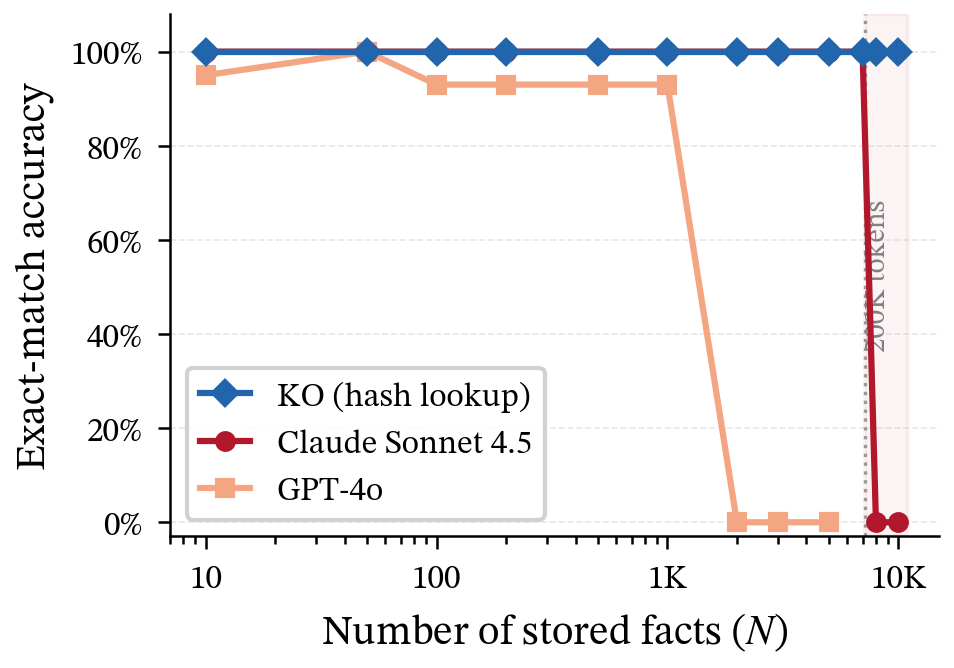
- Claude Sonnet 4.5 got 100% exact matches from 10 up to about 7,000 facts (almost the whole 200K‑token window), even with many look‑alike facts.
- But at ~8,000 facts the prompt overflows and the request fails. This isn’t a slow fade; it’s a cliff. Bigger windows help a bit, but they still fill up—and attention cost grows fast as prompts get longer.
- Summarizing destroys detail:
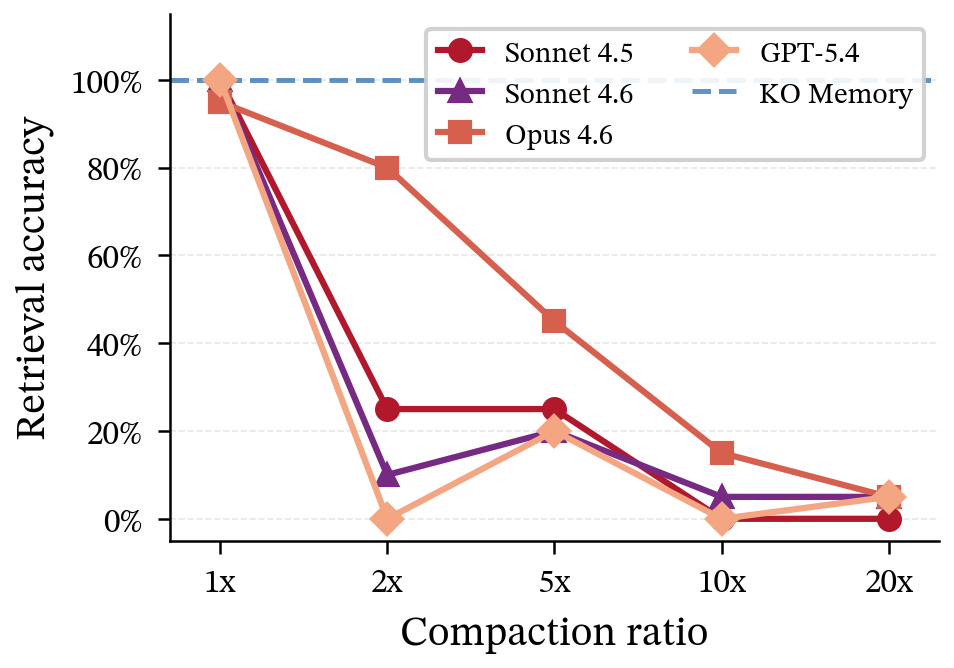
- After compressing 2,000 facts into a short summary (about 37× smaller), the AI could only answer 40% of the original fact questions. The other 60% were gone. It didn’t hallucinate—just admitted it no longer had the specifics. For work that needs exact numbers, that’s a deal‑breaker.
