RoboPocket: Improve Robot Policies Instantly with Your Phone
Abstract: Scaling imitation learning is fundamentally constrained by the efficiency of data collection. While handheld interfaces have emerged as a scalable solution for in-the-wild data acquisition, they predominantly operate in an open-loop manner: operators blindly collect demonstrations without knowing the underlying policy's weaknesses, leading to inefficient coverage of critical state distributions. Conversely, interactive methods like DAgger effectively address covariate shift but rely on physical robot execution, which is costly and difficult to scale. To reconcile this trade-off, we introduce RoboPocket, a portable system that enables Robot-Free Instant Policy Iteration using single consumer smartphones. Its core innovation is a Remote Inference framework that visualizes the policy's predicted trajectory via Augmented Reality (AR) Visual Foresight. This immersive feedback allows collectors to proactively identify potential failures and focus data collection on the policy's weak regions without requiring a physical robot. Furthermore, we implement an asynchronous Online Finetuning pipeline that continuously updates the policy with incoming data, effectively closing the learning loop in minutes. Extensive experiments demonstrate that RoboPocket adheres to data scaling laws and doubles the data efficiency compared to offline scaling strategies, overcoming their long-standing efficiency bottleneck. Moreover, our instant iteration loop also boosts sample efficiency by up to 2$\times$ in distributed environments a small number of interactive corrections per person. Project page and videos: https://robo-pocket.github.io.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
RoboPocket: Improve Robot Policies Instantly with Your Phone — A Simple Explanation
Overview
This paper introduces RoboPocket, a way to teach robots better and faster using a regular smartphone. Instead of needing a real robot next to you, the phone uses augmented reality (AR) to show you what the robot would try to do. You can spot likely mistakes before they happen, record helpful examples, and the robot’s “brain” (its software policy) updates within minutes. The goal is to make robot learning safer, quicker, and doable by many people—not just experts in labs.
Key Questions the Paper Tries to Answer
The paper focuses on three simple questions:
- How can we collect the right kind of examples that a robot truly needs to learn from?
- How can regular people (not just experts) help improve robot skills safely and easily?
- How can we update a robot’s “brain” immediately—without using a real robot?
How RoboPocket Works (In Everyday Terms)
Think of teaching a robot like coaching a player in a game:
- The “policy” is the robot’s playbook—the rules it follows to act.
- “Imitation learning” means the robot learns by copying human demonstrations.
- A big problem: when the robot ends up in situations it didn’t see in training, it can make bad mistakes (this is called “distribution shift,” like being asked a test question you never practiced).
RoboPocket tackles this with a phone-based system that acts like a coach with instant replay and a practice mode:
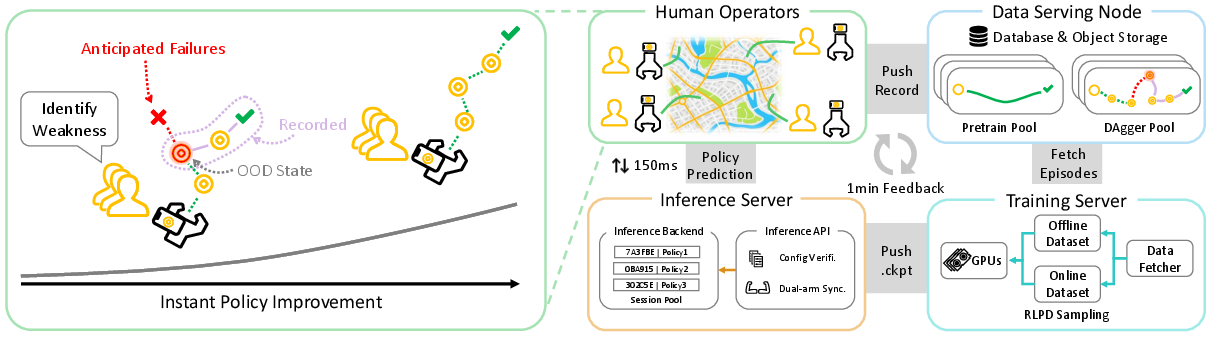
- Augmented Reality (AR) Visual Foresight: On your phone screen, you see the robot’s planned path drawn into the real world—like a line of “coins” to follow. It’s as if you can peek into the robot’s mind.
