How to Set the Batch Size for Large-Scale Pre-training?
Abstract: The concept of Critical Batch Size, as pioneered by OpenAI, has long served as a foundational principle for large-scale pre-training. However, with the paradigm shift towards the Warmup-Stable-Decay (WSD) learning rate scheduler, we observe that the original theoretical framework and its underlying mechanisms fail to align with new pre-training dynamics. To bridge this gap between theory and practice, this paper derives a revised E(S) relationship tailored for WSD scheduler, characterizing the trade-off between training data consumption E and steps S during pre-training. Our theoretical analysis reveals two fundamental properties of WSD-based pre-training: 1) B_min, the minimum batch size threshold required to achieve a target loss, and 2) B_opt, the optimal batch size that maximizes data efficiency by minimizing total tokens. Building upon these properties, we propose a dynamic Batch Size Scheduler. Extensive experiments demonstrate that our revised formula precisely captures the dynamics of large-scale pre-training, and the resulting scheduling strategy significantly enhances both training efficiency and final model quality.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how to choose the “batch size” when training very LLMs. Batch size is how many examples the model studies at once before it updates itself. The authors show that a popular old rule for picking batch size no longer works with the way people train modern models. They create a new way to think about batch size and propose a strategy to adjust it during training to make learning faster and better.
Key Questions
The paper asks simple but important questions:
- How should we set batch size when using the common Warmup–Stable–Decay (WSD) learning rate schedule (start slow, train steadily, then slow down)?
- Is there a minimum batch size needed to reach a certain quality (low loss)?
- Is there an “best” batch size that uses the least data to reach a chosen quality?
- Can we improve training by changing (not fixing) batch size over time?
Methods and Approach
Think of training an LLM like practicing for a big exam:
- Batch size is how many practice questions you do before checking your progress.
- Learning rate is how big a change you make to your study plan after each check.
- The WSD schedule is like: warm up (start gently), stable (keep a steady pace), decay (slowly ease off).
Earlier work (by OpenAI) used a formula to trade off “data used” (, like total tokens read) against “steps taken” (, like number of updates) to reach a target score (low loss). That old formula worked well with a different learning rate schedule but not with WSD’s long, steady middle phase.
What the authors did:
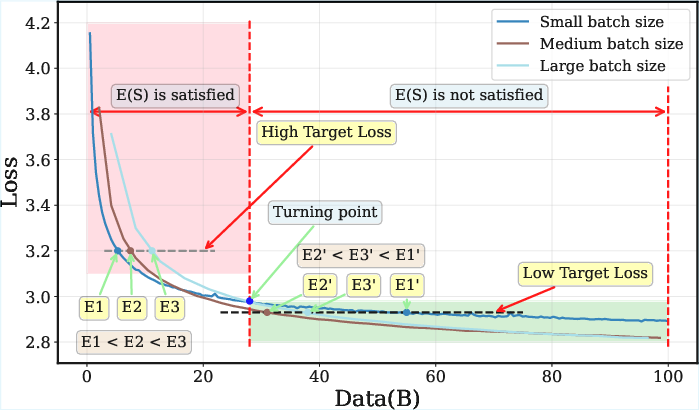
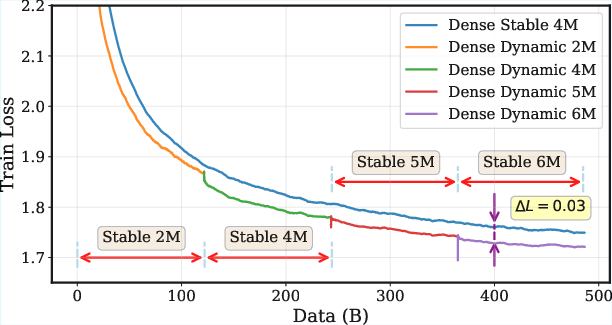
- They measured how much data is needed to reach certain loss levels under WSD and noticed training curves for different batch sizes can cross. In simple terms: sometimes a bigger batch actually needs less total data to reach a deeper (lower) loss, which breaks the old rule.