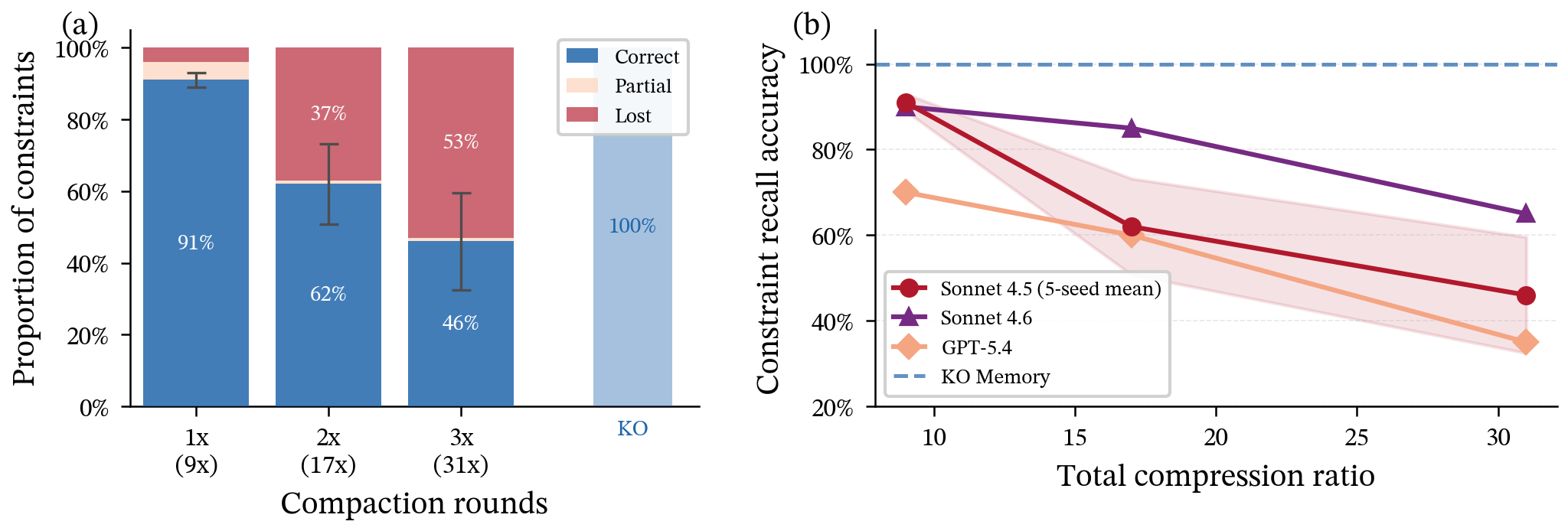
- Goals drift away quietly:
- After three rounds of summarizing a long project chat, more than half of the planted rules/constraints disappeared (54% lost). Worse, the AI carried on confidently using default choices, not the original rules. That’s risky for real projects (compliance, safety, system design).
- Similarity search can pick the wrong “twin”:
- On groups of almost identical facts that differ in the key number, embedding retrieval only got the right one 20% of the time (basically random among the look‑alikes).
- A simple switch fixes the “twin crowd”:
- Their density‑adaptive trick—if the retrieved set is too similar, switch to exact (subject, predicate) matching—jumped to 100% on the adversarial sets while keeping normal search quality elsewhere.
- Knowledge Objects stayed perfect and cheap:
- KOs delivered 100% correct retrieval across all tests, even when the fact set was too big to fit in any prompt.
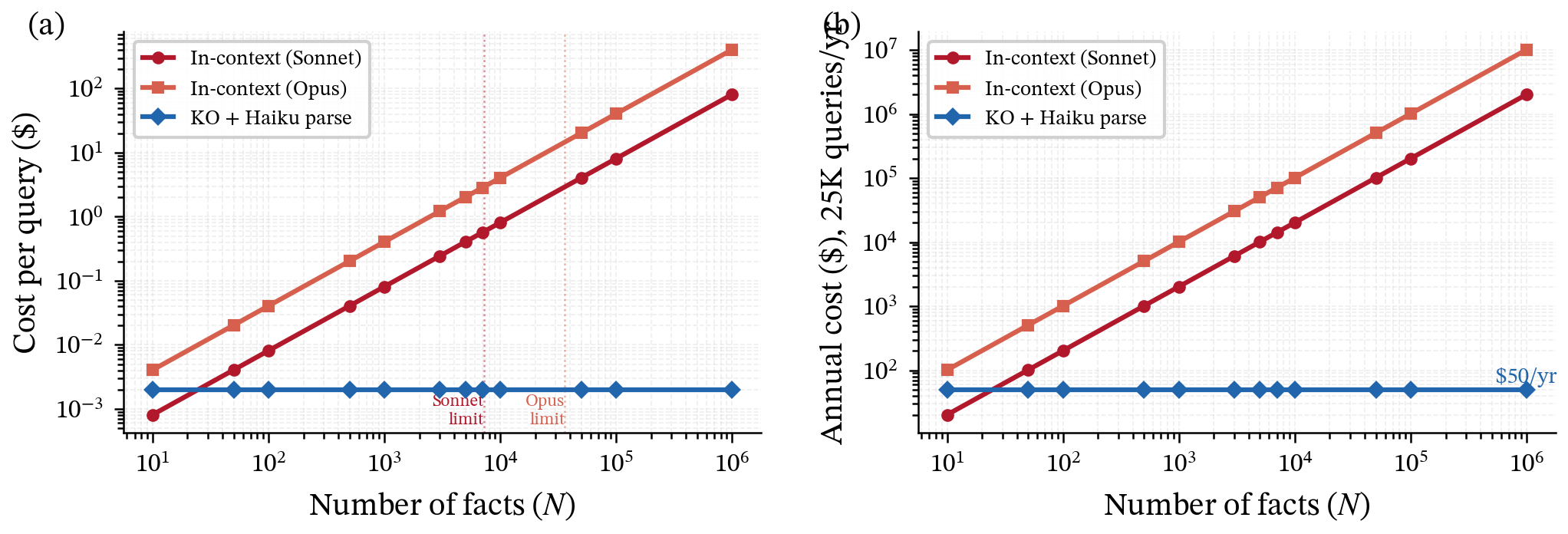
- Cost was about 252× lower than cramming everything into the prompt at 7,000 facts, and it stays basically flat as the knowledge base grows. In contrast, in‑prompt costs rise with every added fact—and eventually you hit a hard limit.
