Out of Sight, Out of Mind? Evaluating State Evolution in Video World Models
Abstract: Evolutions in the world, such as water pouring or ice melting, happen regardless of being observed. Video world models generate "worlds" via 2D frame observations. Can these generated "worlds" evolve regardless of observation? To probe this question, we design a benchmark to evaluate whether video world models can decouple state evolution from observation. Our benchmark, STEVO-Bench, applies observation control to evolving processes via instructions of occluder insertion, turning off the light, or specifying camera "lookaway" trajectories. By evaluating video models with and without camera control for a diverse set of naturally-occurring evolutions, we expose their limitations in decoupling state evolution from observation. STEVO-Bench proposes an evaluation protocol to automatically detect and disentangle failure modes of video world models across key aspects of natural state evolution. Analysis of STEVO-Bench results provide new insight into potential data and architecture bias of present-day video world models. Project website: https://glab-caltech.github.io/STEVOBench/. Blog: https://ziqi-ma.github.io/blog/2026/outofsight/






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple but important question: do AI video “world models” keep track of what’s happening in a scene even when the camera isn’t watching? In real life, water keeps filling a glass even if you turn away. The authors built a test, called StEvo‑Bench, to check if today’s video models can keep a process going “out of sight.”
The main questions
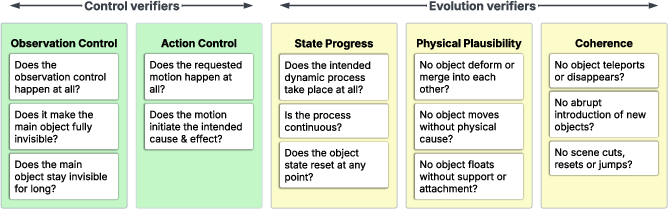
The researchers focus on three easy‑to‑grasp abilities that good “world models” should have when part of the scene is hidden:
- Does the process keep going? (Progress) For example, does a candle keep burning while the view is blocked?
- Is what happens realistic? (Physics) Does everything follow basic rules like gravity and cause‑and‑effect?
- Does the scene stay consistent? (Coherence) Do objects keep their identity, shape, and place instead of suddenly changing or teleporting?
They also check two controls to make sure the tests are fair:
- Was the scene actually hidden for a while? (Observation control)
- Did the action that starts the process really happen? (Action control)
How did they test it?
The team created 225 short tasks covering everyday changes—like pouring water, things falling, switches turning lights on, or a match burning—grouped into six categories (continuous processes, motion, cause/effect changes, and more). For each task, they:
- Show an initial picture and give a simple instruction to start a process (like tipping the first domino).
- Interrupt what the camera sees in the middle of the action. They do this in two ways:
- For regular video generators: tell the model to add an occluder (like a piece of cardboard), or “turn off the lights,” then remove it later.
- For camera‑controlled video models: move the camera away from the main object, then back again.
- When the object comes back into view, they check if the process continued correctly while it was out of sight.
Because watching hundreds of videos by hand is slow and subjective, they built automatic “verifiers”—specialized AI judges that work like referees with checklists. Each verifier answers one yes/no question:
- Did the hiding really happen?
- Did the starting action really happen and cause the right effect?
- Did the process make progress while hidden?
- Did the physics look sensible?
- Did the video stay consistent (no sudden object changes or cuts)?
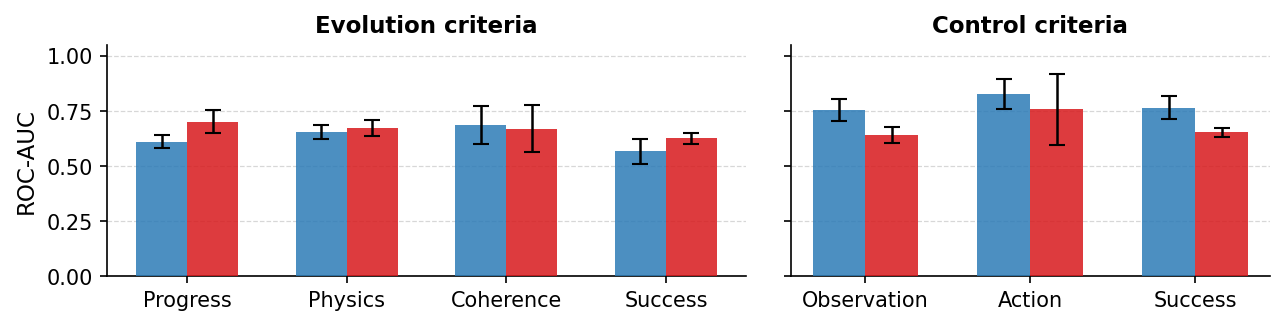
They validated these verifiers against human annotators and found the AI judges agreed with people about as well as people agree with each other.
