- The paper presents a unified end-to-end VLN architecture integrating BEV-based perception, waypoint and future scene prediction, and hierarchical planning.
- The model achieves state-of-the-art performance on challenging benchmarks like REVERIE, R2R-CE, and RxR-CE, underscoring its improved scene grounding and spatial reasoning.
- The design mitigates error accumulation by explicitly fusing predictive cues with holistic scene representations, enhancing robust instruction-following navigation.
Unified Perception, Prediction, and Planning for Vision-and-Language Navigation: An Analysis of P3Nav
Introduction
P3Nav ("P3Nav: End-to-End Perception, Prediction and Planning for Vision-and-Language Navigation" (2603.17459)) introduces a fully end-to-end architecture for Vision-and-Language Navigation (VLN) that explicitly unifies perception, prediction, and planning modules. Unlike prior approaches that primarily focus on direct alignment between visual features and language or rely on modular designs with external scene graph or waypoint predictors, P3Nav leverages a unified Bird's-Eye-View (BEV) representation with differentiable feature propagation across all intermediate heads. The central hypothesis is that explicit and holistic scene understanding, with both current and predictive cues provided to the planner, is critical for robust and efficient instruction-following navigation.
The authors claim new state-of-the-art (SOTA) results on three challenging VLN benchmarks: REVERIE, R2R-CE, and RxR-CE, and justify each module’s inclusion via quantitative, ablation, and qualitative studies.
Motivation and Methodological Overview
The motivation for P3Nav arises from the deficiencies and brittleness observed in both implicit end-to-end and modular VLN approaches. Implicit end-to-end models based on transformers or sequence-to-sequence mapping generally lack mechanisms to extract and propagate navigation-critical scene semantics, causing fragile textual grounding and poor generalization. Modular approaches constructing external scene graphs or standalone waypoint predictors improve scene analysis, but suffer from information loss and error accumulation at module boundaries.
To address these issues, P3Nav introduces an architecture that:
- Encodes panoramic observations to a BEV representation as a shared spatial feature core.
- Decodes object-level and map-level semantic features in parallel to harness both fine-grained landmark cues and spatial relations (perception).
