Much Ado About Noising: Dispelling the Myths of Generative Robotic Control
Abstract: Generative models, like flows and diffusions, have recently emerged as popular and efficacious policy parameterizations in robotics. There has been much speculation as to the factors underlying their successes, ranging from capturing multi-modal action distribution to expressing more complex behaviors. In this work, we perform a comprehensive evaluation of popular generative control policies (GCPs) on common behavior cloning (BC) benchmarks. We find that GCPs do not owe their success to their ability to capture multi-modality or to express more complex observation-to-action mappings. Instead, we find that their advantage stems from iterative computation, as long as intermediate steps are supervised during training and this supervision is paired with a suitable level of stochasticity. As a validation of our findings, we show that a minimum iterative policy (MIP), a lightweight two-step regression-based policy, essentially matches the performance of flow GCPs, and often outperforms distilled shortcut models. Our results suggest that the distribution-fitting component of GCPs is less salient than commonly believed, and point toward new design spaces focusing solely on control performance. Project page: https://simchowitzlabpublic.github.io/much-ado-about-noising-project/



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
Robots often learn by watching examples of how to do a task, like opening a drawer or stacking blocks. This is called behavior cloning. Recently, “generative” models (the kind used to make images or text) have been used as robot controllers, and many people believed they work better because they can learn all the different ways (the full distribution) to do a task.
This paper asks a simple question: Why do these generative robot controllers seem to work so well? The surprising answer: it’s not because they learn many different possible actions. Instead, their advantage mostly comes from two things:
- They think step-by-step (iterative computation), and each step gets feedback during training.
- They practice with a little randomness (stochasticity) during training.
The authors even build a tiny, simple version called a Minimal Iterative Policy (MIP) that does just those two things—and it matches the performance of fancy generative models on many tasks.
What questions did the researchers ask?
The paper tests several common beliefs about why generative policies (GCPs) beat regular regression policies (RCPs). In everyday terms, they ask:
- Do generative policies do better because they see pixels (images) better?
- Is it because they can handle multiple good answers for the same situation (multi-modality)?
- Are they just more expressive or powerful because they think in multiple steps?
- Does adding noise help them learn better representations?
- Are they more stable and scale better when training on big datasets?
How they tested their ideas (methods in simple terms)
To make the comparison fair, the authors used the same neural network backbones for both policy types:
- Regression Control Policies (RCPs): These pick one best action directly, like “go here now.”
- Generative Control Policies (GCPs): These describe a whole range of possible actions and then “sample” one, often by starting with random noise and refining it over several steps (like diffusing noise into a picture).
What they did:
- Tested 28 common robot benchmarks across different inputs: numbers (state), images (pixels), 3D point clouds, and language instructions.
- Carefully controlled the architecture so the only difference was the training style (regression vs generative), not the network size or shape.
- Performed “ablations,” meaning they turned certain design choices on and off (like step-by-step thinking, adding noise, or learning distributions).
- Checked whether the data actually had multiple good actions for the same situation (multi-modality), by:
- Sampling many actions from the same observation and seeing if they form separate clusters.
- Trying the average of many sampled actions (if there were truly different modes, this average should perform badly, but it didn’t).
- Creating a fully deterministic dataset (no randomness) and seeing if GCPs still had an advantage (they did, a little).
- Measured “expressivity” (how sharply a policy can change its action when the observation changes slightly). They did this by nudging the robot’s state a tiny bit and seeing how much the chosen action changed. If GCPs are more expressive just because they think in steps, that should show up here.
A few key terms explained:
- Iterative computation: The model solves the problem step-by-step (like showing your work in math), not in a single jump.
- Stochasticity injection: Adding a little randomness during training, so the model learns to handle small mistakes or uncertainty.
- Distribution learning: Modeling all the possible good actions, not just one.
- “Manifold adherence”: Staying close to the kinds of actions that look like real, expert actions—even when the situation is a bit unusual. Think of it like staying on the “road” of reasonable behavior rather than swerving into weird actions.