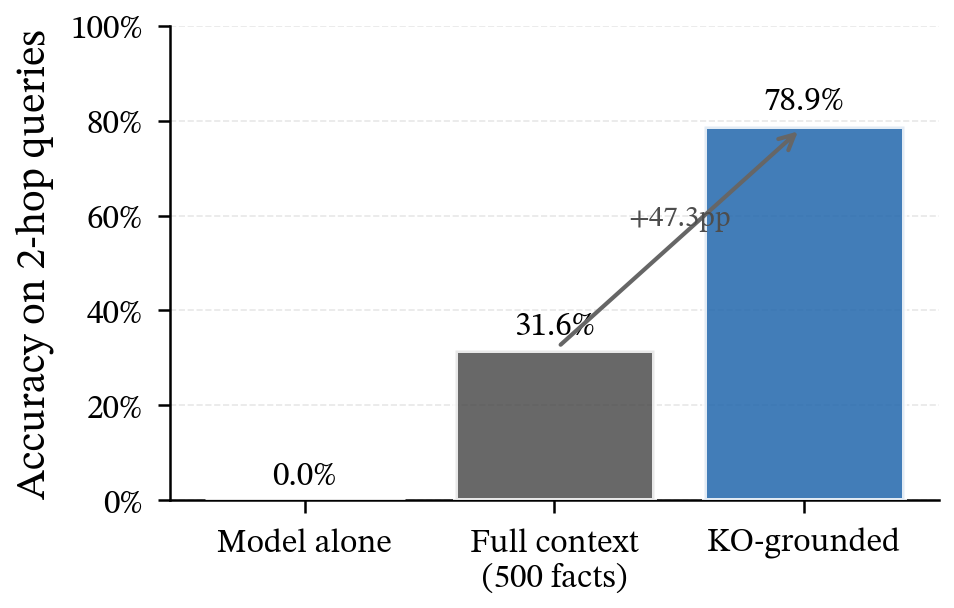
- On multi‑step questions (multi‑hop reasoning), KOs reached 78.9% vs. 31.6% for in‑prompt memory in their tests, likely because the right facts were always grabbed reliably before reasoning.
Big picture: The real problem isn’t that the model “can’t think.” It’s that the way we store and manage memory (stuffing/summarizing the prompt) makes facts and rules decay over time—a process the authors call “context rot.”
So what? Why this could change how we build AI tools
- Separate storage from thinking: Let the AI think and explain, but store facts in a simple, exact, external memory (KOs). That way, facts don’t vanish across sessions or summaries.
- Stop relying on giant prompts for memory: Bigger windows help for a while, but they don’t prevent overflow, they’re expensive, and they encourage lossy summarization that erodes details and rules.
- Be careful with summaries: Summaries are fine for “the gist,” but they are not safe for precise facts or critical constraints. Use exact stores for those.
- Use “crowd detectors” in search: When many near‑identical candidates show up, switch from “similarity” to exact keys. This avoids picking the wrong twin.
- Lower costs at scale: KO‑style memory keeps query costs tiny even as your fact library grows to enterprise size.
In short: If you want AI teammates that remember precisely and reliably, don’t make them reread everything or depend on summaries. Give each fact its own labeled slot in a fast address book (Knowledge Objects), let the model fetch exactly what it needs, and save the thinking for where thinking matters. This makes systems more accurate, more predictable, and much cheaper to run as they grow.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper surfaces important results but leaves several concrete gaps that future work should address. Below is a focused list of unresolved issues, organized by theme.
