MDM-Prime-v2: Binary Encoding and Index Shuffling Enable Compute-optimal Scaling of Diffusion Language Models
Abstract: Masked diffusion models (MDM) exhibit superior generalization when learned using a Partial masking scheme (Prime). This approach converts tokens into sub-tokens and models the diffusion process at the sub-token level. We identify two limitations of the MDM-Prime framework. First, we lack tools to guide the hyperparameter choice of the token granularity in the subtokenizer. Second, we find that the function form of the subtokenizer significantly degrades likelihood estimation when paired with commonly used Byte-Pair-Encoding (BPE) tokenizers. To address these limitations, we study the tightness of the variational bound in MDM-Prime and develop MDM-Prime-v2, a masked diffusion LLM which incorporates Binary Encoding and Index Shuffling. Our scaling analysis reveals that MDM-Prime-v2 is 21.8$\times$ more compute-efficient than autoregressive models (ARM). In compute-optimal comparisons, MDM-Prime-v2 achieves 7.77 perplexity on OpenWebText, outperforming ARM (12.99), MDM (18.94), and MDM-Prime (13.41). When extending the model size to 1.1B parameters, our model further demonstrates superior zero-shot accuracy on various commonsense reasoning tasks.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper introduces a new way to train text-generating AI models called MDM-Prime-v2. It improves a family of models known as “masked diffusion LLMs” (MDMs), which generate text by repeatedly “unmasking” hidden pieces of a sentence. The authors show two simple tricks—binary encoding and index shuffling—that make this kind of model learn better and use computer power more efficiently than the standard approach used in many chatbots today (called autoregressive models, or ARMs).
The main questions the paper asks
- Can we choose a better way to break each token (a chunk of text) into smaller pieces so the model learns more effectively?
- Can we design those small pieces so they carry more useful information, making training easier and more accurate?
- If we do these things, will diffusion-based LLMs become as efficient—or even more efficient—than today’s common models when we compare them fairly under the same compute budget?
How their method works (with everyday explanations)
To follow the ideas, here are a few simple concepts:
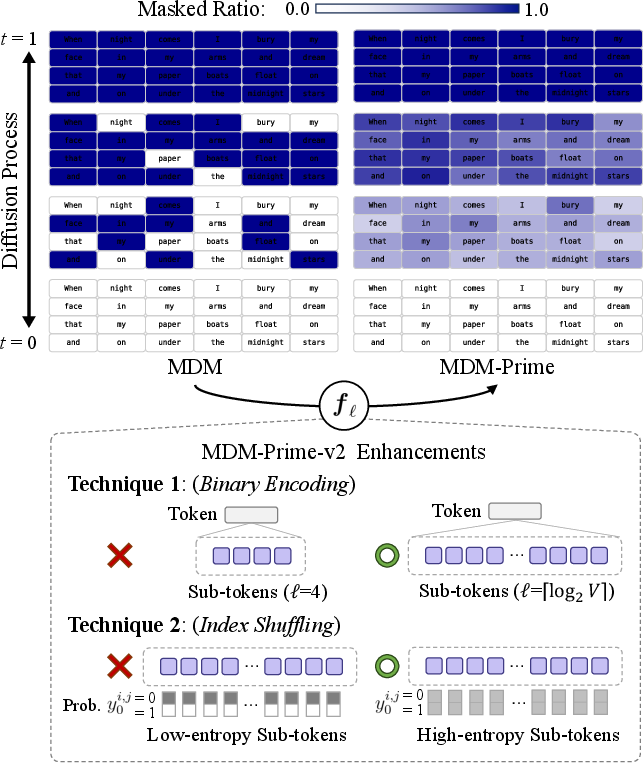
- Tokens and sub-tokens: Computers read text as tokens (like word pieces). MDM-Prime breaks each token into smaller “sub-tokens,” so the model can fill in missing pieces more gently and precisely—like solving a jigsaw puzzle with smaller pieces, which can make the picture clearer at each step.
- Diffusion with masking: The model starts with a sentence where many tokens are hidden (masked). It then repeatedly guesses and reveals parts of the sentence until it reconstructs the whole thing. More steps with small pieces = more control.
- Perplexity: A score that measures how “confused” a model is when predicting text. Lower is better.
