- The paper introduces a novel framework combining task-conditioned sparse autoencoders and DAG-based causal graph learning to elucidate multi-step LLM reasoning.
- It demonstrates significant performance gains with a mean causal fidelity score of 5.654, outperforming baseline methods on reasoning benchmarks.
- The approach enhances interpretability by revealing domain-specific causal interactions, paving the way for safer and more auditable AI systems.
Causal Concept Graphs in LLM Latent Space for Stepwise Reasoning
Introduction
The paper "Causal Concept Graphs in LLM Latent Space for Stepwise Reasoning" presents a novel methodological approach for enhancing the interpretability of transformer-based LLMs, specifically focusing on the deployment of Causal Concept Graphs (CCG) for elucidating multi-step reasoning processes. By integrating task-conditioned sparse autoencoders and causal graph learning techniques, the research addresses the critical question of how internal features within LLMs interact during complex reasoning tasks, thereby facilitating better diagnostic capabilities and robustness in AI systems.
Methodological Framework
The research introduces an intricate pipeline for CCG construction, comprising three primary stages:
- Task-Conditioned Sparse Autoencoder (SAE): This initial stage involves training a sparse autoencoder on the residual activations of a pre-existing LLM (GPT-2 Medium). TopK gating, which ensures precise sparsity (5.1% L0 activation rate), is employed to extract task-specific concept features.
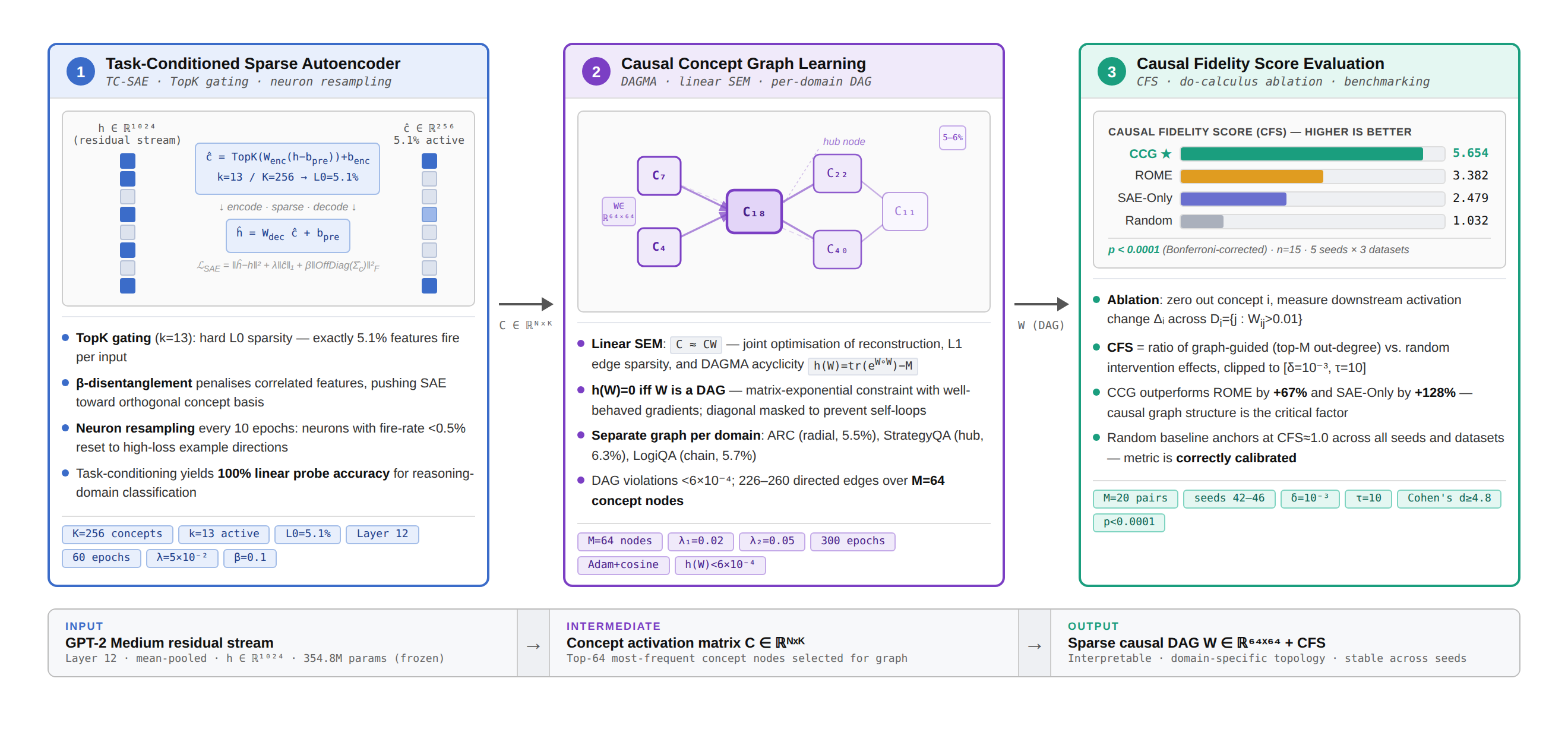
Figure 1: CCG pipeline. Stage 1 leverages a task-conditioned SAE on GPT-2 Medium for feature extraction.