Scope, generalization, and external validity
- Generalization beyond synthetic, structured, fact-dense corpora: Results are primarily on pharmacological tuples and synthetic data; it is unclear how KOs and density-adaptive retrieval perform on unstructured narratives, procedural knowledge, legal/medical notes, code bases, multimodal inputs, or cross-lingual settings.
- Multi-hop reasoning details are underspecified: The claim that KOs reach 78.9% vs 31.6% for in-context lacks task definitions, hop depth, and robustness analysis; scaling behavior as hop count increases and the effect of compounding retrieval errors remain open.
- Cross-model replication is incomplete: The abstract mentions four frontier models and “architectural” compaction loss, but the body details mainly Claude Sonnet 4.5 and GPT‑4o; missing are results for Gemini, Llama-class, and open-source long-context models, with standardized protocols and variance reporting.
- Positional effects and long-context pathologies: The “Lost in the Middle” phenomenon is discussed but not stress-tested beyond structured facts; whether the absence of this effect holds across domains, prompt formats, and different positional encodings is untested.
- Real-world messiness: The benchmarks avoid entity aliasing, unit variability, typos, inconsistent naming, and conflicting sources; the behavior of KO and adaptive retrieval under noisy, heterogeneous enterprise data is not evaluated.
Knowledge Objects (KO) design and coverage
- Entity resolution and canonicalization: The KO pipeline assumes reliable extraction of keys; how to handle synonyms, aliases, morphological variants, abbreviations, cross-lingual names, and ontology drift is not specified or evaluated.
- N-ary and context-dependent relations: KOs are described as tuples; support for n-ary relations (e.g., time, location, conditions), qualifiers, and scopes (e.g., “valid from–to,” cohort, environment) is unspecified.
- Time-varying and contradictory facts: Policies for versioning, conflicting values for the same over time, and query semantics (e.g., “latest,” “as of date,” “most credible”) are not defined.
- Many-to-many mappings and multiplicity: How KO handles multiple valid objects per (e.g., a drug with several approved indications) and how answers are ranked/aggregated is unclear.
- CRUD operations, de-duplication, and merges: Insertion, updates, deletions (e.g., GDPR “right to be forgotten”), deduplication, and record merges across sources are not specified or evaluated.
- Provenance use beyond storage: Although provenance is stored, the paper does not define how it is used for conflict resolution, trust calibration, auditing, or ranking in answers.
- KO extraction accuracy and error propagation: The precision/recall of LLM-driven KO extraction from conversations is not measured; the impact of extraction errors on downstream correctness and mechanisms for human-in-the-loop validation remain open.
- Composition limits: For complex queries requiring dozens to hundreds of facts, it is unclear how many KOs can be retrieved/combined before hitting new context or reasoning bottlenecks, and what planning/aggregation strategies are needed.
Density-adaptive retrieval and adversarial neighborhoods
- Threshold learning and portability: The density threshold is tuned for a specific setup; how to learn/calibrate across domains, embedding models, and languages—and how stable it is to distribution shift—remains untested.
- Sensitivity to k, similarity metric, and embedding choice: How density estimates vary with , cosine vs other metrics, and stronger retrievers (e.g., domain-tuned bi-encoders, ColBERT, SPLADE, cross-encoder reranking) is not explored.
- Partial or missing keys: The fallback to exact matching presumes key extractability; behavior when keys are ambiguous, partially specified, or absent (and when to ask clarification questions) is not addressed.
- False positives/negatives in density triggers: Beyond one adversarial vs BEIR separation, rates of spurious/non-trigger events in broader corpora and the downstream cost of incorrect routing decisions are not quantified.
- Interaction with hybrid lexical–dense baselines: The baseline uses all‑MiniLM‑L6‑v2; comparisons against stronger hybrid pipelines with learned interpolation, lexical constraints, or schema-aware retrieval are missing.
Compaction, goal drift, and lifecycle management
- Generality of compaction loss: The study uses LLM summarization with a specific compression factor; whether structured compaction (e.g., tables, slot-based digests), constraint-first preservation, or learned compressive memory can reduce the 60%/54% losses is not tested.
- Measurement beyond numeric facts: Fact recall focuses on numeric exact match; preservation of categorical facts, exceptions, edge cases, and conditional rules is not assessed.
- Goal drift detection and mitigation: The system documents drift but does not propose or evaluate mechanisms to detect lost constraints, solicit confirmations, or enforce constraints via KO gating.
- Robustness across domains and settings: The 88‑turn constraint experiment involves 20 hand-picked constraints in a specific scenario; coverage across domains, larger constraint sets, different compaction schedules, and other models is unknown.
- Effects of model and prompt updates: Lifecycle events (model upgrades, instruction changes) are cited as sources of “context rot,” but their quantitative impact on recall and goal retention is not measured.
Cost, latency, and systems considerations
- Full cost model completeness: KO “O(1)” costs exclude storage, index maintenance, replication, backups, and concurrency control; end-to-end costs under production workloads (QPS, p95 latency, cold starts) are not reported.
