The FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality (2512.10791v1)
Abstract: We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of LLMs to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
Sponsor

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces the FACTS Leaderboard — a big, public scoreboard that measures how well AI LLMs tell the truth. It tests models in four different situations and combines their scores to give one overall “factuality” score. The goal is to see how reliable models are when answering questions, looking things up, and explaining content.
What questions did the researchers ask?
They focused on simple but important questions:
- How often do AI models give factually correct answers?
- Do models stay true to the information they’re given (like a picture or a document)?
- Can models answer questions using their own “memory,” without searching the web?
- Can models use a search tool to find accurate information?
- Can we judge these answers automatically in a fair, consistent way?
How they tested the models
Think of this like a school report card with four subjects. The models are tested in four “pillars,” each checking a different type of truthfulness:
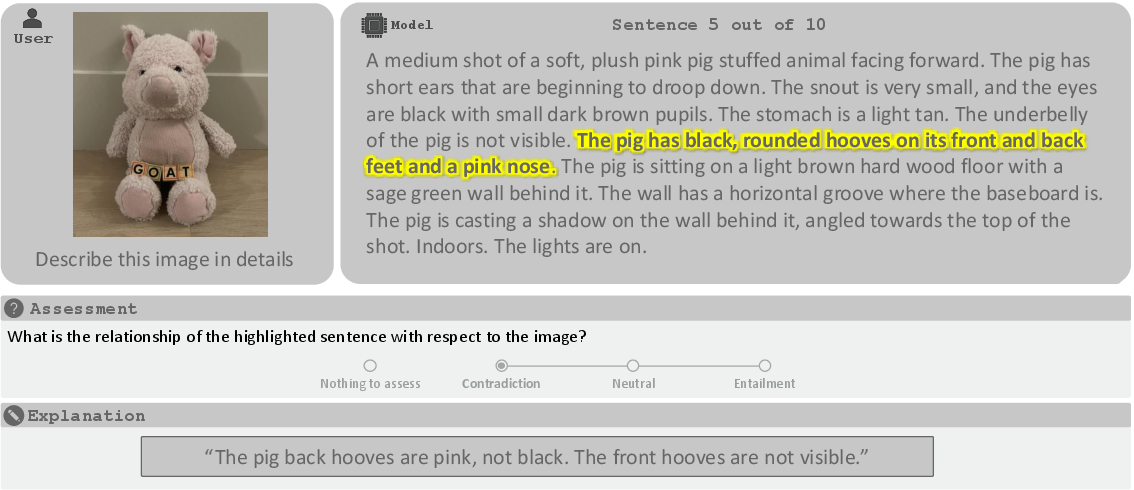
- FACTS Multimodal: The model looks at an image and answers a question about it. It must use what’s in the picture plus general knowledge, without making things up.
- FACTS Parametric: The model answers short factual questions using its own internal knowledge (no web search). All answers must be supported by Wikipedia.
- FACTS Search: The model uses a web search API (Brave Search) to find answers, like a student who’s allowed to look things up.
- FACTS Grounding v2: The model reads a document and writes an answer or summary that must be grounded in that document — no extra facts or guesses.
Each pillar uses automated “judge models” to score answers. The final FACTS Score is the average of all four pillar scores. There are both public and private test sets to keep the evaluation fair and prevent memorization.
How scoring works (in everyday terms)
- Automated judges: These are AI graders trained to act like careful fact-checkers. They check whether answers include the key facts and whether they avoid contradictions.
- Public vs. private tests: Some questions are shown publicly, but others are kept hidden. This limits overfitting (models shouldn’t just memorize the test).
- Accuracy: The percentage of answers the judge marks as correct.
- Attempted accuracy and hedging: If a model sometimes says “I’m not sure” or refuses to answer, that’s called hedging. Attempted accuracy measures how often the model is right when it does try to answer.
Pillar details
FACTS Multimodal (questions about images)
- Method: Human annotators write rubrics (lists of essential and non-essential facts) for each image-question pair. The AI judge checks:
- Coverage: Did the answer include all essential facts?