- Causal Graph Learning: Utilizing the extracted sparse features, the second stage constructs a directed acyclic graph (DAG) using DAGMA, a differentiable structure learning method. This step focuses on recovering sparse, task-specific causal dependencies, achieving an edge density between 5-6%.
- Causal Fidelity Score (CFS): A novel metric is introduced to evaluate the causal influence of the learned graph's structure, comparing it against baseline interventions.
Experimental Evaluation
The methodology is rigorously assessed on three reasoning benchmarks: ARC-Challenge, StrategyQA, and LogiQA. The CCG approach demonstrates substantial performance improvements, evidenced by a mean CFS of 5.654 ± 0.625, significantly surpassing baselines like ROME-style tracing and SAE-only methods.
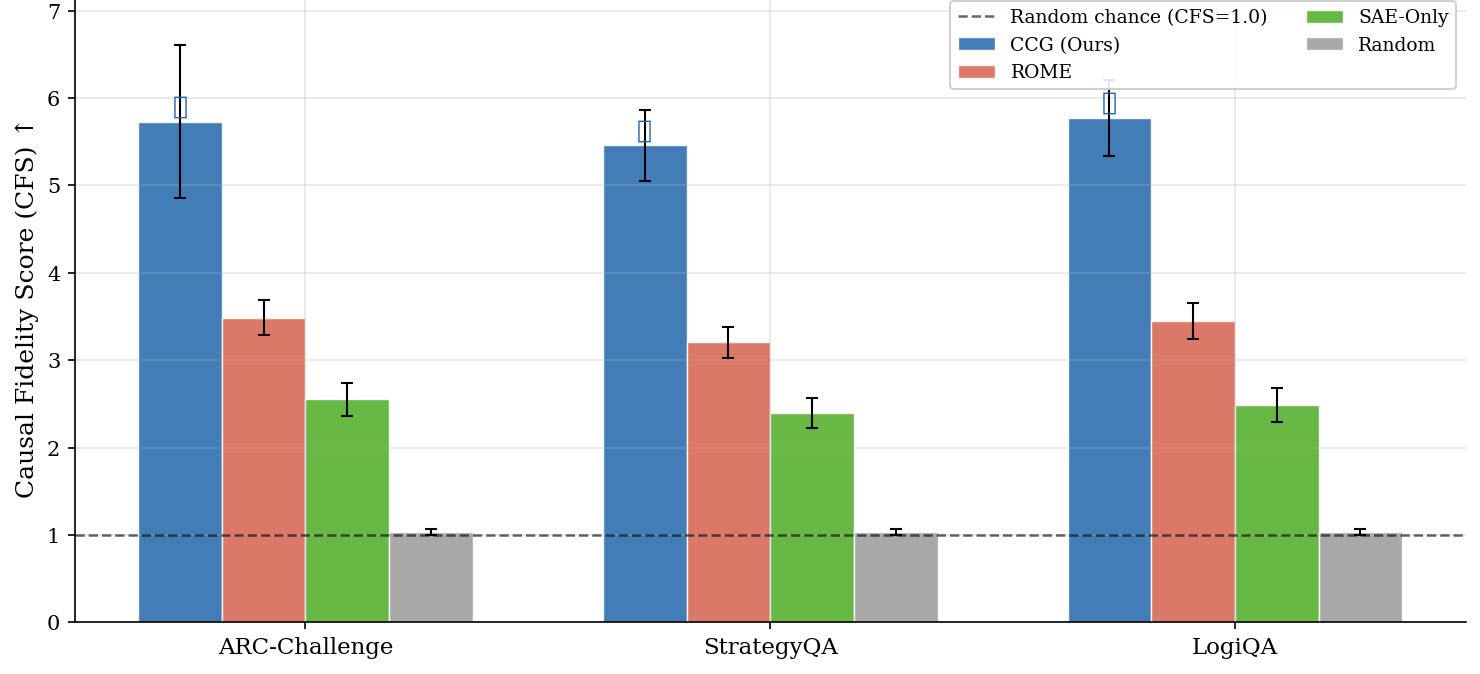
Figure 2: Main results illustrating consistent outperforming of baselines by CCG across datasets.