- Latency and throughput: The paper focuses on token costs; empirical latency vs in-context and RAG baselines, and scalability under high concurrency, are not provided.
- Distributed deployment and failure modes: Behavior under network partitions, eventual consistency, cache staleness, and hash-ring rebalancing is not analyzed; the practical limits of “O(1)” under distributed systems realities remain open.
- Storage growth and monitoring: Policies and tooling for KO store growth, monitoring data quality, detecting drift/anomalies, and operational dashboards are not specified.
Security, privacy, and governance
- Access control and confidentiality: How KOs are protected (encryption, ACLs, multi-tenant isolation), how hash keys are secured (e.g., HMAC vs plain hashes), and leakage risks are not addressed.
- Data governance and write permissions: Who is authorized to write/update KOs (especially when auto-extracted by LLMs), required approvals, and audit trails are unspecified.
- Poisoning and adversarial attacks: Defenses against malicious or erroneous KO insertions, embedding-space attacks that manipulate density signals, and integrity verification are not evaluated.
- Compliance and deletion guarantees: Mechanisms to implement retention policies, legal holds, and verifiable deletions (e.g., GDPR) are not described.
Evaluation methodology and reproducibility
- Reproducibility details: The benchmark suite is said to be released, but dataset composition, licenses, scripts, and exact prompts for all experiments (including the “four frontier models”) are not fully documented here.
- Statistical robustness: Several results use small numbers of seeds and queries; comprehensive variance analyses, power calculations, and sensitivity to prompt phrasing and formatting are absent.
- Fair baselines: RAG and embedding baselines are not state-of-the-art; head-to-heads with tuned domain retrievers, cross-encoders, and hybrid re-rankers are needed for a fair comparison.
Architectural integration and future directions
- Bicameral routing beyond density: A general router deciding between KO (discrete) and parametric/neural memory (patterned knowledge) is not formalized; richer features (uncertainty, provenance, query type) beyond density are unexplored.
- Reasoning over KOs at scale: Approaches for join operations, aggregation, and graph-style inference over many KOs (without exceeding prompt limits) are not specified or benchmarked.
- Human-in-the-loop workflows: Design and evaluation of review/approval pipelines for KO creation and edits, escalation for ambiguous queries, and UI/UX considerations are not provided.
- Extensibility to non-text artifacts: How KOs represent code snippets, schemas, images, or structured configs—and how retrieval and provenance apply to such artifacts—remains open.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s methods (Knowledge Objects, density-adaptive retrieval) and empirical findings, with modest engineering effort and existing tooling.
- KO-backed project constraint vaults for software delivery
- Sectors: software, DevOps, compliance, cloud
- What: Store non-default decisions (SLOs, retries=7, EU-only regions, banned tech like Redis) as hash-addressed KOs; every agent/tooling step runs a “constraint preflight” that resolves applicable KOs before generation or deployment.
- Tools/workflow: KO store (SQLite/Postgres/Redis) with (subject, predicate, object, provenance); small LLM for query parsing; CI/CD checks that fetch constraints by key; IDE extension to surface constraints inline; provenance logged for audits.
- Benefits: Eliminates goal drift from summarization; O(1) retrieval at fixed cost; auditability.
- Assumptions/dependencies: Reliable canonicalization of subjects/predicates (e.g., project_id, env=prod); access control on KO reads; change management for updates/deprecations.
- Density-adaptive retrieval in production RAG stacks
- Sectors: software, search, customer support, documentation portals
- What: Add retrieved-set density check (ρ) to switch between embedding retrieval and exact key matching for adversarial neighborhoods (e.g., SKU variants, versioned docs, near-identical policies).
- Tools/workflow: Existing RAG pipeline (e.g., LangChain/LlamaIndex) + density calculator + key extractor + conditional reranker; threshold τ≈0.85 (tunable); fall back to exact match on (subject, predicate).
- Benefits: 100% P@1 on adversarial fact clusters without hurting general retrieval; prevents “near-duplicate but wrong” answers.
- Assumptions/dependencies: Availability of keys in content or derivable via lightweight parsing; telemetry to measure ρ and trigger path.
- KO-powered clinical and pharmaceutical fact layers
- Sectors: healthcare, life sciences, pharmacology
- What: Encode drug–target–assay tuples, dosing rules, contraindications, and trial metadata as KOs; CDS and research assistants retrieve by exact keys rather than long prompts or embeddings alone.
- Tools/workflow: ETL from labeling/clinical trial registries into KOs with provenance (source, date, confidence); clinicians/researchers query via natural language parsed to (drug, relation, target/parameter).
- Benefits: Fact-level precision, resistance to adversarial similarity (similar molecules/targets), strong audit trails.
- Assumptions/dependencies: High-quality normalization (RxNorm, MeSH, UniProt); clear authority hierarchy for provenance; HIPAA/GDPR compliant storage.
- Account- and policy-accurate customer support assistants
- Sectors: customer support, telecom, SaaS, retail
- What: Store account entitlements, SLAs, region-specific policies, and exception approvals as KOs; assistants resolve keys like (account_id, entitlement), (region, refund_policy).