What did they find?
Big picture: today’s video world models struggle when the scene goes out of sight.
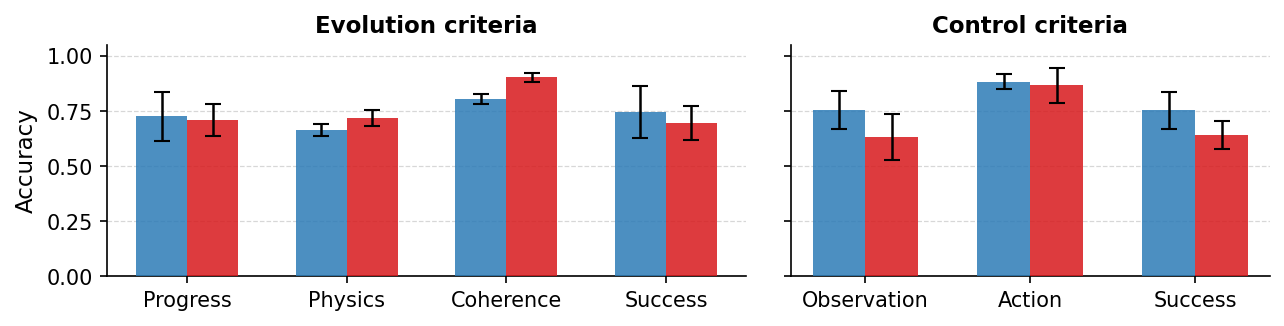
- Overall success rates under interrupted observation were very low (often under 10%).
- Regular video models (like well‑known text‑to‑video systems) sometimes kept the process going, but often:
- The process “froze” during the hidden period (e.g., a deflating mattress stopped deflating when the lights went off).
- Objects became inconsistent after the occluder was removed (e.g., a rectangular sponge reappeared as a round one).
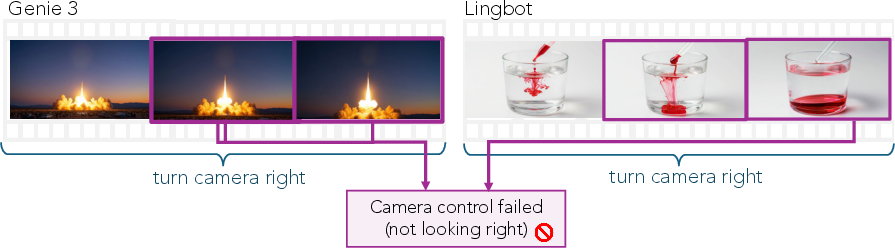
- Camera‑controlled models (where you can steer the camera) mostly “froze” the entire scene while the camera moved, so nothing progressed during the look‑away.
- When camera‑controlled models did manage to keep the process evolving, they often ignored the camera commands (the camera stopped moving properly), showing a trade‑off: either move the camera or evolve the scene, but not both at once.
- Models with special memory modules tended to remember the initial scene very well—but this reinforced a bias toward static (unchanging) scenes instead of helping them update the scene while it’s out of sight.
- When the same models were tested without any hiding (full observation), they performed much better. This suggests they “know” how the process should look, but lose the thread when the view is blocked.
Why might this be happening? The authors suspect training data and design choices:
- Many training videos show static scenes or synthetic camera motions without real changes happening.
- Some architectures focus on remembering appearance instead of tracking how states change over time.
Why this matters
If we want AI to build believable, interactive worlds or help robots plan over long periods, they must understand that the world keeps changing even when it’s not in view. StEvo‑Bench highlights where current systems fall short and gives a clear, automatic way to measure progress.
In simple terms:
- It nudges researchers to design models that separate “what’s happening in the world” from “what the camera currently sees.”