- No-Contradiction: Did the answer avoid claims that contradict the rubric, the image, or common knowledge?
- An answer only counts as accurate if it covers the essentials and contains no contradictions.
- Validation: The judges were compared to human ratings and showed strong agreement.
FACTS Parametric (closed-book factual questions)
- Method: Questions reflect real user interests and must have answers supported by Wikipedia. The team used “adversarial sampling” — they picked questions that several strong open-source models failed to answer correctly.
- Judges label responses as correct, incorrect, not-attempted (hedged), or unknown.
- This setup tests a model’s “memory” of stable facts (like a person’s birthplace or a date).
FACTS Search (with a web search tool)
- Method: All models use the same search API (Brave Search) for fairness. Questions are designed to be hard without search, including:
- Hard Tail: Tricky, less-popular topics written by humans.
- Wiki Two-Hop: Questions that need multiple steps of reasoning.
- Wiki Multi-Doc: Questions requiring information from several documents.
- KG Hops: Questions built from linked facts in a knowledge graph.
- Judges score correctness and track things like hedging and how many searches a model makes per question.
FACTS Grounding v2 (answers must stick to the given document)
- Method: Long-form tasks (like Q&A and summarization) with long documents. The new version improves the judge models to better catch ungrounded claims.
- Purpose: Reward models that closely follow the source material, rather than adding facts from elsewhere.
What they found
Big picture:
- No model is perfect, but some are clearly stronger.
- Gemini 3 Pro had the highest overall FACTS Score (about 68.8 out of 100), meaning it was the most reliable across all four pillars in this test.
- Many models performed best on the Search pillar (using tools to look things up) and were weaker on Multimodal (images) and Grounding (long documents).
- Different model families have different styles:
- In Multimodal, Gemini models tend to include more essential facts (higher coverage), while GPT models tend to avoid contradictions better (higher precision).
- In Parametric and Search, some models hedge more — they say “I don’t know” more often — which can improve their accuracy on attempted answers.
- Efficiency varies: For Search, top models may find more correct answers while making fewer total search calls, showing smarter use of the tool rather than just searching more.
Examples of pillar-specific patterns:
- Multimodal accuracies for top models were in the mid-40% range (this is a hard task).
- Parametric (memory-based) best accuracy was around 76% (Gemini 3 Pro).
- Search best accuracy was around 84% (Gemini 3 Pro), with strong attempted accuracy.
- Grounding scores vary and are crucial for tasks like summarizing documents without adding extra claims.
Why this matters
This leaderboard gives a fuller picture of how trustworthy an AI model is. Instead of judging models on a single test, it:
- Measures truthfulness across different real-world situations (images, memory, web search, and document reading).
- Encourages building models that are not just good at one thing but reliable overall.
- Helps researchers and users compare models fairly, using the same tools and scoring.
- Uses both public and private tests to keep evaluations honest and avoid gaming the system.
- Can guide better model design for practical tasks like research assistance, data analysis, and answering questions accurately.
In short, the FACTS Leaderboard is like a comprehensive truthfulness exam for AI, helping everyone see which models are most dependable and pushing the field toward more accurate, grounded answers. You can explore it and participate via Kaggle, and the team plans to keep it updated over time.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper. Each point is framed to be actionable for future research.
- Dependence on judge models from a single vendor: Most grading relies on Gemini-family autoraters (e.g., Gemini-2.5-Pro for Parametric and Gemini 2.0 Flash for Search), raising concerns about judge bias, self-preference, and fairness across competing model families. How robust are rankings to alternative or mixed-panel judges, and can a standardized, open-weight ensemble judge reduce bias?
- Limited validation of updated Grounding v2 judges: The paper claims “significantly improved judge models” but does not present quantitative human–judge agreement, error analyses, or inter-rater reliability for v2. What are the measured improvements vs. v1 on curated human ground truth, and how do judge decisions change rankings?