- Tools/workflow: Middleware layer that resolves customer/session keys into KOs before answer generation; “not found” paths escalate to human or knowledge capture.
- Benefits: Eliminates silent reversion to defaults; consistent, personalized responses; auditability of policy applications.
- Assumptions/dependencies: Identity resolution to correct account; real-time KO updates; privacy controls.
- Finance risk and compliance guardrails
- Sectors: finance, banking, insurance
- What: Encode risk limits, trading constraints, product eligibility, KYC/AML rules as KOs applied at decision time by analyst copilots and booking systems.
- Tools/workflow: Keyed lookups like (desk, product, risk_limit), (jurisdiction, KYC_rule_version); explainability via provenance.
- Benefits: Prevents violations due to context compaction; consistent application across agents and tools; lower operational risk and audit cost.
- Assumptions/dependencies: Up-to-date regulatory mappings; strong access controls; versioning/attestation processes.
- Enterprise knowledge bases without compaction
- Sectors: enterprise KM, HR, operations
- What: Replace summarization-based “agent memory” with KO stores for SOPs, handbooks, decision logs, and exceptions; agents retrieve exact constraints and steps.
- Tools/workflow: KO ingestion pipelines; topic-to-key mapping; density-adaptive RAG for unstructured content plus KO exact matches for procedures/parameters.
- Benefits: No context rot; stable costs independent of corpus size; better reproducibility.
- Assumptions/dependencies: Governance for key schema evolution; deduplication and deprecation workflows.
- Research reproducibility and lab notebook KOs
- Sectors: academia, R&D, biotech, materials science
- What: Extract experiment parameters, outcomes (including negatives), and data provenance into KOs; assistants plan next steps via multi-hop KO retrieval.
- Tools/workflow: Templates to capture (experiment_id, parameter, value, units, error); nanopublication-like provenance fields; export to publication supplements.
- Benefits: Eliminates loss of fine-grained parameters in summaries; easier replication; explicit credit via provenance.
- Assumptions/dependencies: Researcher adoption; unit/ontology alignment; permissioning for sensitive results.
- “Memory health” observability for LLM systems
- Sectors: MLOps, platform engineering
- What: Instrumentation that tracks context length, compression ratios, density-trigger rates, KO hit/miss rates; SLOs and alerts for context rot risk.
- Tools/workflow: Dashboards, canaries that query known KOs, drift tests for constraints; budget policies that prevent excessive summarization.
- Benefits: Early detection of information loss; measurable memory reliability.
- Assumptions/dependencies: Telemetry integration; gold KO test sets.
- Cost-optimized AI operations
- Sectors: finance/ops across all industries
- What: Shift from in-context to KO retrieval to reduce token spend (97–99% reduction reported); budgeting that fixes annual memory costs.
- Tools/workflow: FinOps dashboards; per-query cost accounting; migration playbooks.
- Benefits: Predictable and lower costs at scale; avoids quadratic attention costs.
- Assumptions/dependencies: Accurate cost modeling; stakeholder buy-in for architecture change.
- Education: accommodation-accurate tutoring
- Sectors: education, EdTech
- What: Store student-specific constraints (IEPs, accommodations, goals) as KOs and resolve them before lesson generation.
- Tools/workflow: LMS integration; per-student KO namespace; “policy preflight” for lesson plans.
- Benefits: Personalization without drift; compliance with accommodations.
- Assumptions/dependencies: Consent and privacy; robust identity mapping.
- Personal knowledge management without drift
- Sectors: daily life, consumer apps
- What: Keep immutable KOs for medication schedules, allergies, household configs, travel preferences; assistants consult KOs before suggestions.
- Tools/workflow: Mobile/desktop PKM app with KO store; simple key templates; local-first or encrypted cloud storage.
- Benefits: Reliable, personalized assistance over months/years; avoids loss from periodic summarization.
- Assumptions/dependencies: Usable UI for key creation; privacy-by-design.
Long-Term Applications
These opportunities likely require further research, scaling, standardization, or ecosystem adoption beyond current off-the-shelf capabilities.
- Standardized bicameral memory for AI agents
- Sectors: software platforms, agent frameworks
- Vision: Make external, addressable memory (KOs) a first-class OS/service alongside parametric model memory; learned routers use density signals and task archetypes to choose memory pathways.
- Dependencies: Open standards (API/format), ecosystem integration across frameworks, learned routing policies tuned per domain.
- KO–knowledge graph fusion with schema evolution
- Sectors: enterprise data, semantic web, scientific knowledge
- Vision: Layer KOs as a flat, robust fact substrate that can be progressively lifted into typed knowledge graphs for reasoning; automatic schema induction and ontology alignment.
- Dependencies: Reliable entity resolution; versioned schemas; tooling for incremental lifting and back-compat.
- Safety-critical robotics and industrial control memory
- Sectors: robotics, manufacturing, aviation, automotive, energy
- Vision: Robots and control agents consult certified KOs for torque specs, safety envelopes, and maintenance states, with offline caches and provenance checks.
