RoboCade: Gamifying Robot Data Collection
Abstract: Imitation learning from human demonstrations has become a dominant approach for training autonomous robot policies. However, collecting demonstration datasets is costly: it often requires access to robots and needs sustained effort in a tedious, long process. These factors limit the scale of data available for training policies. We aim to address this scalability challenge by involving a broader audience in a gamified data collection experience that is both accessible and motivating. Specifically, we develop a gamified remote teleoperation platform, RoboCade, to engage general users in collecting data that is beneficial for downstream policy training. To do this, we embed gamification strategies into the design of the system interface and data collection tasks. In the system interface, we include components such as visual feedback, sound effects, goal visualizations, progress bars, leaderboards, and badges. We additionally propose principles for constructing gamified tasks that have overlapping structure with useful downstream target tasks. We instantiate RoboCade on three manipulation tasks -- including spatial arrangement, scanning, and insertion. To illustrate the viability of gamified robot data collection, we collect a demonstration dataset through our platform, and show that co-training robot policies with this data can improve success rate on non-gamified target tasks (+16-56%). Further, we conduct a user study to validate that novice users find the gamified platform significantly more enjoyable than a standard non-gamified platform (+24%). These results highlight the promise of gamified data collection as a scalable, accessible, and engaging method for collecting demonstration data.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a new way to collect the “how-to” data that robots need to learn everyday skills. The idea is to turn robot control into a fun online game so many people—not just experts in labs—will want to help. The authors built a platform called RoboCade where anyone can remotely drive a real robot arm through game-like tasks, and the robot uses those human demonstrations to learn.
What questions does the paper ask?
- Can we make robot data collection more scalable and exciting by gamifying it?
- If people play game-like robot tasks, will the data still help robots learn real, non-game tasks?
- Do beginners find a gamified teleoperation system more enjoyable and motivating than a normal, plain interface?
