- The paper introduces the AtS protocol that dynamically updates factuality benchmarks using agentic verifiers to provide evidence-based adjudication.
- The methodology demonstrates a rise in expert accuracy from 60.8% to 90.9% and validates the scalability of agent-only auditing for deep research synthesis.
- Comparative results show that DeepFact-Eval outperforms snippet-based pipelines by achieving up to 87.2% accuracy and strong cross-dataset transfer.
DeepFact: Co-Evolving Benchmarks and Agents for Deep Research Factuality
Motivation and Problem Context
LLMs augmented with search capabilities have attained significant proficiency at generating Deep Research Reports (DRRs), which require high-level synthesis and cross-document reasoning. Evaluating the factuality of such DRRs has emerged as a core bottleneck for practical deployment in scientific and engineering applications. Prevailing fact-checkers and evaluation benchmarks are constructed around short, factoid-style claims, and often fall short in handling long-form, multi-hop research synthesis. The reliability of these static, expert-annotated benchmarks has not been rigorously validated for cognitively intensive tasks, resulting in potential miscalibration of factuality metrics.
Failure Modes of Static Benchmarking
The standard paradigm treats human expert annotations as authoritative “gold labels” against which verifiers are scored. The authors demonstrate in a controlled PhD-level study that this assumption is brittle: even domain-matched experts, under realistic cognitive load, achieve only 60.8% accuracy on micro-gold “known answer” claims (i.e., adversarially designed supported and unsupported statements) embedded within DRR annotation tasks. This finding exposes fundamental flaws in both static benchmarking and the perceived infallibility of expert annotation for tasks requiring deep, context-rich reasoning. Expertise is highly fragmented; multi-expert adjudication is impractical at DRR scale due to scarcity, cost, and domain drift. This unreliability directly undermines the foundation of current factuality evaluation.
Audit-then-Score (AtS): Dynamic Benchmarking Protocol
To address the limits of static benchmarks, the paper introduces Evolving Benchmarking via Audit-then-Score (AtS). AtS operationalizes benchmarking as a co-evolving protocol: agentic verifiers (“Challengers”) challenge existing labels by submitting evidential proposals when a discrepancy is observed; a designated Auditor (human expert or trusted agent) adjudicates these proposals based on the quality and completeness of presented evidence. Successful challenges update the consensus ground truth, and all models are scored against this refined, versioned benchmark.
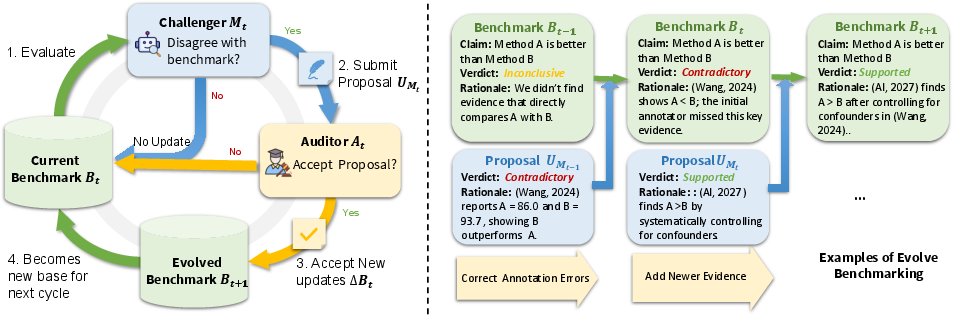
Figure 1: AtS workflow: Unlike static benchmarks, AtS dynamically updates ground truth by adjudicating disagreements between verifiers and current labels.
This architecture allows for longitudinal improvement in data quality, rationales, and decisional traceability. Empirically, human expert micro-gold accuracy rises monotonically to 90.9% across four AtS rounds, confirming that experts are far more reliable in the role of auditors—when allowed to reflect and adjudicate in the presence of model-generated evidence—than as one-shot labelers.
The DeepFact Suite: Benchmark and Evaluation Agent
The protocol is instantiated concretely as DeepFact-Bench and DeepFact-Eval. DeepFact-Bench is a continually versioned, claim-level factuality benchmark constructed from 944 DRR claims sampled from six high-complexity domains. Each entry includes the original context, current label, and a structured rationale. Its test split comprises 621 claims, including a substantial adversarial micro-gold subset to monitor label drift and annotation quality longitudinally.
DeepFact-Eval, a document-level agentic verifier, is developed with two regimes: an expert-level variant for maximum accuracy, and a “lite” variant that optimizes compute by grouping semantically similar claims for joint evidence retrieval (minimizing redundant queries). Unlike snippet-based pipelines (e.g., SAFE, FactCheck-GPT) or general deep-research agents, DeepFact-Eval interleaves breadth-oriented retrieval with depth-oriented, targeted evidence synthesis and cross-document reasoning.
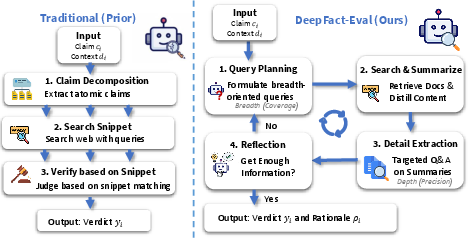
Figure 2: Side-by-side: traditional snippet-based fact-checker pipeline versus DeepFact-Eval’s multi-step retrieval and in-depth reasoning workflow.
Empirical Evaluation
AtS protocol refinement is validated with both human and agent auditors. Critical findings include:
- Audited expert performance surpasses unaided expert annotation: Micro-gold accuracy rises from 60.8% (static) to 90.9% (AtS Round 3) as agents introduce stronger evidence. Experts often learn from correct agent suggestions, and rarely regress by blindly accepting incorrect agent verdicts.