- Dependencies: Real-time constraints and deterministic fallbacks; certification of KO provenance; robust synchronization and fail-safe modes.
- Regulatory-grade provenance and audit in AI systems
- Sectors: policy, regulated industries (health, finance, gov)
- Vision: Mandate or standardize KO-like provenance for AI decisions that rely on stored facts; regulators accept KO logs as audit artifacts (alignment with EU AI Act, FDA/EMA guidance).
- Dependencies: Standards bodies’ engagement; legal acceptance of digital provenance; secure time-stamping/attestation.
- Lifelong personal memory with privacy-preserving compute
- Sectors: consumer, healthcare, finance
- Vision: Encrypted, portable KO vaults spanning years of personal data; local inference or privacy-preserving server-side access; fine-grained consent.
- Dependencies: Usable consent/UI models; interoperable formats; secure multi-party or TEEs; right-to-erasure tooling.
- Autonomous research co-pilots with multi-hop KO reasoning
- Sectors: academia, pharma, materials, climate
- Vision: Agents plan experiments by chaining precise KOs (materials, parameters, prior outcomes) and proposing next steps; integrate uncertainty and priors.
- Dependencies: Improved multi-hop orchestration; uncertainty-aware answer generation; domain ontologies; lab automation interfaces.
- KO-native IDEs and “memory-safe” agent runtimes
- Sectors: software engineering tools
- Vision: Development environments that enforce constraint retrieval before code generation, deployment, or migrations; “policy as KOs” with blocking checks.
- Dependencies: IDE vendor integration; policy authoring UX; org-wide adoption of key standards.
- Data governance via KO-enforced data contracts
- Sectors: data platforms, analytics
- Vision: Data contracts, PII handling rules, and schema versions are KOs enforced at query time and pipeline execution; embedded density checks for adversarial schema collisions.
- Dependencies: Tight integration with warehouses (Snowflake/Databricks/BigQuery); lineage capture; access control.
- Embedding models and indexes co-designed with KO signals
- Sectors: search infra, ML
- Vision: Indexes that compute density cheaply, expose it natively, and integrate key-aware rerankers; embeddings trained to surface discriminative keys.
- Dependencies: Open-source/index vendor support; benchmark-driven training; standardized APIs.
- Sector-specific KO catalogs and marketplaces
- Sectors: legal, healthcare, finance, engineering
- Vision: Curated, licensed KO datasets with high-quality provenance (e.g., statutes/clauses, device specifications, pricing terms) consumable by agents.
- Dependencies: IP/licensing models; curation standards; update cadences and deprecation policies.
- Memory reliability metrics and certifications
- Sectors: compliance, platform certification
- Vision: Third-party “memory reliability” certifications based on context-rot resistance, precision under adversarial density, and provenance completeness.
- Dependencies: Benchmarks (like this paper’s suite) becoming industry norms; independent auditors; reporting standards.
- Edge and offline KO caches for critical infrastructure
- Sectors: energy, telecom, defense
- Vision: Agents operate with KO snapshots during connectivity loss, reconciling later with conflict resolution and provenance merges.
- Dependencies: Snapshotting protocols; conflict-free replicated data types (CRDTs); rigorous reconciliation semantics.
Notes on cross-cutting assumptions and dependencies (affecting both horizons):
- Canonicalization: Robust, versioned key schemes and synonym handling (e.g., entity IDs, units).
- Extraction quality: Reliable KO creation from conversations/docs; human-in-the-loop where stakes are high.
- Security and privacy: Access control, encryption, differential access by role; compliance with GDPR/CCPA/HIPAA.
- Provenance governance: Clear source-of-truth, timestamps, confidence; procedures for correction and retraction.
- Coverage vs. fallbacks: Graceful “not found” handling and knowledge capture loops to extend KO coverage.
- Organizational adoption: Training, change management, and incentives to move from summarization-based memory to KO-backed architectures.
- Latency budgets: Query parsing + KO lookup must meet product SLOs; caching strategies where needed.
Glossary
- Adversarial facts: Pairs of items that are semantically near-identical in embedding space but assert different ground-truth values, causing similarity-based retrieval to fail. "embedding retrieval fails on adversarial facts (20\% precision at 1)"
- BEIR: A benchmark suite for information retrieval evaluation across diverse datasets and tasks. "BEIR NDCG@10"
- Bicameral architecture: A two-system memory design that separates discrete external storage for specific facts from neural memory for patterns, with a router deciding which to use. "they proposed a ``bicameral'' architecture inspired by complementary learning systems theory from cognitive neuroscience"
- BigBird: A transformer variant that uses sparse attention patterns to handle very long sequences efficiently. "BigBird's sparse attention patterns"
- BM25: A classic probabilistic retrieval function that ranks documents based on term frequency and document length normalization. "hybrid approaches interpolating sparse BM25 scores with dense similarity"
- Compressive Transformers: Models that learn to compress past activations into a smaller memory bank to extend effective context. "Compressive Transformers \citep{rae2019compressive} approach the problem architecturally, learning to compress past activations into a smaller memory bank"
- Contrastive learning: A training approach that pulls semantically similar representations together and pushes dissimilar ones apart without requiring labeled relevance. "contrastive learning objectives that operate without labeled relevance judgments"
- Context rot: The progressive, often silent erosion of stored knowledge due to lifecycle operations like session boundaries and compaction. "We term this progressive degradation context rot:"
- Cosine similarity: A measure of similarity between vectors based on the cosine of the angle between them, commonly used for embeddings. "pairwise cosine similarity exceeds 0.95."
