You've Got a Golden Ticket: Improving Generative Robot Policies With A Single Noise Vector
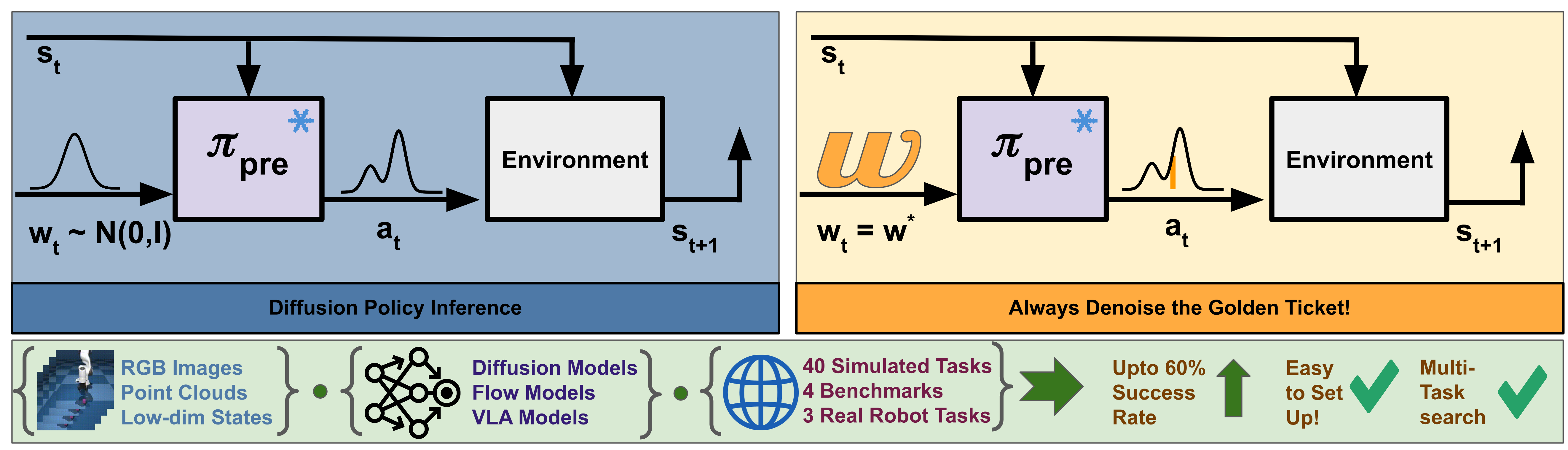
Abstract: What happens when a pretrained generative robot policy is provided a constant initial noise as input, rather than repeatedly sampling it from a Gaussian? We demonstrate that the performance of a pretrained, frozen diffusion or flow matching policy can be improved with respect to a downstream reward by swapping the sampling of initial noise from the prior distribution (typically isotropic Gaussian) with a well-chosen, constant initial noise input -- a golden ticket. We propose a search method to find golden tickets using Monte-Carlo policy evaluation that keeps the pretrained policy frozen, does not train any new networks, and is applicable to all diffusion/flow matching policies (and therefore many VLAs). Our approach to policy improvement makes no assumptions beyond being able to inject initial noise into the policy and calculate (sparse) task rewards of episode rollouts, making it deployable with no additional infrastructure or models. Our method improves the performance of policies in 38 out of 43 tasks across simulated and real-world robot manipulation benchmarks, with relative improvements in success rate by up to 58% for some simulated tasks, and 60% within 50 search episodes for real-world tasks. We also show unique benefits of golden tickets for multi-task settings: the diversity of behaviors from different tickets naturally defines a Pareto frontier for balancing different objectives (e.g., speed, success rates); in VLAs, we find that a golden ticket optimized for one task can also boost performance in other related tasks. We release a codebase with pretrained policies and golden tickets for simulation benchmarks using VLAs, diffusion policies, and flow matching policies.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “You’ve Got a Golden Ticket: Improving Generative Robot Policies With A Single Noise Vector”
What is this paper about?
This paper asks a surprising question: What if we can make a pretrained robot smarter just by changing one number at its starting point—without retraining it? Many modern robot controllers use “generative” models (like diffusion models) that start from random noise and then refine it into an action plan. The authors show that if you replace the usual random noise with one well-chosen fixed noise vector—what they call a “golden ticket”—the same robot policy can perform better on many tasks.
