Pre-training LLM without Learning Rate Decay Enhances Supervised Fine-Tuning
Abstract: We investigate the role of learning rate scheduling in the large-scale pre-training of LLMs, focusing on its influence on downstream performance after supervised fine-tuning (SFT). Decay-based learning rate schedulers are widely used to minimize pre-training loss. However, despite their widespread use, how these schedulers affect performance after SFT remains underexplored. In this paper, we examine Warmup-Stable-Only (WSO), which maintains a constant learning rate after warmup without any decay. Through experiments with 1B and 8B parameter models, we show that WSO consistently outperforms decay-based schedulers in terms of performance after SFT, even though decay-based schedulers may exhibit better performance after pre-training. The result also holds across different regimes with mid-training and over-training. Loss landscape analysis further reveals that decay-based schedulers lead models into sharper minima, whereas WSO preserves flatter minima that support adaptability. These findings indicate that applying LR decay to improve pre-training metrics may compromise downstream adaptability. Our work also provides practical guidance for training and model release strategies, highlighting that pre-training models with WSO enhances their adaptability for downstream tasks.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at a simple but important choice when training LLMs: how to change the “learning rate” over time. The learning rate is like the size of each step the model takes while learning. Many teams gradually shrink this step size (called “decay”) during pre-training to get lower training loss. But this paper asks a different question: which choice actually gives you a better model after the final, practical step—supervised fine-tuning (SFT), where the model learns to follow instructions?
Surprisingly, the authors find that not decaying the learning rate during pre-training—keeping it steady after a short warmup—often makes models do better after SFT.
The big questions the paper asks
- Is it really best to shrink the learning rate (decay) during pre-training if your goal is a strong model after SFT?
- Does a simple schedule that skips decay—called Warmup-Stable-Only (WSO)—help models adapt better in SFT?
- Do these patterns hold for different model sizes and training styles (like mid-training and very long “over-training”)?
- Why would this happen? What’s going on inside the model’s “loss landscape” (the shape of the problem the model is trying to solve)?
How they tested their ideas (explained simply)
Think of training a model like hiking down into a valley to find the lowest point (the best solution). The learning rate is how big your steps are:
- Warmup: start with small steps and quickly ramp up to a good step size (so you don’t trip at the start).
- Decay: many people then make steps smaller and smaller to reach a lower spot in the valley.
- WSO (Warmup-Stable-Only): you warm up, then keep the step size steady until the end—no shrinking later.
What the authors did:
- They trained two sizes of models (about 1 billion and 8 billion parameters) using different learning rate plans: Cosine decay, Linear decay, Warmup-Stable-Decay (WSD), and Warmup-Stable-Only (WSO).
- After pre-training, they did SFT (teaching the models to follow instructions) using standard instruction datasets.
- They tested the models on common benchmarks (reasoning, math, reading comprehension, and instruction-following).
- They also tried “mid-training” (an extra training stage before SFT) and “over-training” (training on a huge amount of text) to see if the results still held.
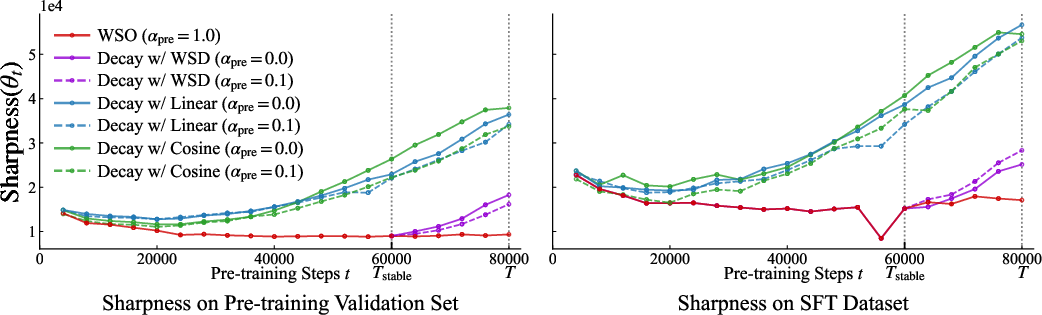
- Finally, they studied the “loss landscape” shape. In everyday terms, they checked whether the place the model ended up was a sharp, narrow valley (hard to move around without losing performance) or a wide, flat valley (easier to adapt when you fine-tune). They measured “sharpness” to quantify this.