- It points to better training data (with real, ongoing processes and look‑aways) and improved model architectures (that track and update hidden state reliably).
- It provides a benchmark so everyone can test and compare future systems fairly.
If models learn to keep the story going off‑camera, they’ll be much closer to understanding and simulating the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research.
- Lack of standardized, model-agnostic observation control: results may be confounded by using text-based occlusions for generative models and trajectory-based lookaway for camera-controlled models; a unified control interface and protocol is needed to isolate evolution-versus-observation effects.
- No calibration study of occlusion properties: sensitivity to occlusion duration, timing (early/mid/late), frequency, and extent (partial vs complete) is unmeasured; design controlled tasks to characterize thresholds at which models halt or corrupt evolution.
- Binary, coarse-grained success metrics: state progress, physics, and coherence are judged as yes/no; develop continuous, calibrated metrics (e.g., magnitude of progress, quantitative physical error, temporal continuity scores) with task-specific tolerances.
- Verifier dependence on a single closed VLM (Gemini 3.1 Pro): reproducibility and portability are uncertain; test verifier consistency across multiple VLMs, open-source judges, and varying prompts, and report cross-verifier agreement.
- Limited human validation scope: verifier–human agreement is reported on a small subset (n=180) with non-expert annotators; scale up expert-labeled ground truth, report confidence intervals and inter-rater reliability per criterion, and include task-specific rubrics.
- Ambiguous definition of “physical plausibility”: current taxonomy mixes frame-level and dynamic violations, but does not quantify tolerable deviations; formalize physics checks (e.g., gravity consistency, conservation constraints, fluid kinematics) and implement task-specific quantitative tests.
- No ground-truth state trajectories: evaluations rely on VLM judgments rather than explicit, annotated state variables (e.g., water level, object pose/velocity); construct tasks with measurable ground truth and automatic extraction pipelines.
- Ensemble verifier composition not fully specified: the identity and diversity of “video understanding models” used for unanimous/majority voting is unclear; publish the exact ensemble components, calibration methods, and ablation results.
- Absence of statistical significance analyses: reported percentages lack uncertainty (e.g., confidence intervals, bootstrapped variances); add statistical tests to compare models and conditions (full observation vs observation control).
- Unaddressed stochasticity in generative outputs: models are evaluated per single generation; quantify success probabilities across multiple seeds/samples and analyze variance.
- Video length and pacing confounds: different models may produce varying durations and temporal pacing; normalize or control for video length, frame rate, and occlusion window across models.
- Limited coverage of evolution types: six categories exclude many realistic processes (e.g., multi-agent interactions, stochastic/thermodynamic processes, plastic deformation, chemical reactions); expand task set to diverse, long-horizon, compositional, and concurrent evolutions.
- Short-context limitations not systematically probed: effects of context window size (e.g., AETHER’s 41 frames) on evolution under occlusion are not ablated; design tasks varying memory length and quantify degradation.
- Camera control vs evolution disentanglement: observed tradeoffs (evolution occurring while camera control fails) are described but not isolated; create tasks that independently probe camera-following, camera-independent evolution, and concurrent execution with counterfactuals.
- Training data bias hypotheses untested: claims about static-scene bias from 3D renders, indoor/outdoor datasets, and gaming corpora are speculative; run controlled training ablations (static-only vs dynamic-rich, motion-with-dynamics vs motion-only) to causally link data composition to failures.
- Architecture-level ablations missing: memory modules (e.g., VMem) and 3D priors (e.g., GEN3C) are qualitatively assessed; quantitatively ablate attention schemes, latent-state designs (JEPA/SSM), 3D scene representations, and update rules to identify components that enable unobserved evolution.
- No training-time objectives targeting unobserved evolution: propose and test objectives (e.g., predictive coding under occlusion, masked-dynamics modeling, counterfactual consistency, physics-informed losses) that enforce latent state updates during non-informative frames.
- Lack of tasks where output frames are intentionally uninformative: assess whether models maintain and update hidden state under black frames, heavy noise, or camera freeze, and then reveal correct state afterwards.
- Limited action spaces: action control is mostly initiation events and camera; extend to richer interventions (robotic end-effector actions, tool use, force application) and evaluate evolution under occlusion with concurrent action sequences.