Main findings and why they matter
Here are the main takeaways, explained simply:
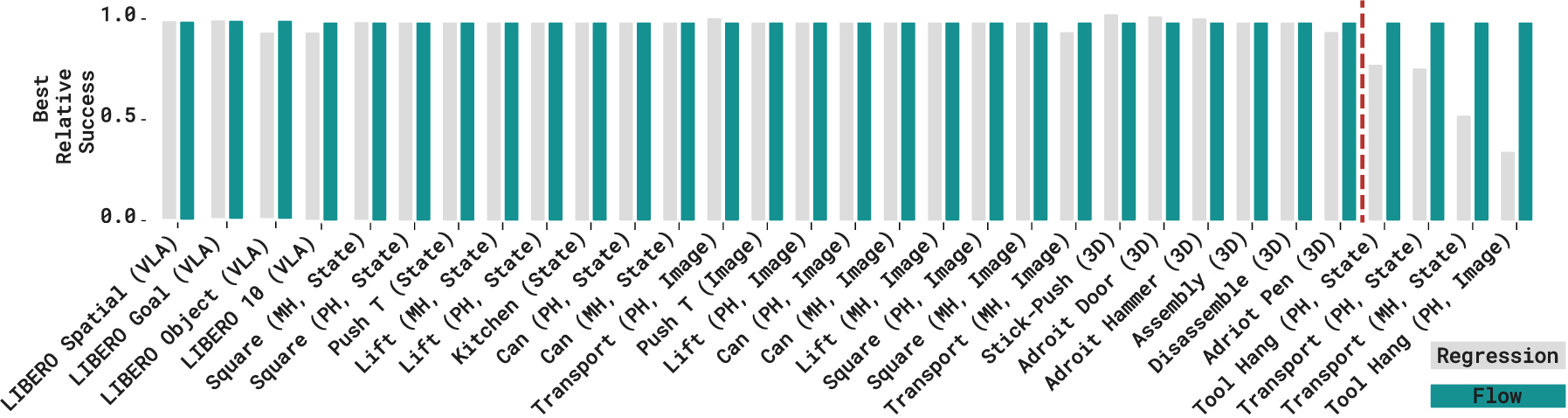
- Generative vs regression is mostly a tie. When you use the same strong network architecture for both, they perform about the same on most tasks (state, image, 3D, and language). Generative models only clearly win on a few very precise tasks (like careful insertions).
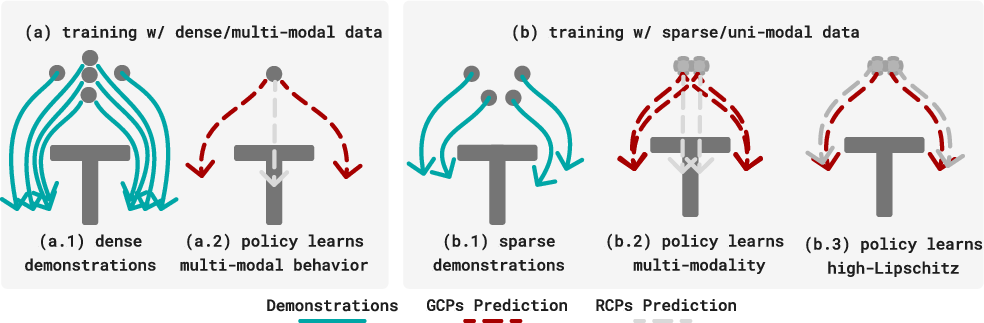
- It’s not about multi-modality. On these benchmarks, the data rarely shows clear “multiple correct actions” for the exact same observation. Sampling many actions didn’t produce distinct clusters, and taking the average action worked nearly as well. Even with a fully deterministic dataset, generative models still had a small edge—so the advantage isn’t from capturing many modes.
- It’s not about being more expressive. Thinking in steps didn’t let generative models learn sharper, more complex reaction patterns (when there wasn’t true multi-modality). In tests, they weren’t more sensitive than regression models to small changes in the input.
- What actually helps: step-by-step + noise during training. The winning combo is:
- Supervised iterative computation: teach the model step-by-step, and grade each step during training.
- Stochasticity injection: add small randomness during training so the model learns to recover from small errors and doesn’t let mistakes snowball.
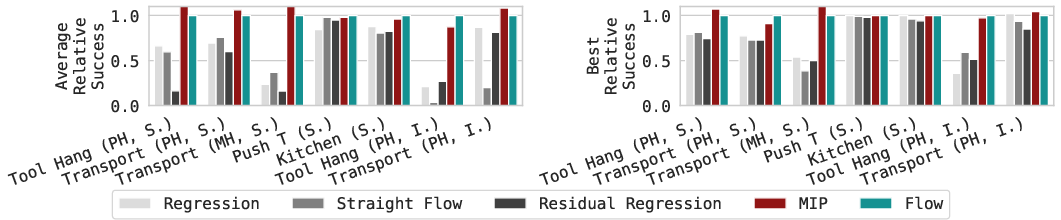
- A tiny two-step policy (MIP) works great. The authors built a very simple two-step policy that uses those two ideas (step-by-step with noise) but does not try to learn full action distributions. It matches the performance of advanced generative methods on many tasks.
