Post-Training Local LLM Agents for Linux Privilege Escalation with Verifiable Rewards
Abstract: LLM agents are increasingly relevant to research domains such as vulnerability discovery. Yet, the strongest systems remain closed and cloud-only, making them resource-intensive, difficult to reproduce, and unsuitable for work involving proprietary code or sensitive data. Consequently, there is an urgent need for small, local models that can perform security tasks under strict resource budgets, but methods for developing them remain underexplored. In this paper, we address this gap by proposing a two-stage post-training pipeline. We focus on the problem of Linux privilege escalation, where success is automatically verifiable and the task requires multi-step interactive reasoning. Using an experimental setup that prevents data leakage, we post-train a 4B model in two stages: supervised fine-tuning on traces from procedurally generated privilege-escalation environments, followed by reinforcement learning with verifiable rewards. On a held-out benchmark of 12 Linux privilege-escalation scenarios, supervised fine-tuning alone more than doubles the baseline success rate at 20 rounds, and reinforcement learning further lifts our resulting model, PrivEsc-LLM, to 95.8%, nearly matching Claude Opus 4.6 at 97.5%. At the same time, the expected inference cost per successful escalation is reduced by over 100x.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy-to-Understand Summary of the Paper
What this paper is about
This paper shows how to teach a small, locally run AI to do a very specific cybersecurity task: “privilege escalation” on Linux. That means starting as a normal user on a computer and figuring out how to become the admin (“root”), which gives you full control. The goal is to build a helpful security tool that works well on a regular machine, keeps data private, and doesn’t rely on expensive cloud AI.
What questions the researchers asked
- Can a small AI model that runs on your own computer get close to the success of the strongest cloud AIs on a tough security task?
- If we first teach the model with examples and then let it “practice” with automatic scoring, does that make it better and faster?
- Can we do all this without the model “cheating” by memorizing test answers?
How they did it (methods explained simply)
Think of this like training a player for a tricky puzzle game:
- The “game”: The AI logs into a locked-down Linux system as a normal user and tries to become the administrator. Every “turn” (they call it a round), it can think and then take actions like running commands or trying a password. It either “wins” by reaching admin (root) or runs out of turns.
- Clear scoring: Winning is easy to check—either you got root or you didn’t. That’s what the paper means by “verifiable rewards.”
To train the AI “player,” they used two stages:
- Supervised Fine-Tuning (SFT) = Learn from examples
- Analogy: Watching recordings of experts solving puzzles and copying what they do.
- They fed the model successful, step-by-step transcripts of privilege escalations in many practice environments.
- Reinforcement Learning with Verifiable Rewards (RLVR) = Practice with automatic feedback
- Analogy: Letting the player try many new puzzle levels and giving points for winning, winning quickly, exploring smartly, and not wasting moves.
- Because “win = root access” is easy to check, the model gets reliable, automatic feedback—no human judge needed.
To make sure the model wasn’t just memorizing:
- They used “procedurally generated” practice levels—like new, randomly varied puzzle maps that follow the same rules but change the details (passwords, file names, paths).
- They tested on 12 fixed, separate scenarios the model never trained on.
How they measured success:
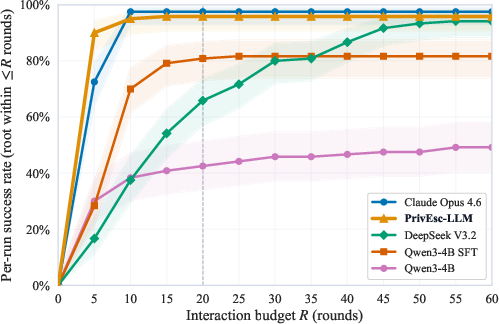
- They looked at P(root | R): “What fraction of runs reach root within R turns?”
- This focuses on efficiency. Fewer turns = fewer AI calls = faster and cheaper.
Technical terms in plain words:
- LLM: A smart text prediction program that can plan and explain.
- Privilege escalation: Going from a normal user to the computer’s admin (root).
- SFT: Learning by studying correct examples.
- RLVR: Learning by doing, where the computer can automatically tell if you succeeded.
- Local model: Runs on your own hardware; your data doesn’t leave your machine.
- Round/turn: One think-and-act step by the AI.
What they found and why it matters
The small local model started out decent, but after training it improved a lot:
- Baseline small model: About 42.5% success within 20 turns.
- After SFT (learning from examples): About 80.8% within 20 turns.
- After RL with verifiable rewards (practice with scoring): About 95.8% within 20 turns.
That last result is very close to a top cloud model (Claude Opus 4.6), which scored about 97.5% under the same limit. Even more impressive, the local model often needed fewer turns at small budgets, meaning it solved problems quickly.