- Predicts candidate waypoints and future map semantics conditioned on current BEV and perception features (prediction).
- Integrates all features in a differentiable planning module that reasons over immediate, prospective, and global memories, fusing their scores hierarchically for instruction-grounded navigation decisions.
This design is summarized in the system motivation diagram:
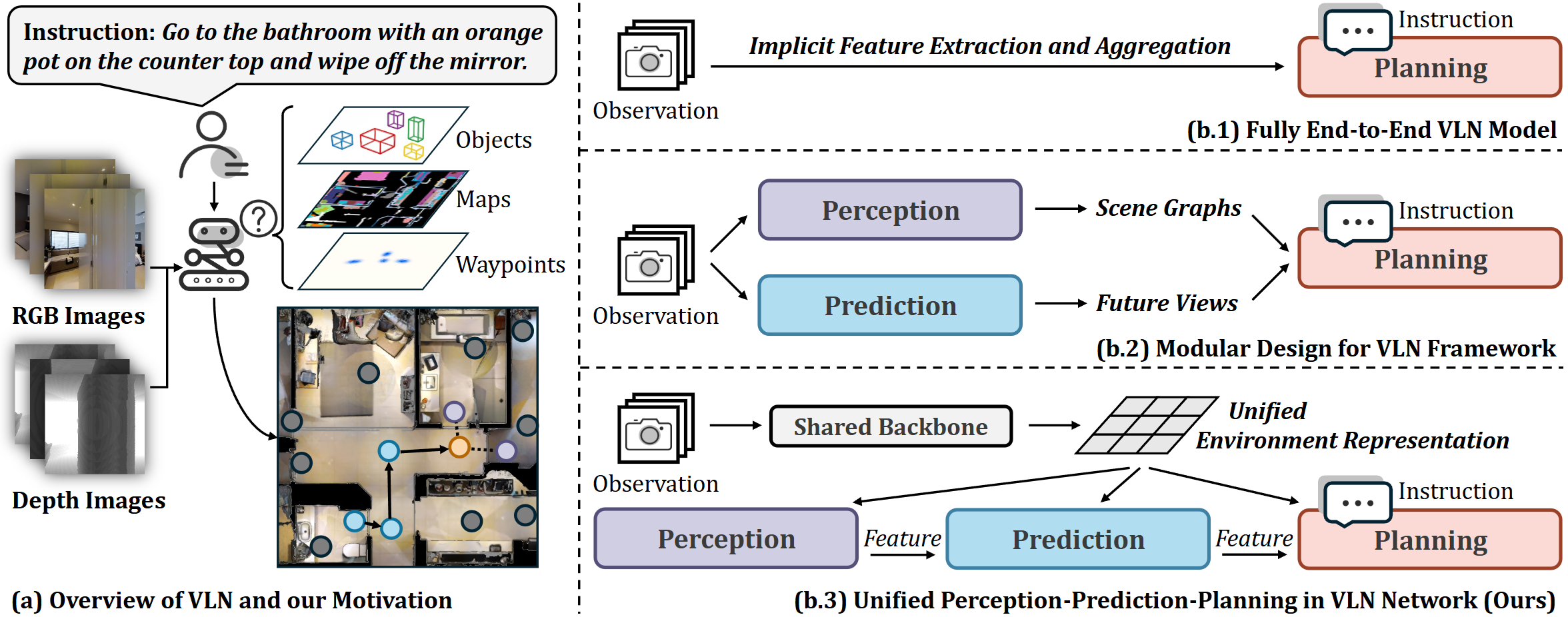
Figure 1: The P3Nav design motivation—contrasting prior planning-centric and modular models with the unified perception, prediction, and planning pipeline of P3Nav.
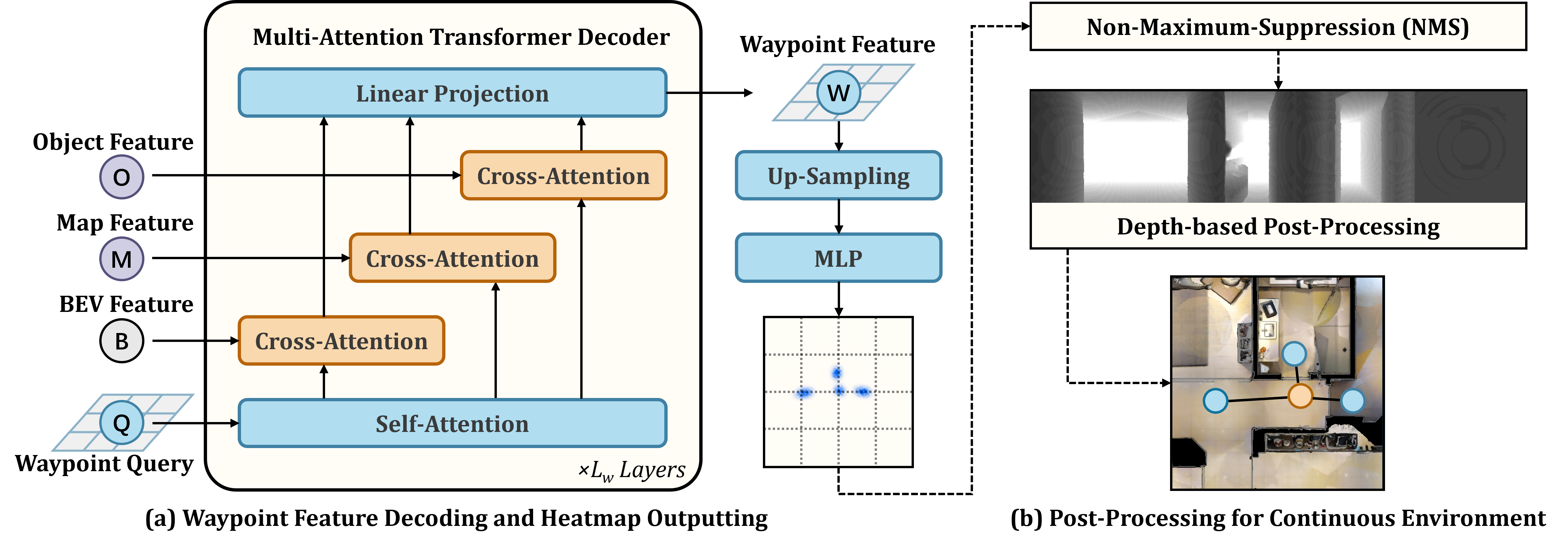
The detailed system pipeline is as follows:
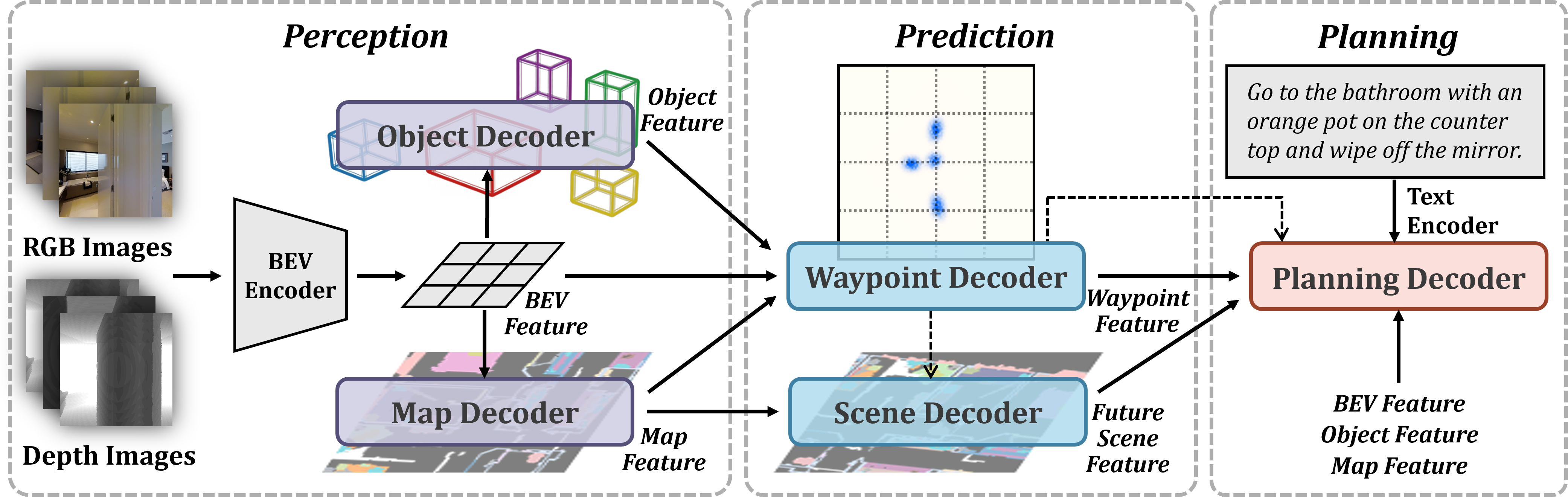
Figure 2: The full P3Nav pipeline, illustrating the flow from BEV encoding to dual-level perception, sequential prediction, and fused planning.
Perception: Object and Map Semantics
P3Nav's perception module applies parallel object-level and map-level analysis to the unified BEV grid. Object queries are updated using deformable attention, enabling explicit object detection and providing fine-grained landmark features essential for visual-textual alignment. In parallel, map queries interact with the BEV features to decode spatial relations into a latent code that compactly summarizes global scene semantics.