How did they do it?
First, some quick background: Robots often learn by imitation—like a student copying a teacher. People show the robot what to do many times, and the robot practices copying those examples. But gathering these examples is slow, expensive, and kind of boring.
The authors’ approach:
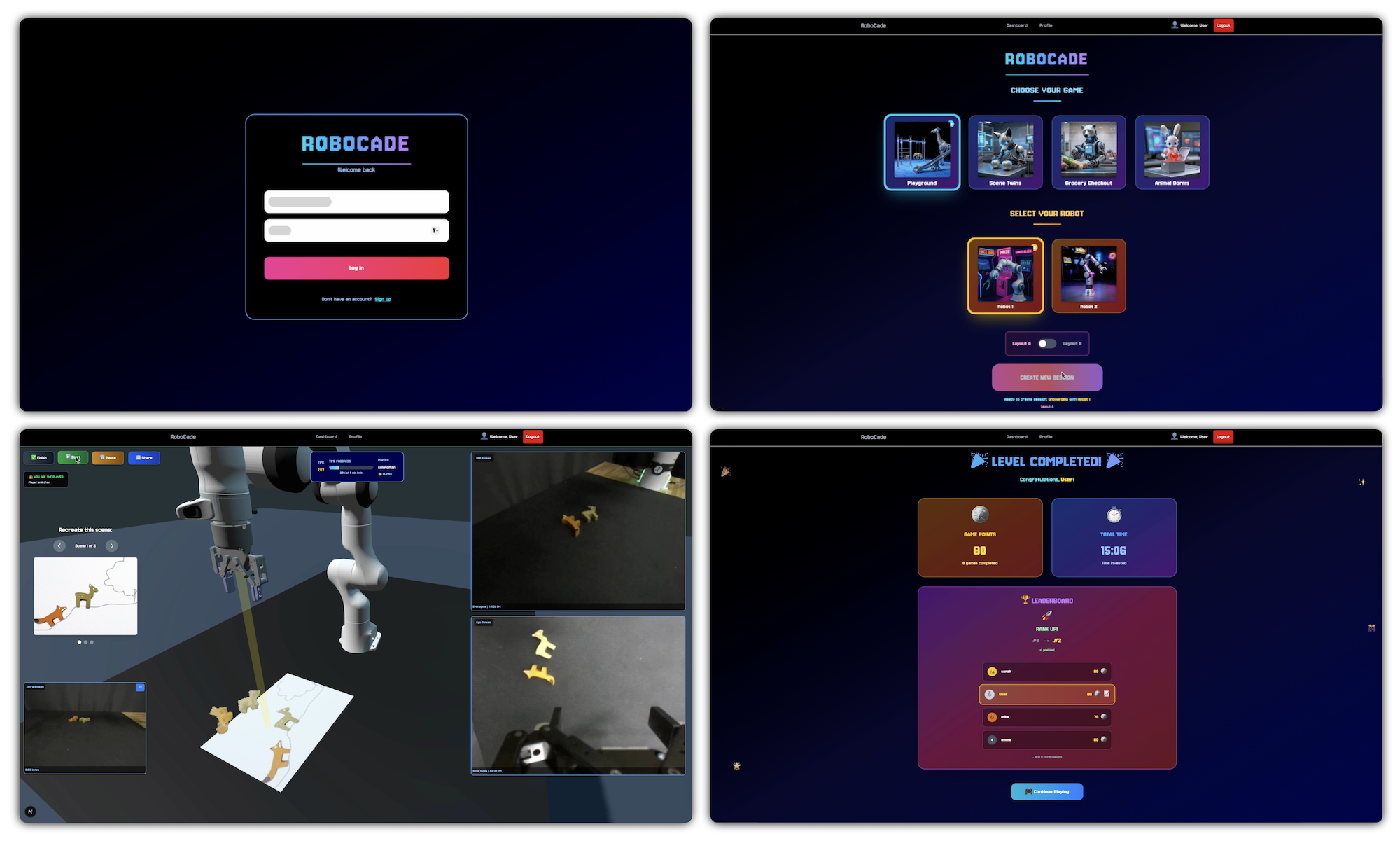
- They built a web platform, RoboCade, that lets people control a real robot arm from anywhere using an affordable controller called GELLO. Think of GELLO like a physical puppet: you move it, and the robot arm mirrors you.
- They added game elements to make it fun and clear what to do: live visual and sound feedback, progress bars and timers, goal overlays, points, badges, and leaderboards. You can even share a live link so others can watch your game session.
- They designed “support tasks” (the game-like versions) that are fun but still practice the same key skills as the “target tasks” (the real-world versions the robot eventually needs to do).
They focused on three kinds of robot skills:
- Rearrangement (moving objects to match a layout)
- Scanning (picking up and showing an item to a camera)
- Insertion (picking up and placing something into a container)
Example pairs of tasks:
- Target: ArrangeDesk (line up a mouse and adapter neatly) ↔ Support: SceneTwins (recreate a scene with animal blocks using an overlaid guide)
- Target: ScanBottle (pick up a bottle and show its barcode to a scanner) ↔ Support: GroceryCheckout (scan toy groceries, with receipt and beep sounds)
- Target: PackBox (put a tape roll in a box and close the lid) ↔ Support: AnimalDorms (put animal toys into matching “homes”)
How they tested the idea:
- They collected two kinds of data: regular target-task demos and gamified support-task demos.
- They trained robot policies in two ways: 1) Only on target-task data 2) “Co-training” on a mix of target-task data plus gamified support-task data
- They used a standard robot learning method (a policy that learns from images to predict the robot’s next moves) and also tested a larger pre-trained model called a VLA (vision-language-action) by fine-tuning it on these datasets.
- They ran 25 trials per task and condition, and also tested “out-of-distribution” setups—layouts the robot didn’t see during target-task training—to see if it would generalize.
- They ran a user study with 18 beginners to compare the gamified interface versus a plain, non-gamified interface using the same robot controller.
What exactly is “gamified” here?