- Autorater reliability is moderate and thresholding is ad hoc: Multimodal Coverage shows Spearman 0.64 and macro F1 72.3; No-Contradiction macro F1 is 78.2. The Coverage boolean threshold (0.5) is chosen without sensitivity analysis. How sensitive are leaderboard rankings to judge error rates, thresholds, and rubric composition? Provide calibration curves and stability analyses.
- Unclear whether multimodal judges actually “see” images: No explicit description confirms visual input to the autorater. If the judge does not process images, “contradictions to the input image” cannot be reliably assessed. Clarify and, if necessary, add a vision-capable judging pipeline with documented accuracy on visual claims.
- Rubric construction subjectivity and missing agreement metrics: Essential vs. Non-essential fact labeling is inherently subjective; the paper provides no inter-annotator agreement, annotation guidelines fidelity checks, or quality metrics. Quantify rubric consistency and measure how rubric variability affects model accuracy and rankings.
- Completeness vs. usefulness trade-offs are underexplored: Accuracy requires both covering essential facts and having no contradictions, which may penalize otherwise useful partial answers. Develop graded utility metrics (e.g., weighted coverage, partial credit, user utility models) and assess their impact on rankings.
- Aggregation is a naïve unweighted average: The “FACTS Score” averages four heterogeneous tasks without justification of equal weighting or task difficulty normalization. Perform sensitivity analyses on task weights, difficulty-adjusted scoring, or bootstrapped reliability to avoid overweighting easier or noisier slices.
- Search benchmark tightly coupled to a single engine: All models use the Brave Search API; no cross-engine sensitivity or robustness (e.g., to Bing, Google, DDG) is reported. Evaluate how engine choice, snippet quality, and tool output format affect model performance and tool-use behavior.
- Tool-call protocol and context ingestion are under-specified: The Search task appends API output to context, but details (snippet depth, page retrieval vs. snippets-only, timeouts, rate limits, pagination) are not documented. Standardize and report tool-call budgets, content extraction policies, and latency constraints to ensure fair comparison.
- Synthetic-question artifacts and distribution shift in Search: Three of four Search subsets are generated synthetically (Wiki Two-Hop, Multi-Doc, KG Hops). Investigate whether synthetic generation introduces artifacts models exploit or avoid, and expand with real-world, user-authored multi-hop queries to validate external validity.
- “Requires search” filtering is model-anchored: Search queries are filtered to exclude those Gemini 2.5 Flash (without search) can answer, creating potential selection bias toward Gemini’s weaknesses or strengths. Re-run “requires search” filtering against diverse models and document the effect on task composition and fairness.
- Parametric labels anchored to Gemini-generated silver answers: Initial answers come from Gemini-2.5-Pro with search; although later human-verified, anchoring can bias examples and corrections. Quantify silver-label error rates and assess whether alternative silver sources or multi-source anchoring change dataset quality.
- Wikipedia-only evidence constraint narrows coverage: Restricting Parametric answers to Wikipedia biases topics and excludes true facts absent from Wikipedia. Explore multi-source evidence (e.g., Wikidata, reputable news, textbooks) with provenance scoring, while maintaining verifiability and stability.
- No evaluation of recency/freshness: The Search benchmark filters for “immutable” answers and Parametric uses time-anchored or static facts, leaving dynamic/rapidly-changing factuality largely untested. Add a freshness slice with date-anchored queries, measure temporal generalization, and evaluate update-aware behaviors.
- Hedging detection is judge-dependent and may be gameable: “Not-attempted” classification can be influenced by phrasing (e.g., cautious language), enabling potential gaming. Develop robust, formal uncertainty metrics (e.g., calibrated confidence scores, abstention quality via selective prediction) and cross-check against human labels.
- Citation and attribution quality are not measured: Search and Parametric slices do not assess whether produced citations are correct, sufficient, and attributable. Add citation precision/recall, source fidelity, and quote integrity metrics to reflect responsible factuality.
- Multilingual and cross-cultural coverage is missing: All benchmarks appear English-centric with Wikipedia as a source. Evaluate factuality across languages, scripts, and culturally diverse knowledge sources, and report per-language reliability of judges and datasets.