The ground truth for map semantics leverages Matterport3D annotations and Vision-LLMs (VLMs), with template-based scene descriptions refined via cross-modal fusion. The map semantic code is taken from the last VLM decoder token and supervised with MSE loss:
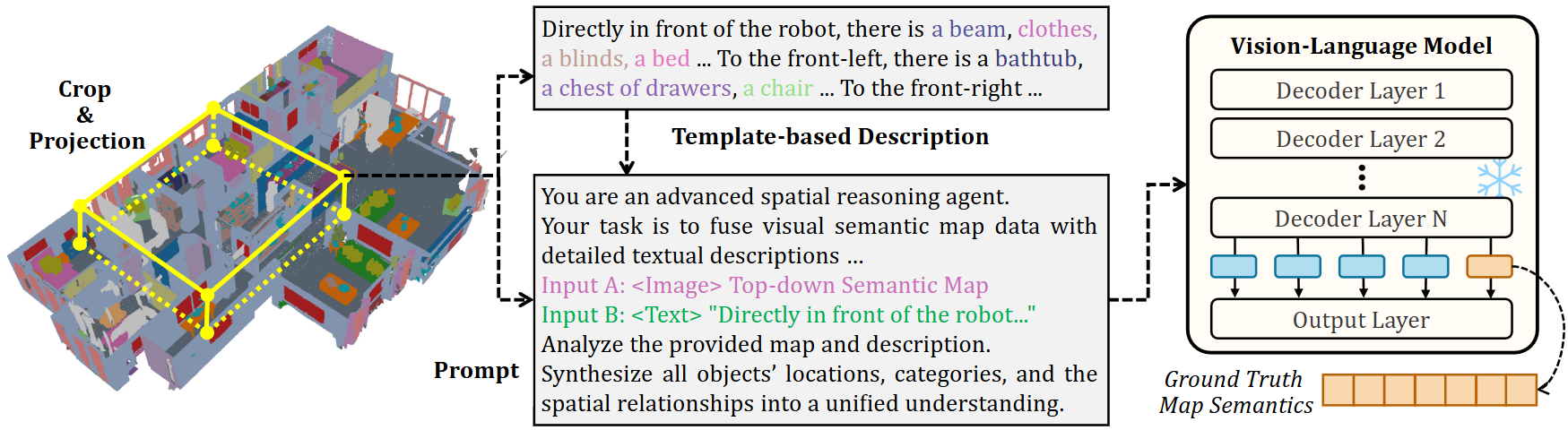
Figure 3: Pipeline for generating ground truth map semantics—BEV map projection, template description generation, and VLM-based semantic fusion.
Prediction: Waypoint and Future Scene Forecasting
P3Nav augments present-state understanding with explicit prediction of future agent states and their corresponding semantic contexts:
Planning: Hierarchical Fusion of Perception and Prediction
The planner synthesizes features from all preceding heads via a three-tiered process:
- Immediate Scene Grounding: Assesses current physical and semantic affordances via BEV, object, map, and waypoint features, aligned with language embeddings.
- Prospective Future Evaluation: Scores candidate waypoints by considering the anticipated scene graph in conjunction with language features.
- Global Memory Correction: Integrates long-term context by reasoning over the history of past waypoints and their semantics.