- Compute budget: How much training power you spend (think: total “fuel” like time × hardware).
The two core techniques:
- Binary encoding (choosing the “right” number of sub-tokens)
- Each token has an ID number (like #12345). You can write any number in binary—that’s a string of 0s and 1s.
- The authors show that if you split tokens into the maximum number of sub-tokens so that each sub-token is just a bit (0 or 1), the training objective becomes tighter—meaning the model gets a more accurate learning signal.
- In simple terms: turning each token into a sequence of bits (0s/1s) gives the model small, balanced clues at each step, which helps it learn better.
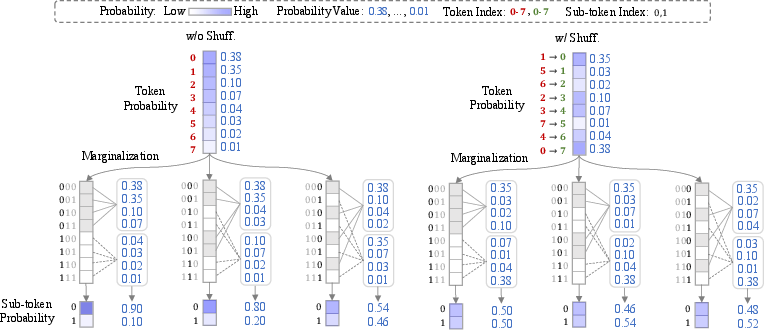
- Index shuffling (making the bits informative)
- Many tokenizers (like GPT-2’s) give low ID numbers to very common tokens and high ID numbers to rare ones. If you turn those IDs straight into bits, the bits can be uneven (for example, too many 0s), which makes learning less effective.
- Index shuffling randomly reassigns the token IDs before turning them into bits. This evens out the 0s and 1s across the dataset, making each sub-token (bit) more unpredictable and informative.
- Everyday analogy: imagine a sports team where the best players all wear low jersey numbers; if you only look at the first digit, you almost always see “0” or “1.” Shuffle the jersey numbers and suddenly that first digit reveals more. The model gets richer clues.
Why these help (intuitively)
- The model’s training objective benefits when each small piece (sub-token) is informative and balanced. Binary encoding creates the smallest, cleanest pieces; shuffling makes those pieces carry more useful information.
- The authors also give a theoretical reason: these choices make the model’s bound on how well it can learn tighter, which typically leads to better performance.
What they found and why it matters
Here are the key results, expressed plainly:
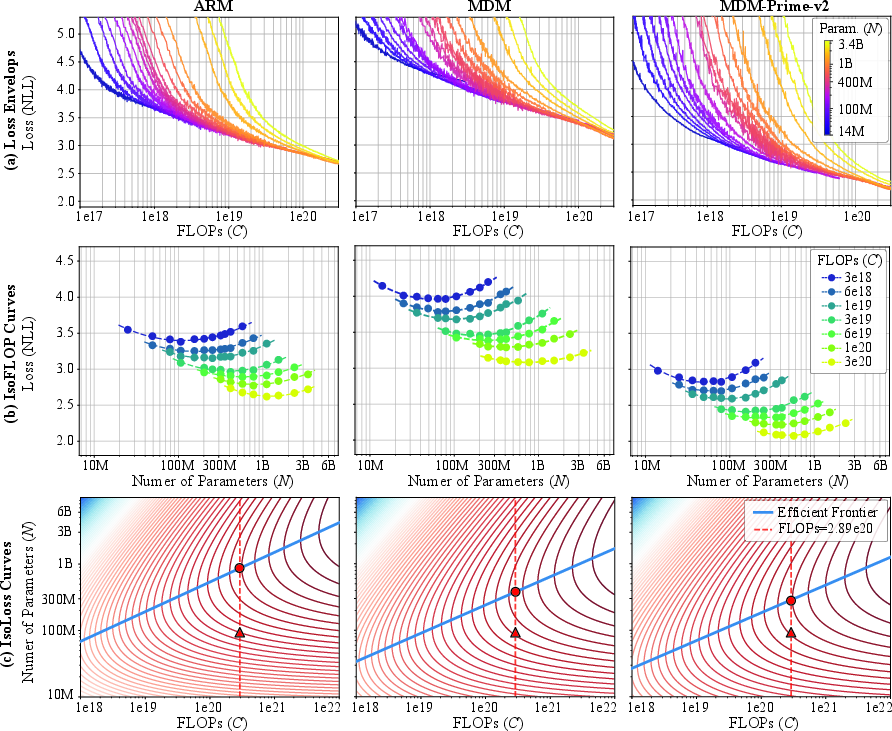
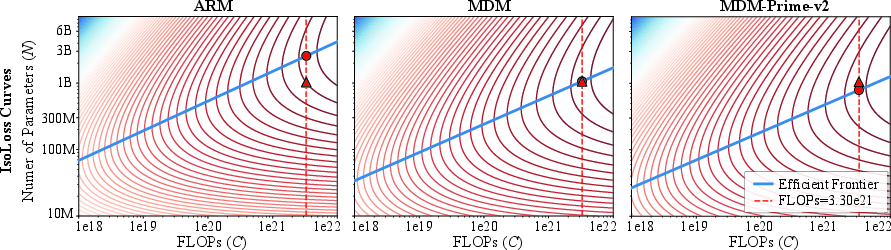
- Much better use of compute: When comparing models fairly under fixed training budgets, MDM-Prime-v2 is about 21.8× more compute-efficient than standard autoregressive models (ARMs). In other words, for the same “fuel,” it gets more learning done.
- Stronger text modeling (lower perplexity): On the OpenWebText dataset, in compute-optimal setups:
- MDM-Prime-v2 achieved perplexity 7.77 (lower is better),
- Beating ARM (12.99), standard MDM (18.94), and the earlier MDM-Prime (13.41).
- Scales well: Across a wide range of model sizes and training amounts, the method keeps improving predictably as you invest more compute—so it’s reliable to scale up.