What they found and why it matters
Key findings:
- Decay helps pre-training numbers, but hurts adaptability: Schedules that shrink the learning rate (decay) often give better pre-training metrics (like lower loss). But after SFT, those same models usually perform worse.
- WSO wins after SFT: Models trained with WSO (no decay after warmup) consistently did better after SFT across both 1B and 8B models and across many benchmarks.
- Works in modern pipelines: The same pattern holds when there’s a mid-training stage and even in “over-training” with trillions of tokens. In short: WSO stays robust.
- Flatter is more adaptable: Models trained with decay ended up in “sharper” minima (narrow valleys). Models trained with WSO ended up in “flatter” minima (wide valleys). Flatter minima made the models more adaptable during SFT, leading to better final performance.
- The data backs the link: They found a clear negative correlation between sharpness and SFT performance—sharper = worse after SFT; flatter = better after SFT.
Why this is important:
- Many teams pick learning rate decay because it improves pre-training loss. But if your goal is a model that responds well to SFT and real tasks, decay can be the wrong choice.
- WSO offers a simple, practical change: keep the learning rate steady after warmup during pre-training to get a more “flexible” model for later fine-tuning.
What this means going forward
- Train for the end goal, not just pre-training scores: If you plan to fine-tune your model for instructions or other tasks, consider skipping learning rate decay during pre-training.
- Release base models that are easier to fine-tune: Models pre-trained with WSO are likely better starting points for many downstream users because they adapt more easily.
- Rethink mid-training schedules: Even in multi-stage pipelines, avoiding decay (keeping the LR steady) can help the final SFT performance.
- A simple rule of thumb: Aim for flatter minima during pre-training (WSO helps) to make the model more adaptable later.
In short, the paper’s message is: don’t just chase the best pre-training metrics. If you want the best final model after SFT, keep the learning rate steady after warmup during pre-training. This simple tweak often makes models more flexible and better at learning new tasks.
Knowledge Gaps
Unresolved Knowledge Gaps and Limitations
Below is a concise, actionable list of what remains uncertain or unexplored in the paper, to guide future research:
- Scale generalization: Findings are shown for 1B and 8B models; it is unknown whether WSO’s SFT advantage persists at larger scales (e.g., ≥30B, ≥70B, ≥100B), or with MoE architectures.
- Architectural breadth: Results are limited to Llama‑3–style decoder-only models; effects on encoder–decoder models, convolutional/linear-attention variants, and non-Transformer architectures are not evaluated.
- Optimizer interactions: Only one optimizer configuration is effectively used (implied AdamW-like); the sensitivity of WSO’s benefit to optimizer variants (e.g., Lion, Adafactor), Adam betas, weight decay values/schedules, gradient clipping thresholds, EMA, and mixed-precision settings is not assessed.
- Max LR and warmup sensitivity: The pre-training max LR is fixed (3e−4) and warmup schedule/length are not ablated; whether WSO’s advantage holds across max LR and warmup sweeps (per scheduler) is unknown.
- Batch-size and sequence-length effects: The interaction between WSO and global batch size, microbatching, gradient accumulation, and context length scaling is not examined.
- Fairness at stage boundaries: In mid-training, “constant LR” inherits different absolute LR values depending on whether pre-training decayed or not; a controlled study that resets the mid-training LR to a common value across conditions (to isolate the effect of decay vs LR magnitude) is missing.
- Broader scheduler family coverage: Only Linear, Cosine, WSD, and WSO are tested; schedules like One-Cycle, cosine with restarts, exponential/step decay, slanted triangular, polynomial decay, and noise-injected schedules are not explored.