- Remote Inference: Your phone sends what it sees to a computer server with a powerful GPU. The server thinks like the robot and sends back its next moves. This happens fast (under 150 ms), so it feels smooth.
- Proactive Corrections: If you see the plan looks wrong, you can interrupt and record the right way to do it immediately—no real robot needed.
- Instant Policy Updates: As you collect “fix-it” examples, the system fine-tunes the robot’s brain right away by mixing old data (to avoid forgetting) with your new targeted examples (to fix weaknesses).
- Quality Checks While Recording: The app warns you if the phone’s tracking gets shaky or if a motion wouldn’t be possible for the real robot. That way, you collect clean, useful data.
- Realistic Handheld Tool: You hold a 3D-printed gripper designed to feel and behave like a real robot gripper, so demonstrations transfer well to actual robots later.
- Multi-Device Sync: Two phones can work together for two robot arms, keeping timing and positions aligned.
Helpful analogies for tricky terms:
- AR: Like Pokémon Go, but instead of creatures, you see the robot’s planned motion overlaid on the real world.
- SLAM/VIO (how the phone knows where it is): Like a super-stable phone GPS for indoors that uses the camera and motion sensors to track position.
- Online fine-tuning: The robot studies its newest mistakes right away, not weeks later.
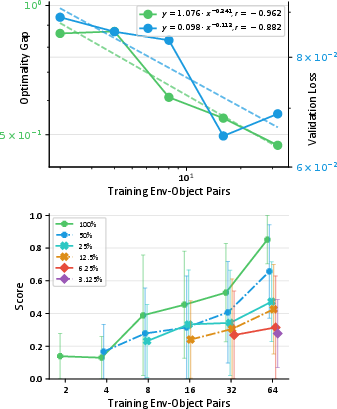
- Data scaling laws: In general, more and more varied examples help; RoboPocket follows that pattern, but also beats it by targeting the robot’s weak spots.
Main Findings and Why They Matter
Here are the key results the authors report:
- Faster, cleaner data collection: Compared to a popular handheld method, RoboPocket cut collection time and avoided noisy tracking spikes. That means more good data in less time.
- Matches known “more data helps” behavior—and improves on it: Their data follows standard scaling laws (more diverse data → better performance), but RoboPocket goes beyond that by focusing on failure cases the robot is likely to face.
- Up to 2× better data efficiency: With AR feedback and instant updates, they needed about half as much data to reach similar or better results compared to normal “collect first, train later” methods.
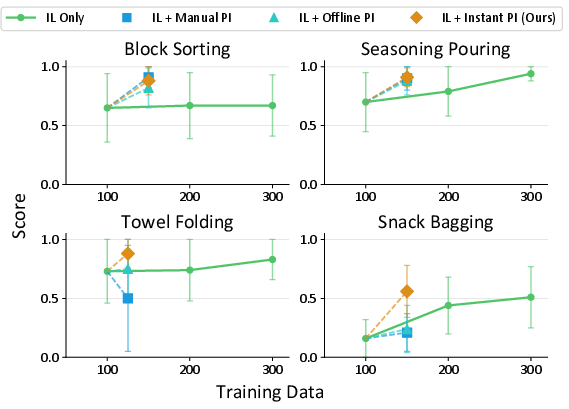
- Works across tough tasks:
- Block sorting (long, step-by-step task): Found and fixed ordering mistakes.
- Seasoning pouring (big wrist rotations): Kept accuracy after twisting motions.
- Towel folding (soft, flexible object): Helped the robot pick the right corners.
- Snack bagging (two arms): Targeted confusing cases and improved coordination.