- Better reasoning at larger size: At around 1.1 billion parameters, MDM-Prime-v2 achieved the best average zero-shot accuracy on several commonsense reasoning benchmarks compared to similar-sized baseline models (like GPT-Neo, OPT, Pythia, Bloom, SMDM, and TinyLLaMA).
Why this is important:
- Diffusion-based LLMs have often lagged behind ARMs in efficiency. This paper shows that with the right sub-token design, diffusion models can not only catch up but surpass ARMs under fair compute comparisons.
- The two tricks—binary encoding and index shuffling—are simple to implement (just look-up tables) and add no extra training cost per step.
What this could lead to
- Cheaper, more efficient training: If models learn more from the same compute, you can train stronger models for less money and energy, or get better results on the same budget.
- Practical guidance for builders: The paper gives clear rules—use full binary splitting for tokens and shuffle indices before encoding. This makes diffusion-style LLMs much easier to tune.
- Rethinking tokenization: It shows that how you number and break down tokens matters a lot. Smarter token handling can boost performance without changing the neural network itself.
- Better generalization: Because the method helps the model learn cleaner signals, it can transfer better to new tasks—useful for real-world applications like question answering and reasoning.
In short: By turning tokens into balanced bits and shuffling their IDs first, this work makes diffusion-based LLMs learn faster and better, helping them compete with—and sometimes beat—the most common language modeling approach today.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues, open questions, and limitations that future work could address.
- Theoretical optimality of index shuffling: The paper shows that maximizing sub-token entropy tightens the bound but uses random permutations as a heuristic. There is no proof or algorithm for finding an entropy-maximizing (or near-optimal) permutation under the empirical token distribution, nor an analysis of how close random shuffling comes to the optimum.
- Learnable subtokenizers: The work does not explore learning the invertible mapping (e.g., via a learnable permutation or structured bijection) to directly maximize or mutual information with , potentially outperforming random shuffling.
- Interaction with tokenizers: Only GPT‑2 BPE is tested. It remains unclear how the approach behaves with Unigram LM/SentencePiece, WordPiece, multilingual tokenizers, or tokenizers with already randomized/hashed indices. Do index shuffling and binary encoding still help, hurt, or become unnecessary?
- Handling of special and reserved tokens: The effect of shuffling on BOS/EOS/unk/pad/control tokens is not discussed. How should these be treated to avoid harming training stability or decoding?