- Decay-phase design space: The onset, length, and rate of the decay phase (beyond αpre ∈ {0, 0.1}) are not systematically varied; whether gentler/shorter/late decays mitigate sharpness and preserve SFT adaptability remains open.
- Stage-wise LR resets: Common practice often resets LR at the start of new stages; the paper does not test resetting LR (to a shared value) at mid-training or SFT start as a confound-control or as a potential alternative to WSO.
- Post-training diversity: Only supervised fine-tuning (SFT) is considered; the downstream impact on preference optimization (e.g., DPO), RLHF, safety-tuning, and tool-use fine-tuning is not studied.
- SFT methodology breadth: It is unclear whether SFT uses full-parameter fine-tuning; effects of WSO under parameter-efficient fine-tuning (LoRA/QLoRA/adapters), different SFT schedulers, and SFT regularization are unexplored.
- SFT data dependence: Only the Tulu‑3 SFT mixture is used; whether the WSO benefit holds across different instruction mixtures, task distributions, instruction qualities, and multilingual SFT corpora is not evaluated.
- Knowledge retention vs adaptability: The paper infers adaptability improvements but does not measure catastrophic forgetting or preservation of pre-training competencies post-SFT; tradeoffs between adaptability and retention remain unquantified.
- Evaluation breadth and bias: SFT evaluation focuses on AlpacaEval, TruthfulQA, MMLU (and a larger suite in the three-stage setup) but lacks comprehensive safety, calibration, multilingual, code, and specialized domain evaluations; LLM-judge biases (e.g., AlpacaEval) are not discussed.
- Statistical robustness: Results are reported as relative deltas with no confidence intervals, multiple seeds, or significance testing; the variance and reproducibility of the observed gains are unknown.
- Over-training generality: Over-training experiments are conducted only for 1B; whether the WSO advantage in heavy over-training persists for larger models and across wider token budgets is unknown.
- Domain shift severity: Mid-training explores a limited domain shift; whether WSO’s benefits scale with more extreme shifts (e.g., code, math-heavy, multilingual, long-context extensions) is not analyzed.
- Mechanistic validation of flatness hypothesis: The sharpness–SFT correlation is shown (Pearson r ≈ −0.71) but causal tests are absent; interventions like pre-training with SAM, SWA, model/weight averaging, or explicit flatness regularizers to mimic WSO’s flatness without removing decay are not tested.
- Sharpness measurement scope: Sharpness is primarily analyzed for the 1B model using Hutchinson’s trace estimator; results are not reported for 8B, largest-eigenvalue measures, Fisher information, or alternative curvature proxies, nor is estimation variance quantified.
- Training stability boundaries: Constant LR training can risk instability; the paper does not map stability regions (divergence thresholds) for WSO across LR, batch sizes, and model sizes, or report gradient norm/pathology diagnostics.
- Compute/economic tradeoffs: Although WSO underperforms in pre-training metrics but improves SFT outcomes, the compute–quality tradeoff (e.g., time-to-target SFT performance, pre-training cost savings/penalties) is not quantified.
- Pre-training LR scheduling across data mixtures: Only a few data mixtures (FineWeb‑Edu, OLMo mixes) are studied; how data quality, deduplication, curriculum, and mixture ratios interact with WSO vs decay schedules remains unexplored.
- Preservation of zero-shot/unsupervised capability: WSO degrades pre-training metrics; whether this harms use cases that rely on zero-shot/unsupervised performance (without SFT) is not assessed.
- Interaction with regularization: Effects of dropout, label smoothing, data augmentation, and weight decay schedules on the WSO vs decay outcome are not investigated.
- Stage interdependencies: The paper concludes decay at any stage harms SFT, but does not analyze nuanced policies (e.g., brief late-stage decays with subsequent LR “re-warmup” or staged flattening) that might balance pre-training loss and SFT adaptability.