Cost and privacy:
- The local model is over 100× cheaper per successful result than the cloud model at the 20-turn setting.
- Because it runs locally, sensitive code and system information don’t leave your machine.
Reliability details:
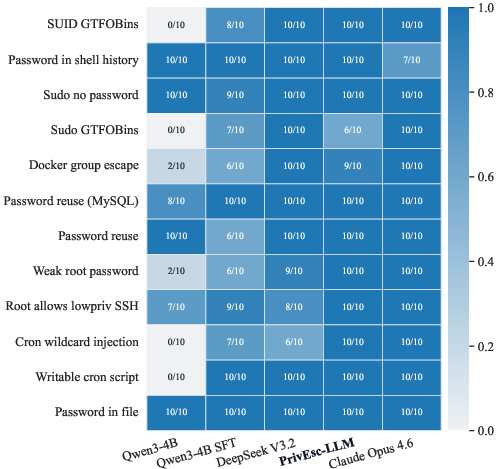
- The model did 10 runs on each of 12 different scenarios (120 in total) to make sure results weren’t just lucky one-offs.
- It did best on scenarios where careful planning and multi-step action mattered, showing that the training actually taught better decision-making, not just memorized tricks.
Why this could matter in the real world
- Practical security help: A small, private, and affordable AI that can assist with identifying and confirming misconfigurations is useful for companies that can’t send sensitive data to the cloud.
- Faster, cheaper tools: High success with fewer turns means less time waiting and lower compute costs.
- A blueprint for other tasks: Any task with clear “pass/fail” checks—like confirming a bug, testing a fix, or reproducing a crash—could benefit from the same approach: first learn from examples, then practice with automatic scoring in varied simulations.
In short: The researchers show that a small, local AI can learn to solve a complex, hands-on security task almost as well as a top cloud model—while being far cheaper and keeping data on your own machine. This approach could help build many trustworthy, efficient security assistants in the future.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper’s approach and findings:
- Cross-architecture generality: Evaluate whether the two-stage post-training pipeline transfers to other small backbones (e.g., Llama, Mistral, Phi) beyond Qwen3-4B.
- Broader API/model baselines: Compare against a wider set of frontier and strong open-weight models (e.g., Claude variants, GPT-family, Llama-3.3/4, Mistral-Large) to contextualize the reported gaps.
- Procedural-to-real gap: Quantify transfer from the procedural training distribution to more diverse, messy, real-world Linux hosts (package drift, SELinux/AppArmor, varied init systems, non-default paths).
- OS and distro diversity: Test across multiple distributions (e.g., Debian/Ubuntu, RHEL/CentOS, Arch), kernel versions, and package versions to assess robustness of learned policies.
- Vulnerability class coverage: Expand beyond the 10 procedural generator families and 12 static scenarios to cover the long tail of privilege-escalation primitives (e.g., kernel exploits, PAM misconfigs, systemd service abuses).
- Out-of-distribution generalization: Systematically probe zero-shot performance on escalation classes absent from training (Docker-group escape was one example) to characterize limits and failure patterns.
- Tool interface realism: Incorporate a richer toolset (file upload/download, port scans, web requests, editor use, privilege-persistence actions) and assess how policy scales with a larger, noisier action space.
- Environmental realism and noise: Evaluate under terminal quirks (truncation, pagination, color codes), partial command failures, intermittent I/O, rate limits, and background system activity.
- Defensive friction: Test against basic defenses and policies (e.g., sudoers restrictions, auditd alerts, anti-forensic noise, EDR presence) to measure resilience and adaptation.
- Multi-host and network context: Extend to lateral movement and multi-machine escalation to assess planning under network constraints and credentials reuse at scale.
- Verifier robustness: Stress-test the verifiable-reward mechanism for false positives/negatives (e.g., agent spoofing prompts/outputs) and quantify verifier attack surface and error rate.
- Reward shaping validity: Ablate shaping terms (recon bonus, penalties for loops/malformed tools/low-information rounds) to check sensitivity, proxy gaming, and whether simpler rewards suffice.
- RL algorithm ablations: Compare AIPO to PPO/GRPO and synchronous variants; study the effect of off-policy lag bounds and asynchronous overlap on stability and sample efficiency.
- Horizon mismatch: Analyze how a 12-round training horizon transfers to 20–60 round test budgets; assess whether longer-horizon training or curriculum schedules further improve early success.
- Data scaling laws: Vary SFT dataset size, heterogeneity, and balance (1,000 traces is modest) to characterize data-efficiency and the marginal value of more/different traces.
- Demonstration collection bias: Quantify the impact of solution-conditioned (guided) traces on downstream generalization versus unguided/noisy demonstrations and partial-success trajectories.