- Agent-only auditing is viable for future scalability: Agents, when used as auditors instead of humans, reliably consolidate improvements in the benchmark, and cross-auditing among agents outperforms the solo baselines of each participant in both weaker→stronger and stronger→weaker pairings.
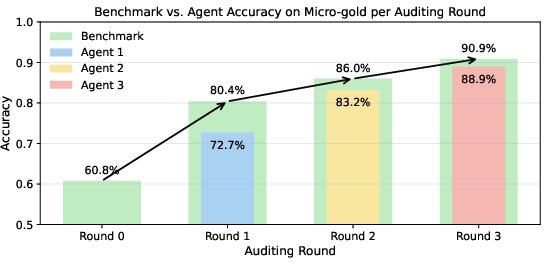
Figure 3: Micro-gold accuracy evolution across AtS auditing rounds. Auditing produces monotonic gains in expert labeling reliability.
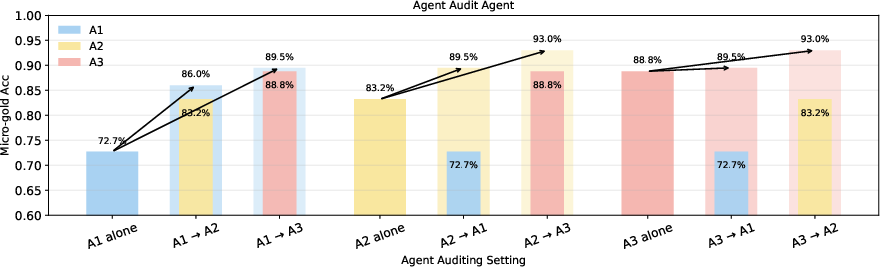
Figure 4: Auditing performance for agent-only, showing that agent auditors reliably improve consensus regardless of the baseline strength of the agent being audited.
Ablations further show that auditing frequency (how many conflicts are actually adjudicated) modulates the speed of quality improvement: near-complete auditing rapidly saturates accuracy, while lower rates require more rounds for convergence. Strictness in revision gating provides only minor marginal benefit, with a potential trade-off in suppressing beneficial corrections.
Comparative Results and Generalization
DeepFact-Eval (GPT-4.1) attains 83.4% accuracy on DeepFact-Bench, a 27.5-point margin over snippet-based pipelines (e.g., SAFE, FactCheck-GPT) and a 14.3-point margin over GPT-Researcher—the strongest prior deep-research agent baseline. The “lite” variant maintains strong accuracy (76.4–77.9%) while reducing cost by 3–5×.
Upgrading to GPT-5 as the backbone provides additional gains (87.2%). Notably, DeepFact-Eval exhibits robust cross-benchmark transfer: on SciFact and Factcheck-Bench, many apparent disagreements reflect original annotation divergence, claim ambiguity, or non-verifiable statements rather than systematic model error. After controlled re-audits of disagreement cases, recalibrated accuracy rises to 94.7% (SciFact) and 93.0% (Factcheck-Bench).
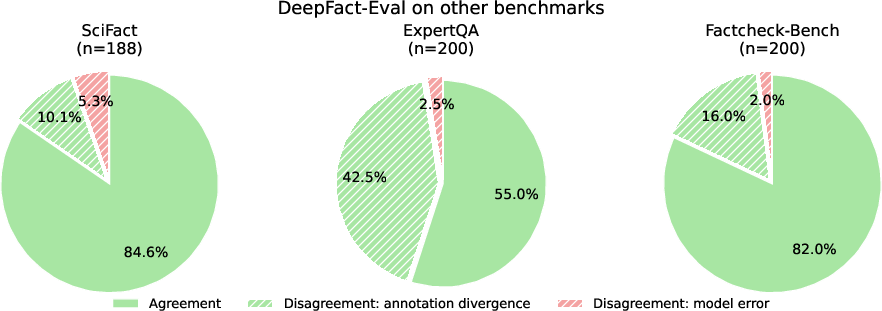
Figure 5: Audit dissects DeepFact-Eval disagreement cases on external datasets, showing that most residual errors are due to annotation discrepancies, not true model failures.
Practical Implications, Limitations, and Future Directions
The DeepFact paradigm—the co-evolution of models and benchmarks—addresses an acute need for evaluation in domains where expertise scarcity and cognitive load render traditional gold-label datasets inadequate. The AtS protocol is cost-efficient and amortizes the overhead of deep expert annotation, as the majority of adjudication and improvement occurs in the early rounds, with diminishing human effort in later rounds.
Practically, DeepFact-Bench and DeepFact-Eval instantiate a scalable, transparent infrastructure for ongoing “living” evaluation, necessary as LLMs reach or surpass expert-level literature reasoning capabilities. This lays the foundation for fully autonomous, continuously self-improving benchmarks driven by agent–agent auditing, with periodic expert involvement to ensure calibration.
However, DeepFact-Eval is fundamentally constrained to verification against the extant literature. It is not equipped to conduct original experimental science, and the computational burden of thorough, context-rich verification remains substantial. Real-time or low-latency deployment in decision-critical applications (e.g., clinical, legal, regulatory) is currently limited by this overhead.
Conclusion
DeepFact demonstrates that the factuality bottleneck for research-centric LLM outputs is not due to inherent limitations in modeling, but to the brittleness of static benchmarks and expert annotation workflows. The AtS protocol enables dynamic, evidence-driven evaluation where both agentic verifiers and benchmark labels iteratively improve in a traceable, versioned process. DeepFact-Bench and DeepFact-Eval establish new state-of-the-art accuracy on DRR factuality evaluation, with strong evidence for transfer, modular maintainability, and extensibility toward fully autonomous benchmarking ecosystems.