- Release and reproducibility: While settings are described, trained checkpoints, scripts, and full logs are not reported as released; independent replication and real-world deployment effects (e.g., safety tuning success rates) remain to be demonstrated.
- Generalization to multilingual/code/multimodal: The pre-training and SFT regimes are predominantly English text; applicability to multilingual corpora, code pre-training, and multimodal pre-training is unknown.
- Interaction with context extension: Whether WSO influences the success of long-context training (e.g., RoPE scaling, continued pre-training for long sequences) and subsequent SFT is not tested.
- Post-training schedule effects: The SFT LR schedule design (decay vs constant) is not detailed; interactions between pre-training schedule (WSO vs decay) and SFT LR schedule choices remain unstudied.
- Practical selection criteria: The work advises picking models trained with WSO for release, but offers no diagnostics (beyond sharpness) to decide when WSO is preferable given specific post-training goals or task portfolios.
Practical Applications
Immediate Applications
The following are concrete, deployable uses of the paper’s findings that organizations can adopt now to improve model adaptability and post-training performance.
- Adopt Warmup‑Stable‑Only (WSO) in pre‑training when downstream SFT is planned
- Description: Replace decay-based LR schedules (Cosine, Linear, WSD) with a constant LR after warmup to improve SFT outcomes, even if pre-training loss is slightly worse.
- Sectors: Software/AI labs, cloud providers, foundation model builders.
- Tools/workflows: Training recipes/templates with WSO; default LR scheduler modules in internal frameworks.
- Assumptions/dependencies: Stable optimization with a chosen max LR and warmup; AdamW-like optimizers; target pipeline includes SFT; results established for Llama-like 1B/8B models and evaluated on Tulu-3 SFT mixture.
- Apply WSO across mid‑training (avoid further decay)
- Description: Keep LR constant in mid-training as well; avoid decays that reduce adaptability before SFT.
- Sectors: Model labs with multi-stage pipelines (pre-, mid-, post-training).
- Tools/workflows: Mid-training configurations setting α_mid=1.0; curated mid-training data (e.g., high-quality/domain data).
- Assumptions/dependencies: Mid-training objective remains language modeling; training remains stable at a fixed LR.
- Release “SFT‑ready” checkpoints
- Description: Publish and tag base models pre-trained with WSO as more adaptable starting points for enterprise or community fine-tuning.
- Sectors: Open-source model hubs, commercial model marketplaces.
- Tools/workflows: Model cards explicitly documenting LR schedules; tags like “WSO-pretrained.”
- Assumptions/dependencies: Users have access to base weights for SFT; transparency in training logs.
- Shift model selection from pre‑training loss to post‑training utility
- Description: Select checkpoints for the next stage based on projected SFT performance rather than the lowest pre-training loss.
- Sectors: MLOps, AI product teams.
- Tools/workflows: Small SFT “probe” evaluations; selection heuristics that downweight pre-training metrics.
- Assumptions/dependencies: Availability of small, representative SFT datasets; willingness to trade slight PT metric gains for better downstream.
- Instrument training with sharpness monitoring for checkpoint selection
- Description: Add Hessian-trace (sharpness) estimators (e.g., Hutchinson-based) to dashboards and prefer flatter minima for SFT readiness.
- Sectors: MLOps/Observability, academia.
- Tools/workflows: Periodic sharpness computation on validation batches; alerts/thresholds for sharpness increases during LR decay.
- Assumptions/dependencies: Extra compute for Hessian-vector products; proxy fidelity acceptable for billion-parameter models.
- Improve parameter‑efficient fine‑tuning (PEFT) outcomes with WSO bases
- Description: Start LoRA/Adapters/Prefix-tuning from WSO-pretrained models to gain better instruction-following with fewer steps/data.
- Sectors: SMEs, healthcare, finance, customer support.
- Tools/workflows: PEFT kits (e.g., LoRA) integrated with WSO base checkpoints.
- Assumptions/dependencies: Similar distribution shift as in the paper; careful safety/QA for regulated sectors.
