RedSage: A Cybersecurity Generalist LLM
Abstract: Cybersecurity operations demand assistant LLMs that support diverse workflows without exposing sensitive data. Existing solutions either rely on proprietary APIs with privacy risks or on open models lacking domain adaptation. To bridge this gap, we curate 11.8B tokens of cybersecurity-focused continual pretraining data via large-scale web filtering and manual collection of high-quality resources, spanning 28.6K documents across frameworks, offensive techniques, and security tools. Building on this, we design an agentic augmentation pipeline that simulates expert workflows to generate 266K multi-turn cybersecurity samples for supervised fine-tuning. Combined with general open-source LLM data, these resources enable the training of RedSage, an open-source, locally deployable cybersecurity assistant with domain-aware pretraining and post-training. To rigorously evaluate the models, we introduce RedSage-Bench, a benchmark with 30K multiple-choice and 240 open-ended Q&A items covering cybersecurity knowledge, skills, and tool expertise. RedSage is further evaluated on established cybersecurity benchmarks (e.g., CTI-Bench, CyberMetric, SECURE) and general LLM benchmarks to assess broader generalization. At the 8B scale, RedSage achieves consistently better results, surpassing the baseline models by up to +5.59 points on cybersecurity benchmarks and +5.05 points on Open LLM Leaderboard tasks. These findings demonstrate that domain-aware agentic augmentation and pre/post-training can not only enhance cybersecurity-specific expertise but also help to improve general reasoning and instruction-following. All models, datasets, and code are publicly available.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces RedSage, a special-purpose AI assistant that understands cybersecurity. Think of it like a smart study buddy trained to help with tasks such as spotting security problems, analyzing threats, and using security tools—without sending your data to the cloud. The team built RedSage, created a big training set focused on cybersecurity, and designed a new “exam” (benchmark) to fairly test how well such AIs really know and can do cybersecurity work.
What questions were the researchers trying to answer?
They focused on five simple questions:
- Can we build a strong, privacy-friendly cybersecurity assistant that runs locally (on your own computers)?
- If we train an AI on lots of high-quality cybersecurity material, will it really get better at real tasks (not just memorizing facts)?
- Can we make realistic practice conversations (like expert–assistant chats) to teach the AI good workflows?
- How do we test not only what the AI knows, but also how well it uses tools (like command line and Kali Linux) and explains its reasoning?
- Does teaching an AI cybersecurity also improve its general reasoning and instruction-following on everyday tasks?
How did they do it?
1) Collecting and cleaning the right “textbooks”
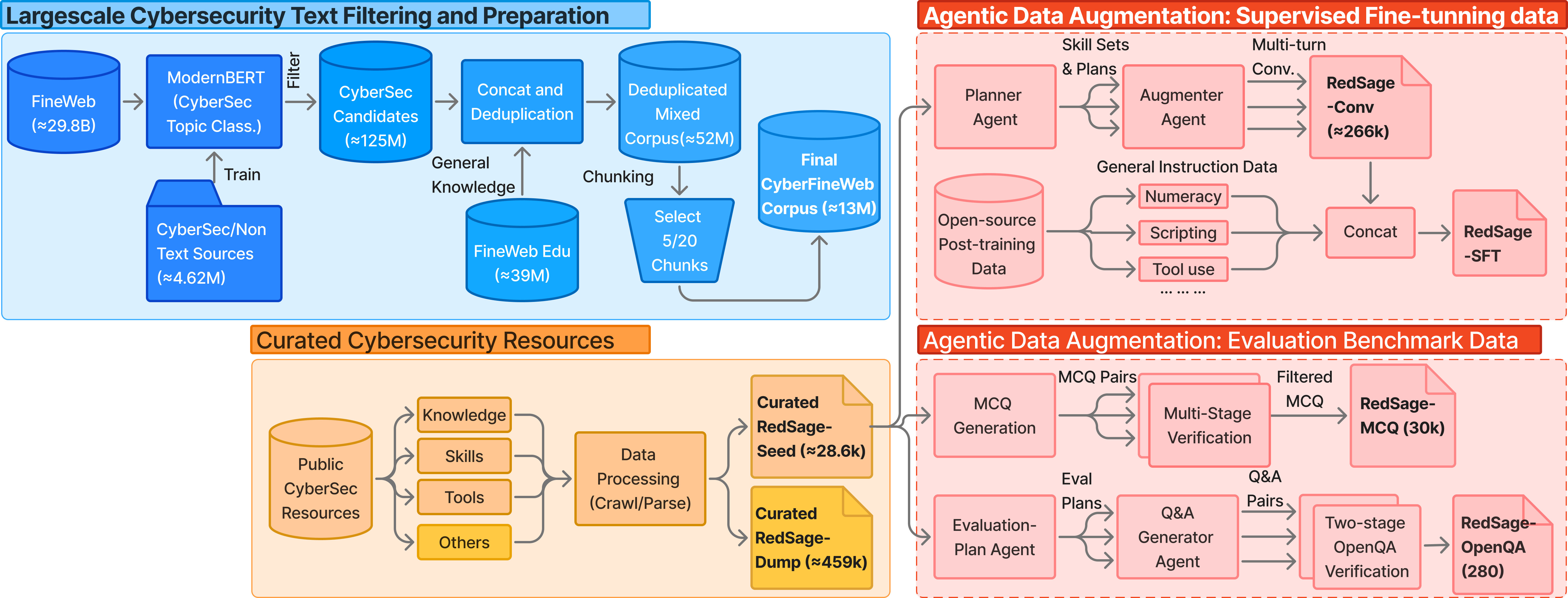
- They started with a giant pile of internet text and filtered it to keep cybersecurity-related content. This formed a big “library” called CyberFineWeb (about 11.8 billion token-sized chunks of text—think of tokens as pieces of words).