- Non-power-of-two vocabularies: For , binary encoding creates unused codes. The impact of this mismatch on sub-token entropy, training dynamics, and the bound is not analyzed or ablated.
- Quantifying ELBO tightness empirically: Although theory connects higher and higher sub-token entropy to tighter bounds, the paper does not directly measure the ELBO gap (bound tightness) across and shuffling; it reports losses/perplexities only.
- Forward schedule design: The scheduling function is taken as given. Jointly optimizing with to maximize or training signal is not explored, nor are schedule sensitivities and discretization effects.
- Masking independence assumption: The analysis assumes independent masking over sub-tokens and positions. Whether structured/ correlated masking could further tighten the bound or improve efficiency is left unexplored.
- Architecture–granularity interaction: Sub-token embeddings are aggregated to token-level representations, but alternative aggregation schemes (e.g., attention over sub-tokens, learned routing, gating) and their effect on performance/compute are not studied.
- Inference efficiency and latency: Claims of compute optimality focus on training FLOPs. The paper does not report or compare decoding latency, number of reverse steps, throughput, or wall-clock generation efficiency versus ARMs in practical settings.
- Robustness across domains and distributions: Index shuffling is calibrated on the pretraining corpus. Its robustness to domain shift (e.g., scientific, legal, code), multilingual data, and long-tail distributions is not evaluated.
- Broader benchmark coverage: Experiments focus on OWT/C4 and a handful of zero-shot tasks. There is no evaluation on code, math, multilingual, long-context, or instruction-following tasks, limiting conclusions about generality.
- Scaling law stability and uncertainty: The fitted Chinchilla-style exponents determine “compute-optimal” allocations, yet confidence intervals, sensitivity to optimizer/regularization schedules, and robustness across seeds/architectures are not reported.
- Fairness of 1.1B comparisons: The 1.1B results compare to publicly released models with differing data/compute/curricula. Strictly compute- and data-matched comparisons (or controlled ablations) are not provided.
- Effect on token-level tasks: Shuffling breaks the conventional relationship between token ID order and frequency. Impacts on token-level labeling tasks, span prediction, or alignment-dependent evaluations are not assessed.
- Interoperability and tooling: Shuffling alters index–token mappings, which may complicate reuse of pretrained checkpoints, tokenizer interoperability, and dataset/tooling compatibility. Guidelines for deployment and conversion are absent.
- Degree and strategy of shuffling: The paper shows 25% vs 100% shuffling but does not present a principled method to choose shuffling degree or to target shuffling where it maximally increases entropy with minimal side effects.
- Mutual information diagnostics: The argument that shuffling “increases certainty” in is qualitative. Information-theoretic diagnostics (e.g., mutual information per sub-token before/after shuffling) are not reported.
- Stability with large : While setting improves losses, potential optimization instabilities (e.g., gradient variance, convergence speed) and memory/activation trade-offs at large are not analyzed.
- Alternative encodings: Only base‑ (binary) encoding is considered. Other invertible encodings (e.g., Gray codes, structured bit permutations) that might improve locality or denoising dynamics are not explored.
- Reverse process design: The paper adopts the standard carry-over condition and reverse kernel but does not investigate alternative parameterizations or denoisers better suited for large- binary sub-token spaces.
- Multi-objective trade-offs: The work optimizes perplexity; calibration, uncertainty estimation, and human-evaluated generation quality (beyond brief appendix notes) are not systematically studied.
- Curriculum over : Given , staged training that gradually increases (curriculum) could stabilize or accelerate training; this possibility is not examined.
- Combination with order-specific methods: The interaction of MDM-Prime-v2 with block or partially autoregressive schemes (e.g., BD3-LM) is not evaluated; potential synergies remain unknown.
Glossary
- Autoregressive models (ARM): A language modeling paradigm that factorizes the joint likelihood into a product of conditional probabilities and generates tokens sequentially. Example: "Autoregressive models (ARM) (e.g., \cite{radford2019language,touvron2023llama})"
- Base- encoding: Representing token indices in base so they can be decomposed into sub-tokens, enabling partial masking at the sub-token level. Example: "MDM-Prime employs standard base- encoding for "
- Binary Encoding: Encoding each token index into its binary representation by setting , maximizing sub-token granularity. Example: "Technique 1. (Binary Encoding) Select such that encodes tokens into binary sub-tokens."