- Occluder semantics and prompt ambiguity: “turn off the light” may be interpreted variably across models; define standardized occluder assets, visual overlays, and disambiguated prompts, and measure model-specific prompt-following reliability.
- Geometry and 3D consistency untested: coherence assessments are 2D; incorporate depth, scene graphs, or 3D reconstruction to evaluate whether occluded evolution maintains geometric consistency (e.g., rigid-body constraints) upon re-appearance.
- Insufficient control over camera trajectories: lookaway commands are simple (e.g., “right-30, left-30”); diversify trajectories (curved paths, varying speed/acceleration, rotations vs translations) and measure how trajectory complexity affects evolution.
- Benchmark scale and representativeness: 225 tasks may not capture the breadth of real-world dynamics; report category-wise distribution, object/material diversity, and add tasks with varied environmental conditions (wind, friction, lighting, fluids).
- Model comparability across closed vs open ecosystems: closed-source models’ settings, sampling, and guardrails are opaque; document per-model configuration, sampling parameters, and failure-to-generate rates to ensure fair comparisons.
- Reproducibility of prompts and initial conditions: the exact text prompts, initial images, and timing schedules are not exhaustively published; release full task specifications, seeds, and automation scripts for independent replication.
- Adversarial robustness of verifiers and tasks: susceptibility to spurious cues or editing artifacts is untested; evaluate robustness against adversarial occluders, cuts, and appearance changes.
- Evaluation of long-horizon evolutions: many real processes evolve over minutes/hours; design scalable protocols (chunked generation, latent rollouts) to test whether models maintain correct evolution over extended occlusions.
- Interaction with agentic decision-making: the benchmark is passive video generation; assess how failures impact planning/interaction in embodied agents and whether agent feedback (e.g., probing actions during occlusion) mitigates evolution stalls.
- Cross-domain generalization: results are primarily everyday physics; test domains like medical dynamics, industrial processes, and natural phenomena to assess domain-specific failures and training needs.
- Ethical and safety considerations: incorrect evolution under occlusion could mislead downstream systems; articulate risk scenarios and evaluation gates for deployment in embodied applications.
Practical Applications
Below are practical applications that follow from the paper’s benchmark (StEvo-Bench), its observation-control methodology, and its specialist VLM-based verifier pipeline. Each item includes likely sectors, potential tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
- Software/AI R&D: CI-style evaluation for video and “world” models
- What: Integrate StEvo-Bench and its automatic verifiers into continuous integration to quantify “state evolution under occlusion/lookaway” alongside quality and consistency.
- Sectors: Software/AI, foundation model labs
- Tools/Workflows: “StEvo score” in model cards; nightly regression tests; failure dashboards broken down by progress/physics/coherence.
- Assumptions/Dependencies: Access to model APIs; ability to run the VLM verifier ensemble (e.g., Gemini or strong open alternatives); compute budget.
- Video platform QA: Preflight checks for generated videos
- What: Use the specialist verifiers to automatically flag stalled dynamics, physics violations, or continuity errors before videos are surfaced to users.
- Sectors: Creative tools, media platforms, advertising tech
- Tools/Workflows: QC plug‑ins for post-production or AIGC platforms; batch screening of outputs triggered by “lookaway/occlusion” prompts.
- Assumptions/Dependencies: VLM-based judgments generalize to platform content; acceptable false-positive/negative rates.
- Robotics and Embodied AI: Pre-deployment screening for occlusion robustness
- What: Before using video-based world models for planning or simulation-in-the-loop, apply StEvo-Bench tasks to avoid models that “freeze” state when the agent’s camera turns away.
- Sectors: Robotics, autonomous systems, drones
- Tools/Workflows: Acceptance criteria that require minimal state-progress under camera lookaway; hard gating tests for rollout.
- Assumptions/Dependencies: The tested video world model is in the perception/simulation loop; camera-control interface available.
- AR/VR and Gaming: QA for camera-motion and dynamics
- What: Test in-engine generative components to ensure dynamic processes continue when users change viewpoint, preventing “static-scene bias.”
- Sectors: AR/VR, game engines, virtual production
- Tools/Workflows: Automated “lookaway-return” test suites embedded in scene validators; reports on progress/physics/coherence.