- Lower SFT data/compute for enterprise customization
- Description: Use WSO bases to reach target performance with less fine-tuning data/epochs in vertical applications (e.g., contact centers, legal).
- Sectors: Enterprise SaaS, legal, finance, customer service.
- Tools/workflows: Prebuilt instruction datasets + company data; reduced LR/epoch sweeps due to better adaptability.
- Assumptions/dependencies: Comparable task and data complexity to evaluated benchmarks; robust evaluation for safety.
- Domain expansion via mid‑training without decay prior to SFT
- Description: When expanding to jargon-heavy domains (e.g., clinical/biomedical, legal), maintain constant LR in mid-training to preserve adaptability.
- Sectors: Healthcare/biomed, legal services.
- Tools/workflows: Curated domain corpora; mid-training with α_mid=1.0; subsequent SFT for instruction alignment.
- Assumptions/dependencies: High-quality mid-training data; strict compliance and privacy practices.
- Education-focused fine‑tuning with limited resources
- Description: Build classroom assistants or tutoring bots by fine-tuning WSO bases on small, curriculum-specific datasets.
- Sectors: Education/EdTech.
- Tools/workflows: Lightweight SFT pipelines; evaluation on instruction-following (e.g., AlpacaEval) and MMLU subsets.
- Assumptions/dependencies: Content quality and local curriculum coverage; guardrails for age-appropriate/use.
- Procurement/model selection using “adaptability score”
- Description: Add an adaptability metric (e.g., sharpness + small SFT probe) to vendor evaluations rather than relying on PT loss or zero-shot.
- Sectors: Public-sector IT, regulated enterprise procurement.
- Tools/workflows: Standardized probe SFT; reporting templates capturing LR schedule and sharpness proxies.
- Assumptions/dependencies: Access to base weights or vendor-run probes; standardization of tests across vendors.
- Reduce LR-scheduler hyperparameter sweeps
- Description: Simplify LR policy tuning by removing decay-phase hyperparameters and focusing search on max LR and warmup.
- Sectors: Model training teams, cloud compute operations.
- Tools/workflows: AutoML pipelines with fewer LR schedule dimensions; reproducible recipe libraries.
- Assumptions/dependencies: Stability at chosen max LR; may still require per-scale calibration.
- Continual pre‑training (CPT) version updates without decay
- Description: For successive CPT rounds, avoid decay to maintain adaptability for subsequent SFT or alignment steps.
- Sectors: Foundation model maintainers.
- Tools/workflows: Versioned CPT pipelines with constant LR; release notes emphasizing SFT-readiness.
- Assumptions/dependencies: Monitoring for catastrophic drift; periodic probe SFT for regressions.
Long‑Term Applications
These opportunities may require further validation across scales, modalities, optimizers, or training regimes, and/or new tooling and standards.
- Adaptability‑aware pre‑training objectives and optimizers
- Description: Co-optimize for flat minima (e.g., SAM, sharpness penalties) and downstream SFT performance rather than PT loss alone.
- Sectors: AI R&D.
- Tools/workflows: Regularizers targeting sharpness; multi-objective training pipelines.
- Assumptions/dependencies: Stable large-scale implementations; avoiding over-regularization that harms learning.
- Learning‑to‑schedule controllers that maximize post‑training utility
- Description: Automated controllers/RL agents that adjust LR over pre-/mid-training to maintain flatness and improve later SFT.
- Sectors: AutoML, platform tooling.
- Tools/workflows: Closed-loop schedulers with sharpness feedback; Bayesian/RL controllers.
- Assumptions/dependencies: Reliable online proxies for sharpness; low-latency metrics.
- Cross‑domain validation (code, multimodal, speech)
- Description: Extend WSO findings to code LLMs, VLMs, and speech models; verify adaptability gains hold broadly.
- Sectors: Software engineering, robotics, media.
- Tools/workflows: Benchmarks for code generation, VQA, planning; domain-specific SFT suites.