What were the main goals?
The researchers wanted to:
- See if fixing the initial noise to a special, constant value could improve how well a robot performs tasks.
- Find a simple way to discover these “golden tickets” without retraining the robot’s model or building new helper networks.
- Test whether this idea works across many kinds of models and tasks, including real robots, and whether one golden ticket can sometimes help with more than one task.
How did they do it? (Methods, in everyday terms)
Modern generative robot policies (like diffusion or flow matching models) plan actions by:
- Starting from random noise (think of this as a scrambled starting point).
- “Denoising” step by step to produce a sequence of actions for the robot.
Usually, the model rolls virtual dice to pick new random noise each time it needs to plan. The authors tried something different: use the same fixed noise vector every time—if it’s the right one—so the robot tends to produce better behaviors consistently.
How do you find that right one? They used a simple “try lots and keep the best” approach:
- Generate many candidate noise vectors (like trying lots of starting “seeds”).
- For each one, run the robot through episodes in the task and measure how well it does (the reward or success rate).
- Pick the noise vector that gets the best average performance and use that as the golden ticket.
This process is called random search with Monte Carlo evaluation:
- “Random search” means you try many random candidates.
- “Monte Carlo” means you estimate how good each candidate is by actually running it multiple times and averaging the results.
Key points about their approach:
- The robot’s model stays frozen (no retraining).
- No extra helper network is needed.
- You only need to be able to set the initial noise and measure success or reward.
- It works like a black-box trick and can be used with many kinds of generative policies, including VLAs (Vision-Language-Action models).
Analogy: Imagine a video game character that behaves differently depending on a hidden “starting mood.” The game normally picks a random mood every time. The authors discovered that if you find the one “best mood” and reuse it, the character plays much better without changing any game code.
What did they find, and why does it matter?
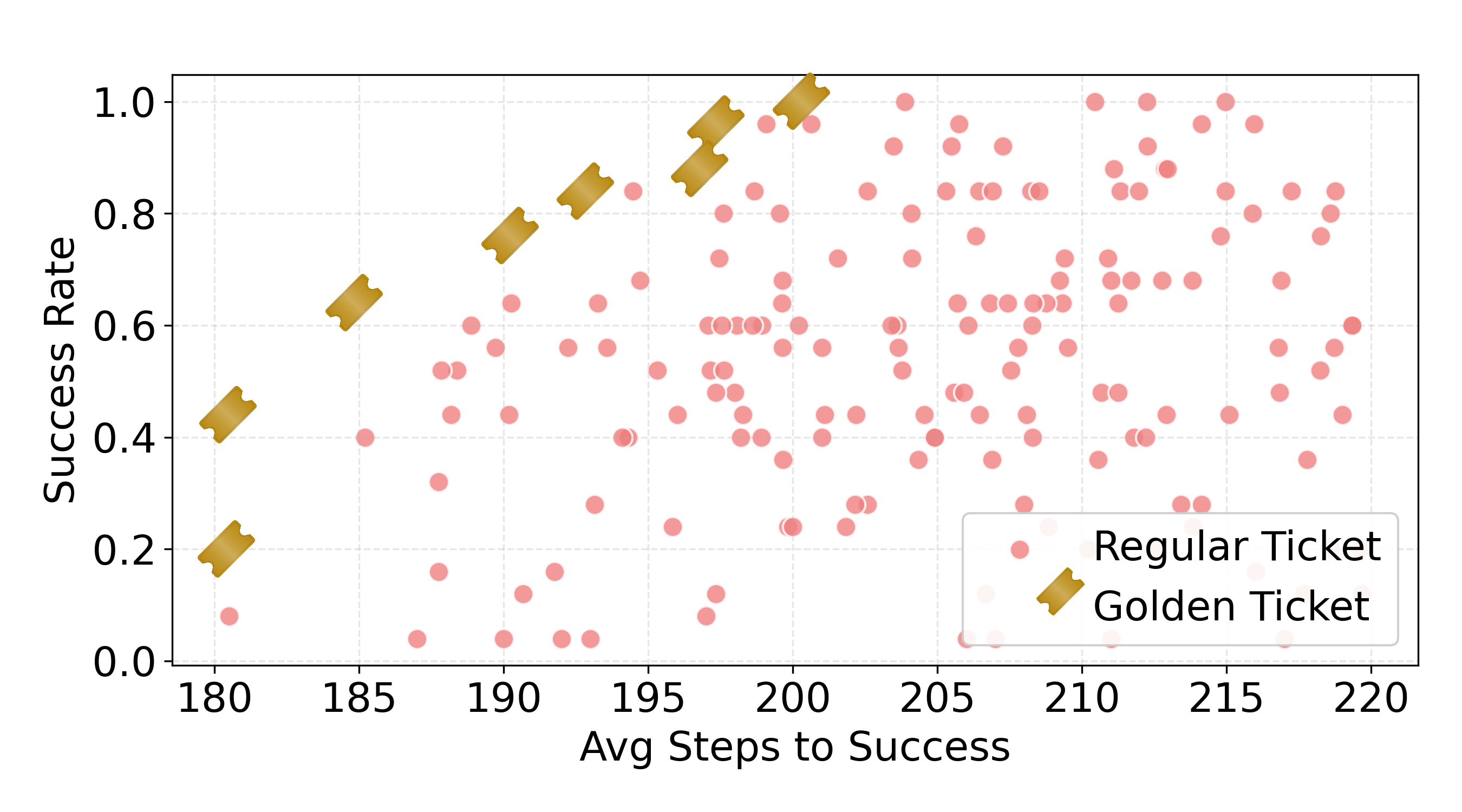
Across many tests—both in simulation and on real robot arms—the golden ticket idea worked surprisingly well.
Here are the highlights:
- It worked in 38 out of 43 tasks: In most tasks, a golden ticket beat the usual “random noise every time” approach.
- Big improvements: In some simulated tasks, success rates improved by up to 58%. On real robots, they saw up to a 60% improvement in a pushing task and an 18% improvement in a picking task after relatively few test episodes.
- Works widely: They tested different policy types (diffusion and flow matching), different inputs (images, point clouds, low-dimensional states), single- and multi-task settings, and even large VLAs. The idea held up across the board.
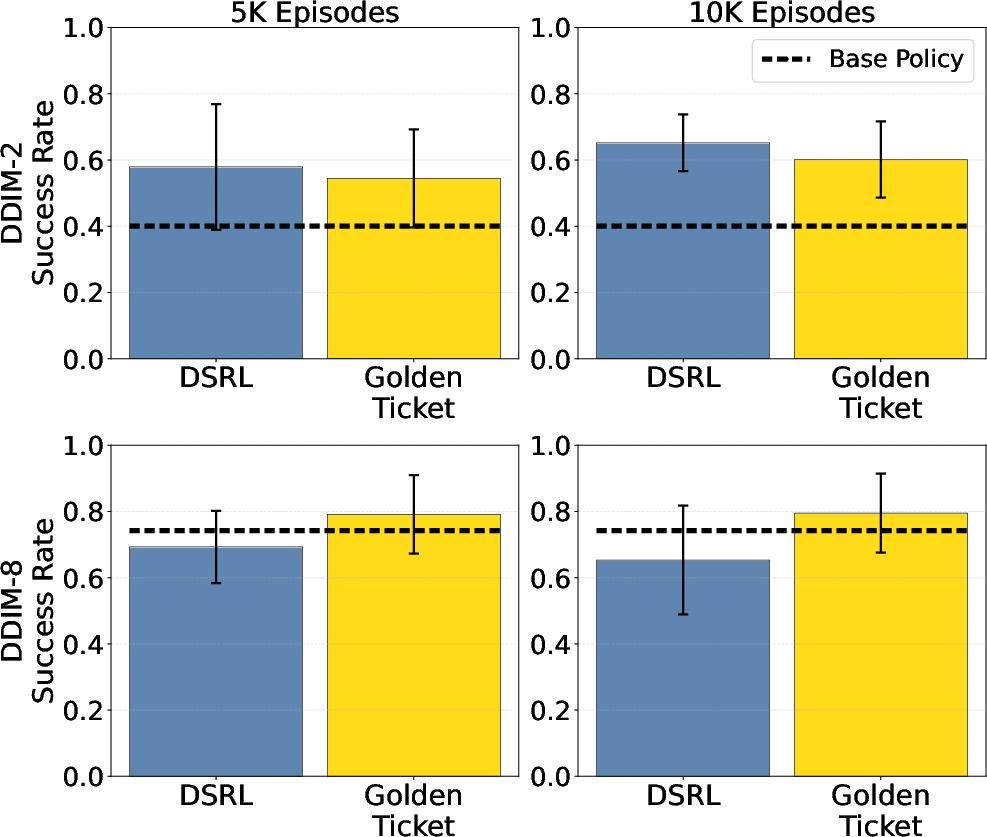
- Competitive with advanced methods: Their simple search approach performed on par with a state-of-the-art method that uses reinforcement learning to steer the noise—without the extra training or complicated design choices.