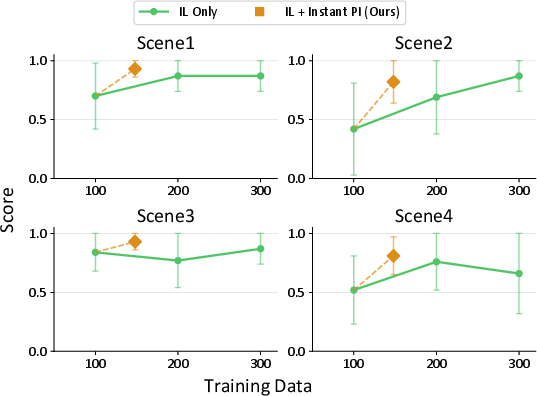
- Scales across people and places: Four different users in four rooms each gave just 12 targeted corrections. Success rates jumped—sometimes nearly doubling—showing the system works in the wild, not just in labs.
Why this is important:
- You don’t need a room full of robots or a PhD to help teach a robot.
- It’s safer—no risky robot failures while you’re learning.
- Feedback is instant, which makes teaching more focused and effective.
What This Could Mean for the Future
If many people can teach robot skills with just their phones:
- Robots could learn new tasks faster and adapt to new homes, stores, or factories more easily.
- Crowdsourced teaching becomes realistic: lots of people contribute small, high-quality fixes, and the robot improves quickly.
- This could speed up the development of general-purpose robots that can work in many different places.
Simple limitations and next steps:
- The handheld tool is like a standard two-finger gripper—it’s not for super delicate finger tricks yet.
- The setup can be a bit bulky and tiring for long sessions.
- Future versions might use lighter gear (like AR glasses) for even more natural teaching.
Overall, RoboPocket puts a “robot coach” in your pocket. By showing you what the robot plans to do and letting you correct it on the spot—without the robot being there—it makes teaching robots faster, safer, and open to everyone.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide follow‑up research:
- External validity across tasks and embodiments: The system is evaluated on four manipulation tasks (one bimanual) with a single arm model (Flexiv Rizon 4) and a Robotiq 2F‑85 gripper; it is unclear how well the approach transfers to different robot arms, mobile manipulators, humanoids, or tasks requiring dexterous in‑hand manipulation or tool use.
- Dependence on parallel‑jaw gripper isomorphism: The handheld gripper is tailored to 2F‑85 geometry/dynamics; the method’s applicability to other end‑effectors (suction, multi‑finger hands) and the impact of non‑isomorphic hardware on data transferability are not studied.
- Dynamics and contact mismatch: While passive DoFs are replicated, there is no quantitative analysis of how residual differences in compliance, friction, and contact dynamics between the handheld rig and the real robot affect policy performance, especially in contact‑rich or force‑critical tasks.
- Limited tactile/force sensing: The system captures gripper width but lacks tactile or force/torque sensing; it remains unknown whether the approach can support tasks that need force cues, contact timing, or slip detection, and how to incorporate such signals into AR feedback and policy training.
- Visual sensing constraints: The approach relies on monocular RGB with a fisheye adapter; the role of depth sensing (or lack thereof) in long‑horizon precision tasks, occlusions, or 3D geometry ambiguity is not explored.
- AR Visual Foresight fidelity: There is no quantitative evaluation of the alignment accuracy between projected trajectories and the real scene under different intrinsics/extrinsics, lighting, motion blur, or lens distortion errors, nor how misalignment biases data collection.
- Uncertainty and intent visualization: The AR interface visualizes a single trajectory (“coins”) but does not convey model uncertainty or alternative modes; it is unclear how to expose confidence, failure likelihood, or multi‑modal plans to guide higher‑value corrections.
- Human‑factors evaluation: Beyond small user studies, the paper does not assess cognitive load, learning curves for non‑experts, inter‑user variability, or whether AR foresight systematically improves targeting of failure modes versus simpler UIs.
- Gamification effects and Goodhart’s law: The “follow the coins” paradigm might steer collectors toward trajectories that satisfy the UI rather than the underlying task; the risk of interface‑induced bias in the collected distribution is unquantified.
- SLAM/VIO robustness limits: Although invalid frames are flagged, there is no systematic study of failure rates under texture‑poor, reflective, dynamic, or low‑light scenes, nor recovery strategies when tracking is intermittently lost.
- Map merging and scaling: Multi‑device spatiotemporal synchronization is evaluated for two devices; it is unknown how the system scales to larger multi‑arm setups or many users in the same space, and how map conflicts/drift are handled over long sessions.