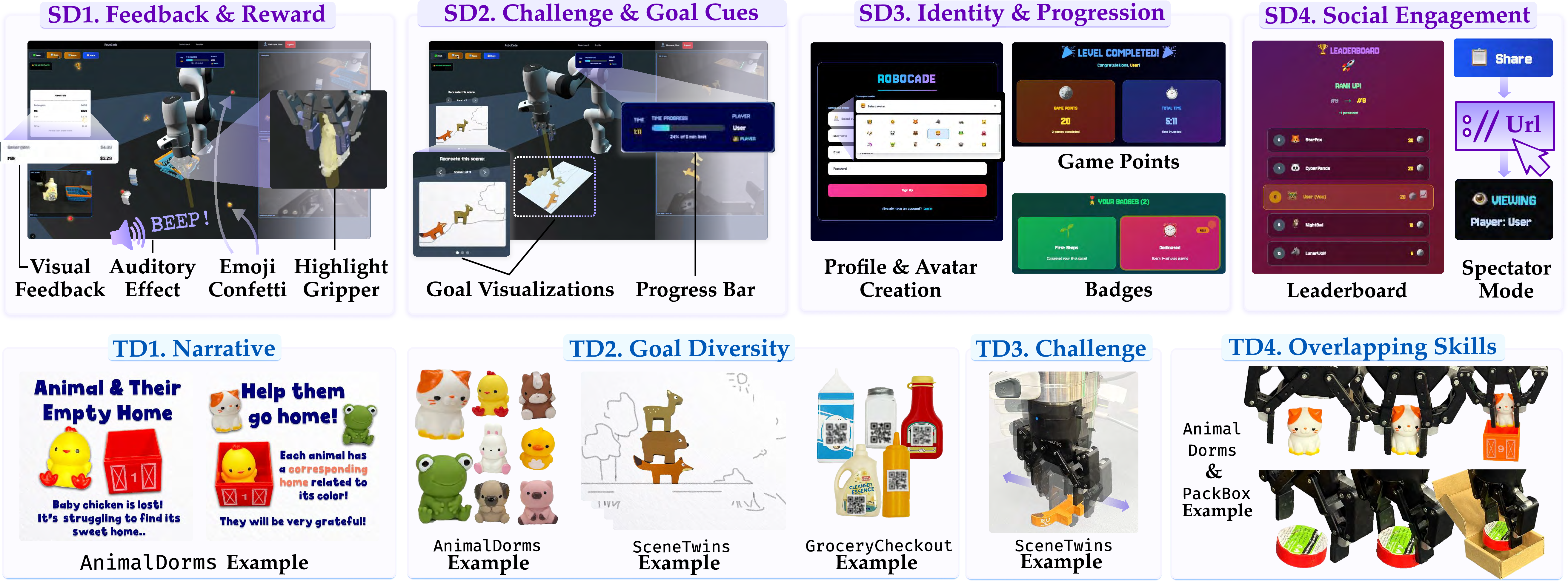
RoboCade uses game design to guide and motivate players:
- Feedback and rewards: instant visual highlights, sound effects, confetti on success
- Clear goals and challenge: timers, progress bars, and goal overlays (like a scene template or a grocery receipt)
- Identity and progression: usernames, avatars, points, and badges
- Social features: leaderboards and shareable live links to watch games in real-time
For task design, they followed four simple rules:
- Add a story: “help the animal find its home,” “check out groceries”
- Vary goals: different objects or layouts so it doesn’t feel repetitive
- Set fair difficulty: not too easy, not too hard
- Reuse core skills: the game should practice the same key moves as the real task (like grasping, aligning, inserting), even if the story or objects are different
Main findings
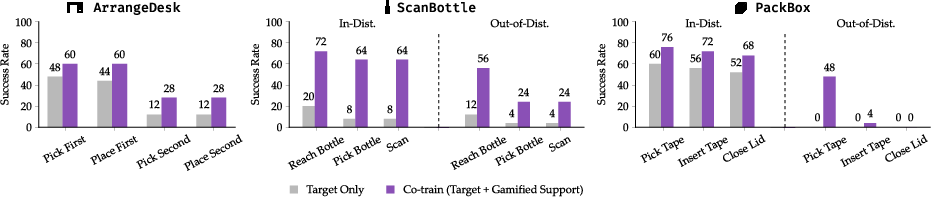
- Gamified data improves robot learning
- When they mixed in game-collected data (co-training), robot success on the real target tasks went up across the board:
- ArrangeDesk improved from 12% to 28% overall success with co-training
- ScanBottle and PackBox also showed strong gains
- In several cases, the robot got better at “out-of-distribution” setups too—meaning it handled new, harder starting positions more robustly. For example, the co-trained system improved out-of-distribution performance by up to about 20% in one set of experiments.