Results and Discussion
The evaluation results underscore the efficacy of the CCG approach, particularly in its ability to identify high-impact causal nodes within the LLM's latent space. The sparse graph structure not only aids in interpretability but also ensures that the model captures domain-specific reasoning patterns.
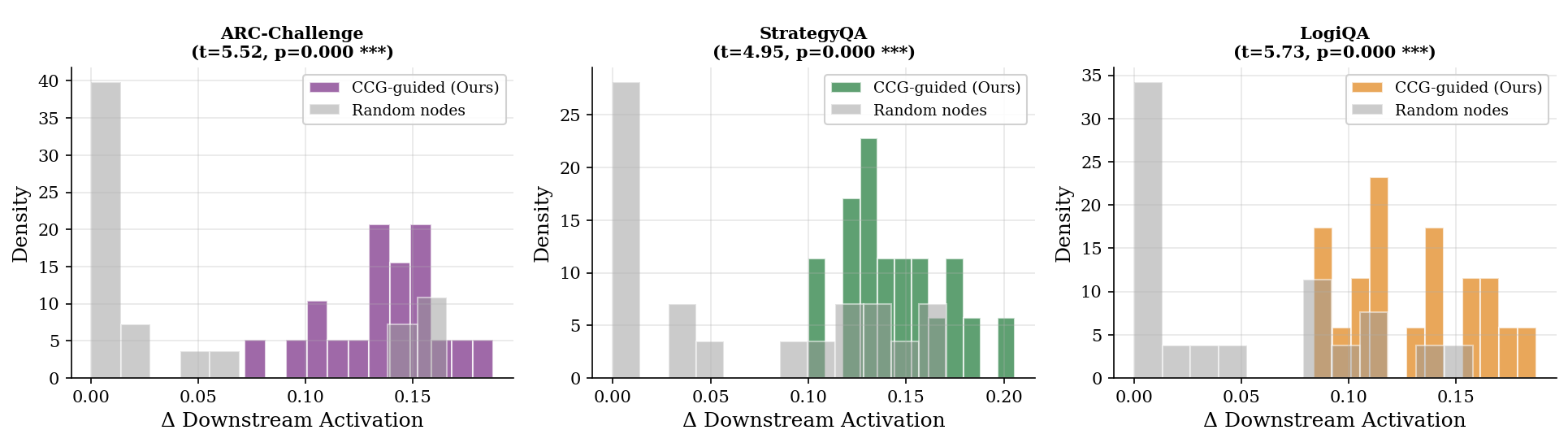
Figure 3: Intervention effect distributions showing CCG's superior selection of influential nodes compared to random targets.
Furthermore, the learned graph topologies reveal distinct patterns across different datasets—e.g., StrategyQA's dense hub-like nodes and LogiQA's sequential structure—highlighting the adaptability of the CCG framework.
Implications and Future Work
The implications of this research are manifold. Practically, the enhanced interpretability facilitates better understanding and auditing of AI decisions, aiding in alignment and safety. Theoretically, it opens avenues for exploring richer causal models within AI systems, potentially extending to nonlinear interactions and scalable implementations on larger LLMs.
Future work could focus on multi-layer graph composition to capture more comprehensive reasoning processes and extend the methodology to diverse transformer architectures, thus broadening the applicability of CCGs in various AI domains.
Conclusion
This study advances the field of mechanistic interpretability by merging sparse feature discovery with causal graph learning in LLMs, yielding a framework that not only identifies pertinent causal interactions but also enhances the overall understanding and reliability of AI systems. Causal Concept Graphs represent a significant step forward in demystifying the complex inner workings of transformer-based models, promising to bridge the gap between high-level interpretability and low-level neural activations.