- Latency sensitivity and network variability: Reported round‑trip inference latency (<150 ms) is measured on standard Wi‑Fi; the impact of higher latency, jitter, or intermittent connectivity (e.g., cellular, congested networks) on usability and data quality is not characterized.
- Server scalability and cost: The backend’s ability to handle many concurrent users/sessions, autoscaling policies, GPU utilization, and operational costs are not assessed.
- Online finetuning schedule and stability: The 50/50 sampling between offline and online data is fixed; there is no ablation on mixing ratios, update frequency N, batch sizes, or adaptive weighting, nor analysis of stability, convergence, or susceptibility to overfitting/forgetting.
- Theoretical grounding vs. DAgger: While inspired by interactive IL, there is no theoretical analysis of whether robot‑free instant iteration approximates DAgger’s on‑policy data distribution, nor bounds on compounding error or convergence.
- Coverage vs. corrections: Criteria for when to stop collecting corrective data, diminishing returns of additional corrections, and how to prioritize which failure modes to target remain unspecified.
- Evaluation depth and statistical power: Several comparisons use small sample sizes (e.g., 10 demos in a study) with limited variance reporting; broader statistical validation across users, seeds, and environments is missing.
- Generality of scaling‑law findings: Scaling‑law validation is shown for a single “Mouse Arrangement” task; it is unclear whether the same exponents/curves hold for deformable, long‑horizon, or bimanual tasks.
- Transition from robot‑free to robot‑executed: The correlation between AR‑visualized “improved intent” and actual improvement on hardware is not quantified; a gap analysis between AR foresight updates and real robot execution outcomes is missing.
- Safety upon deployment: Although iteration is “robot‑free,” eventual deployment occurs on a real robot; there are no safety checks or guarantees that AR‑guided corrections will not introduce unsafe behaviors when executed on hardware.
- Camera viewpoint mismatch: The handheld sensor viewpoint may differ from the robot’s wrist camera at deployment; the effect of viewpoint/domain mismatch (lighting, mounting height, occlusions) on policy transfer is not examined.
- Calibration procedures and drift: The paper does not detail fisheye calibration robustness, re‑localization after VIO loss, or cumulative drift over long sessions—and how these affect pose/action accuracy and dataset integrity.
- Data quality auditing at scale: Beyond real‑time flags and replay, there is no automated, post‑hoc quality control for large datasets (e.g., anomaly detection, outlier pruning, success labeling), especially in crowd‑sourced settings.
- Labeling and outcome feedback: Policies are trained from demonstrations without explicit outcome labels; how successes/failures are recorded, weighted, or filtered in online finetuning is unspecified.
- Privacy and security: Continuous streaming of video and sensor data to remote servers and BLE telemetry is not accompanied by a discussion of data privacy, encryption, user consent, or security against spoofing/interference.
- Battery, thermal, and ergonomics: The iPhone edge‑compute and AR rendering may induce heat and battery drain; prolonged‑use studies, drop rates, and their effects on data quality are not reported.
- Hardware reproducibility and durability: While low BOM cost is cited, there is no systematic evaluation of assembly tolerances, calibration repeatability, mechanical wear, or cross‑site reproducibility.
- Benchmarking vs. related AR‑in‑the‑loop systems: The method is not empirically compared against contemporaneous AR feedback tools (e.g., ARCap) or alternative interactive UIs to isolate which design choices drive gains.
- Bimanual coordination limits: Only one bimanual task is tested; handling of mutual occlusions, inter‑arm collisions, and timing jitter in tighter coordination tasks remains unexplored.
- Extending to deformables: Towel folding is a single deformable task; generalization to diverse cloth materials, garments, cables, or soft objects with varying mechanical properties is not studied.
- Handling adversarial/low‑quality users: In distributed settings, mechanisms for detecting, weighting, or excluding low‑quality or adversarial contributions are not described.
- Versioning and dataset/model governance: Policies are updated continuously, but procedures for dataset versioning, model provenance, rollback, and conflict resolution across multiple simultaneous collectors are unspecified.
- UI accessibility and inclusivity: The system’s effectiveness for users with different physical abilities or AR accessibility needs is not addressed.