- Architecture and action chunking matter a lot. Choosing a good backbone (like Transformers or UNets) and the right action “chunk” length often affects performance more than choosing generative vs regression.
- A useful concept: manifold adherence. The better-performing methods tend to pick actions that “look like” real expert actions, even when the robot sees something a bit different from training. Iterative steps help nudge actions back toward this safe, realistic region, and the added training noise helps prevent errors from piling up.
Why this matters: It suggests we don’t need full-blown generative distribution learning to get strong robot control. We can use simpler models that are easier, faster, and cheaper—if we use the right training tricks.
What this means going forward (implications)
- Focus on control performance, not just fancy generative modeling. For many robot tasks, you don’t need to model all possible actions—just a reliable one that works well.
- Design simpler, stronger policies. A small, step-by-step policy trained with a bit of noise and feedback at each step can match the heavy generative models.
- Spend effort where it counts. Choose a good architecture and action chunk size; these often matter more than whether the policy is “generative” or “regressive.”
- Better robustness in real robots. Training with small randomness and supervising intermediate steps helps robots stay on-track when the world isn’t exactly like the training data.
- New research direction. Instead of focusing on full distribution learning, explore algorithms that combine iterative thinking with smart training noise and strong supervision of each step.
In short: The “magic” of modern generative robot controllers is less about modeling every possible action and more about teaching the model to think step-by-step while learning to handle small errors. That’s good news—it means we can build simpler, efficient controllers that perform just as well.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored based on the paper’s scope, methods, and claims. Each point is framed to be actionable for future research.
- Generalization beyond flow-based GCPs: The study restricts to flow-based generative policies; it remains unclear whether the findings (e.g., limited role of distribution learning, importance of SIC+STCH) hold for diffusion models, tokenized autoregressive transformers, and hybrid architectures under varied sampling regimes.
- Real-world validation: Most benchmarks are simulated or standardized BC datasets; there is no systematic evaluation on physical robots across contact-rich, high-precision, safety-critical tasks with real-world latency, sensing noise, and actuation constraints.
- Multi-task pretraining at scale: The study focuses largely on single-task BC and limited finetuning; it does not resolve whether multimodality becomes consequential at large multi-task pretraining scales (e.g., cross-embodiment, diverse domains, long-horizon branching tasks) or in zero-shot generalization settings.
- When (if ever) distribution learning helps: The paper argues distribution fitting is rarely beneficial but does not identify conditions under which it is necessary (e.g., risk-sensitive control, uncertainty-aware planning, explicit ambiguity in language instructions, multi-agent coordination).
- Measuring multimodality rigorously: Current evidence relies on qualitative visualization and mean-action tests; there is no robust, principled metric or detection protocol to quantify multimodality in action distributions conditioned on high-dimensional observations.
- Task characteristics predicting GCP advantage: The paper notes GCP gains mainly on “high-precision” tasks but does not formalize a taxonomy or predictive features (e.g., contact modeling, tight tolerances, frictional interactions) that forecast when SIC+STCH or GCPs will outperform RCPs.
- Manifold adherence: The proposed “manifold adherence” is introduced as an explanatory proxy but lacks a formal definition, standardized measurement procedure, and validated correlation (or causality) with downstream control performance across diverse tasks and domains.
- Theory of SIC+STCH: The synergy between supervised iterative computation and stochasticity injection is observed empirically; a formal training-dynamics analysis (e.g., noise scheduling, iteration count, error propagation, convergence/stability guarantees) is missing.
- Intermediate supervision acquisition: The approach presumes supervised targets for intermediate steps; methods to automatically derive stepwise labels (segmentation, trajectory retiming, self-supervised targets) from demonstrations—and their robustness to label noise—are not addressed.
- Lipschitz analysis limitations: The Lipschitz constant is estimated via zeroth-order finite differences near feasible states; the method’s sensitivity to scaling, architecture, action normalization, and observation noise—and its predictive power for performance—remains unvalidated.
- Assumptions in the expressivity theorem: The theoretical bound assumes log-concavity of ; implications for heavy-tailed, non-log-concave, or genuinely multimodal distributions (where iterative computation may confer expressivity benefits) are unexplored.