These perspectives are progressively fused in a hierarchical manner, ensuring both local and global optimality, and robustly avoiding short-sighted or locally trapped behavior.
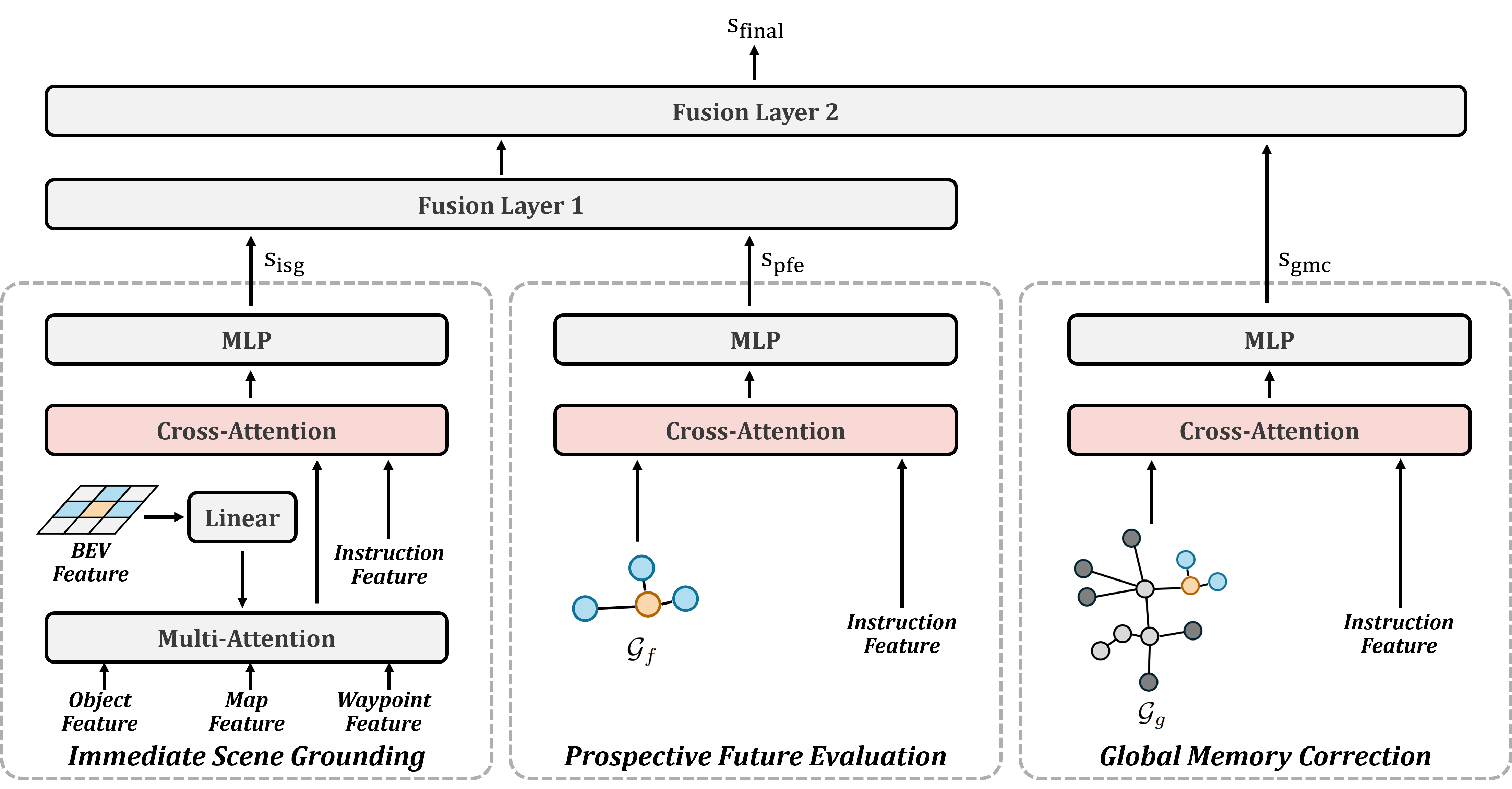
Figure 5: Planning module pipeline—successive fusion of immediate, prospective, and global cues for final navigation scoring.
Empirical Results
Extensive experiments on REVERIE, R2R-CE, and RxR-CE demonstrate clear SOTA performance. Selected numerical highlights include:
- REVERIE Test Unseen: 60.06 SR and 39.75 RGS, exceeding all previous published results for both navigation and target localization.
- R2R-CE Validation Unseen: 62 SR, 52 SPL, and 69 OSR.
- RxR-CE Validation Unseen: 58.01 SR, 47.92 SPL, 64.29 nDTW, and 48.04 SDTW.
The advantage over prior baselines (including modular approaches and map-based planners) is consistent across all metrics and environments.
Component-wise analysis demonstrates that both object-level and map-level perception heads are indispensable: removing either results in statistically significant drops in success rate and alignment metrics. The waypoint and scene decoders similarly yield complementary gains by augmenting candidate selection and forward reasoning.