- Criteria for foresight horizon length: How far ahead the trajectory is visualized, and how horizon length impacts intervention timing, data utility, and user comprehension, is not analyzed.
- Visualizing long‑horizon state: For multi‑step tasks, the interface does not clarify task progress memory or subgoal intentions; how to communicate long‑horizon plans to users remains an open design question.
Practical Applications
Immediate Applications
The following use cases can be deployed with the paper’s current system components (iPhone + ARKit app, isomorphic handheld gripper, remote inference server, online finetuning, and data verification).
- Industrial “last‑mile” policy tuning on the shop floor (Robotics, Manufacturing)
- Use case: Technicians visualize a robot policy’s planned trajectory in AR at a cell, proactively collect corrective demos with the handheld gripper, and push an updated model before running hardware.
- Tools/workflows: RoboPocket iOS app; AR Visual Foresight; remote inference + online finetuning; ROS2 deployment hook for weight updates.
- Dependencies/assumptions: Reliable Wi‑Fi/LAN (<150 ms RTT); GPU training server; target robot with a parallel‑jaw gripper comparable to Robotiq 2F‑85; safety review before activating updated policies.
- Rapid SKU changeovers for pick‑and‑place/kit‑packing lines (Robotics, Logistics)
- Use case: Line change to new parts/packaging; operators gather targeted failure-recovery data (e.g., new object shapes, box positions) and fine‑tune in minutes without stopping the robot for long.
- Tools/workflows: Isomorphic handheld gripper; AR Trajectory Replay; weighted sampling finetuning (RLPD‑like) mixing base and new data.
- Dependencies/assumptions: Proper fisheye calibration; stable SLAM (texture in scene or markers); MLOps gate to approve updates.
- In‑the‑wild policy adaptation for distributed sites (Robotics, Field Service)
- Use case: Field teams at different facilities collect a handful of interactive corrections each; the backend aggregates and pushes a generalized model across sites.
- Tools/workflows: Multi‑user data streaming; asynchronous training and model distribution; site‑tagged data for governance.
- Dependencies/assumptions: Data governance and privacy policy; per‑site evaluation checklist; consistent robot camera viewpoint.
- Bimanual setup prototyping and calibration (Robotics, Assembly/Packaging)
- Use case: Two phones with spatiotemporal synchronization prototype bimanual behaviors (e.g., bagging), identify occlusion/coordination failures in AR, and collect target fixes.
- Tools/workflows: Shared ARKit world maps; on‑device IK feasibility checks; dual‑stream data capture.
- Dependencies/assumptions: 5 ms clock sync; adequate texture or fiducials; bimanual robot with synchronized cameras.
- Pre‑deployment safety/QA checks via AR foresight (Robotics, EHS)
- Use case: Safety officers visualize intended trajectories near fixtures, jigs, and people to flag near‑collisions before powering actuators.
- Tools/workflows: AR Visual Foresight overlay; distortion‑aware rendering; IK singularity and joint‑limit warnings.
- Dependencies/assumptions: Accurate hand‑eye calibration; conservative geofence policies; documented review process.
- Fast onboarding for new environments (Warehousing/Retail back‑of‑house)
- Use case: Staff adapt grasping, pouring, or sorting policies to new shelves, lighting, or containers during setup of a new store/warehouse zone.
- Tools/workflows: Gamified AR “coin path” guidance to elicit relevant trajectories; immediate model refresh.
- Dependencies/assumptions: Adequate bandwidth; minimal operator training; policy compatible with wrist‑camera views.
- Customer support and RMA triage for robot vendors (Robotics, SaaS/Support)
- Use case: Support engineers collect targeted corrective data at a customer site with a phone, reproduce failures via AR foresight, and deliver a patched model quickly.
- Tools/workflows: Ticket‑linked data sessions; versioned model artifacts; rollback mechanisms.
- Dependencies/assumptions: Customer consent; secure upload; reproducible environment tags.
- Robotics education and training (Education)
- Use case: Students observe “policy intent” in AR, perform interactive corrections, and study covariate shift without access to expensive robot fleets.