- Byte-Pair Encoding (BPE) tokenizer: A subword tokenization method that iteratively merges frequent character pairs to form a fixed-size vocabulary of tokens. Example: "Text is mapped to discrete random variables (tokens) via Byte-Pair Encoding (BPE) tokenizer, following the standard practice of GPT~\cite{radford2019language} and LLaMA~\cite{touvron2023llama}."
- Carry-over condition: A constraint on the denoising model ensuring that already unmasked positions are deterministically preserved. Example: "satisfying the carry-over condition~\cite{sahoo2024simplifieddiff}"
- Change-of-variable principle: A probabilistic equivalence indicating that invertible reparameterizations (e.g., token→sub-token) leave the NLL invariant. Example: "the change-of-variable principle indicates that the NLL is invariant:"
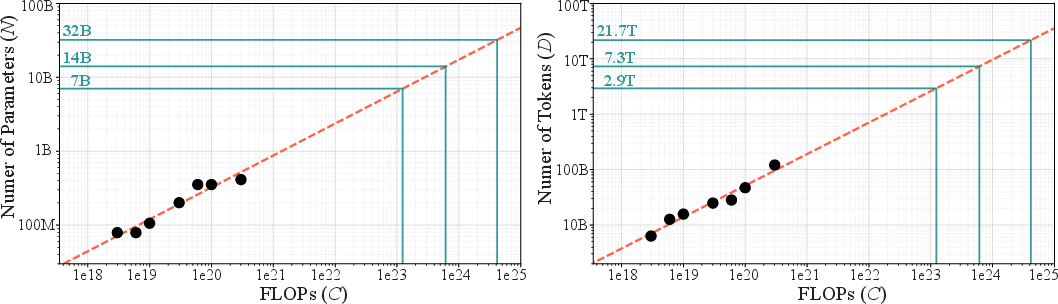
- Chinchilla scaling law: An empirical relation describing how optimal parameter and data allocations minimize loss under fixed compute for LLMs. Example: "we employ the Chinchilla scaling law~\cite{hoffmann2022chinchilla} to analyze loss behavior."
- Conditional (predictive) distribution: The distribution over original tokens given partially observed (masked/unmasked) sub-tokens during denoising. Example: "Conditional (predictive) distribution: The distribution exhibits higher certainty under index shuffling"
- Compute-optimal: Refers to model and data configurations that minimize loss for a fixed compute budget. Example: "In compute-optimal comparisons, MDM-Prime-v2 achieves 7.77 perplexity on OpenWebText, outperforming ARM (12.99), MDM (18.94), and MDM-Prime (13.41)."
- CTMC: Continuous-Time Markov Chain–based discrete diffusion framework for generative modeling. Example: "CTMC~\cite{campbell2022ctmc}"
- D3PM: Denoising Diffusion Probabilistic Models for discrete state spaces. Example: "D3PM~\cite{austin2021structurediff}"
- Diffusion Transformer (DiT): A Transformer architecture adapted for diffusion modeling. Example: "a diffusion transformer (DiT)~\cite{Peebles2022DiT}"
- Efficient frontier: The set of (parameters, tokens) pairs that achieve the lowest loss for a given compute, beyond which improvements are suboptimal. Example: "the solid blue line denotes the efficient frontier"
- Entropy (sub-token entropy): The uncertainty of sub-token distributions; higher sub-token entropy tightens the variational bound. Example: "a technique to enhance sub-token entropy, called index shuffling."
- FLOPs: Floating point operations; used as a measure of training compute. Example: "By varying compute budgets from to FLOPs"
- Forward diffusion process: The noising process that stochastically masks tokens/sub-tokens according to a schedule. Example: "The forward diffusion process is performed through a kernel"
- GPT-2 tokenizer: A specific BPE-based tokenizer used to map text into token indices. Example: "The dataset is tokenized using the GPT-2 tokenizer with a vocabulary size of ."
- Index Shuffling: A permutation of token indices prior to encoding that increases sub-token entropy and improves likelihood estimation. Example: "Technique 2.~(Index Shuffling) Randomly shuffle the token indices before performing base- encoding."