- Multi-turn factuality and context persistence are not tested: Benchmarks use single-turn prompts. Introduce multi-turn settings to evaluate factual consistency over dialog, correction handling, and resistance to drift across turns.
- Long-context and retrieval depth limitations: Grounding uses long-form documents but lacks reporting on context length extremes, retrieval-augmented settings, or models’ ability to handle very large inputs. Include stress tests for context windows, chunking strategies, and retrieval depth.
- Numeric normalization and synonym handling are under-specified: The grading policy for equivalent numeric ranges, units, alternate entity names, and paraphrases is unclear beyond isolated examples. Publish normalization rules and unit-conversion policies; test judge sensitivity to common equivalences.
- Topic and demographic bias analyses are absent: While topics include politics, sports, tech, there is no breakdown of performance by topic difficulty, demographic coverage, or bias. Provide per-category performance, bias diagnostics, and audits of judge decisions across sensitive topics.
- Statistical rigor for the aggregate score: Confidence intervals are reported per subset but not for the overall FACTS Score; no significance testing across models is shown. Provide aggregated uncertainty (e.g., bootstrap CIs), pairwise significance, and rank stability analyses.
- Versioning and comparability over time: The suite will be “actively maintained,” but changes to judges, tools, and splits can break score comparability. Establish versioned benchmarks, frozen splits, and change logs; report back-compatibility and re-scoring policies when judges or tools are updated.
- Data leakage and contamination controls: Public splits exist and models can train on them. Detail contamination checks, canary prompts, or rotating private splits to discourage overfitting and ensure leaderboard integrity.
- Limited modalities: The suite covers text and images; audio, video, and tables are not included. Expand multimodal slices (e.g., AVQA, chart/table comprehension with provenance) and add judges capable of robustly evaluating those modalities.
- Participant reproducibility: Proprietary API-based evaluations on Kaggle hinder independent replication. Provide open-weight, locally runnable judges, synthetic tool simulators, and a public scoring harness to enable reproducible community evaluation.
Glossary
- Adversarial sampling: A data collection strategy that uses model failures to select especially challenging examples. "Each of the questions was found challenging through adversarial sampling with a suite of open-source models (see \S\ref{sec:parametric-data-processing})."
- Attempted accuracy: Accuracy computed only over responses where the model attempts an answer (excluding hedges). "Consequently, GPT-5 achieves superior attempted accuracy ( vs. ) and F1 scores ($59.7$ vs. $57.6$)."
- Autorater: An automated evaluator that scores model outputs against a reference rubric. "The autorater uses the rubric to generate two distinct verdicts for factuality and completeness."
- Automated judge models: Models used to automatically assess and score the correctness of responses. "Each sub-leaderboard employs automated judge models to score model responses"
- Brave Search API: The web search service used uniformly across models for the Search benchmark. "The FACTS leaderboard evaluation uses the Brave Search API as the search tool."
- Closed-book setting: An evaluation mode where models answer without external tools or sources. "we query these models in a closed-book setting, without access to external search tools."
- Coverage verdict: A boolean judgment that a response includes all essential facts from the rubric. "Coverage verdict: This boolean verdict verifies that the model response includes the essential facts specified in the ground-truth rubric."
- FACTS Grounding v2: The updated grounding benchmark assessing whether responses are consistent with a provided document. "FACTS Grounding v2 is an updated version of FACTS Grounding, which tests grounding to a given document, with improved judges."
- Google Knowledge Graph: Google’s structured database of entities and relations used to synthesize or alter questions. "with a different description of this entity that is extracted from the Google Knowledge Graph."
- Hard Tail: A dataset slice focusing on difficult, low-popularity (tail) entities and questions. "The resulting final dataset sizes were 328, 932, 268, 356 for Hard Tail,Wiki Two-Hop,Wiki Multi-Doc, and KG Hops respectively."
- Hedging rate: The proportion of cases where the model avoids answering (labels like not-attempted). "Hedging rate (the percentage of not-attempted)"
- Immutability: An evaluation criterion checking if an answer is unlikely to change over time. "Immutability: Identify whether the answer to the given query is likely to change in the next five years."