- Assumptions/Dependencies: Ability to script camera trajectories; model runs in-engine or via service.
- Dataset curation and training diagnostics
- What: Audit training sets for over-representation of static scenes; introduce occlusion-interrupted dynamic clips to reduce bias.
- Sectors: Data vendors, ML training teams
- Tools/Workflows: Data scorecards tracking occlusion/dynamics coverage; curriculum schedules that mix “full-observation” and “interrupted-observation” clips.
- Assumptions/Dependencies: Rights to alter data pipelines; budget to source or synthesize new video segments.
- Benchmarking standards in procurement and risk review
- What: Add “state evolution decoupled from observation” as a procurement checkbox for vendors claiming “world modeling” capabilities.
- Sectors: Public sector IT, enterprise compliance
- Tools/Workflows: Request-for-Proposal (RFP) annex specifying minimum StEvo performance; vendor self-attestations plus reproducible runs.
- Assumptions/Dependencies: Stakeholder buy-in; reproducibility guarantees.
- Academic evaluation and ablation studies
- What: Use StEvo-Bench to test architectural hypotheses (e.g., memory modules, 3D priors) and data interventions on decoupling evolution from observation.
- Sectors: Academia, industrial research
- Tools/Workflows: Ablation templates mapping each change to per-criterion verifier scores; shared leaderboards.
- Assumptions/Dependencies: Access to the benchmark, code, and comparable compute.
- MLOps monitoring of deployed AIGC services
- What: Lightweight runtime checks on samples to detect new regressions (e.g., growing incoherence when prompts contain occlusions/“lights off”).
- Sectors: Software/AI operations
- Tools/Workflows: Canary prompts; alerting on significant drops in state-progress or coherence.
- Assumptions/Dependencies: Cost-aware sampling; stable verifier behavior over time.
- Education and training materials
- What: Use the benchmark’s task categories to teach “physics and coherence” evaluation for video models and the value of checklist-based judging.
- Sectors: Education, workforce training
- Tools/Workflows: Course modules, lab assignments, and small-group annotations comparing human vs. verifier decisions.
- Assumptions/Dependencies: Appropriate licensing for classroom use; simplified compute environments.
Long-Term Applications
- Robust embodied agents that plan through occlusion
- What: Develop stateful world models whose latent states evolve correctly when the camera is off-target, enabling safe long-horizon planning.
- Sectors: Home/warehouse robots, drones, autonomous systems
- Tools/Workflows: Architectures combining latent state, physics priors, and camera-control conditioning; “evolve-while-unobserved” training losses; acceptance gates based on StEvo-like criteria.
- Assumptions/Dependencies: New datasets with interrupted observation; verified safety; strong open VLMs or learned video critics.
- Digital twins and predictive maintenance with unobserved intervals
- What: Twin models that continue simulating process evolution during sensor dropouts or occlusions, then re-synchronize on return.
- Sectors: Energy, manufacturing, process industries
- Tools/Workflows: Twin modules trained with lookaway augmentations; reconciliation logic using state-progress checks; operator dashboards showing confidence bands.
- Assumptions/Dependencies: Domain adaptation; strict calibration; integration with sensor streams and control systems.
- Surgical and clinical video assistants robust to camera movement
- What: Assistance systems that maintain physically plausible predictions of tissue or device state when endoscope views change or are temporarily blocked.
- Sectors: Healthcare
- Tools/Workflows: Domain-specific benchmarks mirroring StEvo-Bench; timeline-aware video assistants; safety cases referencing evolution-under-occlusion performance.
- Assumptions/Dependencies: Medical data access and consent; rigorous validation and regulation; high reliability thresholds.
- Smart-home/IoT safety agents
- What: Predict appliance or environmental state evolution when cameras are off or viewpoints change (e.g., stove heating after switch-on).
- Sectors: Consumer IoT, insurance
- Tools/Workflows: Local or cloud models with occlusion-aware training; alerting when predicted evolution becomes unsafe; verification logs for audits.
- Assumptions/Dependencies: Privacy constraints; on-device compute; robust false-alarm controls.
- Film/VFX and interactive media engines with timeline coherence
- What: Generative engines that preserve object identity and dynamics across cuts, off-screen time, and re-entries into frame.