- IsoFLOP curves: Contours of constant compute used to analyze performance trade-offs across model/data scales. Example: "The (a) loss envelops, (b) isoFLOP curves, and (c) isoloss curves"
- Isoloss curves: Contours of constant loss visualized to understand scaling behavior across parameters and tokens. Example: "The (a) loss envelops, (b) isoFLOP curves, and (c) isoloss curves"
- Joint entropy: The entropy of the joint distribution of original and noised variables; an -independent term in the variational bound. Example: "represent the entropy of and the joint entropy of , respectively."
- KL divergence: A measure of distributional difference; equality conditions in the bound require it to be zero. Example: "The equality condition Eq.~(\ref{eq:kl_condition}) requires the KL divergence to be zero"
- Kronecker delta function: A function equal to 1 when its arguments match and 0 otherwise, used to define discrete kernels. Example: "Let be the Kronecker delta function, which equals $1$ if and $0$ otherwise."
- Latent variable: The masked sequence produced by the forward diffusion process on which denoising is conditioned. Example: "denotes the latent variable introduced by the forward diffusion process"
- Likelihood-based pretraining: Training by maximizing data likelihood (or minimizing NLL) to scale language modeling. Example: "Likelihood-based pretraining serves as the cornerstone of scalable language modeling"
- Masked Diffusion Models (MDM): Discrete diffusion LLMs that reconstruct data from masked sequences via denoising. Example: "Masked diffusion models (MDM) exhibit superior generalization"
- MDM-Prime: An MDM variant that encodes tokens into sub-tokens to enable partial masking as intermediate latent representations. Example: "MDM-Prime introduces a richer set of intermediate latent representations via partially masked tokens."
- MDM-Prime-v2: An enhanced MDM-Prime that uses Binary Encoding and Index Shuffling for improved compute efficiency. Example: "we develop MDM-Prime-v2, a masked diffusion LLM which incorporates Binary Encoding and Index Shuffling."
- Negative log-likelihood (NLL): The training objective corresponding to the negative log probability assigned to data. Example: "The negative log-likelihood (NLL) of the data distribution "
- Order-Agnostic Models: Models that do not depend on a specific generation order for tokens. Example: "Order-Agnostic Models"
- Perplexity (PPL): A standard metric for LLMs defined as the exponential of NLL. Example: "We compare performance using perplexity (PPL) (i.e., exponential of NLL)"
- QK-normalization: A normalization technique applied to Query/Key in attention for stability and scaling. Example: "QK-normalization~\cite{dehghani2023qknorm}"
- Reverse diffusion process: The iterative denoising process that reconstructs the original sequence from masked inputs. Example: "The reverse diffusion process is performed by iteratively applying "
- RoPE: Rotary Positional Embeddings used to encode position information in Transformers. Example: "RoPE~\cite{su2023roformerenhancedtransformerrotary}"
- Subtokenizer: An invertible mapping from tokens to a sequence of sub-tokens that enables partial masking. Example: "an invertible function $f_\ell:X\toY^{\ell}$, known as subtokenizer"
- SwiGLU: A gated activation function variant improving Transformer training and performance. Example: "SwiGLU~\cite{shazeer2020gluvariantsimprovetransformer}"
- Token granularity: The number of sub-tokens per token, controlling the resolution of partial masking. Example: "Given the token granularity , MDM-Prime~\cite{chao2025mdmprime} represents each token"
- Variational bound: An upper bound on NLL used for training diffusion models, whose tightness affects performance. Example: "we study the tightness of the variational bound in MDM-Prime"
- Zero-shot: Evaluation without task-specific fine-tuning, directly testing generalization. Example: "zero-shot commonsense reasoning benchmarks."
Practical Applications
Overview
The paper introduces MDM-Prime-v2, a masked diffusion LLM that improves likelihood estimation and compute efficiency via two practical techniques:
- Binary Encoding: set token granularity to so tokens are represented as binary sub-tokens.
- Index Shuffling: permute (shuffle) tokenizer indices before base- encoding to maximize sub-token entropy.