- To make sure the AI didn’t forget general knowledge, they mixed in some regular educational text.
- They also handpicked trusted resources (like MITRE ATT&CK, OWASP, Linux manuals, tool cheat-sheets, and ethical hacking tutorials) into a high-quality “seed” set called RedSage-Seed (about 28,600 documents).
Analogy: They built a carefully curated bookshelf with both general textbooks and specialized cybersecurity books.
2) Teaching through practice conversations
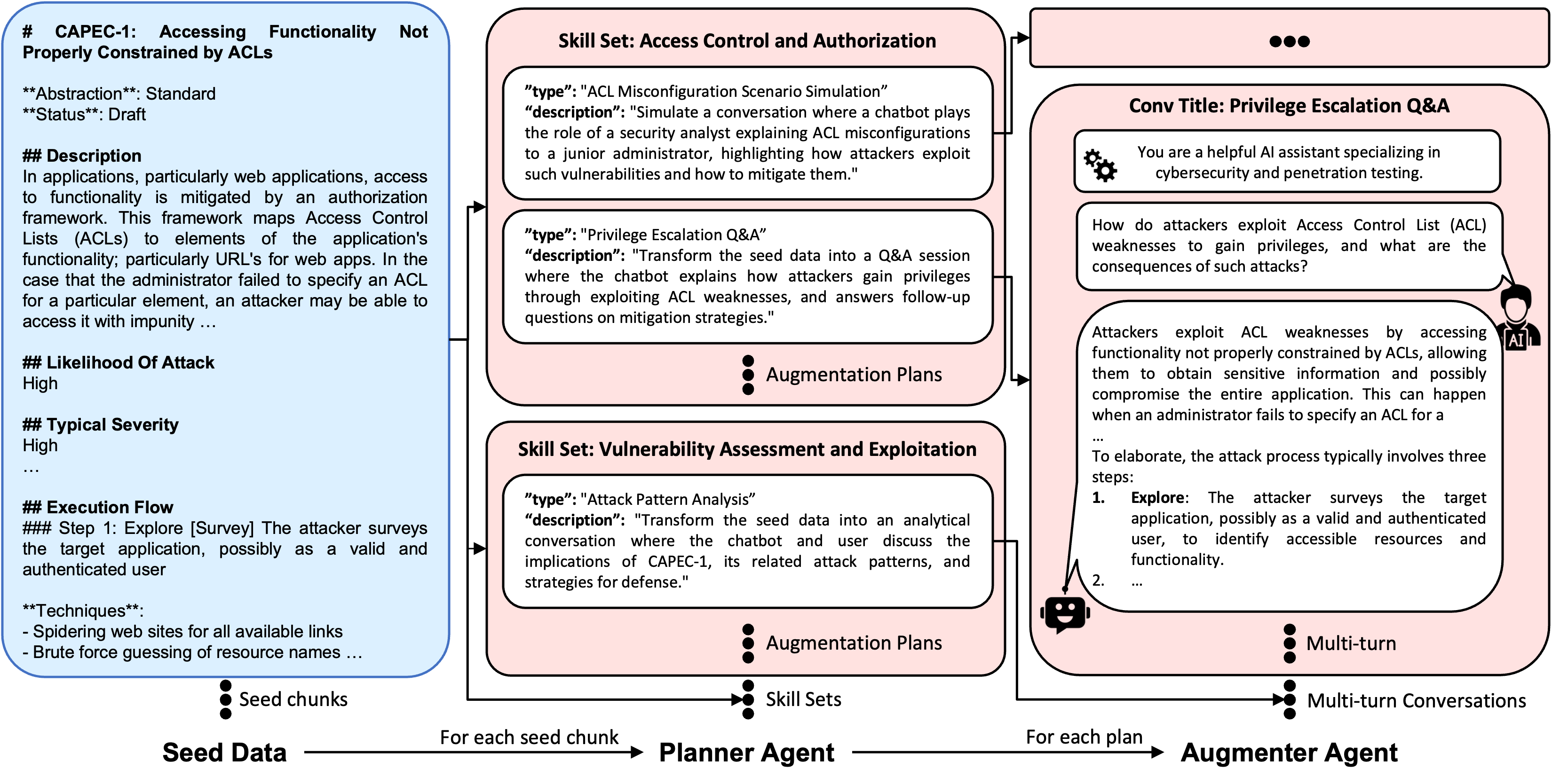
- The team used an “agentic augmentation” pipeline—basically, two helper programs:
- A Planner Agent breaks each seed document into skills (e.g., “how to analyze a vulnerability”).
- An Augmenter Agent turns those skills into realistic multi-turn dialogues, like practice conversations between a security expert and an assistant.
- This generated about 266,000 practice conversations covering knowledge, hands-on skills, and tool use.
Analogy: It’s like hiring a tutor to turn your textbooks into practice Q&A sessions and role-plays so you learn by doing.