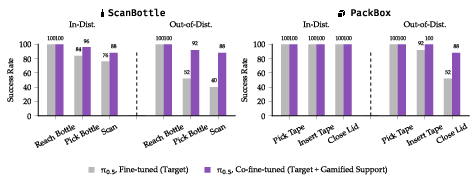
- With the larger pre-trained VLA model, co-fine-tuning with gamified data boosted success even more, especially on harder starting conditions (e.g., +48% for ScanBottle and +36% for PackBox out of distribution), while matching or beating in-distribution performance.
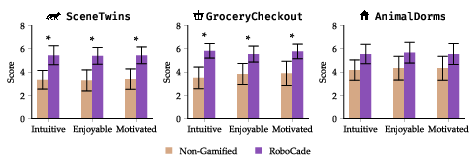
- Users liked the gamified platform more
- In a study with 18 beginners, the gamified interface felt:
- More intuitive (+27%)
- More enjoyable (+24%)
- More motivating (+24%)
- People also completed more tasks with the gamified version and gave it a higher usability score overall.
Why this matters:
- Better data: The game version still teaches the robot the important skills.
- More data: Making it fun invites more people to help, from more places, without needing to be in the lab.
- Lower cost: The GELLO controller is low-cost, and the platform runs over the web.
What could this change?
If collecting robot training data feels like playing a game, many more people might participate—without needing payment or special training. That can:
- Speed up how quickly robots learn new skills
- Make robot learning more affordable and accessible
- Encourage new communities (like gamers) to contribute high-quality demonstrations
The authors note future directions like rewarding high-quality data even more, studying which game elements work best over time, and collecting open-ended “play” data to train robots to be more flexible and curious.
Bottom line
RoboCade shows that turning robot control into a game is not just fun—it also creates useful training data. Mixing game-collected demos with normal demos makes robots more successful and more adaptable, while the gamified interface keeps new users engaged and eager to contribute.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list synthesizes what remains missing, uncertain, or unexplored in the paper, framed as concrete directions for future research and validation.
- Causal impact of gamification components is not disentangled: no ablation to quantify which interface elements (feedback effects, time limits, overlays, badges, leaderboards, spectator mode) most influence engagement, data quality, and policy performance.
- Support task design principles are qualitative: no quantitative measure of “skill overlap” or a predictive criterion for when a support task will transfer to a target task; need metrics and a design-time procedure to optimize support-task selection.
- Co-training recipe is fixed and unoptimized: only a 50/50 batch mix is tested; unexplored is how mixing ratios, curriculum schedules, task weighting, and representation sharing affect transfer and sample efficiency.
- Small-scale evaluation of policy gains: 25 trials per condition and limited dataset sizes (80–150 target demos, 200 support demos) without statistical tests or variance analysis; replication across seeds, more tasks, and larger datasets is needed.
- Out-of-distribution evaluation is narrow: OOD is defined only by initial object positions; generalization to novel objects, textures, lighting, clutter, backgrounds, and different scanners/containers remains untested.
- Generality across hardware and settings is unknown: results are limited to a Franka FR3 with a two-finger gripper and ZED cameras; assess portability to different arms, grippers, cameras, mobile robots, dual-arm systems, and in-the-wild environments.