These innovations tighten the variational bound, yield better perplexity than autoregressive models (ARMs) under compute-optimal settings, and shift optimal training toward using more tokens (data) rather than more parameters, enabling more compute-efficient pretraining. Below are concrete applications and workflows derived from these findings.
Immediate Applications
The following applications can be realized with current tools and minor changes to training pipelines.
- Industry (Software/AI platforms): Lower-cost pretraining and fine-tuning of LLMs
- What: Adopt MDM-Prime-v2 to reduce total FLOPs for a target perplexity and improve zero-shot performance on commonsense tasks, especially in compute-constrained settings.
- Sectors: Software, cloud AI services, enterprise AI, MLOps.
- Tools/Workflows:
- Integrate an index-shuffling lookup table into the tokenizer pipeline (e.g., extend Hugging Face tokenizers) and enable binary subtokenization within the embedding layer.
- Adjust training recipes to follow compute-optimal allocation (more tokens D vs parameters N) using Chinchilla-like scaling estimates.
- Provide “Diffusion-LM pretraining as a service” SKUs optimized for tokens-heavy regimes.
- Assumptions/Dependencies:
- Requires training (or re-training) models with the shuffled index map consistently used in preprocessing, training, and inference.
- Gains are shown for BPE-like tokenizers; results may vary with other tokenization schemes and domains.
- Inference latency for diffusion models may be higher than ARMs unless paired with fast sampling strategies.
- Academia and ML Research: Standardized scaling experiments and curricula
- What: Use the paper’s scaling analysis and tightness-of-bound results to teach/practice compute-optimal training and tokenizer–model interaction effects.
- Sectors: Education, ML research labs.
- Tools/Workflows:
- Course labs demonstrating how setting and shuffling indices increases sub-token entropy and improves likelihood.
- Reproduce isoFLOP/isoloss curves and derive optimal N–D splits for student projects.
- Assumptions/Dependencies:
- Requires access to mid-scale compute and public corpora (e.g., OWT/C4).
- Tokenizer index shuffling must remain invertible and consistent across experiments.
- Data Center and Cloud Operations: Energy and cost reduction in model training
- What: Lower energy per performance (e.g., PPL) by training diffusion LMs that are more compute-efficient than ARMs at comparable budgets.
- Sectors: Energy-conscious HPC, cloud providers.
- Tools/Workflows:
- Introduce an “entropy-aware tokenization” step (index shuffling) during data ingestion.
- Shift capacity planning toward longer training runs (larger D) with moderate model sizes (N), aligned with observed /.
- Assumptions/Dependencies:
- Requires rigorous MLOps to maintain the shuffled index map across distributed preprocessing and inference services.
- Energy gains depend on sustained training throughput and availability of large, compliant datasets.
- Domain-specialized LMs with smaller budgets
- What: Train performant domain LMs (e.g., legal, biomedical, support) with limited compute by exploiting MDM-Prime-v2’s efficiency.
- Sectors: Healthcare, legal, finance, customer support.
- Tools/Workflows:
- Plug-in index shuffling and binary subtokenization into existing training code; focus budget on more tokens from curated domain corpora.
- Use the provided scaling guidance to choose near-optimal N–D configurations for each budget.
- Assumptions/Dependencies:
- Requires high-quality, legally compliant domain datasets; the approach benefits most when ample data is available.
- Must maintain index-map compatibility across pretraining and downstream fine-tuning.
- Evaluation and Benchmarking Services
- What: Provide fair, compute-optimal comparisons across LM families (ARM vs diffusion) using isoFLOP/isoloss frontiers.
- Sectors: AI benchmarking, consulting.
- Tools/Workflows:
- Offer standardized reports with fitted scaling laws, frontier lines, and compute-optimal configurations for clients/models.
- Assumptions/Dependencies:
- Frontier positions depend on corpora, architectures, and optimizers; results generalize best when matched conditions are enforced.
- Open-source community models and teaching assistants
- What: Release community MDM-Prime-v2 checkpoints and training recipes so smaller groups can achieve strong zero-shot performance.
- Sectors: Education, non-profits, civic tech.
- Tools/Workflows:
- Public scripts for index-shuffle table generation, entropy diagnostics, and binary subtoken embedding adapters.