- Dense passage retrieval (DPR): A dense retrieval method that encodes queries and documents into the same vector space and retrieves by nearest neighbors. "dense passage retrieval (DPR) embeds both queries and documents into a shared vector space"
- Density-adaptive retrieval: A hybrid retrieval strategy that switches methods based on the similarity density of retrieved candidates to avoid errors in crowded embedding neighborhoods. "We introduce density-adaptive retrieval"
- Dual encoders: A retrieval architecture that uses separate encoders for queries and documents, enabling efficient nearest-neighbor search. "using dual encoders"
- EGFR: Epidermal Growth Factor Receptor, a protein target in pharmacology/oncology. "Erlotinib inhibits EGFR with IC50 = 2.3 nM"
- FlashAttention: An IO-aware attention algorithm optimized to reduce memory bandwidth bottlenecks for long contexts. "FlashAttention's IO-aware implementation that minimizes memory bandwidth bottlenecks"
- Goal drift: The loss or erosion of goals and constraints over time (e.g., through summarization), causing systems to revert to defaults without awareness. "Goal drift is more insidious than fact loss"
- Hard negative mining: Training technique that uses particularly confusable or challenging non-relevant examples to improve retriever robustness. "hard negative mining that exposes the model to challenging distractors during training"
- IC50: The concentration of a substance required to inhibit a biological process by 50%, used as a potency measure. "IC50 = 2.3 nM"
- Knowledge graphs: Structured representations that store facts as subject–predicate–object triples with explicit entity identifiers. "knowledge graphs that store facts as triples"
- Knowledge Objects (KOs): Discrete, hash-addressed tuples storing facts (with provenance) externally for O(1) lookup. "We propose Knowledge Objects (KOs)---discrete, hash-addressed tuples"
- Linear Associative Memory (LAM): An associative memory mechanism underlying linearized attention and related models, subject to interference limits. "Linear Associative Memory (LAM), the memory mechanism underlying linearized attention and state-space models"
- Longformer: A transformer architecture using sliding-window attention with global tokens to handle long sequences. "Longformer's sliding window with global tokens"
- Lost in the Middle: A phenomenon where models struggle to retrieve information placed in the middle of long contexts. "demonstrated the ``Lost in the Middle'' phenomenon"
- Nanopublication: A framework for publishing small, structured assertions with detailed provenance metadata. "The nanopublication framework \citep{groth2010anatomy} extends this approach with rich provenance metadata"
- NDCG@10: Normalized Discounted Cumulative Gain at rank 10; a metric for evaluating the quality of ranked retrieval results. "BEIR NDCG@10"
- Orthogonality Constraint: A theoretical limit indicating that storing many similar items in shared representational spaces causes interference and retrieval collapse. "Following recent theoretical work on the Orthogonality Constraint"
- Parametric neural memory: Knowledge stored implicitly in model parameters (weights), as opposed to external discrete storage. "parametric neural memory (analogized to the neocortex) for patterns and generalizations"
- Precision@1 (P@1): The fraction of queries for which the top-ranked result is relevant. "embedding retrieval achieves only 20\% precision@1"
- Provenance metadata: Information about the origin, authorship, and context of a fact or document. "rich provenance metadata"
- Retrieval-augmented generation (RAG): A paradigm where a model retrieves external documents to ground and inform its generated outputs. "The retrieval-augmented generation (RAG) paradigm"
- Ring attention: A technique that distributes long-sequence attention computation across devices to scale context length. "ring attention that distributes long sequences across devices"
- RotatE: A knowledge graph embedding method modeling relations as rotations in complex space. "RotatE \citep{sun2019rotate}"
- Semantic density: The average similarity among retrieved items indicating how crowded a query’s local neighborhood is in embedding space. "high semantic density"
- Sparse attention: Attention mechanisms that reduce computational cost by attending over a sparse subset of positions. "sparse attention patterns"
- State-space models: Sequence models that represent dynamics with state-transition equations; in this context, related to linearized attention mechanisms. "state-space models"
- Structured key matching: Exact retrieval using structured keys (e.g., subject–predicate) instead of similarity search. "falls back to exact structured key matching on the tuple."
- TransE: A knowledge graph embedding model representing relations as translations in vector space. "TransE \citep{bordes2013transe}"
Collections
Sign up for free to add this paper to one or more collections.