- Tools/workflows: Course modules using RoboPocket app; sandbox inference servers; rubric tied to scaling‑law experiments.
- Dependencies/assumptions: iOS devices with ARKit; supervised environments; curated starter datasets.
- Lab/research data engine for manipulation (Software/Research)
- Use case: Rapid experiment cycles: collect targeted OOD data, online finetune, and validate across long‑horizon/deformable tasks.
- Tools/workflows: Diffusion Policy training; dataset registry; reproducible pipelines.
- Dependencies/assumptions: GPU availability; consistent camera intrinsics; version control for models/data.
- Vendor‑neutral AR policy visualization for integrators (Software Tools)
- Use case: ROS2 extension or plugin that renders any policy’s predicted end‑effector path in AR for debug and demo.
- Tools/workflows: Distortion‑aware AR renderer; ROS2 bridge; generic inference API.
- Dependencies/assumptions: ROS graph access; calibration between phone and robot frames.
- Home/office pilot adaptation by technicians (Facilities/Service Robotics)
- Use case: Technicians adapt policies for office/home tasks (e.g., sorting office supplies) offline via AR foresight before enabling robot execution.
- Tools/workflows: Targeted corrections for specific objects/placements; on‑site fine‑tune then push live.
- Dependencies/assumptions: Policy guardrails; data privacy in occupied spaces; task within parallel‑jaw capability.
- Acceptance testing and A/B evaluation without robot motion (Robotics QA)
- Use case: Compare two policy checkpoints’ AR‑rendered intents against edge cases before choosing which to deploy.
- Tools/workflows: Side‑by‑side AR overlays; scenario catalogs; automatic metric logging.
- Dependencies/assumptions: Identical camera alignment across tests; curated edge‑case scenes.
Long‑Term Applications
These opportunities require additional R&D, scaling, or ecosystem maturation (e.g., broader hardware support, regulatory frameworks, or expanded sensing).
- At‑home personalization of consumer robots (Consumer Robotics, Daily Life)
- Use case: Owners use a phone to adapt cooking, laundry (e.g., towel folding), or tidying behaviors to their unique home layouts.
- Tools/products: Consumer RoboPocket‑like app with privacy controls; on‑device or cloud finetuning.
- Dependencies/assumptions: Wider gripper/tool support; robust on‑device SLAM under clutter; simple UX and safety interlocks.
- Crowdsourced OOD correction loops at scale (Robotics Platforms)
- Use case: Opt‑in networks of users collect short, targeted corrections that continuously improve a shared generalist model.
- Tools/products: Data contribution SDK; quality scoring; reward or credit system; federated or privacy‑preserving learning.
- Dependencies/assumptions: Strong data governance; bias controls; differential privacy; robust validation to avoid catastrophic regressions.
- Foundation model pretraining for manipulation (AI for Robotics)
- Use case: Aggregate massive, diverse “pocket‑collected” interaction data across tasks and environments to pretrain generalist manipulation models.
- Tools/products: Cross‑site data lake; standardized schemas; scalable diffusion/transformer training.
- Dependencies/assumptions: Inter‑vendor data standards; legal/IP frameworks; compute scale and cost control.
- Continuous learning MLOps in factories (Industry 4.0)
- Use case: Always‑on closed loops where production anomalies trigger targeted data collection and safe model updates during micro‑downtimes.
- Tools/products: CI/CD for robot policies; canary and rollback; safety simulators; A/B orchestration.
- Dependencies/assumptions: Enterprise MLOps maturity; formal verification or guardrail policies; union/EHS buy‑in.
- Assistive and rehabilitation robots trained by caregivers (Healthcare)
- Use case: Clinicians/caregivers demonstrate bedside tasks safely with a handheld mock and AR intent, then deploy on assistive robots.
- Tools/products: Medical‑grade handheld; compliant grippers; audit logs; user‑specific profiles.
- Dependencies/assumptions: Regulatory approvals (e.g., FDA/CE); infection control; fail‑safe autonomy; protected health information handling.
- Agriculture and outdoor task adaptation (Agriculture/Energy)
- Use case: Farmers/technicians tailor grasping and handling tasks (harvesting, tool use) in situ with AR guidance.