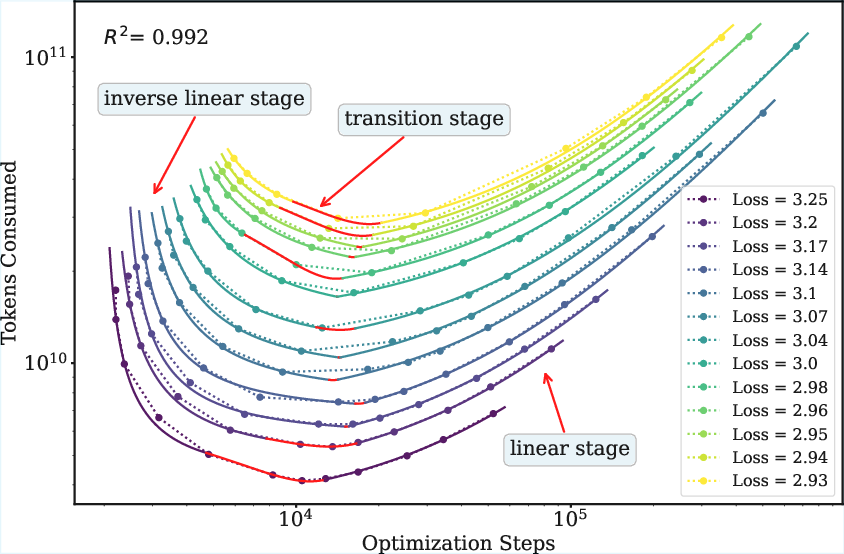
- They built a new piecewise model of (data vs steps) tailored for WSD’s stable phase:
- At first, using more steps can sharply reduce data needed.
- In the middle, there’s a “sweet spot” where the trade-off is curved (like a valley).
- Later, data needed grows more linearly with steps.
- They fit this new curve to real training results using a robust method (a fitting technique that isn’t thrown off by noisy points).
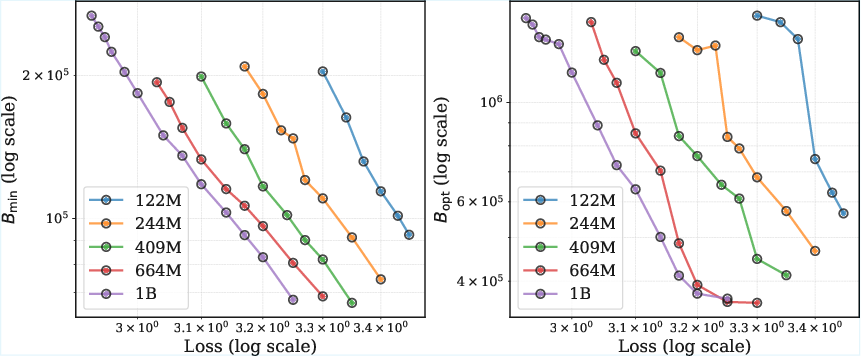
- From this curve, they defined two simple, useful batch size measures:
- : the smallest batch size you must use to reach a chosen loss (quality).
- : the batch size that reaches that loss using the least total data.
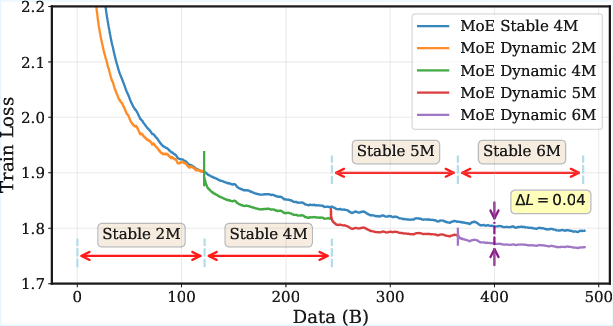
Finally, they created a practical “Batch Size Scheduler”: instead of picking one batch size for the whole run, gradually increase batch size as training progresses (especially through the stable phase), guided by the curve of vs how much data you’ve already used.