- Assumptions/dependencies: Architectural differences may change stability; different loss landscapes.
- Standardized “SFT‑readiness” certification in model cards and procurement
- Description: Policy and ecosystem standards to disclose LR schedules, sharpness proxies, and SFT probe results.
- Sectors: Governance, policy, enterprise procurement.
- Tools/workflows: Model card extensions; third-party certification bodies.
- Assumptions/dependencies: Community consensus on metrics and thresholds; vendor cooperation.
- Integration with alignment (DPO/RLHF) scheduling
- Description: Design post-training LR and optimizer policies (DPO/RLHF) that exploit flatter pre-training minima for safer, more data-efficient alignment.
- Sectors: Safety/alignment teams.
- Tools/workflows: Pipeline-wide schedule orchestration; alignment-stage sharpness monitoring.
- Assumptions/dependencies: Alignment objectives may interact differently with flatness; careful evaluation of safety outcomes.
- Compute‑budget planning and new scaling laws for adaptability
- Description: Reallocate compute from chasing PT loss to maximizing post-training performance; derive scaling laws linking LR schedule, sharpness, and SFT efficiency.
- Sectors: Cloud/energy planning, model labs.
- Tools/workflows: Cost–benefit dashboards; experimental design frameworks.
- Assumptions/dependencies: Laws may vary by model family, data quality, and task mix.
- Robustness under distribution shift via flat‑minima pre-training
- Description: Use WSO-pretrained bases to improve robustness when fine-tuning on shifted distributions (e.g., clinical notes, financial filings).
- Sectors: Healthcare, finance, legal.
- Tools/workflows: Domain-shift challenge suites; OOD evaluation harnesses.
- Assumptions/dependencies: Need large-scale validation beyond the paper’s tasks; regulatory validation.
- Model selection frameworks that include curvature metrics by default
- Description: Bake Hessian-trace proxies into standard training suites and selection UIs; treat sharpness as a first-class metric.
- Sectors: MLOps platforms, open-source frameworks.
- Tools/workflows: Library support for efficient Hessian-vector products; UI/alerts.
- Assumptions/dependencies: Efficient, unbiased estimators at trillion-parameter scale.
- Curriculum and data‑mix design that synergizes with WSO
- Description: Co-design data curricula (pre-/mid-training) and constant LR schedules to preserve flatness while improving coverage.
- Sectors: Foundation model builders.
- Tools/workflows: Data-quality scoring + schedule co-optimization; curriculum schedulers.
- Assumptions/dependencies: Interactions between data difficulty and flatness not fully understood.
- PEFT methods tailored to flat minima (e.g., “FlatLoRA”)
- Description: New PEFT techniques that exploit flatter basins for higher stability and fewer catastrophic regressions.
- Sectors: Edge/enterprise personalization.
- Tools/workflows: PEFT algorithms with curvature-aware updates; partial unfreezing policies.
- Assumptions/dependencies: Requires empirical validation across tasks and scales.
- On‑device personalization with limited compute
- Description: Flatter-minima bases could enable effective few-shot on-device customization (mobile, IoT) with small PEFT updates.
- Sectors: Consumer devices, automotive, robotics.
- Tools/workflows: Efficient PEFT runtimes; secure on-device SFT.
- Assumptions/dependencies: Hardware constraints; privacy-preserving training; stability on small batches.
- Regulatory best practices for training transparency
- Description: Encourage/require disclosure of LR schedules and downstream evaluation plans in public-sector and safety-critical deployments.
- Sectors: Government, healthcare, critical infrastructure.
- Tools/workflows: Compliance checklists; audit trails linking schedule choices to safety evaluations.
- Assumptions/dependencies: Policy adoption timelines; balancing IP concerns with transparency.