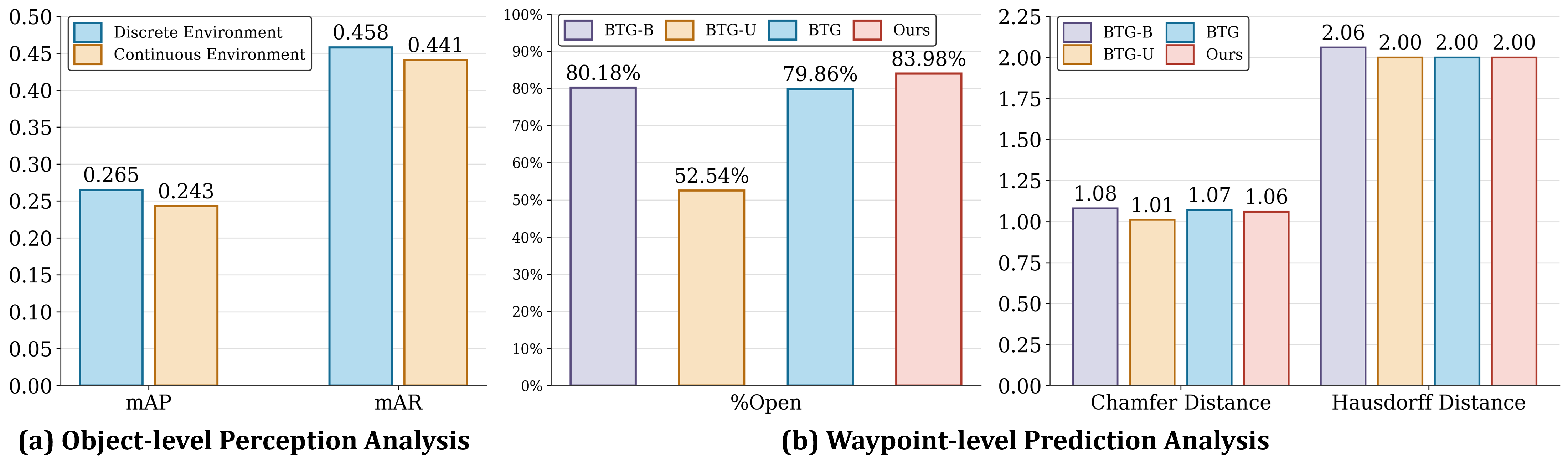
Figure 6: Quantitative analysis of object-level perception (mAP, mAR) and waypoint prediction (spatial and obstacle-aware metrics).
Qualitative Demonstrations and Ablation
Case studies underline the agent's improved ability to correctly associate complex referential language with in-scene entities and maintain globally consistent trajectories, even in the presence of occlusion, multi-step compositional instructions, or continuous control execution.

Figure 7: Simulation case study—P3Nav versus BEVBert: superior path selection and target localization.

Figure 8: Real-world case study—P3Nav executing complex navigation instructions with robust scene grounding and spatial reasoning.
Ablations between modular and end-to-end integration confirm that joint end-to-end optimization of intermediate modules is critical for high-fidelity feature propagation and mitigating error accumulation ("modular" approaches exhibit nontrivial drops in SR, SPL, nDTW).
Practical and Theoretical Implications
Practically, P3Nav's holistic, interpretable pipeline sets a strong precedent for future embodied instruction-following agents—demonstrating that tightly intertwining semantic perception, explicit prediction, and learned planning can jointly yield robust, generalizable navigation. The real-world deployment suggests strong resilience to observation noise and physical imprecision.
Theoretically, P3Nav opens pathways towards explicit yet differentiable intermediate scene representations in embodied decision making, moving beyond black-box end-to-end mapping or brittle symbolic modularity. The demonstrated gains from using latent VLM codes for map semantics further indicate the advantages of integrating large-scale cross-modal pre-training into end-to-end navigation pipelines.
Potential for Future AI Systems
Future research may extend these principles to:
- More general semantic task specification (beyond navigation).
- Holistic world modeling in open domains via larger scene graphs and LLMs.
- Curriculum- or memory-augmented hierarchical reinforcement learning leveraging analogous unified pipelines.
- End-to-end sim-to-real transfer, bridging the reality gap with robust perception-prediction-planning coupling.
Conclusion
P3Nav sets a new standard for interpretable, end-to-end VLN by demonstrating the value of unified, explicit multi-level perception and prediction tightly integrated with hierarchical planning. The design achieves SOTA results with clear ablation-validated module efficacy, provides directions for further integration of cross-modal knowledge, and establishes a robust blueprint for future embodied agents that require precise language grounding and spatial-semantic reasoning (2603.17459).