- Sectors: VFX, animation, gaming
- Tools/Workflows: Timeline-aware editors with “evolution continuity” validators; render-time correction guided by verifier feedback.
- Assumptions/Dependencies: New model capabilities (state tracking across shots); creator workflows adapting to automated feedback.
- Autonomous driving and mobile robotics prediction under occlusion
- What: Use world-model-inspired predictors that maintain consistent, physically plausible state estimates of occluded agents.
- Sectors: Mobility, transportation
- Tools/Workflows: Adapt StEvo principles to driving datasets (camera/lookaway analogs via occluders and ego-turns); per-criterion evaluation for planners.
- Assumptions/Dependencies: Task transfer from generative video to predictive perception; extensive domain data and safety validation.
- Standards and certification for “world evolution fidelity”
- What: Establish third-party certification that a model’s state evolution is decoupled from observation, with transparent, multi-criteria scores.
- Sectors: Standards bodies, regulators, enterprises
- Tools/Workflows: Reference implementations of verifiers; test suites; pass/fail thresholds by domain risk.
- Assumptions/Dependencies: Community consensus; reproducible environments; open benchmarks or escrowed tests.
- Training-data and objective innovations
- What: Services and toolkits to generate or mine occlusion-interrupted dynamic sequences and to train with evolution-aware objectives.
- Sectors: ML tooling, data providers
- Tools/Workflows: Data synthesizers; curriculum schedulers; losses that penalize “evolution stopping” and reward physically plausible progress during lookaway.
- Assumptions/Dependencies: Cost of data production; alignment with downstream tasks; availability of physics-informed priors.
- Open verifier ecosystems and multi-judge ensembles
- What: Open-source verifier stacks that replace or complement closed VLMs, reducing reliance on a single judge and improving robustness.
- Sectors: Open-source AI, academic/industry consortia
- Tools/Workflows: Multi-VLM and video-model ensembles with checklist prompts; calibration against human panels; bias and drift monitors.
- Assumptions/Dependencies: Strong open VLMs; reproducible evaluation protocols.
- Regulatory testing frameworks for high-stakes deployments
- What: Formalize “interrupted-observation evolution” tests in regulatory approvals for public-sector or safety-critical AI.
- Sectors: Public sector, critical infrastructure
- Tools/Workflows: Government-run testbeds; mandated disclosure of evolution/coherence/physics scores for approved uses.
- Assumptions/Dependencies: Legal authority; harmonization across jurisdictions; test reproducibility and fairness.
Glossary
- 2.5D: A representation between 2D and 3D that adds depth cues without full volumetric geometry. "2.5D/3D as state"
- 3D cache: A stored 3D representation used to improve rendering or control efficiency during generation. "leverages 3D cache to enhance camera control"
- 3D Gaussian Splats: A point-based 3D scene representation using anisotropic Gaussians for fast rendering. "renderings of reconstructed 3D Gaussian Splats"
- 3D priors: Prior knowledge or constraints from 3D geometry used to guide model generation or control. "GEN3C incorporates 3D priors"
- 4D reconstruction objective: A training objective that reconstructs dynamic 3D scenes over time (3D + time). "AETHER pretrains on 4D reconstruction objective."
- action-conditioned video models: Video generators that take action inputs (e.g., controls) to produce future frames. "The other type is action-conditioned video models"
- all-to-all bidirectional attention: Attention mechanism where every token attends to every other token in both temporal directions. "naive all-to-all bidirectional attention might not be efficient in such cases."
- block world: A simplified synthetic environment of geometric blocks used to study reasoning or dynamics. "like block world."
- camera-controlled video models: Video models that accept camera movement commands to navigate the scene during generation. "For camera-controlled video models, we specify a camera trajectory"
- camera pan: Horizontal rotation of the camera to sweep across a scene. "VMem always creates severe visual artifacts during camera pan"
- camera trajectory: A specified path or sequence of camera movements through a scene. "we specify a camera trajectory"
- causal change: Evolution category where causes lead to effects (e.g., flipping a switch causes a light to turn on). "causal change"
- checklist-style prompting: Prompting strategy that decomposes evaluation into explicit, itemized checks for reliability. "checklist-style prompting"
- coherence verifier: An automatic checker assessing temporal consistency of objects and scenes across time. "The coherence verifier captures these errors"
- continuous process: Evolution category involving uninterrupted change over time (e.g., melting, pouring). "continuous process"
- depth point cloud: A set of 3D points with depth information representing scene geometry. "use depth point cloud or 3D representations"
- embodied agents: Systems (e.g., robots) that perceive and act in the physical world. "embodied agents deployed in the real world."