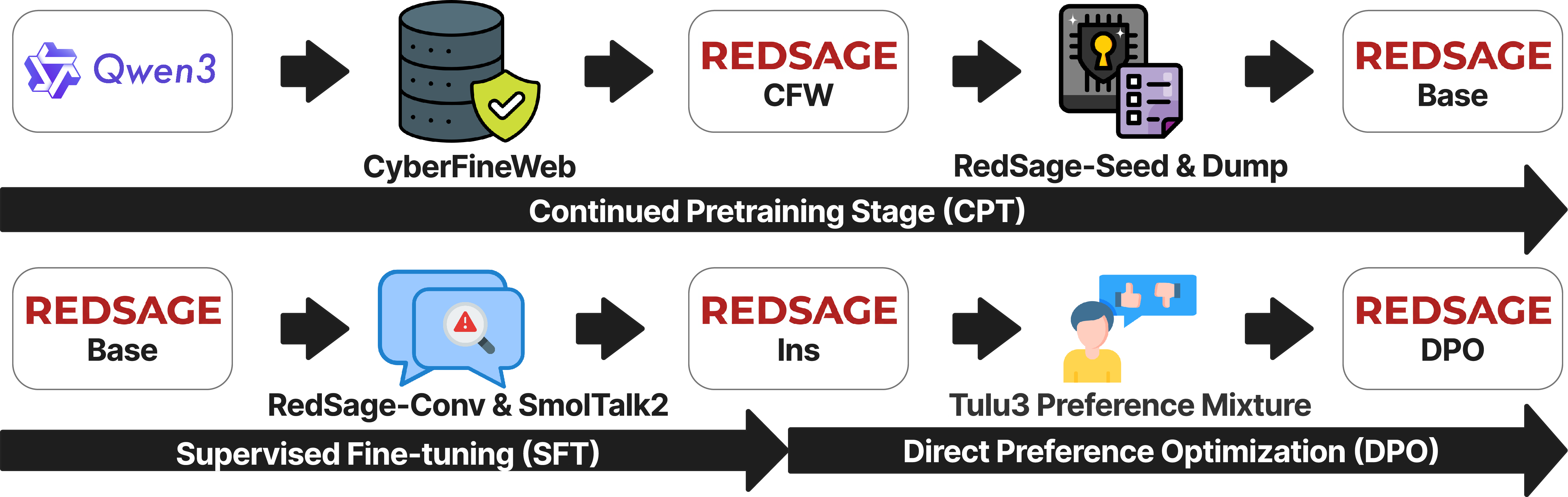
3) Training the model in stages
- Stage A (Continual pretraining): Start from a strong open model and “read” the cybersecurity library to build domain knowledge.
- Stage B (Supervised fine-tuning): Practice on those multi-turn conversations to learn how to help people step by step.
- Stage C (Preference alignment): Fine-tune it to answer more helpfully and clearly using a method called DPO (Direct Preference Optimization).
Analogy: First, the student studies the books, then practices with mock conversations, and finally learns how to give clearer, more helpful answers.
4) Building a fair test: RedSage-Bench
- They created a new benchmark with:
- 30,000 multiple-choice questions (to test core knowledge across knowledge, hands-on skills, and tools).
- 240 open-ended questions (to test how well the AI explains and reasons in longer answers).
- They used careful quality checks (including another strong AI as a “judge” and human reviews) to make sure the questions are fair and not duplicated from training.
Analogy: They wrote a thorough exam that checks not just memorization but also problem-solving and tool-handling.
What did they find?
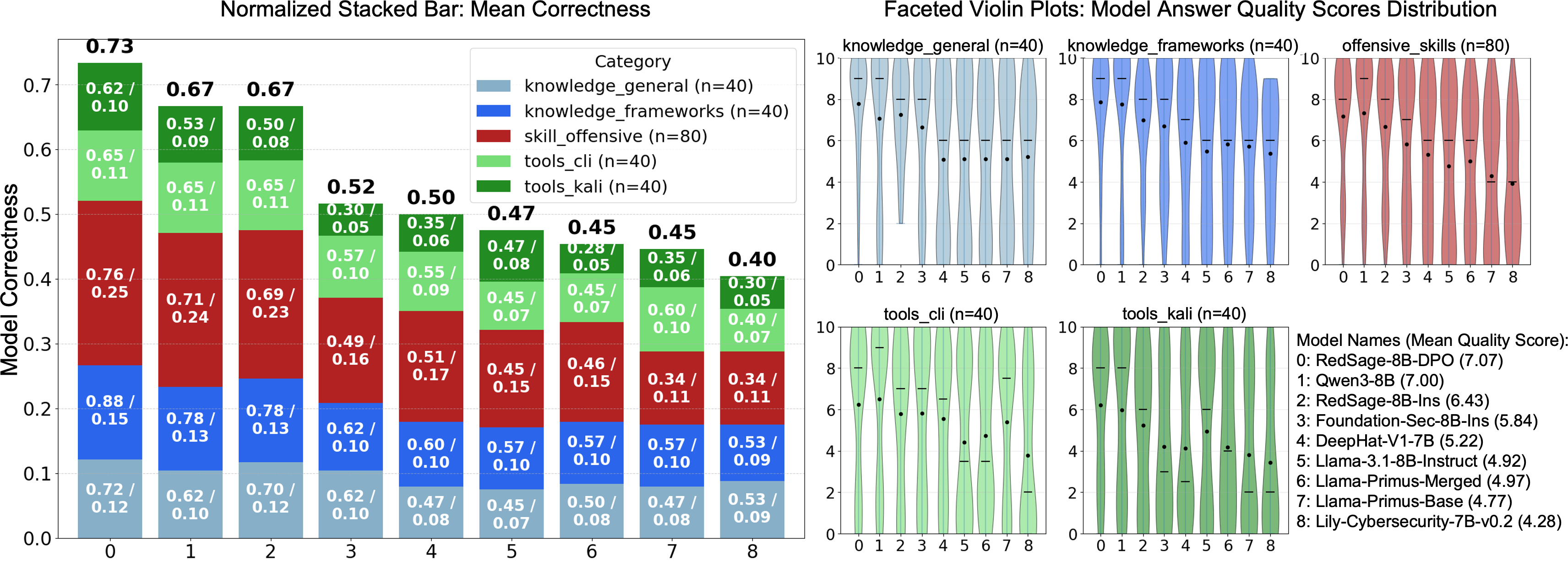
- RedSage (8B parameters) beat other similar-sized models on many cybersecurity benchmarks by up to about 5.6 percentage points.
- It also improved on general AI tests (like math word problems and multiple-choice reasoning) by up to about 5.0 points—showing that focused training in cybersecurity can also sharpen overall reasoning and instruction-following.