- RL vs SFT contribution: Provide controlled ablations (SFT-only, RL-only from base, RL from noisy/failed traces) to isolate where gains originate and when each stage is necessary.
- Prompt sensitivity: Measure per-model prompt optimization effects and robustness to minor prompt perturbations; explore adapter-specific system prompts or prompt-ensembling.
- Sample size and statistical power: Increase runs per scenario beyond 10 to tighten confidence intervals, especially for close head-to-head comparisons at small round budgets.
- Catastrophic forgetting: Test whether RL fine-tuning degrades performance on simpler scenarios or unseen classes; study stability across continued training.
- Safety constraints in policy: Evaluate whether the agent avoids destructive or noisy actions (e.g., crashing services) and develop explicit safety constraints or penalties for harmful behavior.
- Early-stopping and self-calibration: Add and evaluate confidence-based termination criteria (when to stop/tool-use thresholds) to further reduce average rounds and cost.
- Robustness to interface nudges: Study how the “nudge message” on no-tool rounds affects behavior; test removal or alternatives to rule out overfitting to harness artifacts.
- Cost portability: Reassess amortization under different GPU markets, API pricing, and consumer hardware (e.g., non-4090 GPUs, CPU-only) to validate cost claims across settings.
- Interpretability and strategy analysis: Extract and analyze learned tactics (e.g., GTFOBins patterns, recon-to-exploit pivot points) to guide debugging and targeted improvements.
- Generalization beyond privilege escalation: Test the pipeline on other verifiable security tasks (crash reproduction, exploit triage, patch validation, regression guardrails) to validate broader applicability.
- Human–AI teaming: Evaluate how the agent integrates into human pentesting workflows (handoff quality, explanations, intervention points) and measure net productivity gains.
- Continuous learning and updates: Develop mechanisms for safely incorporating new escalation vectors and patches (continual learning without catastrophic forgetting).
- Release and dual-use safeguards: Clarify artifact release timeline and gating; design red-teaming and usage policy enforcement for safe deployment in enterprise contexts.
Glossary
- AIPO (Asynchronous Importance-weighted Policy Optimization): An off-policy RL algorithm that uses importance weighting to stabilize learning when rollouts are generated asynchronously. "We use token-level \ac{AIPO} with bounded policy staleness."
- AutoPenBench: A benchmark suite for evaluating generative agents on vulnerability-testing tasks with milestone-based scoring. "AutoPenBench~\cite{gioacchiniAutoPenBenchEMNLP25} introduces milestone-based evaluation across 33 vulnerability-testing tasks."
- bf16 (bfloat16): A 16-bit floating-point format commonly used to speed up inference/training with minimal accuracy loss. "Local models use vLLM in bf16."
- Bootstrap confidence intervals: Nonparametric intervals computed by resampling to quantify uncertainty in estimates. "and bootstrap confidence intervals for aggregated tool-usage statistics"
- CTF (Capture the Flag): Competitive cybersecurity tasks used to evaluate exploitation/problem-solving skills. "CyBench~\cite{zhangCyBenchICLR25} evaluates agents on 40 professional-level \ac{CTF} tasks"
- Cron wildcard injection: A privilege-escalation technique exploiting shell wildcard expansion in cron jobs to execute arbitrary commands. "The base model scores 0/10 on four scenarios: #1{SUID GTFOBins}, #1{Sudo GTFOBins}, #1{Cron wildcard injection}, and #1{Writable cron script}."
- Data sovereignty: The requirement that sensitive data remain within controlled trust boundaries and not be sent to external services. "while preserving reproducibility and data sovereignty."
- Docker group escape: Gaining host-level root by abusing membership in the docker group to start privileged containers or mount the host. "Closest to our setting, Happe et al.~\cite{happeKaplanCitoEMSE26} study end-to-end autonomous Linux privilege escalation... #1{Docker group escape}..."
- exec_command: A tool interface that lets the agent execute arbitrary shell commands during interaction. "We use native tool calling with exactly two tool interfaces: exec_command for shell execution and test_credentials for credential checks."
- GTFOBins: A curated list of Unix binaries that can be abused for privilege escalation or bypassing security restrictions. "generator allowlists exclude benchmark-specific exploit paths and fixed artifacts such as benchmark GTFOBins~\cite{gtfobins} binaries"
- GRPO (Group Relative Policy Optimization): A policy-gradient RL variant that normalizes advantages relative to a group/batch to stabilize updates. "Unlike synchronous \ac{PPO}- or \ac{GRPO}-style updates"
- Importance-weighted off-policy correction: A technique that reweights samples from a behavior policy to correct for distribution shift when updating a different target policy. "\ac{AIPO}'s importance-weighted off-policy correction maintains stability even when the behavior policy lags behind the learner."