Main Findings and Why They Matter
- The old “Critical Batch Size” idea doesn’t describe modern training under WSD. In the stable phase, batch size behavior changes: curves cross, and bigger batches can become more data-efficient at lower losses.
- The new curve fits real training data well and leads to clear, interpretable batch size rules:
- is the minimum you need to even reach your target quality.
- is the best batch size for using the least data.
- Both and go up as you aim for lower loss (better quality). Translation: as the model gets better, it benefits from larger batch sizes.
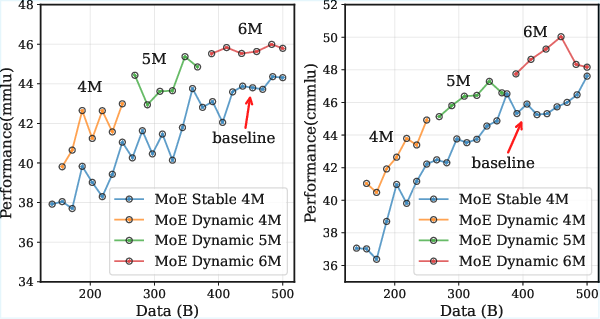
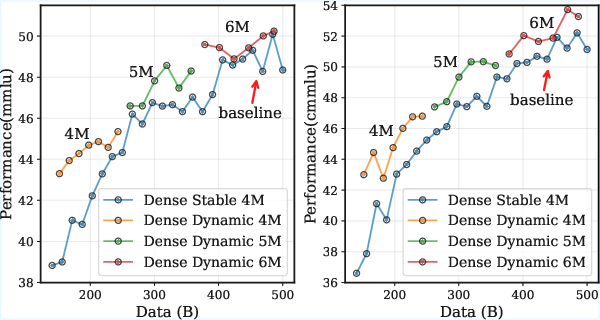
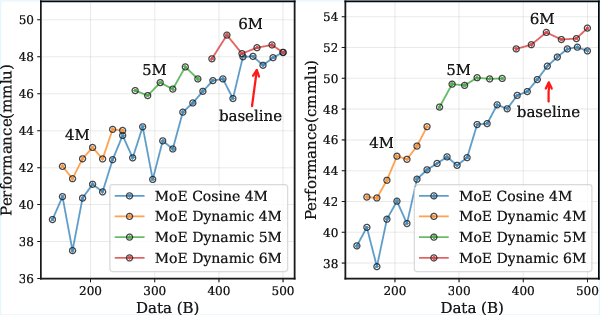
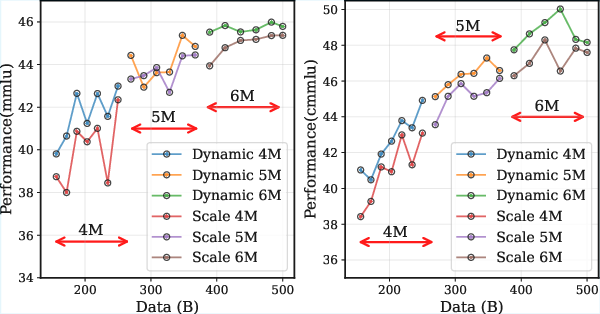
- A dynamic batch size schedule (start smaller, then step up the batch size during the stable phase) consistently beat a fixed batch size in experiments:
- It lowered training loss faster.
- It improved scores on benchmarks like MMLU and CMMLU across different model types (dense and MoE).
- Extra checks (ablations) showed:
- The strategy also helps with cosine learning rates.
- Increasing learning rate alongside batch size (a common trick) didn’t help here and could hurt, because it adds noise.
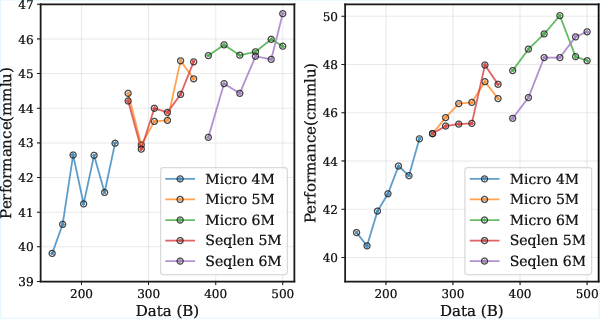
- Increasing sequence length to simulate bigger batches can cause temporary performance drops due to distribution shifts (the model starts seeing longer texts and needs time to adapt).