- RedSage performed especially well on:
- Knowledge of frameworks and concepts,
- Practical offensive/security skills,
- Tool use (command line and Kali Linux).
- Because it’s 8B in size and open-source, RedSage can run locally, which helps protect sensitive information (no need to send data to a third-party API).
Why this matters: There’s a big shortage of cybersecurity experts worldwide. A reliable assistant that knows the tools and can explain steps clearly can help students and professionals learn faster and work more efficiently—without risking private data.
What’s the impact?
- For learners and teams: RedSage can act like a coach—explaining concepts, suggesting commands, and guiding investigations. It’s also a strong study partner thanks to the new benchmark and practice dialogues.
- For organizations: RedSage’s local, open-source design supports on-premise use, reducing privacy risks.
- For researchers: The team released the model, datasets, and code, plus a better benchmark that tests knowledge, hands-on skills, and tool use. This openness makes it easier to reproduce results and build even better systems.
Final thoughts and limitations
- The authors stress responsible use: cybersecurity knowledge can be misused, so it should be applied ethically.
- Some training material comes from public web sources; the team took steps to clean, filter, and respect licenses, and they won’t redistribute copyrighted content without permission.
- While the data and checks are extensive, AI-generated content can still carry mistakes or biases. The benchmark and open releases are meant to help the community spot and fix these over time.
In short: RedSage is like a well-trained, practical cybersecurity study buddy that can run on your own computer. It learns from trusted sources, practices realistic security tasks, and is tested with a thorough exam. It not only gets better at cybersecurity but also becomes a clearer, more helpful assistant in general.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased so future researchers can act on it:
- Quantify the accuracy of the CyberFineWeb filter: report precision/recall on a labeled cybersecurity corpus, error analysis of false positives/negatives, and sensitivity to threshold choices.
- Assess robustness of the 30% general-knowledge replay: ablate different replay ratios, alternative sampling strategies (e.g., dynamic replay), and their impact on domain vs. general benchmarks and catastrophic forgetting.
- Evaluate the effect of early stopping at 5/20 chunks: establish scaling curves for continued pretraining tokens vs. performance to determine whether more CPT would yield further gains or diminishing returns.
- Provide stronger decontamination guarantees: go beyond a 0.9 semantic similarity cutoff by adding lexical, embedding, and paraphrase-aware filters and releasing overlap statistics between training and all test sets (including per-split).
- Increase human validation of benchmarks: the 30K MCQs rely on LLM verification with only random audits; conduct large-scale human review, report inter-annotator agreement, calibrate item difficulty, and publish a vetted subset.
- Mitigate LLM-as-judge bias: compare multiple judges (different models/families), use pairwise human evaluation, and examine whether training or teacher/verifier choices bias scoring on open-ended QA.
- Validate ground-truth correctness in augmented dialogues: add expert review or tool-assisted checks (e.g., command linters, static analysis) to ensure generated steps, commands, and explanations are accurate and safe.
- Move beyond static “tool proficiency” questions: evaluate real command execution in sandboxed environments (e.g., containers/VMs) with pass/fail based on actual outputs, including error handling and flag correctness.
- Test multi-turn dialogue capabilities: design benchmarks for context retention, clarification, planning across turns, and memory over longer sessions, reflecting realistic analyst–assistant workflows.
- Integrate and evaluate retrieval at inference: despite “Retrieval-Enhanced” in the name, no RAG experiments are reported; add CTI retrieval (live CVEs, advisories) and measure closed-book vs. open-book gains and failure modes.
- Temporal robustness and staleness: create time-split evaluations (e.g., CVEs from post-training periods) to quantify degradation on fast-evolving threats and evaluate strategies for continuous updates.
- Safety and misuse resistance: systematically test refusal of harmful requests, exploit generation, prompt injection resilience, and dual-use risk using red-teaming frameworks beyond CyberSecEval coverage.
- Memorization and privacy audits: run membership inference tests, PII leakage probes, and verbatim memorization checks to validate claims of minimal sensitive content and safe local deployment.
- Multilingual generalization: assess performance on non-English cybersecurity tasks (e.g., Chinese SecBench items), and explore multilingual CPT/SFT to support global analyst communities.
- Fairness and comparability of evaluation settings: harmonize 0-shot vs. 5-shot, decoding parameters, and prompt templates across baselines; report sensitivity analyses to ensure apples-to-apples comparisons.
- Deeper error analysis: provide per-subdomain/tool breakdowns (e.g., per-Kali tool), common failure patterns (flag misuse, outdated procedures), and actionable insights for targeted data augmentation.
- Execution-based verification of commands: augment benchmark generation with automated execution harnesses to validate that CLI examples and remediation steps actually work as stated.
- Expand beyond MCQs/open-QA to realistic artifacts: include tasks on log triage (SIEM), PCAP analysis, malware snippets, and reverse engineering to reflect operational workflows not captured by QA formats.
- Preference alignment side effects: DPO slightly degrades some MCQ scores; study domain-specific preference data, alternative alignment methods (e.g., IPO, CALM, partial freezing), and curriculum scheduling to preserve domain accuracy.
- Ablate dataset components: quantify the marginal utility of each corpus slice (CyberFineWeb vs. Seed vs. SmolTalk2 vs. RedSage-Conv) and each RedSage-Conv category (knowledge/skills/tools) on different benchmarks.
- Scaling behavior: beyond a brief 32B QLoRA result, characterize model- and data-scaling laws (8B→32B→70B) to guide compute-optimal data budgets for cybersecurity CPT/SFT.
- Contamination via shared seeds: although synthetically different, both SFT and benchmarks originate from RedSage-Seed; add strict split-by-source/time and publish overlap diagnostics to rule out subtle leakage.
