- The paper presents a unified control-theoretic framework for fine-tuning diffusion models using the LS-MDP formulation.
- It introduces f-divergence-regularized policy gradient, PPO, and reward-weighted regression algorithms that optimize terminal objectives while preserving baseline fidelity.
- The innovative parameterization, combining a fixed pretrained backbone with a lightweight side network, achieves high quality-efficiency trade-offs in text-to-image alignment.
Diffusion Controller: A Unified Control-Theoretic Framework for Fine-Tuning Diffusion Models
Motivation and Theoretical Framework
The paper "Diffusion Controller: Framework, Algorithms and Parameterization" (2603.06981) advances a unified control-theoretic perspective for controllable generation in diffusion models. It addresses the lack of a theoretically grounded framework underpinning the array of heuristic methods currently leveraged for fine-tuning pretrained diffusion models, particularly for tasks such as preference alignment and constrained image synthesis.
The central theoretical innovation is casting the reverse diffusion process as a state-only stochastic control problem within the linearly-solvable Markov Decision Process (LS-MDP) formalism. Unlike standard MDP formulations that introduce explicit actions, the LS-MDP framework controls the reverse-time transition kernels directly. Here, the pretrained model acts as the uncontrolled (passive) baseline, while control corresponds to reweighting the reverse transition kernels, penalized by a general f-divergence term to balance reward optimization and fidelity to the original generative process.
This formalism enables a principled derivation of both algorithmic strategies and model parameterizations, grounding existing techniques such as PPO-style updates and reward-weighted regression within a unifying mathematical framework.
Practical Algorithms: Policy Gradient, PPO, and Reward-Weighted Regression
The LS-MDP characterization leads to multiple fine-tuning algorithms suitable for scenarios where only terminal reward feedback is available (e.g., via human preference or reward models):