- Multi-task bonuses:
- Sometimes, a golden ticket found for one task also helped related tasks in the same family (e.g., within a set of similar LIBERO tasks).
- Different tickets naturally produced different trade-offs (like “faster but riskier” vs. “slower but safer”). These trade-offs formed a Pareto frontier—meaning you could pick a ticket based on whether you value speed or reliability more, without having to redesign rewards or retrain anything.
Why is this important?
- Faster, simpler improvements: You can make a robot policy better without retraining large models, which can be slow, expensive, and tricky.
- Plug-and-play: Because the method treats the policy like a black box, it’s easy to try on many existing systems.
- Practical for real robots: The team showed it works on physical robot arms with camera and point cloud inputs, not just in simulations.
- Flexible behavior control: By collecting a few different golden tickets, you can switch robot “styles” on the fly—prioritizing speed or success—without touching the model.
Final takeaway
The paper introduces a clever, low-cost way to improve robot performance: choose a special fixed “starting noise” for generative policies. This “golden ticket” approach boosts success in many tasks, can generalize across related tasks, and offers an easy way to balance different goals like speed and reliability. It’s a simple idea with big practical impact—helping robots do better without the headache of retraining big models.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and can guide future research:
- Determinism and loss of exploration: Quantify how replacing stochastic noise with a single constant vector affects robustness, exploration, and recovery from disturbances; develop ways to reintroduce calibrated stochasticity (e.g., mixing Gaussian noise, sampling from a small set of tickets) without degrading performance.
- Sample efficiency of ticket search: The current random search can require many rollouts (e.g., thousands of tickets × many environments). Evaluate more sample-efficient black-box optimizers (e.g., CMA-ES, Bayesian optimization, cross-entropy method, evolution strategies, bandits) and compare episode budgets and success.
- Offline proxies for ticket quality: Identify offline or low-cost metrics (e.g., denoiser internal activations, action entropy, noise inversion stability, trajectory-level priors) that predict ticket performance to reduce on-policy rollouts.
- Theory of steerability: Formalize conditions under which a single fixed initial noise can increase expected return, characterize the prevalence, uniqueness, and basins of attraction of “golden” tickets, and relate them to the score/flow landscape and policy multimodality.
- Generalization vs. overfitting: Develop principled validation protocols and regularization to ensure tickets found on a search set transfer to unseen states, scenes, and tasks; provide statistical guarantees or confidence intervals for generalization performance.
- Sensitivity to generative inference settings: Systematically study how ticket effectiveness depends on sampler (e.g., DDIM steps and schedules), guidance scales, action horizon/chunk length, and flow/diffusion parameterizations.
- Robustness to sensory and dynamics shifts: Measure how ticket performance degrades under observation noise, camera pose changes, lighting, latency, friction/contact variations, and other real-world nonstationarities.
- Task-conditioned selection for multi-task policies: Design mechanisms to automatically select tickets per instruction/task (e.g., a small learned codebook of tickets with a selector) while retaining the simplicity of observation-agnostic control.
- Cross-task performance limits: Since no single ticket improved every task in a suite, investigate mixtures/ensembles of tickets, stochastic ticket policies, or gating mechanisms that can maintain or improve average performance across tasks.
- Reward dependence and availability: Address scenarios with sparse, delayed, or hard-to-measure rewards by developing self-supervised success detectors, learned reward models, or preference-based feedback compatible with ticket search.
- Safety during search: Introduce safe-exploration constraints, shielding, or human-in-the-loop oversight so that ticket search on hardware avoids unsafe trajectories while still discovering high-reward tickets.