- KG Hops: A dataset slice generated via multi-hop paths over the Knowledge Graph. "The resulting final dataset sizes were 328, 932, 268, 356 for Hard Tail,Wiki Two-Hop,Wiki Multi-Doc, and KG Hops respectively."
- Macro F1: The F1 score averaged across classes, used to validate autorater reliability. "This validation achieved a macro F1 score of 78.2."
- Multi-hop queries: Questions requiring chaining multiple facts or steps to reach an answer. "These include tail-entities which are often not sufficiently encoded in parameters, and multi-hop queries (where it's less likely that all hops are encoded in the parameters)."
- No-Contradiction verdict: A boolean judgment that a response contains no statements contradicting the rubric, common knowledge, or the input. "No-Contradiction verdict: This boolean verdict verifies that the model response does not include any claims that contradict either the ground-truth rubrics (essential and non-essential), common knowledge or the input image itself."
- Parametric world knowledge: Facts encoded in a model’s parameters rather than accessed via external tools. "This task requires the integration of visual grounding with parametric world knowledge, a critical capability for modern multimodal systems."
- Rubric: A structured list of essential and non-essential facts used for systematic evaluation. "This rubric-based methodology is central to our benchmark, as it provides a scalable and objective framework for evaluation."
- Silver labels: Preliminary, automatically generated labels used prior to human verification. "First, we generate preliminary ``silver'' labels for all questions using Gemini-2.5-Pro equipped with search tools."
- Spearman's rank correlation: A nonparametric statistic measuring rank agreement, used to compare autorater and human judgments. "on which our autorater achieved a high degree of reliability with a Spearman's rank correlation of 0.64 with human judgments."
- Tail entities: Rare or less common entities that are underrepresented in training data. "and filtered to focus on tail entities."
- Tool call: An LLM’s invocation of an external tool (e.g., search), whose output is fed back into the context. "When an LLM triggers a tool call, the API is queried, and the output is appended to the LLM context."
- Wiki Multi-Doc: A dataset slice built from synthesizing information across multiple Wikipedia documents. "The resulting final dataset sizes were 328, 932, 268, 356 for Hard Tail,Wiki Two-Hop,Wiki Multi-Doc, and KG Hops respectively."
- Wiki Two-Hop: A dataset slice where questions are transformed to require two reasoning hops across Wikipedia/knowledge. "The resulting final dataset sizes were 328, 932, 268, 356 for Hard Tail,Wiki Two-Hop,Wiki Multi-Doc, and KG Hops respectively."
Practical Applications
Immediate Applications
Below is a set of practical, deployable use cases that leverage the FACTS Leaderboard’s benchmarks, judge models, and workflows.
- Model procurement and vendor selection using the FACTS Score
- Sector: software, finance, healthcare, education
- What to do: Use the aggregate FACTS Score and sub-scores (Grounding, Parametric, Search, Multimodal) to select LLMs for specific product requirements (e.g., document-grounded summarization vs. closed-book Q&A vs. web-enabled assistants).
- Tools/workflows: Integrate the Kaggle leaderboard data into internal evaluation dashboards; require minimum sub-scores in SLAs for high-stakes deployments.
- Assumptions/dependencies: Access to the leaderboard and consistent evaluation conditions; alignment between benchmark tasks and your domain tasks.
- Production QA gate for LLM outputs using Coverage and No-Contradiction autoraters
- Sector: software, media, e-commerce
- What to do: Insert the multimodal rubric autorater as a pre-release gate; reject or route to human review if a response fails essential fact coverage or contains contradictions.
- Tools/workflows: “Guardrail” service calling the FACTS-like autorater with rubrics; incident logging of contradictions; prompt adjustments to improve coverage.
- Assumptions/dependencies: Availability of task-specific rubrics or a rubric-generation pipeline; tolerance for added latency and cost.
- RAG pipeline validation with FACTS Grounding v2 judges
- Sector: healthcare (clinical guideline assistants), finance (earnings-call/10-K summarizers), legal (brief drafting), energy (compliance filings)
- What to do: Automatically audit long-form outputs to ensure claims are grounded in provided documents; flag unsupported sentences and contradictions.