- f-divergence-regularized policy-gradient algorithms: These generalize policy gradient methods for the diffusion setting, enabling proximal updates (PPO variants) that stably optimize for terminal objectives (e.g., preference alignment) while constraining deviation from the pretrained model.
- Reward-weighted regression objectives: The authors derive a family of reward-weighted regression losses, showing that—under the KL-regularizer—these objectives preserve the minimizer of the original diffusion fine-tuning problem. In practice, this leads to sharper, more efficient preference alignment compared to naive reward-weighting.
Together, these algorithms allow direct optimization of text-to-image models using preference signals or learned reward models, formalizing previously heuristic-driven approaches.
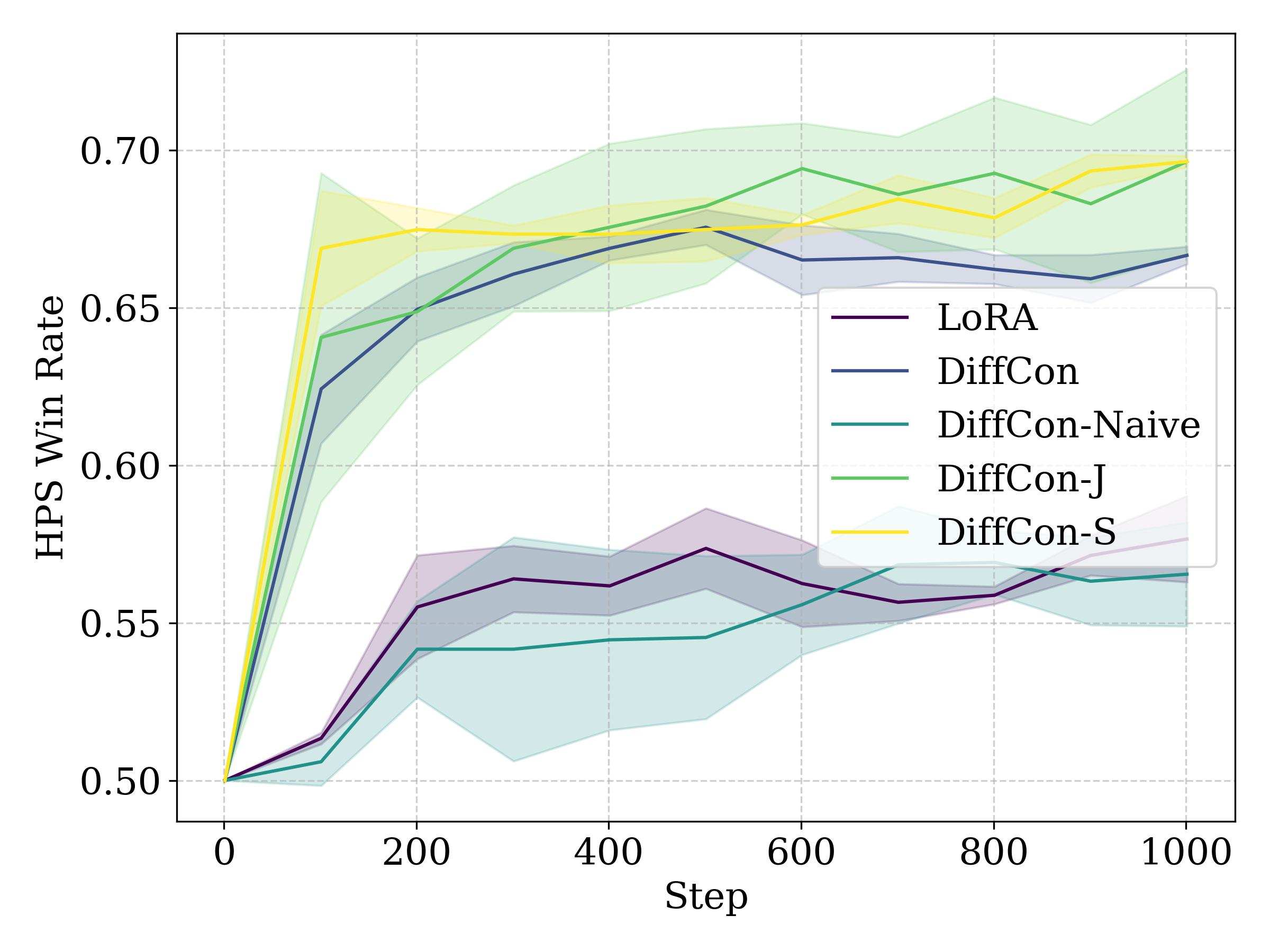
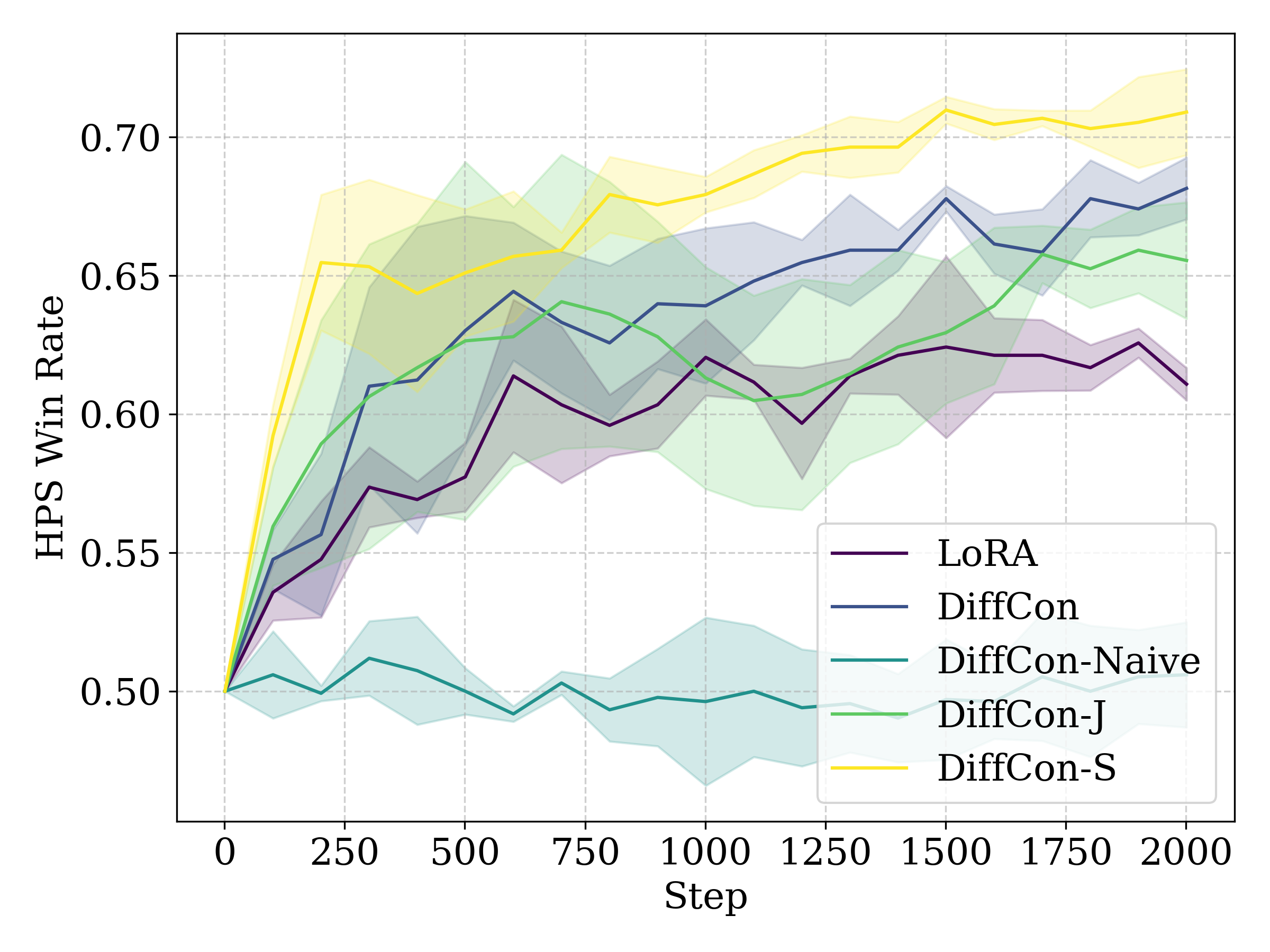
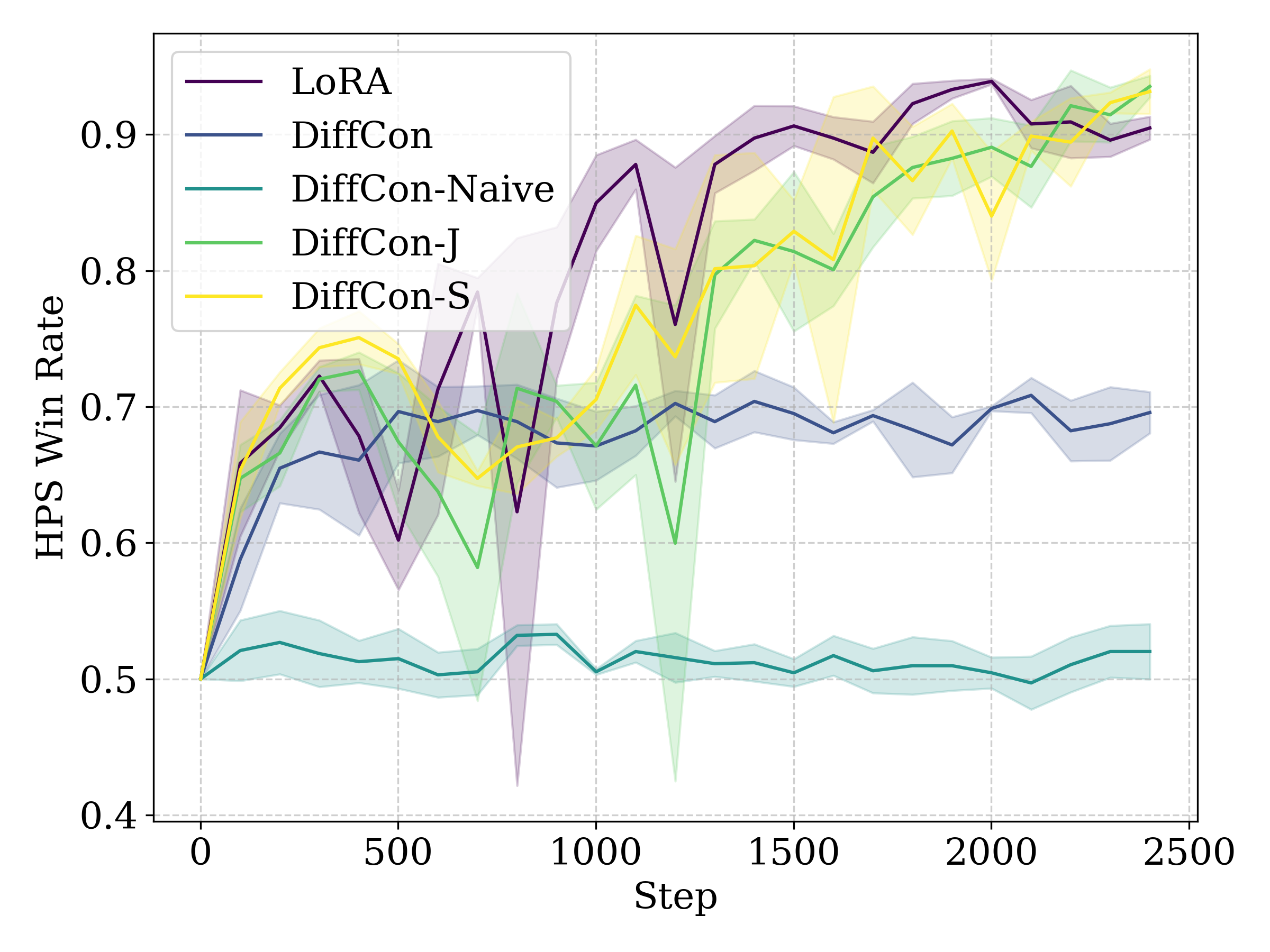
Figure 1: Curves of HPS-v2 win rate against the pretrained model for SFT (left), RWL (middle), and PPO (right).