- Access assumptions and applicability: Many deployed policies may not expose an initial-noise interface. Devise methods to inject or approximate ticket control for models without explicit noise inputs (e.g., certain autoregressive or deterministic controllers).
- Real-world scope and complexity: Validate on broader, long-horizon, contact-rich, deformable, or mobile manipulation tasks at scale, and report search budgets, time, and wear-and-tear to establish practical feasibility.
- Diversity vs. mode collapse: Assess whether a single ticket collapses policy behavior to a narrow mode; design strategies to retain behavioral diversity (e.g., ticket ensembles, entropy-promoting selection) while improving returns.
- Interpretability and structure of tickets: Probe what directions in noise space correspond to which skills or motion styles, identify low-dimensional subspaces or disentangled factors, and develop visualization and semantic attribution tools.
- Combining with other improvement methods: Explore synergies between golden tickets and weight fine-tuning, residual policies, or observation-conditioned noise policies (e.g., use tickets as priors/initialization for DSRL-like methods).
- Online adaptation and drift handling: Develop controllers that monitor ticket performance over time, detect distribution shifts, and trigger rapid re-search or robust switching among a small set of validated tickets (with hysteresis to avoid oscillations).
- Pareto-frontier exploitation: Automate extraction of Pareto-optimal ticket sets for multi-objective trade-offs (e.g., success vs. speed) and design preference-aware selectors with guarantees on trade-off realization.
- Budget allocation strategy: Provide principled methods (e.g., adaptive allocation, bandit-based early stopping) to trade off number of tickets vs. number of search environments for a fixed compute/episode budget.
- Noise dimensionality and priors: Study how the dimension and scaling of the initial noise, alternative prior distributions, and normalization choices impact the search landscape and success rates.
- Time-varying or phase-dependent tickets: Evaluate whether using different tickets across action chunks or task phases (or scheduled mixing) outperforms a single constant vector.
- Uncertainty calibration and failure detection: With reduced stochasticity, develop mechanisms to detect out-of-distribution states or impending failure and trigger fallback policies or safer tickets.
- Performance guarantees: Seek formal bounds or probabilistic guarantees on improvement over Gaussian sampling under assumptions about dynamics, reward structure, and policy class.
- Ticket transfer across embodiments and environments: Systematically study when and how tickets transfer between similar robots, grippers, or scenes, and what adaptations (e.g., re-scaling, fine-tuning) are needed.
- Automating hardware deployment: Reduce human overhead in reward measurement (e.g., vision-based success classifiers), and quantify/limit mechanical wear during search.
- Reproducibility and stability: Analyze sensitivity to random seeds, simulator versions, and dataset differences; establish standardized evaluation protocols and benchmarks for ticket search.
- Detecting and avoiding adversarial tickets: Develop diagnostics to identify tickets that reliably induce failures or unsafe behaviors and incorporate safeguards to exclude them.
- Deployment footprint: Quantify runtime/memory overhead of storing and switching among ticket libraries, and measure latency implications for embedded/onboard control.
Practical Applications
Immediate Applications
The method replaces random Gaussian noise in diffusion/flow robot policies with a single, well-chosen “golden ticket” noise vector found via lightweight Monte‑Carlo search. It requires only (a) the ability to inject initial noise, and (b) a task reward computed from rollouts, with no weight updates or auxiliary networks.
- Industrial robot cell “commissioning boost” for pick, place, push, and assembly
- Sectors/stakeholders: Robotics, manufacturing, logistics/warehousing; Operations teams, system integrators
- What it enables: At deployment time, run a short on-cell search (tens–hundreds of episodes) to find a golden ticket that increases success rate without retraining (paper reports up to 58% simulated and 60% on hardware for some tasks).
- Tools/workflows: “Golden Ticket Optimizer” that runs during station commissioning; Ticket registry stored per task/SKU; A/B evaluation harness on held-out initial states.
- Assumptions/dependencies: Policy must be diffusion/flow/VLA with exposed initial-noise input; a binary or sparse reward must be available (e.g., success sensor, vision check); safe rollout limits and stop conditions must be enforced during search; results may overfit if not validated on held-out states.
- Throughput vs. reliability “mode switch” using Pareto-optimal tickets
- Sectors/stakeholders: Robotics/operations; Production managers
- What it enables: Select among pre-computed tickets that trade off speed and success (as observed in the paper’s Pareto frontier). Operators can choose “fast” or “safe” modes without reward reweighting or retraining.