- Tools/workflows: A grounding QA microservice; per-paragraph grounding checks; fallbacks to cite exact passages; dashboards of grounding adherence rates by model/version.
- Assumptions/dependencies: Robust document retrieval; consistent, well-structured context; acceptance of automated judge decisions (Gemini-2.5-Pro-based).
- Search-tool orchestration tuning based on FACTS Search diagnostics
- Sector: software, knowledge work, customer support
- What to do: Optimize tool-calling policies (when to search, how many queries, multi-hop strategies) to improve attempted accuracy and reduce hedging.
- Tools/workflows: A “search controller” layer instrumented for average searches, hedging rate, and attempted accuracy; A/B tests across prompts and tool settings (Brave Search API).
- Assumptions/dependencies: Stable access to the search API; privacy/compliance review for external calls; adaptability of prompts for multi-hop reasoning.
- Editorial fact-checking of images and captions using FACTS Multimodal
- Sector: media, e-commerce, mapping/geo, education
- What to do: Use the multimodal judge to verify that captions and alt text cover essential visual facts and avoid contradictions (e.g., product attributes, museum labels).
- Tools/workflows: Batch verification of catalog images; rubric libraries per content type (products, artworks, charts).
- Assumptions/dependencies: High-quality visual inputs; availability of essential facts for each image; tolerance for false positives/negatives.
- Calibrated assistant behavior using “attempted accuracy” and hedging metrics
- Sector: customer support, productivity apps
- What to do: Configure assistants to hedge (ask clarifying questions, defer) when closed-book confidence is low; route to search or human agents accordingly.
- Tools/workflows: Confidence-to-action policies informed by benchmark hedging rates; UI affordances for “fact-check mode.”
- Assumptions/dependencies: Clear operational policies for hedging; UX for deferrals; acceptance of occasional slower responses.
- Academic benchmarking and reproducible factuality studies
- Sector: academia
- What to do: Use the suite’s data splits and metrics to study factuality across modalities, search usage, and closed-book recall; measure effects of training interventions.
- Tools/workflows: Replicate autorater validation (macro F1 for Coverage and No-Contradiction); compare ensemble judges vs. single-judge setups; report confidence intervals.
- Assumptions/dependencies: Access to data splits and models; awareness of judge-model biases.
- Policy and internal compliance checks for factual claims
- Sector: policy, enterprise risk, communications
- What to do: Pre-publication checks of press releases or regulated content with a grounding gate; maintain audit trails of factual verification.
- Tools/workflows: Internal “factuality audit” workflows; documented thresholds aligned to FACTS task types; periodic relabeling audits.
- Assumptions/dependencies: Concise, auditable prompts and contexts; governance acceptance of automated judgments.
- Power-user daily workflows for trustworthy answers
- Sector: daily life, knowledge work
- What to do: Enable “Trust Toggle” modes that force search for tail queries, and “Fact-check Me” buttons that run grounding checks on drafts.
- Tools/workflows: Assistant settings to prefer search for multi-hop queries; inline “show sources” and “no-contradiction” indicators.
- Assumptions/dependencies: Users’ willingness to trade speed for reliability; access to search; clear UX communication.
Long-Term Applications
These applications require further research, scaling, standardization, or development before broad deployment.
- Sector-specific factuality certification schemes based on FACTS
- Sector: healthcare, finance, legal, public sector
- What to do: Define minimum sub-scores and judge configurations for “safe-to-deploy” certification in high-risk domains; include audit procedures and drift monitoring.
- Tools/products: “FACTS for Healthcare/Finance” test suites; certification badges; regulator-recognized protocols.
- Assumptions/dependencies: Policy buy-in; domain-specific datasets with strong ground truth; multi-lingual and jurisdictional coverage.
- Dynamic rubric generation and automated fact-checking co-pilots
- Sector: software, media, education
- What to do: Build systems that synthesize task-specific rubrics on the fly, then run Coverage/No-Contradiction checks for complex, evolving tasks.