- Solver and integration-step effects: Flow inference is fixed at 9 integration steps; the compute–performance tradeoffs across different ODE solvers, discretization schemes, and step counts (including few-step regimes) are not systematically studied.
- Strengthening regression baselines: RCPs are trained with standard losses; whether advanced regression variants (e.g., iterative residual updates, auxiliary losses, dropout/noise schedules, robust losses) can replicate SIC+STCH benefits without distribution learning is not tested.
- Action chunking design: The paper notes large performance sensitivity to chunk horizons but does not provide principled methods for selecting chunk sizes, dynamic chunking strategies, or analysis of interactions with SIC+STCH and task type.
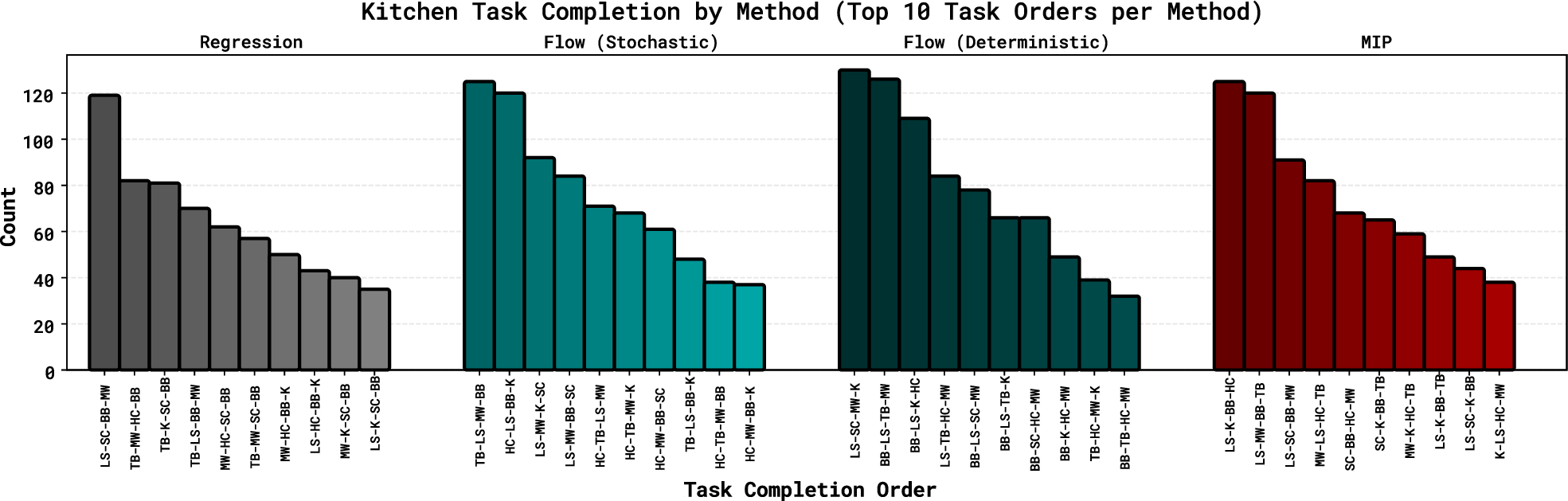
- Diversity and branching evaluation: Diversity is examined on limited examples; unified metrics and broader evaluations (e.g., task completion order distributions across complex long-horizon tasks) are needed to compare behavioral diversity across RCPs, MIP, and GCPs.
- Data scale and coverage effects: The claim that multimodality is rare due to high observation dimensionality and limited demos is plausible but untested; systematic studies varying dataset scale, coverage, and dimensionality to induce (and detect) multimodality are missing.
- Robustness to distribution shift: While off-manifold behavior is discussed, there is no systematic evaluation under domain shift (appearance, geometry, lighting), sensor noise, or perturbations; benchmarks and training strategies to improve out-of-distribution robustness are needed.
- Safety under stochasticity: Noise injection may introduce instability in closed-loop control; safety analysis (e.g., worst-case behavior, constraint violations, recovery under perturbations) and safe noise schedules are not examined.
- Real-time constraints: Iterative inference adds latency; the paper does not quantify impacts on control frequency or propose guidelines to balance performance vs. real-time requirements, especially on resource-constrained hardware.
- Partial observability and memory: The impact of SIC+STCH and MIP under POMDPs, with history-dependent policies or recurrent architectures, is not explored; potential benefits of iterative computation for latent-state inference remain open.