- end effector space: The control space of a robot’s end effector (e.g., gripper pose or actions). "robotic end effector space"
- evolution stopping: Failure mode where state changes halt during unobserved periods. "evolution stopping and incoherence"
- kinematics: The study/category of motion without considering forces, used here as an evolution type. "kinematics"
- latent world state: A compact, internal representation encoding the scene’s underlying state. "use a latent world state"
- lookaway: A camera-control pattern where the camera turns away from the main subject and later returns. "camera ``lookaway'' trajectories"
- majority-vote ensemble: Combining multiple model judgments by taking the majority decision. "majority-vote ensemble ()"
- memory-based architectures: Models with explicit memory components to store and retrieve state over time. "memory-based architectures exacerbate the static-scene bias"
- memory module: A component that stores past information to inform future generation. "VMem incorporates a memory module"
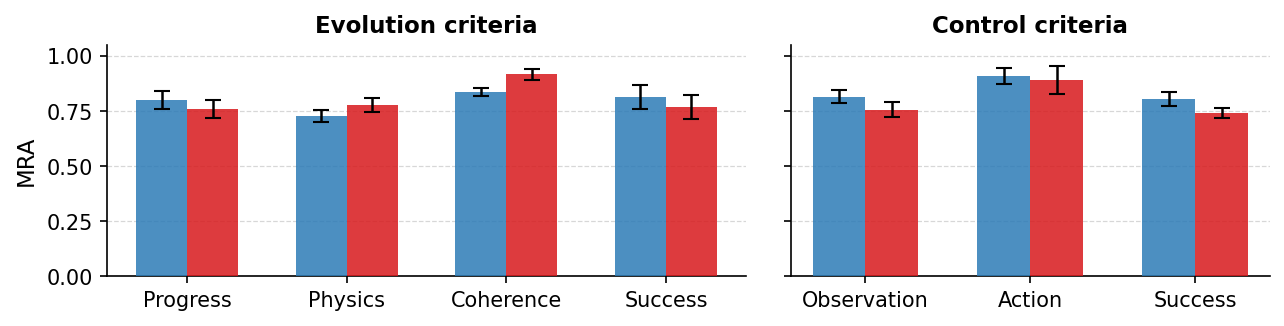
- Model ranking agreement (MRA): A metric assessing how consistently different raters rank models’ performance. "Model ranking agreement (MRA) sidesteps absolute calibration entirely:"
- observation control: Interventions that hide the evolving process (e.g., occlusion, lookaway) to test unobserved evolution. "applies observation control to evolving processes"
- occluder: An object inserted to block the view of the scene or target. "occluder insertion"
- physical plausibility: Conformance of generated dynamics to physical laws and realistic behavior. "The physical plausibility of state evolution:"
- preference optimization: Post-training that aligns model outputs with human or specified preferences. "post-training with preference optimization."
- ROC-AUC: Receiver Operating Characteristic – Area Under the Curve, a metric for binary classifier performance. "ROC-AUC addresses potential label class imbalance."
- semi-autoregressively: Generation where outputs are produced in segments conditioned on previous parts rather than fully step-by-step. "generate videos semi-autoregressively"
- state progress verifier: An automatic checker determining whether intended state changes progressed during occlusion. "Our state progress verifier detects this issue."
- stateful world model: A model that maintains an explicit or implicit representation of the world’s evolving state. "a ``stateful'' world model"
- static-scene bias: A tendency to generate or assume scenes remain static rather than evolve. "exacerbate the static-scene bias"
- unanimous-vote ensemble: An ensemble that only accepts outcomes if all judges agree. "unanimous-vote ensemble ()"
- VLM judge: A Vision-LLM used to evaluate or score generated videos. "All verifiers use Gemini 3.1 Pro as the VLM judge."
- world state: The configuration of objects and properties at a moment, which evolves over time. "forming the ``world state''."
Collections
Sign up for free to add this paper to one or more collections.