- Long-context and document-grounded tasks: evaluate multi-document synthesis (frameworks, advisories), long-context recall, and citation faithfulness for auditability in security reporting.
- Instruction-following vs. domain trade-offs: systematically test inference-time techniques (CoT, self-consistency, few-shot) and their interaction with domain accuracy and safety compliance.
- Reproducibility under data licensing: some curated sources are copyrighted and won’t be redistributed; provide reconstruction scripts, URLs, hashes, and filtering configs so others can rebuild equivalent corpora.
- Cost and efficiency transparency: report token-level generation/verification costs for augmentation and benchmarks, compute budgets for CPT/SFT, and provide guidance for lower-resource replications.
- Robustness to adversarial prompting: evaluate jailbreaks, indirect prompt injection, and context poisoning specific to security tasks (e.g., deceptive threat intel) and test mitigation strategies (parsers, sanitizers).
- Integration with tool APIs: explore function-calling to security tools (e.g., Nmap, YARA, Sigma rules), chain-of-tools execution, and benchmarks that score the end-to-end tool-mediated outcomes.
- Calibration and uncertainty: measure selective prediction (abstention), confidence calibration, and uncertainty-aware responses to reduce overconfident but unsafe recommendations.
- Real-world deployment studies: pilot tests in SOC-like settings to evaluate productivity, error rates, human factors (trust, oversight), and how the model interacts with existing triage and IR workflows.
Practical Applications
Below is an overview of practical, real-world applications enabled by RedSage’s findings, methods, and artifacts (the domain-aware CPT+SFT training recipe, the agentic augmentation pipeline, the 8B on‑prem model, and RedSage‑Bench). Items are grouped by deployment horizon and mapped to sectors, with suggested tools/products/workflows and key assumptions or dependencies noted.
Immediate Applications
The following can be deployed now with modest integration effort, leveraging the open 8B on-prem model, datasets, and benchmark.
Industry
- Cybersecurity copilot for SOCs and MSSPs (software/security; finance; healthcare; energy; government)
- What it does: Privacy-preserving, on-prem assistant to triage alerts, explain detections, propose next steps, and draft tickets. Generates SIEM search queries (e.g., KQL/SPL), suggests CVSS, maps CVE→CWE, and aligns findings to ATT&CK.
- Tools/products/workflows: “RedSage Copilot” with SIEM/SOAR connectors (Splunk, Sentinel, QRadar, Cortex XSOAR), EDR consoles, and ticketing (ServiceNow, Jira).
- Assumptions/dependencies: Safe-ops guardrails; read-only integrations initially; retrieval over internal KBs; fresh threat intel via RAG; human-in-the-loop approvals.
- Incident response triage and reporting (software/security; regulated industries)
- What it does: Triage playbooks, containment checklists, timeline reconstruction prompts, and executive/technical report drafting using IR templates and frameworks.
- Tools/products/workflows: IR “report-writer” plugin; playbook generator integrated with SOAR runbooks.
- Assumptions/dependencies: Clear role/format guidelines, redaction policies, and audit logging for generated artifacts.
- Vulnerability management assistant (software; IT ops)
- What it does: Prioritizes scanner findings; maps to CWE/OWASP; drafts remediation steps; suggests compensating controls; recommends patch windows.
- Tools/products/workflows: Connectors to Nessus/Qualys/Rapid7; ticket auto-drafting; control mapping to CIS/NIST.
- Assumptions/dependencies: Accurate asset context; up-to-date vulnerability feeds; risk appetite thresholds encoded.
- Tool-use tutor for CLI/Linux/Kali (IT ops; blue/purple teams)
- What it does: Explains and composes safe commands; interprets man pages; recommends switches; validates command effects before execution.
- Tools/products/workflows: “Explain this command” sidebar; sandboxed terminal coach; lab-mode-only Kali helper.
- Assumptions/dependencies: Strict execution sandboxing; read-only suggestion mode in production; safe command filters.
- Secure development advisor (software engineering; DevSecOps)
- What it does: Explains vulnerability classes (CWE/OWASP), proposes safer patterns, writes security-focused PR comments, maps issues to standards.
- Tools/products/workflows: IDE/PR bot plugin; CI gate for remediation notes and control mapping.
- Assumptions/dependencies: Not a code generator for exploits; policies enforcing defensive-only guidance; license compliance.
- Cyber threat intelligence (CTI) analyst copilot (security operations; threat intel teams)
- What it does: Summarizes reports, correlates IOCs, drafts attribution rationales, generates ATT&CK technique mappings and hypotheses.
- Tools/products/workflows: OpenCTI/MISP integration; IOC enrichment prompts; “intel brief” generator.
- Assumptions/dependencies: Up-to-date CTI feeds; provenance tracking for generated analyses; human review.
- GRC mapping and audit prep (compliance; risk; internal audit)
- What it does: Maps controls across NIST CSF/800-53, ISO 27001, CIS; drafts evidence requests and audit checklists; summarizes policy gaps.
- Tools/products/workflows: Control mapping assistant; evidence checklist generator.
- Assumptions/dependencies: Organization-specific control catalogues; legal review; change-management records.
- Awareness content and lab generation (L&D; training vendors)
- What it does: Creates quizzes, mini-labs, and rationales drawn from curated seed and augmented dialogues.
- Tools/products/workflows: Training content builder; LMS import.
- Assumptions/dependencies: Content validation to avoid dual-use; versioning and difficulty calibration.
Academia and Education
- Courseware, labs, and CTF prep
- What it does: Generates step-by-step exercises, grading rubrics, and explanations aligned to ATT&CK/CWE/OWASP; supports CLI/Kali practice.
- Tools/products/workflows: Cyber range content generator; autograding using RedSage’s LLM-as-judge rubric with human oversight.