- Language grounding and ambiguity: For VLA models, the interaction between SIC+STCH and language-conditioned policies—particularly under ambiguous or underspecified instructions—is not analyzed; methods to leverage iterative steps for instruction disambiguation are an open direction.
- Off-policy evaluation reliability: Q-value estimates used to assess action plausibility are Monte Carlo-based; their variance, bias, and sensitivity (especially under sparse or noisy rewards) are not characterized, limiting confidence in conclusions drawn from Q-coloring analyses.
Practical Applications
Immediate Applications
The following items can be deployed now by leveraging this paper’s findings that supervised iterative computation (SIC) plus training-time stochasticity—not distributional modeling—drive performance gains in behavior cloning.
- MIP-based control in industrial robotics
- Sector: Robotics, Manufacturing, Logistics
- What to do: Replace diffusion/flow-based policies with the Minimal Iterative Policy (MIP)—a two-step regression policy with training-time noise injection and deterministic inference—for pick-and-place, insertion, assembly, and tool-use tasks.
- Tools/products/workflows: Integrate MIP into ROS control stacks; wrap MIP as a real-time action-chunking controller; maintain existing backbones (UNet/Transformer) but switch objective from distribution learning to regression with SIC; deploy deterministic inference (z=0) to reduce variance and simplify QA.
- Assumptions/dependencies: Tasks are BC-friendly with sufficient demos; intermediate-step supervision can be provided (e.g., via subgoal decomposition or learned auxiliary targets); action chunking is tuned to task; multi-modality is limited at the per-observation level in your data.
- Deterministic inference to simplify certification and safety
- Sector: Healthcare (assistive robots), Warehousing, Consumer robotics
- What to do: Operate deployed policies in deterministic mode (z=0) without materially hurting performance; use MIP or flow policies with fixed noise to improve repeatability and compliance with safety standards.
- Tools/products/workflows: Add an inference-time determinism toggle in controllers; document repeatability in safety dossiers; implement run-time invariance checks.
- Assumptions/dependencies: Benchmarks in the paper show small differences between stochastic vs. mean/zero-noise actions; safety regimes require traceable behavior.
- Architecture parity audits for existing BC pipelines
- Sector: Robotics, Software
- What to do: Re-benchmark regression policies (RCPs) using the same modern backbones (UNet/DiT/Transformers) and action-chunking horizons used by generative policies; remove confounding from architecture differences.
- Tools/products/workflows: Automated experiment harness to swap objectives while holding architecture constant; hyperparameter sweeps for chunk length; CI for benchmark parity checks.
- Assumptions/dependencies: Access to training data and code for existing GCPs; tasks are not dominated by true multimodality.
- Manifold adherence metrics for offline validation
- Sector: Robotics, Academia
- What to do: Adopt manifold adherence (plausibility of actions under OOD observations focusing on off-manifold components) as a proxy metric to predict closed-loop success; use it to triage models before on-robot trials.
- Tools/products/workflows: Add evaluation scripts to compute off-manifold residuals via small action perturbations and finite differences; report manifold adherence alongside validation loss; gate deployments on manifold adherence thresholds.
- Assumptions/dependencies: Access to environment sim or safe on-robot perturbations; metric calibrated to your task domain.
- Data collection and relabeling for deterministic experts
- Sector: Robotics
- What to do: Recollect datasets using deterministic rollouts of trained policies to reduce label noise; retrain RCP/MIP policies to close remaining gaps with GCPs.
- Tools/products/workflows: Dataset relabeling pipeline that replays a baseline policy with deterministic actions; continuous dataset refresh for fine-tuning.
- Assumptions/dependencies: Deterministic environment execution is feasible; baseline policy achieves sufficient success to produce high-quality relabels.
- Cost and sustainability improvements via simpler training/inference
- Sector: Energy (compute sustainability), Policy (procurement), Software
- What to do: Replace diffusion/flow training with MIP or SIC+noise regression to cut training time and inference latency; quantify compute savings for ESG reporting and procurement decisions.
- Tools/products/workflows: Compute metering dashboards; procurement criteria that value simpler models with equal performance; migration guides away from generative sampling loops.
- Assumptions/dependencies: Comparable performance on your tasks given the paper’s benchmarks; organizational willingness to change tooling.