Glossary
- AGI Eval: A benchmark suite designed to evaluate general intelligence capabilities of LLMs across diverse tasks. "AGI Eval~\citep{zhong-etal-2024-agieval} for general intelligence capabilities"
- AlpacaEval: An evaluation benchmark measuring instruction-following ability of LLMs through pairwise or preference-based judgments. "AlpacaEval~\citep{alpaca_eval}"
- ARC-Challenge: The hard subset of the AI2 Reasoning Challenge multiple-choice science questions used to test reasoning. "ARC-Challenge~\citep{clark2018think}"
- ARC-Easy: The easier subset of the AI2 Reasoning Challenge multiple-choice science questions for evaluating basic reasoning. "ARC-Easy, ARC-Challenge~\citep{clark2018think}"
- BigBench-Hard: A challenging subset of the BIG-bench benchmark focusing on difficult reasoning and generalization problems. "BigBench-Hard~\citep{suzgun-etal-2023-challenging}"
- BoolQ: A yes/no question-answering benchmark that tests reading comprehension over passages. "BoolQ~\citep{clark-etal-2019-boolq}"
- checkpoint averaging: A technique that averages parameters from multiple checkpoints to improve generalization without additional training. "checkpoint averaging~\citep{sanyal2024early}"
- Chinchilla compute-optimal regime: A guideline suggesting the optimal tradeoff between model size and training tokens (about 20 tokens per parameter). "Chinchilla compute-optimal regime of roughly 20 tokens per parameter~\citep{hoffmann2022chinchilla}"
- Cosine decay: A learning rate schedule that decays the learning rate following a cosine curve, often from a peak after warmup to a small value. "Cosine decay has been conventionally employed in numerous models~\citep{brown2020gpt3, workshop2022bloom, touvron2023llama}"
- continual pre-training (CPT): Further pre-training of a model on new data distributions to adapt it while retaining prior knowledge. "continual pre-training (CPT)"
- Direct Preference Optimization (DPO): A post-training method that aligns models to human preferences by optimizing directly on preference comparisons. "preference tuning (e.g., DPO~\citep{rafailov2023direct})"
- dolmino-mix-1124: A mid-training dataset used in the study’s three-stage training pipeline. "the dolmino-mix-1124 dataset"
- distribution shift: A change in data distribution between training and deployment (or between training stages) that can degrade performance. "work well under distribution shift~\citep{kaddour2022when}"
- DROP: A reading comprehension benchmark requiring discrete reasoning operations over paragraphs. "DROP~\citep{dua-etal-2019-drop}"
- FineWeb-Edu: A filtered and educationally oriented web-scale dataset for LLM pre-training. "FineWeb-Edu~\citep{penedo2024fineweb}"
- flatter minima: Regions in the loss landscape where the loss changes slowly around the solution, typically associated with better adaptability. "WSO preserves flatter minima that support adaptability."
- GSM8K: A benchmark of grade-school math word problems used to evaluate mathematical reasoning. "GSM8K~\citep{cobbe2021training}"
- HellaSwag: A commonsense inference benchmark with adversarially-filtered multiple-choice questions. "HellaSwag~\citep{zellers-etal-2019-hellaswag}"
- Hessian: The matrix of second-order partial derivatives of the loss with respect to parameters; captures curvature of the loss landscape. "the trace of the Hessian"
- Hutchinson's unbiased estimator: A randomized method to estimate the trace of a matrix (e.g., Hessian) using only matrix–vector products. "Hutchinson's unbiased estimator~\citep{Hutchinson01011989, liu2024sophia}"
- instruction-following capability: A model’s ability to follow natural-language instructions, often measured by benchmarks like AlpacaEval. "instruction-following capability (AlpacaEval~\citep{alpaca_eval})"
- learning rate (LR) scheduling: The strategy for varying the learning rate during training (e.g., warmup, stable, decay phases). "Learning rate (LR) scheduling is arguably one of the most critical yet operationally challenging aspects of LLM pre-training."
- learning rate scheduler: A specific algorithm or function that determines the learning rate at each training step. "Decay-based learning rate schedulers are widely used to minimize pre-training loss."
