- The paper introduces a reinforcement learning-based router that prevents weight collapse by enforcing balanced, fixed routing weights across activated LoRAs.
- It demonstrates significant accuracy improvements (2.8 to 3.3 points) and enhanced parameter efficiency on multi-task LLM finetuning benchmarks.
- The approach leverages a non-differentiable top-k selection transformed into an RL problem using the REINFORCE leave-one-out trick for stable gradient propagation.
ReMix: Reinforcement Routing for Mixtures of LoRAs in LLM Finetuning
Mixture-of-LoRAs architectures generalize classical LoRA-based parameter-efficient finetuning (PEFT) of LLMs by enabling dynamic routing: each input can be processed via a combination of multiple LoRA modules (“experts”) per layer. Prior methods optimize the routing weights (often softmax-based), allowing routers to allocate activation mass among available LoRAs in an input-adaptive manner. However, the authors theoretically and empirically demonstrate that these learnable routers suffer from severe weight collapse: for almost every input, the effective support size of the routing distribution is close to one even when k>1 LoRAs are allowed to be simultaneously activated.
This phenomenon fundamentally limits potential expressivity and parameter utilization—multiple LoRAs are allocated and maintained but rarely used in practice, which all but negates the intended benefits of the mixture mechanism. The problem intensifies during finetuning as well, with routing distributions becoming more peaked over training steps. These observations are made precise through analysis of effective support size (ESS), entropy, and robust statistics across training runs.
The ReMix Approach: Reinforcement-Guided Mixture Routing
To address this collapse, ReMix introduces a new router design based on enforced balanced, non-learnable routing weights across all activated LoRAs. Instead of allocating learned scalar routing weights via a softmax, every selected LoRA receives a fixed weight ω>0. For each input, a categorical distribution (parameterized by a small neural network) produces scores and the top-k LoRAs (by probability) are activated, each with weight ω, while others receive zero.
This design breaks the connection between learnable mixture weights and over-concentration by construction, ensuring that for each input, exactly k LoRAs are activated with equal importance. However, the design is non-differentiable (as the top-k operator is discrete and assigns hard zeros), precluding standard backpropagation to train the router parameters.
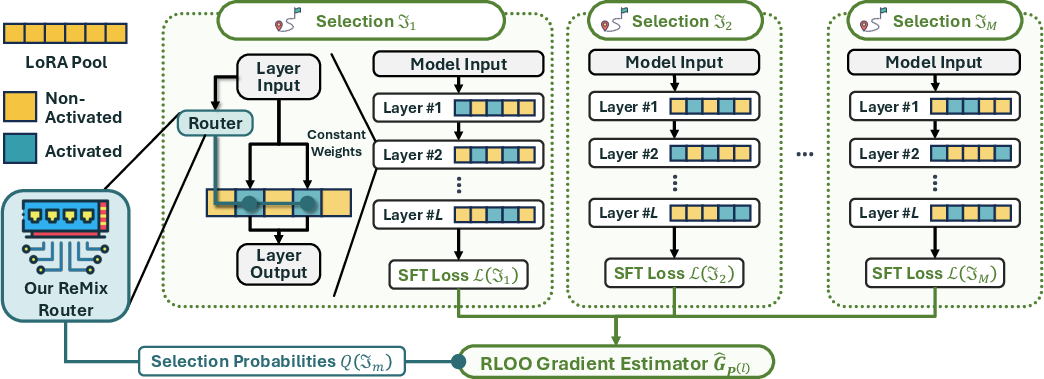
Figure 1: Overview of the ReMix finetuning procedure, showing RL-based training for non-differentiable mixture routing.
To enable end-to-end training, ReMix reframes router optimization as a reinforcement learning (RL) problem. The router defines a stochastic policy over LoRA subsets; the reward is the negative of the task loss. A specialized unbiased gradient estimator using the REINFORCE leave-one-out (RLOO) trick (i.e., the policy evaluation baseline is the average loss observed across sampled routes) is introduced to reduce variance and efficiently propagate gradients through the non-differentiable router. This allows for scalable, compute-efficient training using minibatched sampling of activated LoRA sets.