- Curriculum and lab exercises emphasizing SIC+noise over distribution fitting
- Sector: Education, Academia
- What to do: Update robotics courses to demonstrate that SIC+stochasticity drives control performance; add labs comparing RCP vs. GCP under architecture parity; teach action-chunk tuning and manifold adherence diagnostics.
- Tools/products/workflows: Teaching modules, open-source templates from the project page, student assignments for controlled ablations.
- Assumptions/dependencies: Access to benchmark environments; minimal GPU capacity for small-scale experiments.
Long-Term Applications
These opportunities build on the paper’s design taxonomy and theoretical insights, requiring further research, scaling, or standardization.
- Standardize manifold adherence in safety certification
- Sector: Policy/Regulation, Healthcare robotics, Autonomous systems
- What to do: Incorporate manifold adherence into certification protocols as an offline safety proxy for OOD robustness; align with regulatory bodies on acceptable thresholds and test suites.
- Tools/products/workflows: Formal test specifications; third-party auditing tools; integration with ISO/IEC safety standards.
- Assumptions/dependencies: Broad consensus on metric validity; domain-specific calibration and correlation studies with real-world incidents.
- Scaling MIP/SIC+noise to multi-task VLA models
- Sector: Robotics (foundation models), Software
- What to do: Replace distributional policy heads in large vision-language-action models with iterative regression heads supervised at intermediate steps; explore pretraining regimes that favor SIC.
- Tools/products/workflows: VLA training libraries augmented with SIC intermediates; adapter layers for multi-task subgoal supervision; sparse intermediate target generation via learned decomposition.
- Assumptions/dependencies: Methods to obtain or learn intermediate supervision at scale; retention of multi-task generality with deterministic heads.
- Cross-domain control: energy, HVAC, autonomy, surgical assistance
- Sector: Energy (grid/HVAC control), Transportation (autonomous driving), Healthcare (surgical robotics)
- What to do: Apply SIC+noise training to supervised controllers where RL is impractical; aim for deterministic inference for traceability; study manifold adherence as an OOD guardrail in safety-critical loops.
- Tools/products/workflows: Supervisory controllers with two-step policies; anomaly detection coupled to manifold adherence; hybrid control stacks combining classical planning with SIC-based policies.
- Assumptions/dependencies: Availability of demonstration or supervisory datasets; careful integration with physical constraints and planners.
- Hardware–algorithm co-design for low-latency iterative controllers
- Sector: Robotics, Embedded systems
- What to do: Co-design microcontroller firmware and accelerators to support short SIC sequences with deterministic execution; prioritize energy efficiency and bounded latency over sampling-based generative loops.
- Tools/products/workflows: Embedded inference libraries; real-time schedulers tailored to two-step policies; power and timing certification suites.
- Assumptions/dependencies: Hardware support for chosen backbones; tight integration with motion control stacks.
- AutoML for action-chunking and intermediate supervision
- Sector: Software, Robotics
- What to do: Develop AutoML tools to optimize chunk horizon, intermediate target design, and noise schedules; treat SIC configuration as a first-class hyperparameter space.
- Tools/products/workflows: Bayesian optimization or bandit frameworks; synthetic intermediate target generators; curriculum learning for iterative steps.
- Assumptions/dependencies: Reliable offline metrics (including manifold adherence) to guide search; compute budget for automated sweeps.
- New theory and algorithms focused on control (not distribution)
- Sector: Academia
- What to do: Formalize why SIC+noise improves manifold adherence and scaling; design training objectives that directly reward control performance under OOD perturbations; study adaptive noise schedules and step consistency.
- Tools/products/workflows: Benchmarks that isolate control performance from distribution matching; public leaderboards reporting manifold adherence; theoretical analyses of Lipschitz bounds under SIC.
- Assumptions/dependencies: Community adoption of control-centric metrics; reproducible testbeds across modalities.
- Certification-friendly defaults in public procurement
- Sector: Policy, Public sector robotics
- What to do: Write procurement guidelines that prefer deterministic inference and architecture-parity baselines; require ablation reports showing that distributional modeling is not materially improving control performance for the purchased use-case.
- Tools/products/workflows: Standard RFP language; checklists for ablation evidence (architecture parity, SIC+noise, manifold adherence); post-deployment audit procedures.
- Assumptions/dependencies: Policy-maker engagement; vendors’ ability to supply ablation evidence.
- Educational standards and textbooks emphasizing iterative supervision
- Sector: Education
- What to do: Revise textbooks to distinguish generative modeling objectives from control objectives; teach that iterative supervision and noise-injected training yield practical gains; include exercises measuring manifold adherence and Lipschitz sensitivity.