- Tools/workflows: Control UI slider mapping to ticket ID; Shift schedules that auto-select tickets for peak/off-peak; On-shift validation tests.
- Assumptions/dependencies: Must precompute and validate Pareto tickets in target environment; environment drift can shift the frontier—periodic re-validation required.
- Rapid on-hardware adaptation for SKU/layout changes
- Sectors/stakeholders: Warehousing, e-commerce fulfillment, flexible manufacturing
- What it enables: When a bin layout, object set, or fixture changes, run a brief search to recover or improve success without sending models to the cloud for retraining.
- Tools/workflows: “Changeover” procedure that launches ticket search on a small set of representative start states; Ticket-per-layout library.
- Assumptions/dependencies: Reliable success checks; safety envelope and time budget for search; steerable base policy.
- VLA-based multi-task robot performance tuning without fine-tuning weights
- Sectors/stakeholders: Robotics R&D groups, lab automation
- What it enables: For VLAs (e.g., SmolVLA), ticket search on one task can lift success in related tasks; teams can curate a library of cross-task tickets to raise baseline performance.
- Tools/workflows: Task suite–aware ticket bank; Task-to-ticket mappings learned from validation.
- Assumptions/dependencies: Cross-task transfer depends on similarity; may not yield suite-wide gains—best used per task or task family.
- Field service and agriculture robots: quick robustness “touch‑up”
- Sectors/stakeholders: Agriculture, infrastructure inspection/maintenance
- What it enables: Short ticket searches in situ (morning/evening light, seasonal changes) to regain performance.
- Tools/workflows: Scheduled ticket refresh; Safety-supervised trials; Rollout budget caps.
- Assumptions/dependencies: Reliable, cheap success signals (e.g., vision); environmental variability must be within the policy’s training support.
- Deterministic, auditable operating modes for safety/compliance
- Sectors/stakeholders: Regulated industries (medical devices, automotive manufacturing), quality assurance teams; Policymakers/regulators
- What it enables: Each golden ticket defines a deterministic behavior mode (given fixed sampler); organizations can certify and audit a finite set of ticketed modes without touching model weights.
- Tools/workflows: Signed ticket catalogs; Mode-based validation protocols; Traceability linking ticket IDs to acceptance tests.
- Assumptions/dependencies: Determinism requires fixed sampler/inference settings; vendors must expose initial-noise APIs; safety monitors must bound exploration during ticket discovery.
- Cost and energy savings vs. retraining
- Sectors/stakeholders: Software/IT operations, sustainability leads
- What it enables: Avoids retraining large VLAs or diffusion policies for incremental gains; cuts cloud/compute costs and emissions.
- Tools/workflows: Ticket search pipelines integrated into DevOps/MLOps; Budget-aware search stopping rules.
- Assumptions/dependencies: Episode search cost must be acceptable; requires test-time access to robot/simulator.
- Education and rapid prototyping in academic labs
- Sectors/stakeholders: Academia, teaching labs, student teams
- What it enables: Hands-on demonstration of latent steering without RL infrastructure; faster iteration for class projects and prototypes.
- Tools/workflows: Course modules using the released codebase; Benchmarks with built-in ticket search.
- Assumptions/dependencies: Robots/simulators instrumented for reward; diffusion/flow policies in curricula.
- Consumer/home robots personalization
- Sectors/stakeholders: Consumer robotics; Daily life users
- What it enables: In-home ticket searches personalize behaviors to specific kitchens, counters, or habits (e.g., “gentle handling” ticket vs. “quick tidy-up” ticket).
- Tools/workflows: Mobile app that runs short calibration routines to select tickets; Mode switching per user preference.
- Assumptions/dependencies: Consumer devices must leverage diffusion/flow policies and provide safe, guided search; privacy considerations for home data.
- Ticket libraries distributed with products and across fleets
- Sectors/stakeholders: Robot OEMs, fleet operators
- What it enables: Ship devices with a curated set of tickets for common environments and SKUs; fleet analytics identify when to switch or refresh tickets.
- Tools/workflows: Ticket versioning, OTA distribution, fleet-wide A/B testing; Health monitoring triggers.
- Assumptions/dependencies: Robust metadata (environment tags, SKU IDs) to select correct ticket; monitoring for drift.