During inference, theoretical results show that, under mild assumptions, top-k selection on the router's categorical distribution recovers the optimal subset; this deterministic inference procedure maximizes the probability of utilizing the best available ensemble.
Theoretical and Empirical Evidence for Weight Collapse
A core result is a rigorous upper bound on the effective support size (ESS) of routers with softmax-parameterized weights under Gaussian initialization. With overwhelming probability, ESS for mixture routers is at most two, even when n≫2 LoRAs are available and k>1 are supposed to be concurrently activated. The softmax's competition effect and rare overlap of logits are the underlying cause of this bottleneck.
Empirically, visualizations of routing weights (histograms and ESS trajectories over training steps) confirm that, as finetuning progresses, the routing almost always collapses to a single dominant LoRA, with the remaining weights close to zero—even when k>1. This produces a substantial mismatch between the Mixture-of-LoRAs model’s nominal capacity and its realized capacity in practice.
Experimental Evaluation
Extensive experiments on multi-task LLM adaptation benchmarks (GSM8K for math reasoning, HumanEval for code, ARC-c for knowledge recall) systematically compare ReMix to a wide array of PEFT and mixture baselines. These include prompt/prefix tuning, canonical LoRA, DoRA, rsLoRA, and more recent mixture architectures such as MixLoRA, HydraLoRA, and VB-LoRA. Across all tasks:
- Accuracy: ReMix consistently provides the highest accuracy, with substantial gains (2.8 to 3.3 points) over leading mixture and single LoRA baselines. Improvements are particularly pronounced on GSM8K and code completion.
- Parameter efficiency: These gains are achieved with parameter footprints on par with, or below, those of strong baselines.
- Compute scalability: Due to the RL-based gradient estimator, ReMix can further improve with increased compute (larger minibatch), unlike deterministic routers.
- Ablation: Removing key components (RLOO for router training, top-k for inference) degrades performance, confirming their contribution.
- Subspace diversity: The activated LoRA subsets are demonstrably more diverse than in rank-kr LoRA, yielding better performance per trainable parameter.
- Scalability with k: Increasing the number of activated LoRAs enhances accuracy, supporting the hypothesis that balanced mixtures are critical for model capacity.
Implications and Future Directions
ReMix’s reinforcement-guided router constitutes a shift in PEFT mixture design away from differentiable but imbalanced soft mixtures toward sparsity-enforcing, variance-robust selection policies. This has significant downstream implications:
- Expressivity: The mixture design actually realizes the theoretical expressivity expected of multi-adapter networks.
- Efficiency: Balanced parameter utilization, especially under strict compute/memory budgets, is vital for practical deployment of LLMs across domains and tasks.
- Modular composability: The framework can in principle be composed with any subnetwork or adapter family; it is not specific to canonical LoRA modules.
- Computational scaling: The RL-based surrogate can naturally leverage larger compute resources for more stable/efficient training, in contrast to traditional mixture models where training cost is fixed for a given architecture.
These results open up further avenues, including extending ReMix-type RL-based routers to deeper mixture-of-experts LLMs, modular (cross-task) adaptation, hierarchical mixtures, and potential integration with dynamic modular architectures. The RL optimization paradigm also aligns with broader trends in LLM alignment and downstream task policy tuning.
Conclusion
ReMix provides strong theoretical clarity and practical evidence that mixture-of-LoRAs routers based on reinforcement-guided, non-learnable routing weights unlock the intended expressivity and efficiency of mixture-based PEFT. By ensuring all activated LoRAs contribute equally and leveraging scalable RL-based optimization, ReMix establishes new state-of-the-art accuracy and parameter efficiency for multi-task LLM finetuning (2603.10160).