- Tools/products: Ruggedized phones; marker‑assisted tracking; weather‑robust sensors.
- Dependencies/assumptions: Outdoor‑robust VIO (or fiducials/RTK); variable lighting handling; suitable end‑effectors.
- AR “policy intent” UI for mobile and industrial autonomy (Material Handling)
- Use case: Forklifts, AMRs, and manipulators expose predicted paths/grasps in AR for human‑in‑the‑loop oversight and training.
- Tools/products: Cross‑platform AR SDK; standardized intent APIs; safety overlays.
- Dependencies/assumptions: V2X connectivity; clear human factors guidelines; liability frameworks.
- Handheld “trainer” shipped with every robot (Robot OEMs)
- Use case: OEMs include isomorphic handhelds so customers can adapt policies on day‑one and during reconfiguration.
- Tools/products: OEM‑branded trainer; guided setup flows; pre‑calibrated meshes.
- Dependencies/assumptions: Supply chain for attachments; cross‑camera/viewpoint compatibility; support playbooks.
- Policy marketplace with regional/task variants (Platforms)
- Use case: Curated “policy app store” where vendors publish and users fine‑tune/subscribe to localized variants; AR previews before purchase.
- Tools/products: Marketplace backend; licensing; telemetry and update channels.
- Dependencies/assumptions: IP protection; safety certification; interoperability standards.
- Wearables for hands‑free iteration (AR glasses/exoskeletons)
- Use case: Replace phone with AR glasses for egocentric foresight; integrate exoskeletons or tactile sensors for richer corrections.
- Tools/products: Egocentric SLAM; tactile/force streaming; ergonomic interfaces.
- Dependencies/assumptions: Mature AR wearables; multi‑sensor fusion; comfort and fatigue addressed.
- Higher‑dexterity and tool‑use training (Advanced Manipulation)
- Use case: Extend isomorphism beyond parallel‑jaw to multi‑finger hands and tool attachments for complex tasks.
- Tools/products: Modular handheld kits; physics‑aware simulation alignment; richer IK/feasibility checks.
- Dependencies/assumptions: Better hand‑eye and dynamics matching; tactile/force capture; advanced policies.
- Regulatory audit and certification tooling (Compliance/Safety)
- Use case: Maintain auditable traces of AR‑reviewed intents, corrective data, and model diffs for certified deployments.
- Tools/products: Signed data/model lineage; automated risk assessments; change‑control dashboards.
- Dependencies/assumptions: Industry standards for robot ML updates; third‑party certification pathways.
Each application’s feasibility hinges on core assumptions highlighted in the paper: availability of a capable smartphone (ARKit/VIO), accurate fisheye calibration and hand‑eye alignment, robust networking and GPU servers for low‑latency inference/finetuning, embodiment similarity between handheld and target robot (or appropriate domain adaptation), and organizational processes for safety, privacy, and MLOps governance.
Glossary
- Active learning: A data collection paradigm where the system or user targets informative samples to improve the model efficiently. Example: "effectively performing robot-free active learning."
- AR Visual Foresight: An AR-based visualization of a policy’s predicted trajectory to reveal intent and potential failures before execution. Example: "via AR Visual Foresight"
- ARKit: Apple’s AR framework used here for cross-device spatial mapping and alignment. Example: "peer-to-peer map merging protocol in ARKit"
- Augmented Reality (AR): Technology overlaying virtual content on the real world to provide interactive visual feedback. Example: "projecting the policy's intended trajectory back onto the user's screen via Augmented Reality (AR)"
- Behavior Cloning (BC): An imitation learning method that learns a policy by mimicking expert demonstrations. Example: "While Behavior Cloning (BC) scales effectively with offline data"
- Bimanual: Refers to tasks or manipulation involving the coordinated use of two robot arms. Example: "A bimanual task where the robot coordinates two arms to pick up snacks and place them into a bag."
- Catastrophic forgetting: When a model forgets previously learned behaviors after learning new data without proper balancing. Example: "prevents catastrophic forgetting"
- CLIP: A vision-LLM used here as an image encoder for policy learning. Example: "with a CLIP or DINOv2 encoder."