- Tools/products/workflows: Updated syllabi; open-source lab kits; cross-institutional workshops.
- Assumptions/dependencies: Consensus on pedagogy; accessible compute and environments for students.
Notes on feasibility across applications:
- These recommendations assume limited per-observation multimodality in typical BC datasets; if strong multimodality is present, distributional modeling may be needed.
- Success depends on well-chosen architectures, action-chunking horizons, and the availability or learnability of intermediate supervision.
- Deterministic inference is preferred for safety and certification, but must be validated per task to ensure no unacceptable performance regressions.
- Manifold adherence requires domain-specific calibration to become a reliable safety proxy.
Glossary
- Action-chunking: Executing short sequences of low-level actions as a single higher-level command to improve control efficiency. "actions are often a short-open loop sequence of actions, or action-chunks, which have been shown to work more effectively for complex tasks with end-effector position commands~\citep{zhaoLearningFineGrainedBimanual2023}."
- Aleatoric variance: Output variability due to inherent randomness in the data or process (as opposed to model uncertainty). "Only when averaged over initial noise variance to we start to see a tradeoff from epistemic uncertainty to aleatoric variance."
- Autoregressive transformer: A generative architecture that models sequences by predicting the next token conditioned on previous tokens. "tokenized autoregressive transformer~\citep{shafiullah2022behavior}."
- Behavior Cloning (BC): Supervised learning of policies from demonstration data by mapping observations to actions. "We consider the performance of policies learned via BC---that is, supervised learning from a distribution of (observation, actions pairs) drawn from a training distribution $\Dtrain$."
- Consistency models: One-step or few-step generative models trained to map noise directly to data while preserving distributional consistency across noise levels. "including consistency models~\citep{songConsistencyModels2023,kim2023consistency} and their extensions~\citep{gengMeanFlowsOnestep2025,fransOneStepDiffusion2024}."
- Diffusion models: Generative models that learn to reverse a noise-adding process through iterative denoising steps. "such as diffusion models, flow models, and autoregressive transformers"
- Euler integration: A numerical method for solving ODEs by discretizing time and stepping along the derivative. "In practical implementation, sampling is conducted via discretized Euler integration (see~\cref{app:euler_integration} for details)."
- End-effector: The tool or gripper at the end of a robot arm that interacts with the environment. "end-effector position commands~\citep{zhaoLearningFineGrainedBimanual2023}."
- Flow-based GCPs: Generative control policies that integrate a learned flow to transform noise into actions conditioned on observations. "Given their popularity, we focus on flow-based GCPs (flow-GCPs)."
- Flow field: A vector field over time that specifies the instantaneous velocity for transforming noise into data. "A flow-GCP learns a conditional flow field \citep{lipman2023flow,chisari2024learning,nguyen2025flowmp,albergo2022building,heitz2023iterative,liu2022flow} "
- Generative Control Policies (GCPs): Policies that model a distribution over actions conditioned on observations, typically using generative architectures. "Generative control policies (GCPs) parameterize a distribution of actions given an observation ."
- k-nearest neighbor approximation: A nonparametric method that predicts outputs by averaging the nearest training examples, used as a hypothesis about policy behavior. "addresses other hypotheses, such as -nearest neighbor approximation and the behavior diversity."
- Lipschitz constant: A bound on how sensitive a function’s output is to changes in its input; higher values indicate rapid variation. "a policy that has a high Lipschitz constant, i.e. in which is large."
- Log-concave distribution: A probability distribution whose log-density is concave, often implying unimodality and concentration properties. "we assume that the distribution of is -log-concave"
- Manifold adherence: The tendency of a model’s outputs to remain on or near the manifold of plausible actions under distribution shift. "We identify that a property we term manifold adherence captures the inductive bias of GCPs and MIP relative to RCPs"
- Markov Decision Process (MDP): A formal framework for sequential decision-making with states, actions, transitions, and rewards. "This can be formulated as maximizing reward in an Markov Decision Process, which for completeness we formalize in \Cref{app:MDP}."