- Assumptions/dependencies: Academic policies on AI-generated content; dual-use guardrails; dataset citation.
- Benchmarking and reproducible research
- What it does: Uses RedSage-Bench to compare models’ knowledge/skills/tool proficiency; reproduces the agentic augmentation pipeline for new studies.
- Tools/products/workflows: “Benchmark-as-a-Service” harness with lighteval; shared leaderboards.
- Assumptions/dependencies: Standardized evaluation protocols; decontamination checks; dataset licensing.
Policy and Governance
- Vendor and capability evaluation for procurement
- What it does: Uses RedSage-Bench to score candidate cyber-LLMs on knowledge/skills/tool-use; weights results by mission needs.
- Tools/products/workflows: Procurement scorecards; capability maturity metrics; model cards referencing benchmark slices.
- Assumptions/dependencies: Transparent, reproducible runs; acceptance thresholds; periodic re-testing.
- Safety and misuse risk audits
- What it does: Applies tool/skill categories and CyberSecEval-style tasks to audit harmful capability leakage; validates safety filters.
- Tools/products/workflows: Red-teaming playbooks; safety test suites integrated into release gates.
- Assumptions/dependencies: Clear unacceptable-use policies; human oversight; audit trails.
- Privacy-preserving adoption
- What it does: On-prem deployment to satisfy GDPR/HIPAA/sectoral rules; model confined to internal networks and data.
- Tools/products/workflows: Air-gapped inference; retrieval restricted to sanctioned corpora; security monitoring of model usage.
- Assumptions/dependencies: Sizing for 8B inference (consumer-grade GPU/edge server); access controls and logging.
Daily Life and SMBs
- Personal cyber hygiene coach
- What it does: Guides password managers/MFA, phishing recognition, device hardening, backup strategies; explains steps in plain language or CLI.
- Tools/products/workflows: “Home security checklist” generator; router hardening instructions; safe email triage tips.
- Assumptions/dependencies: Device diversity; avoids exploit instructions; keeps to defensive guidance.
- Small business security advisor
- What it does: Generates baseline security policies, asset inventory templates, and incident response plans for SMB contexts.
- Tools/products/workflows: “Security starter kit” pack; quarterly review prompts.
- Assumptions/dependencies: Local regulations; customization to business size and risk; human validation.
- Home lab tutor
- What it does: Helps set up a safe lab, explains firewall rules, and Linux hardening using tool-aware prompts.
- Tools/products/workflows: Lab-mode tutor with non-production disclaimers; command dry-runs.
- Assumptions/dependencies: Strict separation from production networks; safety reminders.
Long-Term Applications
These require additional research, scaling, integrations, or governance frameworks.
Industry
- Semi-autonomous SecOps agents with approval gates
- What it could do: Plan→simulate→recommend→execute constrained actions in SOAR/EDR with tiered approvals; closed-loop remediation for well-defined incidents.
- Tools/products/workflows: “Action planner” integrating DPO-aligned dialog + tool APIs; sandboxed trials; policy-driven guardrails.
- Assumptions/dependencies: Strong tool-use verification; policy-as-code; continuous safety audits and rollback mechanisms.
- Live tool-use and data-plane integration
- What it could do: Query SIEM/EDR, parse pcap/logs, orchestrate sandbox detonations, and synthesize findings into tickets automatically.
- Tools/products/workflows: Toolformer-style adapters; function-calling to vendor APIs; structured output contracts.
- Assumptions/dependencies: Reliability under distribution shift; observability and rate limiting; vendor cooperation.
- Federated continual learning on-prem
- What it could do: Privacy-preserving updates from local SOC data (e.g., FL/LoRA) to adapt to organization-specific threats.
- Tools/products/workflows: Federated fine-tuning pipelines; drift detection; scheduled evaluation on RedSage-Bench deltas.
- Assumptions/dependencies: Robust decontamination; compliance approvals; strong data governance.
- Sector-specific safety-critical assistants (ICS/OT, healthcare devices, energy)
- What it could do: Provide verified, tool-aware guidance for ICS/OT incidents and medical/energy device security with strict execution constraints.
- Tools/products/workflows: Domain-specialized models co-trained on ICS benchmarks (e.g., SECURE) and vendor docs; digital twins for simulation.
- Assumptions/dependencies: High assurance, temporal correctness, and certification; extensive testbeds; fail-safe designs.
- Secure coding co-pilot with verified remediation
- What it could do: Not just advice, but provably safe refactor proposals with static/dynamic checks and policy mapping to compliance.
- Tools/products/workflows: CI-in-the-loop verifiers, SARIF-based feedback, formal checks for critical code paths.
- Assumptions/dependencies: Advances in program verification; scalable proof tooling; curated secure code corpora.
Academia and Education
- Generative cyber ranges and synthetic threat curricula
- What it could do: Auto-generate evolving scenarios tied to current TTPs; adaptive difficulty; open-ended assessment with calibrated LLM judges.
- Tools/products/workflows: Scenario compilers from augmentation plans; benchmark-aligned assessments; analytics dashboards.
- Assumptions/dependencies: Reliable difficulty estimation; secure lab isolation; standardized rubrics.
- Domain transfer of the pipeline to other specialties
- What it could do: Apply RedSage’s data curation + agentic augmentation to domains like biosecurity, safety engineering, or legal compliance.
- Tools/products/workflows: Reusable “augmentation playbooks”; cross-domain seed corpora; domain-specific benchmarks.
- Assumptions/dependencies: Expert-curated seeds; alignment to domain ethics and safety constraints.
Policy and Governance
- Standardized certification for cybersecurity LLMs
- What it could do: Regulators adopt benchmark suites (e.g., RedSage-Bench dimensions) for certification tiers and periodic re-accreditation.
- Tools/products/workflows: Public test sets + private sequestered items; reporting formats; conformance tests for tool-use safety.