- Assumptions/Dependencies:
- Community adoption requires robust documentation and compatibility with popular frameworks (PyTorch, HF Transformers).
Long-Term Applications
These applications require further research and/or engineering work (e.g., inference acceleration, broader modality coverage, or deployment validation).
- Production conversational systems with diffusion LMs
- What: Bring MDM-Prime-v2 to latency-sensitive applications by combining with fast sampling (e.g., fewer denoising steps, block diffusion, or hybrid AR–diffusion decoders).
- Sectors: Software, customer service, education technology.
- Potential Products:
- Hybrid decoders that exploit diffusion’s parallel unmasking for drafts and ARMs for final refinements or safety filtering.
- Assumptions/Dependencies:
- Needs inference-time speedups to match or beat ARMs in latency.
- Requires safety/tuning pipelines adapted to diffusion generation dynamics.
- Cross-domain discrete diffusion: code, speech units, and tokenized vision
- What: Apply the high-entropy sub-token principle (binary encoding + shuffling) to other discrete-token modalities (code tokens, speech units, VQ tokens for images/video).
- Sectors: Software engineering, speech, multimedia.
- Potential Tools:
- Entropy-aware tokenizers for code (e.g., BPE/Unigram) with shuffled indices to improve diffusion model perplexity/error rates.
- Assumptions/Dependencies:
- Must validate entropy gains and variational bound improvements per modality/tokenizer.
- May require modality-specific forward/reverse processes and training tricks.
- Federated or on-device continual training of smaller LMs
- What: Exploit compute-efficient training to enable periodic on-device or federated updates to small diffusion LMs.
- Sectors: Mobile, IoT, privacy tech.
- Potential Workflows:
- Periodic federated rounds with index-shuffle-consistent tokenization and binary subtokenization for efficient updates.
- Assumptions/Dependencies:
- Inference cost and device memory constraints remain key challenges.
- Requires secure aggregation and privacy controls.
- “Entropy-optimized tokenization” services and auto-design tools
- What: Automated design of index permutations that maximize sub-token entropy given a tokenizer and corpus; dynamic or domain-adaptive shuffling.
- Sectors: MLOps, tooling vendors.
- Potential Products:
- A toolkit that measures sub-token entropy and proposes optimal index maps; CI checks to guard against accidental index-map drift.
- Assumptions/Dependencies:
- Must ensure invertibility and stability across domains and updates.
- Coordination with checkpoint/versioning required to prevent mismatch.
- Green AI policy and procurement frameworks
- What: Use compute-optimal frontiers to guide funding and procurement (allocate budgets toward more data vs larger models, when appropriate).
- Sectors: Public sector, R&D funders, compliance.
- Potential Actions:
- Require reporting of isoFLOP/isoloss analyses, coefficients, and carbon-per-performance metrics in grant applications.
- Assumptions/Dependencies:
- Frontier parameters are dataset- and architecture-dependent; governance must standardize measurement protocols.
- Safety and evaluation research with order-agnostic LMs
- What: Study calibration, uncertainty, and robustness of diffusion LMs in high-stakes settings (e.g., medical triage assistants, scientific QA).
- Sectors: Healthcare, science, safety labs.
- Potential Workflows:
- Benchmarks that extend beyond perplexity to safety, faithfulness, and calibration, tailored for diffusion generation dynamics.
- Assumptions/Dependencies:
- Requires new evaluation rubrics aligned with diffusion sampling behaviors and parallel unmasking.
- Interoperability with existing ARM ecosystems
- What: Explore training curricula that leverage ARM checkpoints for initialization or distillation to diffusion LMs and vice versa.
- Sectors: Software, research labs.
- Potential Workflows:
- Mixed-regime training (e.g., ARM bootstrapping, then diffusion fine-tuning with entropy-optimized tokenization).
- Assumptions/Dependencies:
- Index shuffling breaks raw ID compatibility; mapping-aware distillation or joint tokenization strategies will be needed.
In all cases, the key dependencies to watch are: consistent use of the index-shuffling map end-to-end, validation on the target tokenizer and domain, careful balancing of parameters and tokens for the available compute, and addressing inference-speed gaps for latency-sensitive deployments.
Collections
Sign up for free to add this paper to one or more collections.