Model Parameterization: Structured Score Decomposition
A central theoretical insight is the structural characterization of optimal reverse diffusion within LS-MDPs: the optimal score function decomposes into a frozen pretrained baseline plus a lightweight, state-dependent control correction. This inspires a novel DiffCon parameterization:
- The backbone (pretrained) score is kept fixed.
- An add-on “side network” computes correction terms, conditioned on intermediate denoising outputs (e.g., the stepwise pre-backbone reverse mean).
- This architecture supports gray-box adaptation: only intermediate outputs (rather than full internal structure) of the pretrained model are required, making the method applicable even when the backbone is inaccessible. The controller is parameterized efficiently using random Fourier features and transformer/residual blocks on the latent space.
This design both isolates the adaptation to a small network (enhancing stability and interpretability) and achieves high parameter efficiency.
Empirical Evaluation
Experiments are conducted primarily on Stable Diffusion v1.4, evaluating both supervised fine-tuning (SFT) and reinforcement learning-based fine-tuning (RLFT), including reward-weighted loss (RWL) and PPO using a learned human preference reward (HPS-v2).
The principal findings, as measured by HPS-v2 win rate (preference-alignment metric):
- DiffCon consistently outperforms both gray-box and white-box baselines (such as LoRA and simple additive adapters) in SFT and RWL setups, despite having fewer trainable parameters.
- The proposed parameterization yields better quality–efficiency trade-offs, retaining or improving text-image alignment while minimizing computational and memory overhead versus standard approaches.
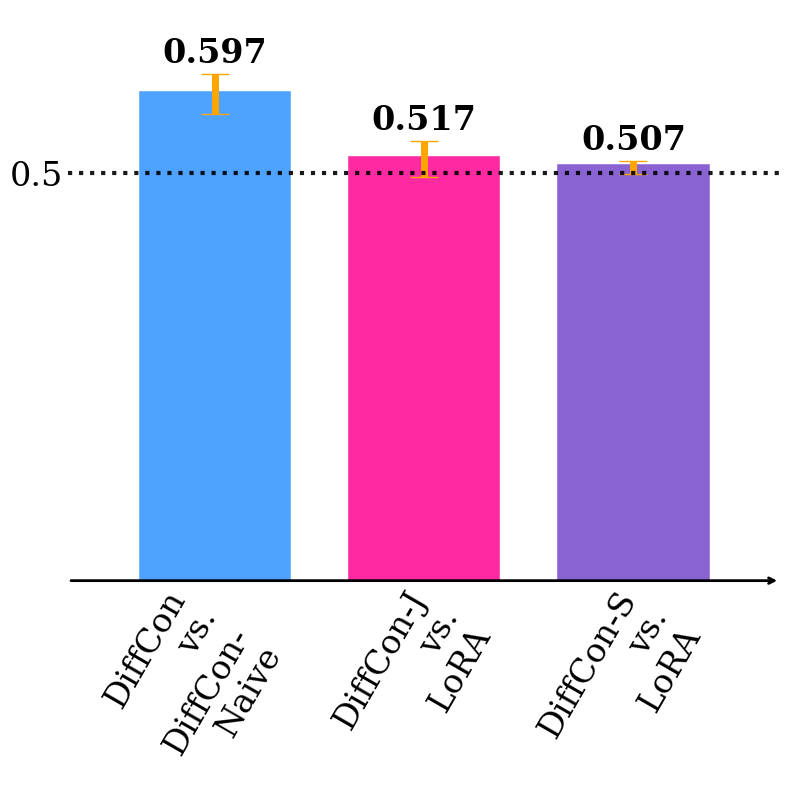
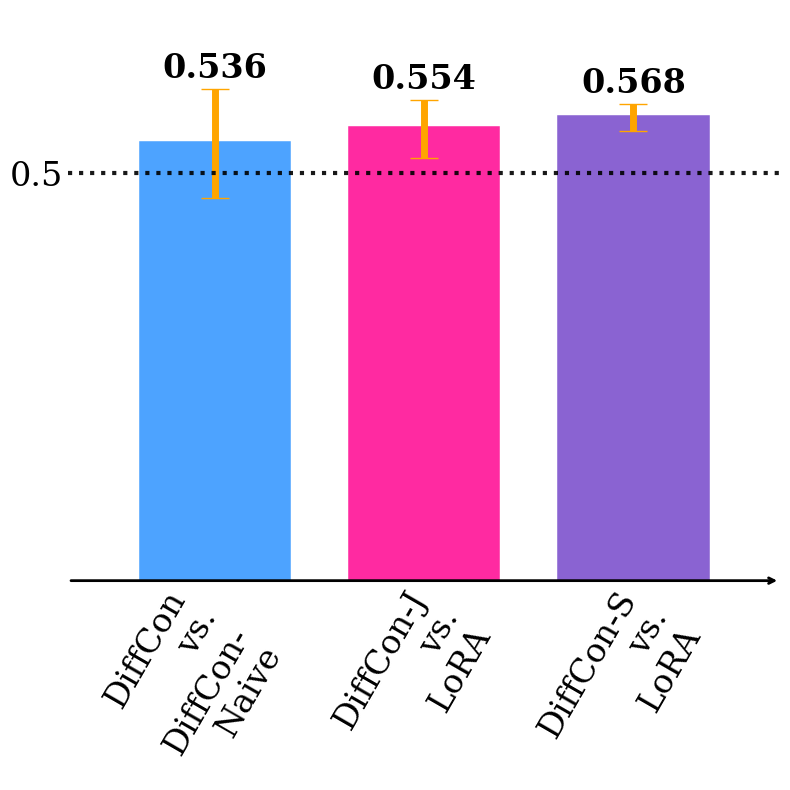
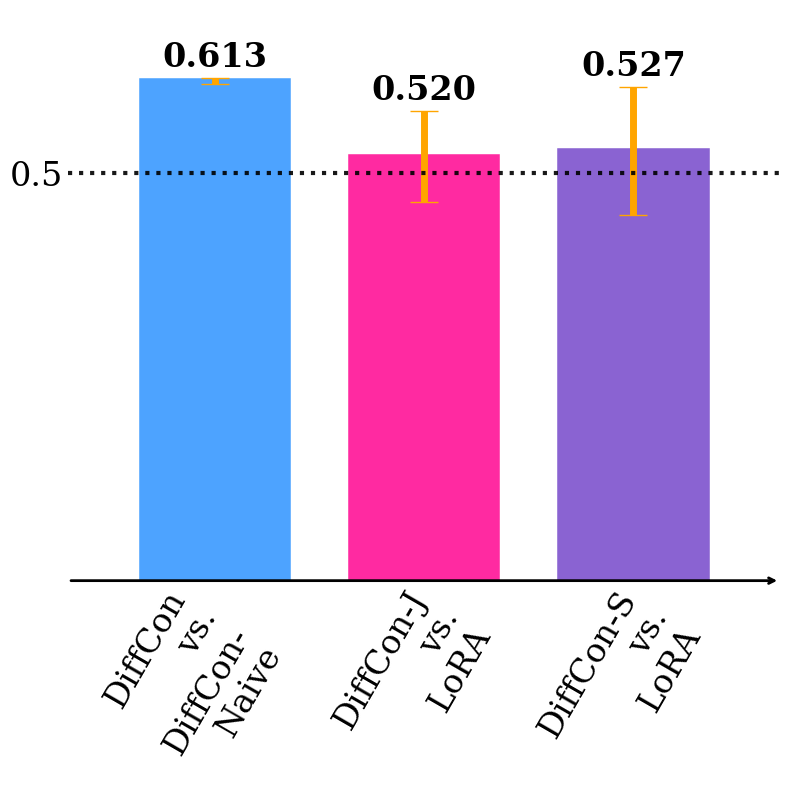
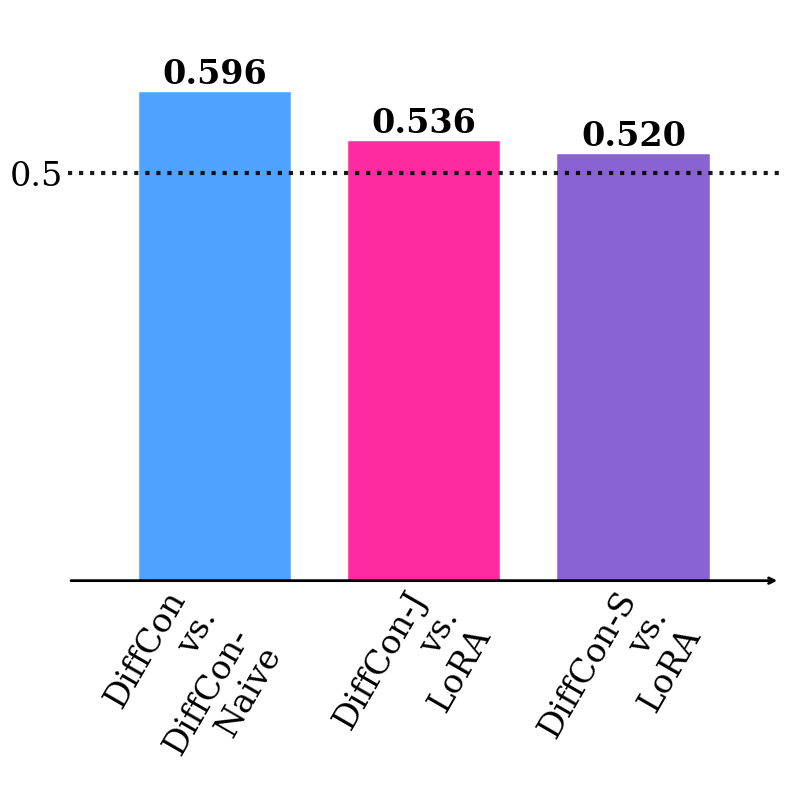
Figure 2: HPS-v2 win rate under supervised fine-tuning (SFT), demonstrating substantial gains using the DiffCon parameterization compared to baselines.
- For RL-based PPO, hybrid white-box architectures combining LoRA and DiffCon reach HPS-v2 win rates exceeding 0.93 after fine-tuning, indicating strong alignment with human preference models.
Qualitative results and an array of ablations confirm the robustness of these trends across hyperparameter configurations, guidance scales, and architecture variants.
Implications and Future Directions
By embedding diffusion fine-tuning in the LS-MDP framework, the approach:
- Unifies a diverse set of controllable generation methods under a rigorous, interpretable formalism.
- Clarifies the regularization–reward trade-offs inherent in diffusion model adaptation.
- Enables parameterization strategies that are both gray-box compatible and highly resource-efficient.
Practically, these advances facilitate rapid, stable deployment of aligned, personalized, or safety-constrained diffusion models, even in restricted-access settings. Theoretically, the interface between stochastic control and deep generative modeling is substantially clarified, enabling rigorous analysis, convergence guarantees, and further algorithmic innovation.
Potential future avenues include:
- Extending the LS-MDP fine-tuning formalism to multimodal, multi-agent, or sequential tasks (e.g., video diffusion, 3D generative models).
- Adapting the controller parameterization for more general forms of adaptation, such as safety alignment, domain transfer, and black-box continual learning.
- Leveraging the effective decomposition for interpretability and theoretical understanding of generative alignment processes.
Conclusion
The Diffusion Controller framework (2603.06981) presents a comprehensive control-theoretic approach to fine-tuning diffusion models, yielding new learning algorithms and a practical, efficient parameterization. Its unified LS-MDP view draws connections between policy regularization, stochastic control, and gray-box adaptation, setting a foundation for more principled, robust, and efficient controllable diffusion generation across a broad array of AI applications.