- Assumptions/dependencies: Multi-stakeholder governance; test integrity; evolution with threat landscape.
- Shared-defense, multi-agent coalitions
- What it could do: Inter-org agents share anonymized signals and augment CTI collaboratively with privacy-preserving analytics.
- Tools/products/workflows: Federated intel-sharing protocols; standardized STIX/TAXII extensions for AI annotations.
- Assumptions/dependencies: Legal frameworks for data sharing; strong anonymization; trust fabric and auditing.
Daily Life and SMBs
- Household “digital safety steward”
- What it could do: Continuously advises on IoT posture, router firmware, child safety settings, and backup health; detects risky settings and suggests fixes.
- Tools/products/workflows: Local gateway app; vendor-neutral device profiles; periodic health checks with explainable suggestions.
- Assumptions/dependencies: Broad device coverage; manufacturer cooperation; local inference footprint.
- SMB managed security automation
- What it could do: Near-autonomous execution of baseline controls and routine checks under MSP supervision, with cost-effective protection.
- Tools/products/workflows: MSP console integrating LLM-driven audits, ticketing, and monthly compliance snapshots.
- Assumptions/dependencies: Clear task boundaries; liability frameworks; safe defaults and escalation paths.
Notes on feasibility across applications:
- Safety/ethics: Dual-use risks require strong guardrails, content filters, role-based policies, and human oversight.
- Freshness: Many tasks depend on up-to-date threat intelligence; plan for RAG or periodic re-tuning.
- Integration: Value scales with connectors to SIEM/SOAR/EDR, scanners, CTI platforms, and ticketing systems.
- Evaluation: Use RedSage-Bench plus domain-specific holdouts and human audits; decontamination to avoid leakage.
- Compute/licensing: 8B model supports consumer-grade GPUs, but plan for VRAM, inference latency, and license alignment.
- Localization: Multilingual and sector-specific variants may require additional curated seeds and augmentation passes.
Glossary
- AdamW optimizer: A variant of Adam that decouples weight decay from the gradient update to improve generalization. "using DeepSpeed ZeRO Stage~3, the AdamW optimizer, and a fixed learning rate of with linear warmup."
- Agentic augmentation: An LLM-driven process that plans and generates realistic, multi-turn training data by simulating agent workflows. "we design an agentic augmentation pipeline that simulates expert workflows to generate 266K multi-turn cybersecurity samples for supervised fine-tuning."
- Augmenter Agent: The component that instantiates planned augmentations into grounded, role-based dialogues. "The Augmenter Agent then instantiates each plan into realistic, role-based multi-turn dialogues grounded in the seed data."
- Axolotl framework: A training framework for fine-tuning and instruction-tuning LLMs. "We build RedSage using the Axolotl framework~\citep{axolotl}, with continued pretraining..."
- CAPEC: MITRE’s Common Attack Pattern Enumeration and Classification, a catalog of known attack patterns. "Seed data (e.g., CAPEC attack patterns) is processed by the Planner Agent"
- Capture the flag (CTF): Interactive security competitions where participants solve hands-on challenges in areas like exploitation and reverse engineering. "assess red-team capabilities through capture the flag (CTF) challenges (e,g web exploitation, reverse engineering) in interactive settings."
- Catastrophic forgetting: Loss of previously learned knowledge when a model is trained on new data without safeguards. "To avoid catastrophic forgetting on general knowledge, we mix CyberFineWeb with general-knowledge samples from FineWeb-Edu"
- Chain-of-thought prompting: Prompting that elicits step-by-step reasoning from an LLM to improve reliability and alignment with a rubric. "#1{We observe that chain-of-thought prompting plays a significant role in producing more precise judgments.}"
- Common Crawl: A massive, open web corpus used for large-scale pretraining. "Common Crawl (2013--2024; 15T tokens)."
- Common Vulnerabilities and Exposures (CVE): A standardized list of publicly known cybersecurity vulnerabilities. "common vulnerabilities and exposures(CVE)-to-common weakness enumeration(CWE) mapping"
- Common Vulnerability Scoring System (CVSS): An industry standard method for scoring the severity of software vulnerabilities. "common vulnerability scoring system (CVSS) prediction"
- Common Weakness Enumeration (CWE): A standardized taxonomy of software weakness types. "common vulnerabilities and exposures(CVE)-to-common weakness enumeration(CWE) mapping"
- Continued pretraining (CPT): Further pretraining of a base LLM on new corpora to adapt it to a domain. "For continued pretraining (CPT), we first train on the CyberFineWeb corpus"
- Cyber threat intelligence (CTI): Evidence-based knowledge about cyber threats used for detection, attribution, and defense. "threat actor attribution in cyber threat intelligence."
- CyberFineWeb: A cybersecurity-filtered subset of a large web corpus curated for domain-specific pretraining. "We construct CyberFineWeb by filtering FineWeb"
- Data decontamination: Removal of training items that overlap with evaluation data to prevent leakage and inflated scores. "#1{Data decontamination.}"
- DeepSpeed ZeRO Stage 3: A memory- and compute-optimized distributed training technique that shards optimizer states, gradients, and parameters. "using DeepSpeed ZeRO Stage~3"
- Deduplication (near-duplicate removal): Filtering repeated or highly similar documents to reduce redundancy and overfitting. "We then apply global near-duplicate removal with MinHash-LSH over the combined data."
- Direct Preference Optimization (DPO): A preference-based alignment method that trains models to prefer chosen responses over rejected ones. "We apply direct preference optimization (DPO)~\citep{rafailov2023direct}"
- Distractors (MCQ): Plausible but incorrect answer options used in multiple-choice questions. "follow a four-option format with three plausible distractors"
- Distributed optimization: Training across multiple GPUs/nodes to scale batch size and throughput. "We run a single epoch with distributed optimization on 32A100-64GB GPUs"
- Encoder-based models: Models (e.g., BERT) that use only an encoder stack, typically requiring task-specific fine-tuning. "Moreover, as encoder-based models, they require task-specific fine-tuning, restricting scalability."