Long-Term Applications
These require additional research, scaling, standardization, or regulatory maturation before broad deployment.
- Safety-critical domains (surgical assistance, medical logistics, automotive assembly)
- Sectors/stakeholders: Healthcare, automotive, aerospace; Regulators, safety engineers
- What it enables: Ticket-based operating modes may simplify certification by fixing behaviors without retraining; per-patient/per-procedure or per-line tickets.
- Tools/workflows: Formal verification of ticketed modes; Hardware-in-the-loop simulators for ticket search; Constrained search with safety shields.
- Assumptions/dependencies: Extensive validation and traceability; strong safety monitors; regulatory acceptance of mode-based certification.
- Automated ticket selection and continual adaptation at scale
- Sectors/stakeholders: Large fleet operators, digital-twin providers
- What it enables: Bandits/Bayesian optimization to pick tickets online; digital twin accelerates search before deploying updates; mixture-of-tickets with context-aware selection.
- Tools/workflows: Context-to-ticket routing services; Data-driven revalidation pipelines; Twin-to-real synchronization.
- Assumptions/dependencies: Reliable context features; safeguards against non-stationarity; robust off-policy evaluation to cap on-robot trials.
- Cross-robot and cross-site ticket transfer and marketplaces
- Sectors/stakeholders: OEMs, integrators, third-party vendors
- What it enables: Share and monetize tickets that generalize across similar embodiments and tasks; accelerate deployments at new sites.
- Tools/workflows: Standardized initial-noise APIs; Ticket compatibility schemas; Benchmark suites for transfer scoring.
- Assumptions/dependencies: Architectural alignment across policies; normalization of noise dimensions; IP/licensing frameworks.
- Policy/governance frameworks for “ticketed” AI modes
- Sectors/stakeholders: Policymakers, standards bodies, compliance teams
- What it enables: Certify a finite set of operating tickets; streamline recertification by adding/removing tickets rather than retraining; align with audit and incident response.
- Tools/workflows: Ticket signing and provenance; Compliance dashboards; Incident postmortems tied to ticket IDs.
- Assumptions/dependencies: Consensus on standards; evidence that ticket sets cover operating envelope; mechanisms to prevent drift and tampering.
- Ticket discovery with offline metrics and safety-aware search
- Sectors/stakeholders: Research labs, tool vendors
- What it enables: Reduce or eliminate on-robot rollouts using offline surrogates (e.g., stability, inversion, preference signals) adapted from diffusion literature; safety-constrained search.
- Tools/workflows: Offline estimators; Uncertainty-aware evaluators; Safety filters baked into search.
- Assumptions/dependencies: Correlation between offline metrics and downstream reward; validated surrogates for specific tasks.
- Hierarchical or gated “mixture of tickets”
- Sectors/stakeholders: Advanced robotics R&D, product teams
- What it enables: Small selector (possibly rule-based or learned) chooses among a library of tickets at runtime to handle broader distributions; smooth transitions between modes.
- Tools/workflows: Lightweight gating modules; Performance monitors; Transition safety checks.
- Assumptions/dependencies: Additional model logic (defeats the zero-training simplicity); careful evaluation to avoid oscillations.
- Extension to other generative control settings (beyond manipulation)
- Sectors/stakeholders: Drone manipulation, mobile manipulation, multi-robot coordination
- What it enables: If policies are diffusion/flow-based, ticket steering could apply to locomotion, aerial grasping, or cooperative tasks.
- Tools/workflows: Domain-specific rewards and safety envelopes; Simulation-heavy pre-screening.
- Assumptions/dependencies: Existence of steerable generative policies in target domains; reward design and safe exploration challenges.
- Vendor-level standardization and security hardening
- Sectors/stakeholders: Robot platform vendors, cybersecurity teams
- What it enables: Secure interfaces to inject initial noise; cryptographic ticket signing; separation of duties between model weights and tickets.
- Tools/workflows: API standards; Secure enclaves for ticket storage; Audit logs of mode changes.
- Assumptions/dependencies: Industry adoption; addressing attack surfaces (e.g., malicious ticket injection).