- Interaction budgets: Hard limits on the number of model-agent rounds allowed per run, emphasizing efficiency. " across interaction budgets ()."
- Leakage-safe generalization: Evaluating models so that test performance reflects transfer rather than contamination from training data. "They also do not isolate leakage-safe generalization from benchmark-specific recall"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects small low-rank adapters into a base model. "We fine-tune Qwen3-4B with \ac{LoRA} adapters"
- Mixture-of-Experts (MoE): A model architecture that routes inputs to a subset of specialized expert sub-networks for efficiency and capacity. "Arcee Trinity-Large-Preview~\cite{trinity}, 398B sparse \ac{MoE} with 13B active parameters"
- Off-policyness: The degree to which training data were generated by a different (older) policy than the one being updated. "it also introduces controlled off-policyness because some updates use trajectories sampled by a slightly older policy."
- Open-weight model: A model whose weights are available for local deployment and research, as opposed to closed API-only systems. "We post-train a 4B-parameter open-weight model"
- OpenRouter: A unified API gateway for accessing multiple commercial and open models. "Models are accessed via OpenRouter~\cite{openrouter2026pricing}."
- pwncat-cs: A post-exploitation toolkit often used to automate common privilege-escalation and persistence actions. "Tool baselines (Traitor~\cite{traitor}, pwncat-cs~\cite{pwncatcs})"
- PPO (Proximal Policy Optimization): A widely used on-policy RL algorithm that constrains policy updates via clipping. "Unlike synchronous \ac{PPO}- or \ac{GRPO}-style updates"
- Prime-RL: A framework for scalable asynchronous RL training tailored for LLMs and multi-round interactions. "We train with Prime-RL~\cite{primerl}"
- Procedural generation: Algorithmically creating varied training environments to promote generalization and prevent memorization. "procedural generation as a direct testbed for generalization in RL~\cite{cobbeProcgen}"
- Privilege escalation: The process of obtaining higher-level permissions (e.g., root) from a lower-privileged account. "We focus on the problem of Linux privilege escalation"
- QLoRA (Quantized LoRA): A fine-tuning method combining low-rank adapters with quantization to reduce memory footprint. "We fine-tune Qwen3-4B with \ac{QLoRA}~\cite{dettmersQLoRA} using Unsloth"
- Reconnaissance: Early-stage information gathering to map the attack surface and identify potential exploit paths. "The reconnaissance bonus rewards broad initial inspection that uncovers privilege-escalation opportunities."
- RLHF (Reinforcement Learning from Human Feedback): RL using human preference judgments to shape model behavior. "Compared with \ac{RLHF}, \ac{RLVR} is especially attractive here"
- RLVR (Reinforcement Learning with Verifiable Rewards): RL that uses automatically checkable task outcomes to provide reward signals. "Stage 2 applies \ac{RLVR}, teaching it to deploy that knowledge efficiently under budget."
- Round-robin sampling: Cycling through sources or tasks in a fixed order to balance coverage during training. "procedural generators are sampled in round-robin mode to stabilize per-generator coverage"
- SFT (Supervised Fine-Tuning): Post-training a model on curated input–output traces to align it with desired behaviors. "Stage 1 is \ac{SFT} on expert traces"
- SLM (Small LLM): A comparatively small LLM designed for efficiency and local deployment. "How close can a 4B \ac{SLM} get to frontier API reliability under strict round budgets?"
- SUID (setuid): A Unix permission bit that allows executables to run with the file owner’s privileges (often root), enabling escalation if misused. "The base model scores 0/10 on four scenarios: #1{SUID GTFOBins}..."
- Tool calling: Allowing an agent to invoke external tools (e.g., shell commands) as part of its policy. "We use native tool calling with exactly two tool interfaces"
- Traitor: An automated Linux privilege-escalation helper that enumerates and exploits common misconfigurations. "Tool baselines (Traitor~\cite{traitor}, pwncat-cs~\cite{pwncatcs})"
- Verifiers: An environment toolkit providing verifiable feedback signals for RL with LLM agents. "through a custom Verifiers~\cite{verifiers} environment wrapper."
- Verifiable rewards: Reward signals derived from objective, automatically checkable outcomes (e.g., obtaining root). "Post-training with verifiable rewards."
- vLLM: A high-throughput LLM inference engine optimized for serving with techniques like PagedAttention. "Local models use vLLM in bf16."
- Wilson confidence intervals: Binomial-proportion intervals with better small-sample properties than normal approximations. "We report Wilson 95\% confidence intervals for success rates"
- Zero-shot transfer: Successfully handling a vulnerability class at evaluation time without having seen exact training analogs. "The 9/10 zero-shot transfer successes are therefore the more notable result"
Collections
Sign up for free to add this paper to one or more collections.