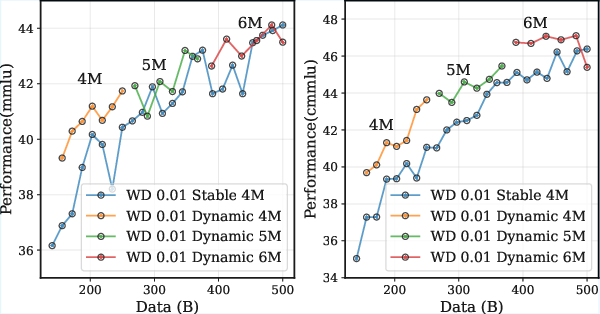
- Regularization strength (weight decay) matters: the scheduler works best with a solid weight decay setting.
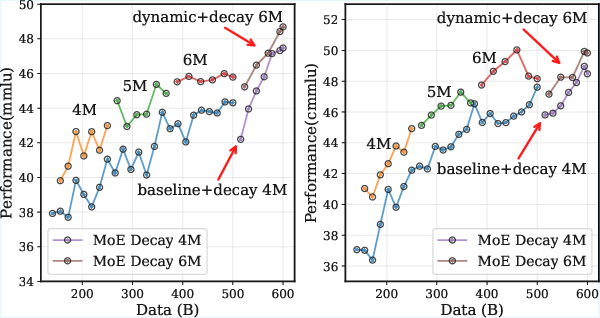
- The benefits persist into the decay phase (later part of training) too.
Implications and Impact
This work gives both a new theory and a practical recipe for modern LLM training:
- Theory: It replaces the old, now-misleading batch size rule with a WSD-friendly framework that explains what’s really happening during the long, steady training phase.
- Practice: It shows that gradually increasing batch size over training can save data, speed up convergence, and yield better models.
In simple terms, it helps teams train big models more efficiently and reach higher quality without wasting compute. Over time, this could lower training costs, make strong models more accessible, and improve performance across many AI applications.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The paper provides a theoretical framework for setting batch sizes during large-scale pre-training with a Warmup-Stable-Decay (WSD) learning rate scheduler. However, there are several areas that require further exploration:
- Generalizability across Learning Rates: The curve fitting was conducted for a specific learning rate of . It remains unclear how this relationship would change under different learning rates.
- Theoretical Proof for Dynamic Strategy: While the dynamic batch size strategy shows empirical success, the paper does not provide a formal theoretical proof supporting the approach.
- Impact of Gradient Noise: The investigation of gradient noise effects on learning dynamics under the WSD schedule is mentioned but not deeply explored, specifically the influence of
on model training dynamics. - Adaptive Strategies for Sequence Length Changes: The paper identifies performance changes associated with increased sequence lengths but does not propose methods for mitigating adaptation issues when extending sequence length.
- Weight Decay Influence: The empirical investigation of weight decay reveals significant interactions with batch size dynamics, yet the underlying mechanisms remain unexplored. How weight decay settings influence the scheduling strategy warrants further study.
- Continued Training Under Decay: The robustness of the proposed strategy during the decay phase is demonstrated, but more insights into how batch size scheduling interacts with high-quality data annealing are needed.
- Compatibility with Other Optimizers: The analysis focuses solely on the Adam optimizer. Exploring how other optimizers might perform under a similar batch size scheduling strategy remains an open question.
- Scalability Across Model Architectures: While validated on specific architectures, such as InternLM2 and Qwen3, the approach's applicability to other model architectures (e.g., Transformers with different attention mechanisms) is not examined.
These gaps provide a substantial opportunity for future research to enhance the understanding and practical application of dynamic batch sizing in LLM pre-training.
Collections
Sign up for free to add this paper to one or more collections.