- FineWeb: A cleaned, large-scale web corpus derived from Common Crawl for LLM training. "We construct CyberFineWeb by filtering FineWeb~\citep{penedo2024the}"
- FineWeb-Edu: An educationally focused subset of FineWeb shown to improve general benchmark performance. "FineWeb-Edu is a 1.3T-token educational subset shown to improve general LLM benchmarks."
- Greedy decoding: A decoding strategy that selects the highest-probability next token at each step. "regex matching on greedy decoding outputs (temperature=0)."
- HuggingFace lighteval: A standardized evaluation toolkit for LLM benchmarks. "in HuggingFace lighteval~\citep{lighteval}."
- Industrial Control Systems: Operational technology systems for monitoring and controlling industrial processes, often with unique security requirements. "SECURE~\citep{secure2024} targets Industrial Control Systems with domain-specific MCQs on risk reasoning and vulnerability analysis."
- Instruction tuning: Fine-tuning models on instruction–response data to improve following user instructions. "instruction-tuned models and structured output tasks use prefix exact match or regex matching"
- Kali Linux: A specialized Linux distribution preloaded with penetration-testing and security tools. "It spans knowledge, practical offensive skills, and tool expertise (CLI and Kali Linux)."
- LLM-as-judge: An evaluation approach where a strong LLM scores other models’ outputs against a rubric. "scored with a reference-based LLM-as-judge rubric that evaluates both factual correctness (True/False) and answer quality (0â10) across helpfulness, relevance, depth, and level of detail."
- Linear warmup: A learning-rate schedule that increases linearly at the start of training to stabilize optimization. "and a fixed learning rate of with linear warmup."
- MinHash-LSH: A technique for efficient near-duplicate detection using MinHash signatures and locality-sensitive hashing. "We then apply global near-duplicate removal with MinHash-LSH over the combined data."
- Named Entity Recognition (NER): An NLP task that identifies and classifies named entities in text. "CyberBench~\citep{liu2024cyberbench} extends beyond MCQs to tasks such as NER, summarization, and classification."
- Normalized log-likelihood accuracy: An evaluation metric using normalized log-probabilities to score multiple-choice answers. "MCQ benchmarks are scored with normalized log-likelihood accuracy over answer options"
- Open LLM Leaderboard: A suite of standardized benchmarks commonly used to compare open LLMs. "We use benchmarks from the Open LLM Leaderboard in Lighteval"
- Personally identifiable information (PII): Data that can identify a specific individual, requiring special handling/removal. "removal of personally identifiable information (PII)."
- Planner Agent: The component that analyzes seed data and creates augmentation plans and skill sets. "our Planner Agent analyzes each seed data chunk and derives candidate skill sets"
- Preference alignment: Post-training that aligns model outputs to human or synthetic preferences for helpfulness and safety. "(2) constructing a 266K-sample augmented dataset via an agentic pipeline for supervised fine-tuning, followed by preference alignment with open-source data,"
- Prompt injection: A security attack where inputs are crafted to subvert an LLM’s instructions or tools. "CyberSecEval~\citep{wan2024cyberseceval} examines model risks across eight areas (e.g., exploit generation, prompt injection)."
- QLoRA: A memory-efficient fine-tuning method using quantization with low-rank adapters. "#1{An additional larger-model scaling experiment is presented in Appendix~\ref{app:larger-scaling}, where partial RedSage data improves a Qwen3-32B model via lightweight QLoRA fine-tuning, demonstrating that our curation pipeline transfers effectively to higher-capacity LLMs.}"
- Quota-aware random sampling: Sampling that respects category quotas to maintain balanced distributions. "and apply quota-aware random sampling to ensure taxonomic balance"
- RAG (Retrieval-Augmented Generation): A method that augments generation with retrieved documents for more factual outputs. "CyberMetric~\citep{cybermetric24} provides 10K MCQs generated with RAG and expert validation"
- ReaderLM-v2: A model/tooling used to convert web content into structured Markdown for downstream processing. "convert them to Markdown using ReaderLM-v2~\citep{wang2025readerlmv2}"
- Red-team: Offensive security practice focused on emulating attackers to test defenses. "assess red-team capabilities through capture the flag (CTF) challenges"
- Replay-based continual learning: A strategy that mixes prior data during new training to mitigate forgetting. "This strategy follows prior work on replay-based continual learning~\citep{ibrahim2024simple,guo2025efficient}"
- Root Cause Mapping (RCM): A CTI-Bench subtask that maps vulnerabilities or incidents to underlying causes. "CTI-Bench \citep{ctibench2024} (MCQ, Root Cause Mapping (RCM))"
- SECURE (benchmark): A cybersecurity benchmark focusing on Industrial Control Systems with specialized MCQs. "For SECURE \citep{secure2024}, we evaluate models using the MCQs types covering MEAT, CWET, and KCV."
- Supervised fine-tuning (SFT): Training on labeled instruction–response pairs to specialize or align a model. "for supervised fine-tuning (SFT)."
- Tulu 3 Preference Mixture: An open dataset of preference pairs used for preference-based alignment like DPO. "We apply direct preference optimization (DPO)~\citep{rafailov2023direct} with open-source Tulu~3 8B Preference Mixture dataset~\citep{lambert2025tulu3pushingfrontiers}"
- Verifier LLM: A strong model used to check and score generated items for structure and quality. "uses a verifier LLM with a checklist on format, correctness, distractors, topical relevance, and consistency, filtering items by pass/fail;"
Collections
Sign up for free to add this paper to one or more collections.