Notes on feasibility across all applications
- Core dependencies: (1) Ability to inject a fixed initial noise vector into the policy at inference; (2) Access to a reward function on rollouts; (3) A steerable base policy (not guaranteed); (4) Safe, budgeted exploration for ticket search; (5) Held‑out validation to avoid overfitting.
- Known limitations: Determinism may reduce exploration; reintroducing controlled stochasticity may be necessary. Performance can degrade under distribution shift—ticket revalidation or periodic refresh is recommended.
Glossary
- Behavior cloning: A supervised learning approach where a policy is trained to imitate expert demonstrations by mapping states to actions. "to train the policy via behavior cloning."
- Conditional Variational Auto-Encoder (CVAE): A generative model that learns a latent representation conditioned on auxiliary inputs to generate structured outputs. "conditional variational auto-encoders (CVAEs)"
- DDIM: Denoising Diffusion Implicit Models; a deterministic sampling method for diffusion models where the number of reverse steps controls speed-accuracy trade-offs. "DDIM steps ($2$ and $8$)."
- Denoising model: The learned function that reverses the corruption process by predicting how to remove noise from partially noised samples. "a denoising model is trained to undo the forward process"
- DexMimicGen: A benchmark suite of dexterous, often bimanual, robotic manipulation tasks used to evaluate policies. "We use the DexMimicGen benchmark"
- Diffusion policy: A robot control policy that samples actions by denoising from an initial noise distribution using a diffusion model. "A diffusion policy trained to pick a banana across the table"
- DSRL: Diffusion Steering via Reinforcement Learning; a method that learns an observation-conditioned noise policy to steer a frozen diffusion policy. "diffusion steering via reinforcement learning (DSRL)"
- Flow matching: A generative modeling framework that learns a continuous-time velocity field to transport samples from a simple source distribution to the data distribution. "flow matching framework with a Gaussian source distribution"
- Franka: The Franka Emika Panda robotic arm platform commonly used in manipulation research. "single-arm Franka robot"
- Isotropic Gaussian: A Gaussian distribution with identical variance in all directions, commonly used as the source noise in diffusion/flow models. "isotropic Gaussian"
- Latent steering: Modulating the latent (noise) inputs of a generative policy at inference time to influence its outputs without changing model weights. "latent steering approaches"
- LIBERO: A multi-task manipulation benchmark comprising suites of related tasks for evaluating generalization in robot policies. "We use the LIBERO benchmark"
- Markov Decision Process (MDP): A formalism for sequential decision making defined by states, actions, transitions, rewards, and a discount factor. "We model robot manipulation as a Markov Decision Process (MDP)."
- Monte-Carlo policy evaluation: Estimating a policy’s value by averaging returns over sampled rollouts in the environment. "using Monte-Carlo policy evaluation"
- MuJoCo: A physics simulation engine widely used for robotics and control experiments. "franka_sim MuJoCo environment"
- ODE: Ordinary Differential Equation; in flow/diffusion sampling, the reverse process can be computed by solving an ODE defined by a learned velocity field. "solving the ODE:"
- Pareto frontier: The set of solutions that achieve the best trade-offs among competing objectives such that none can be improved without worsening another. "defines a Pareto frontier for balancing different objectives"
- Pointcloud: A set of 3D points representing scene geometry, typically obtained from depth sensors, used as policy input. "two pointcloud policies"
- Proprioception: Internal sensor measurements of a robot’s own state (e.g., joint positions/velocities) used as inputs to policies. "and proprioception data"
- Q-function: The expected discounted return from taking an action in a state and following a policy thereafter. "The -function for gives the cumulative discounted expected rewards"
- Reinforcement Learning (RL): A learning paradigm where agents optimize behavior through interaction by maximizing cumulative reward. "trained via reinforcement learning (RL)."
- SmolVLA: A compact Vision-Language-Action model variant used for multi-task robotic manipulation. "We use SmolVLA"
- Velocity field: In flow matching, a vector field learned to guide the transformation of noisy samples toward data samples over time. "treating the denoising model as a velocity field"
- Vector quantization: A technique that maps continuous vectors to discrete codebook entries, often used to discretize or compress latent representations. "potentially leveraging approaches like vector quantization"
- Vision-Language-Action (VLA) models: Multi-modal policies that condition on visual inputs and language instructions to produce robot actions. "Vision-Language-Action (VLA) models."
Collections
Sign up for free to add this paper to one or more collections.