- Covariate shift: A mismatch between the training and deployment state distributions that degrades policy performance. Example: "like DAgger effectively address covariate shift"
- DAgger: An interactive imitation learning algorithm that aggregates on-policy corrections to mitigate distribution shift. Example: "Methods like DAgger"
- Data Scaling Laws: Empirical power-law relationships showing how performance improves as dataset size/diversity grows. Example: "a strong correlation with established Data Scaling Laws"
- DINOv2: A self-supervised vision model used as an image encoder for policies. Example: "with a CLIP or DINOv2 encoder."
- Diffusion Policy: A policy class that models action generation as a denoising diffusion process. Example: "We train all models using Diffusion Policy"
- Domain adaptation: Techniques for transferring models between differing data domains while minimizing performance loss. Example: "without complex domain adaptation"
- Edge computing: Performing computation on-device (at the network edge) to enable low-latency, real-time feedback. Example: "The iOS application acts as an edge-computing hub"
- Embodiment gap: The mismatch between the handheld device and robot hardware that can hurt transfer of learned policies. Example: "to minimize the embodiment gap across both visual and physical domains."
- End-effector: The tool or gripper at a robot arm’s tip that interacts with the environment. Example: "By rendering the end-effector trajectory over the real-world view"
- Field-of-View (FOV): The extent of the observable scene captured by a camera. Example: "The native Field-of-View (FOV) of smartphone cameras is often too narrow"
- Hardware Isomorphism: Designing handheld hardware to be physically equivalent to robot hardware to reduce domain gaps. Example: "Hardware Isomorphism to ensure physical consistency"
- Inverse Kinematics (IK): Computing joint configurations that achieve a desired end-effector pose. Example: "an on-device IK solver (Jacobian DLS)"
- Jacobian Damped Least Squares (Jacobian DLS): A numerically stable IK method that avoids singularities by damping. Example: "IK solver (Jacobian DLS)"
- Joint limit violation: Exceeding mechanical joint limits, leading to infeasible or unsafe configurations. Example: "checking for singularities or joint limit violations."
- Kinematic singularity: A configuration where the robot loses degrees of freedom, making certain motions infeasible. Example: "checking for singularities"
- Markov Decision Process (MDP): A formalism for sequential decision-making defined by states, actions, transitions, and rewards. Example: "We formulate the robotic manipulation task as a Markov Decision Process (MDP)"
- Online Finetuning: Continuously updating a policy with newly collected data during deployment. Example: "an asynchronous Online Finetuning pipeline"
- Out-Of-Distribution (OOD) states: States not represented in the training data that can cause policy failures. Example: "Out-Of-Distribution (OOD) states"
- Remote Inference: Offloading model inference to a server while streaming observations from a client device. Example: "Remote Inference"
- RLPD: A weighted sampling strategy inspired by prior work to mix datasets for efficient updating. Example: "using weighted sampling (RLPD)"
- Shared autonomy: A framework where control is shared between human and robot, often with assistive interventions. Example: "In standard shared autonomy"
- Simultaneous Localization and Mapping (SLAM): Estimating a device’s pose while building a map of the environment. Example: "SLAM stability"
- Spatiotemporal Synchronization: Aligning data across devices in both space and time for coherent multi-sensor learning. Example: "Spatiotemporal Synchronization for scalable multi-device setups."
- Teleoperation: Human remote control of robots to perform tasks and collect demonstrations. Example: "Teleoperation remains the dominant paradigm for acquiring high-precision manipulation data."
- Underactuated dynamics: Systems with fewer actuators than degrees of freedom, relying on passive mechanics for motion. Example: "replicate the gripper’s underactuated dynamics."
- Visual foresight: Visualizing future predicted trajectories to anticipate policy behavior. Example: "The AR interface serves as a 'visual foresight'."
- Visual-Inertial Odometry (VIO): Estimating motion by fusing camera and inertial measurements. Example: "simultaneous VIO (Visual-Inertial Odometry), kinematic solving, and AR rendering"
- Weighted sampling: Constructing training batches by drawing examples with specified proportions from different datasets. Example: "using a weighted sampling strategy"
Collections
Sign up for free to add this paper to one or more collections.