- Tools/products: Rubric generator + autorater as an API; writer/editor co-pilots that highlight missing essentials and likely contradictions.
- Assumptions/dependencies: Reliable rubric synthesis; scalable judge accuracy; human-in-the-loop review for edge cases.
- Training-time optimization for factuality (coverage and contradiction-aware RL)
- Sector: model development
- What to do: Incorporate Coverage and No-Contradiction rewards into RLHF/RLAIF; penalize unsupported claims and encourage citing.
- Tools/workflows: Judge-in-the-loop training pipelines; curriculum emphasizing tail entities and multi-hop reasoning.
- Assumptions/dependencies: Stable judge accuracy across distributions; compute budget; prevention of overfitting to the benchmark.
- Advanced search-retrieval orchestration with privacy and efficiency constraints
- Sector: enterprise software, security
- What to do: Optimize multi-hop search with caches and local indices; hybrid retrieval that respects data residency and compliance.
- Tools/products: Privacy-preserving retrieval layers; “attempted-accuracy vs. search-cost” controllers; query planning modules.
- Assumptions/dependencies: Secure infrastructure; legal approvals; effective on-prem alternatives to public search APIs.
- Multimodal factuality for robotics and AR assistants
- Sector: robotics, manufacturing, logistics, consumer AR
- What to do: Combine visual grounding, world knowledge, and search to ensure task instructions are both observable and factual (e.g., part identification, safety signage).
- Tools/products: On-device multimodal judges; visual rubric construction from CAD/manuals; AR prompts that enforce grounded instructions.
- Assumptions/dependencies: High-quality perception; low-latency inference; reliable mapping of visual cues to essential facts.
- Consumer transparency and labeling standards for factual assistants
- Sector: policy, app marketplaces
- What to do: Develop standardized “Factuality Labels” for apps (e.g., FACTS sub-scores, grounding adherence, search reliance) to inform users.
- Tools/products: Public scorecards; store metadata; periodic independent evaluations.
- Assumptions/dependencies: Coordination with platforms; standardized disclosure formats; credible third-party testing.
- Multi-lingual and cross-domain expansion of FACTS
- Sector: global software, public sector, education
- What to do: Extend datasets and judges to additional languages and specialized domains; validate judge reliability cross-lingually.
- Tools/workflows: Language-specific rubrics; localized search tool adapters; calibration studies per language.
- Assumptions/dependencies: High-quality translations; locale-specific ground truth; judge robustness to linguistic diversity.
- Longitudinal model governance using FACTS-style metrics
- Sector: enterprise MLOps, risk management
- What to do: Monitor factuality performance over time; detect regressions after updates; implement risk thresholds for rollouts.
- Tools/workflows: Versioned dashboards tracking attempt rates, hedging, and sub-scores; rollout gates; incident response playbooks.
- Assumptions/dependencies: Consistent test sets; alignment between benchmark changes and internal KPIs; change-management practices.
- Research on hedging strategies vs. user satisfaction
- Sector: academia, UX research
- What to do: Study the trade-offs between raw accuracy, attempted accuracy, and hedging rates; design UX that properly sets expectations.
- Tools/workflows: Controlled experiments; mixed-methods studies; guidelines for confidence communication.
- Assumptions/dependencies: Access to representative user bases; agreement on success metrics beyond accuracy.
Notes on general assumptions and dependencies across applications:
- Judge reliability and bias: Many workflows depend on automated judges (often Gemini-2.5-Pro); organizations should validate judge agreement with human raters for their domain.
- Data sources: Parametric tasks assume pretraining exposure to Wikipedia; Search tasks depend on external API quality (Brave Search) and availability.
- Distribution fit: Scores may not fully represent performance on specialized or dynamic domains (e.g., breaking news, proprietary data).
- Overfitting controls: The suite’s private/public splits help, but internal evaluations should use additional held-out tasks.
- Cost/latency: Autorating, search calls, and multi-hop reasoning add compute and time; budgets and SLAs must account for this.
Collections
Sign up for free to add this paper to one or more collections.