- Linear decay: A schedule that reduces the learning rate linearly, often down to zero by the end of training. "Linear decay to zero achieves lower pre-training loss in compute-optimal settings~\citep{bergsma2025straight}"
- loss landscape: The surface defined by the loss function over model parameters, whose geometry affects optimization and generalization. "Loss landscape analysis further reveals that decay-based schedulers lead models into sharper minima"
- mid-training: An intermediate training stage between pre-training and post-training, used for domain expansion or capability extension. "Mid-training has emerged as a critical intermediate stage in modern LLM development"
- MMLU: A multitask benchmark that evaluates knowledge and reasoning across many academic subjects. "MMLU~\citep{hendrycks2021measuring}"
- model merging: Combining parameters from multiple trained models to produce a new model, often to blend capabilities. "model merging~\citep{tian2025wsm}"
- OLMo 2: A modern open LLM and training framework that also informs mid-training setups in this paper. "OLMo~2~\citep{olmo20242}"
- olmo-mix-1124: A curated pre-training dataset used in OLMo 2 and adopted here for comparability. "olmo-mix-1124~\citep{olmo20242}"
- OpenBookQA: A question-answering benchmark that requires applying science facts and commonsense reasoning. "OpenBookQA~\citep{mihaylov-etal-2018-suit}"
- over-training: Training on substantially more tokens than compute-optimal recommendations, often to trade training compute for inference efficiency. "over-training~\citep{sardana2024beyond, gadre2025language}"
- path-switching paradigm: A strategy for updating learning rate schedules when releasing new model versions to improve downstream performance. "a path-switching paradigm for LR scheduling in model version updates"
- PIQA: A benchmark for physical commonsense reasoning with multiple-choice questions. "PIQA~\citep{piqa}"
- preference tuning: Post-training methods that align models to human preferences, typically using pairwise comparisons or feedback. "preference tuning (e.g., DPO~\citep{rafailov2023direct})"
- RL-based alignment: Using reinforcement learning (often from human feedback) to align model outputs with desired behaviors. "RL-based alignment~\citep{ouyang2022training}"
- river valley loss landscape: A perspective where training explores along flat valley floors before converging toward the center with decay. "a river valley loss landscape perspective~\citep{wen2025understanding}"
- sharpness: A measure of loss curvature around model parameters; higher sharpness indicates more curved (sharper) minima. "sharpness values"
- Sharpness-Aware Minimization (SAM): An optimization method that seeks parameters robust to perturbations by minimizing sharpness and loss jointly. "sharpness-aware minimization~\citep{foret2021sharpnessaware}"
- stochastic weight averaging (SWA): A technique that averages weights along the training trajectory to find flatter solutions. "stochastic weight averaging~\citep{izmailov2018swa}"
- supervised fine-tuning (SFT): Post-training where models are trained on instruction–response pairs to improve task following and safety. "supervised fine-tuning (SFT)"
- trace of the Hessian: The sum of the Hessian’s diagonal elements, used as a scalar proxy for overall curvature (sharpness). "the trace of the Hessian"
- TruthfulQA: A benchmark evaluating whether models produce truthful answers to questions. "TruthfulQA~\citep{lin-etal-2022-truthfulqa}"
- Tulu-3 SFT mixture: A curated dataset mixture used for supervised fine-tuning in the experiments. "Tulu-3 SFT mixture"
- Warmup-Stable-Decay (WSD): A learning rate schedule with warmup, a long stable phase, then a final decay at the end of training. "Warmup-Stable-Decay (WSD)"
- Warmup-Stable-Only (WSO): A schedule with warmup followed by a constant learning rate and no decay phase. "Warmup-Stable-Only (WSO), which removes the decay phase"
- WinoGrande: A large-scale commonsense coreference benchmark challenging for LLMs. "WinoGrande~\citep{sakaguchi2021winogrande}"
- zero-shot performance: Model accuracy on tasks without any task-specific training or fine-tuning. "we assess zero-shot performance on standard benchmarks"
Collections
Sign up for free to add this paper to one or more collections.