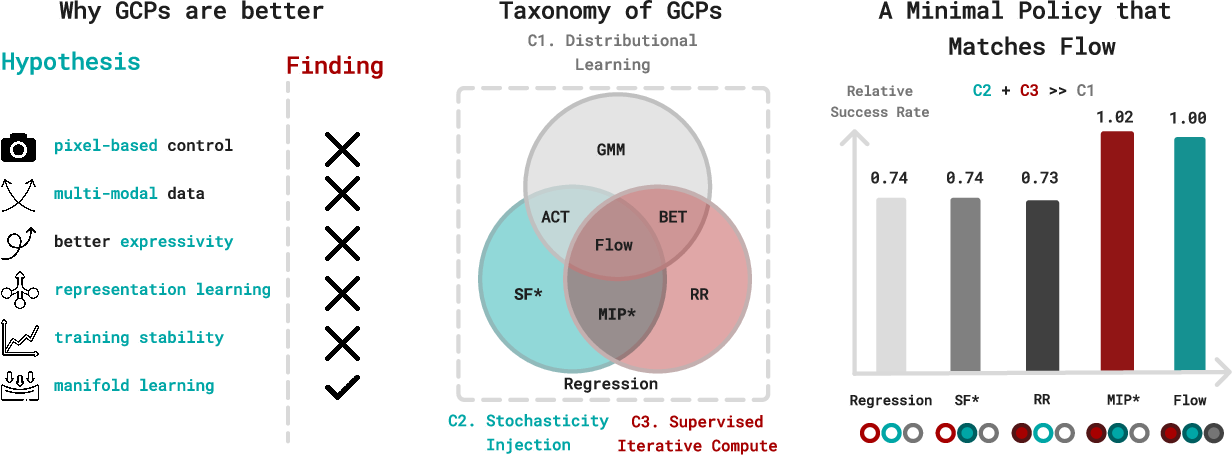
- Minimal Iterative Policy (MIP): A lightweight two-step deterministic policy trained with stochasticity that matches the performance of flow-based GCPs. "we devise a minimal iterative policy (MIP), which invokes only two iterations, one-step of stochasticity during training, and deterministic inference."
- Monte Carlo: A method that uses random sampling to estimate quantities such as expected returns. "We color-code actions by Q-value, i.e. Monte-Carlo-estimated rewards-to-go (\cref{sec:q_function_estimation})."
- Multi-modality: The presence of multiple distinct modes in a conditional action distribution for the same observation. "Past work has conjectured that for salient robotic control tasks, $\Dtrain(a \mid o)$ exhibit multi-modality, i.e. the conditional distribution of given has multiple modes~\citep{shafiullah2022behavior,zhaoLearningFineGrainedBimanual2023,florence2022implicit}."
- ODE (Ordinary Differential Equation): A differential equation involving functions of a single variable and their derivatives, used to define the flow integration. "where solves the ODE:"
- Out-of-distribution (OOD) observations: Inputs that differ from those seen during training, often causing degradation in performance. "Manifold adherence in~\cref{sec:manifold_adherence} measures the generated action's plausibility given out of distribution observations"
- Q-value: The expected cumulative reward (return) from taking an action in a state and following a policy thereafter. "We color-code actions by Q-value, i.e. Monte-Carlo-estimated rewards-to-go (\cref{sec:q_function_estimation})."
- Regression Control Policies (RCPs): Deterministic policies trained with regression losses to map observations directly to actions. "A historically common policy choice for BC is regression control policies (RCPs) \citep{pomerleau1988alvinn,bain1995framework,ross2011reduction,osa2018algorithmic}, given by a deterministic map ."
- Spectral bias: The tendency of neural networks to fit low-frequency (smooth) components before high-frequency details. "While RCPs succumb to spectral bias by averaging the oscillations, GCPs merely trade this averaging for stochastic variance."
- Stochastic interpolant: A framework that defines trajectories between noise and data via stochastic interpolation for training flow models. "We note that this is a special case of the stochastic interpolant framework \citep{albergo2022building,albergo2023stochastic,albergo2024stochastic}"
- Stochasticity Injection: Adding noise during training to improve learning dynamics and robustness across iterative steps. "Stochasticity Injection: injecting noise during training to improve the learning dynamics."
- Supervised Iterative Computation: Training multi-step generation where each intermediate step receives supervision to guide computation. "Supervised Iterative Computation: generating output with multiple steps, each of which receives supervision during training."
- t-SNE: A nonlinear dimensionality reduction technique for visualizing high-dimensional data. "t-SNE visualization."
- Vision-Language-Action (VLA) model: A model that integrates visual inputs, language instructions, and action outputs for robotic tasks. "vision-language-action (VLA) model finetuning (\Cref{sec:myth_performance})."
Collections
Sign up for free to add this paper to one or more collections.