- Controller dependence is not studied: the platform relies on GELLO puppet control; it’s unclear whether results hold with other input modalities (SpaceMouse, VR, AR, smartphone, wearable end-effector systems) or mixed-controller crowds.
- Latency and network variability are unmeasured: no instrumentation of round-trip delays, jitter, or packet loss; quantify how latency affects user experience, safety, and data quality, and evaluate mitigation strategies (prediction, buffering, local autonomy).
- Safety and risk management for novice crowds is thin: beyond workspace bounds and joint limits, there are no formal safety metrics, intervention protocols, or fail-safes; evaluate incident rates, near misses, and automated guardrails (collision prediction, intent checks).
- Data quality control is not addressed: no automatic trajectory scoring, anomaly detection, or filtering; design scalable quality metrics and incentive mechanisms that align points/badges with demonstrational usefulness rather than raw completion.
- Potential for gaming/cheating the system: competitive leaderboards and point systems can incentivize behavior that hurts data quality; investigate adversarial behaviors and robust anti-cheat mechanisms (e.g., reputation scores, peer review, randomized audits).
- Long-term engagement and retention are unknown: the user study is short (≤1 hour) with N=18; measure retention, novelty effects, and contribution rates over weeks/months at scale, including cohort analyses and churn predictors.
- External validity of user study is limited: participants are young adults; test across broader demographics (age, gaming experience, motor impairments), geographies, and cultural contexts to assess inclusivity and accessibility.
- Objective performance metrics for users are sparse: beyond completion rates and Likert scores, measure demonstration throughput, error rates, smoothness, path efficiency, grasp precision, and time-to-success to relate engagement to data quality.
- Mechanism of policy gains is unclear: improvements may stem from increased data diversity rather than gamification per se; isolate diversity effects (object sets, goal distributions) from engagement effects via controlled task variants.
- Automated success and stage labeling is under-specified: success detection appears task-specific; develop general, scalable labeling pipelines (vision-based validators, programmatic checks) and quantify label accuracy/consistency.
- Language grounding is unexplored: VLA fine-tuning details do not clarify if natural language instructions were used; evaluate whether gamified tasks can collect aligned language/action data to improve instruction following.
- Privacy and security risks are unaddressed: remote control via WebSockets and streamed video/point clouds introduce attack surfaces; assess authentication, authorization, sandboxing, and data privacy/compliance for public deployment.
- Economic viability without payments is unproven: the paper argues for intrinsic motivation, but no evidence of sustained contributions at scale; benchmark cost per demo vs paid crowdsourcing and model expected supply under different incentive designs.
- Scheduling and multi-robot orchestration are not evaluated: concurrency, queueing, load balancing, failure recovery, and operator matching are open; develop a backend for large fleets and measure throughput and uptime.
- Adaptive difficulty is missing: time limits and goals are static; investigate adaptive challenge calibration (personalized time budgets, dynamic goals) to maintain “flow” and maximize quality over heterogeneous users.
- Transfer to realistic industrial tasks is open: test on non-toy, precision-demanding workflows (assembly, fastening, cable routing) to assess whether gamified data benefits scale to higher-stakes applications.
- Ethical considerations of gamifying labor are not discussed: examine fairness, transparency, and potential exploitation risks when crowds source robotic demonstrations without compensation.
- Dataset release and reproducibility are unclear: provide public datasets, platform code, and evaluation scripts to enable independent validation and benchmark comparison.
- Spectator mode effects are unknown: quantify whether live audiences improve or degrade user performance, data quality, and safety, and whether social features create pressure that affects behavior.
- Cross-task negative transfer is not tested: co-training can sometimes hurt specialized performance; add experiments measuring interference and mechanisms (e.g., task-specific adapters, gating) to mitigate it.
- Real-time autonomy support is absent: explore shared autonomy or intent inference to assist novices during difficult subtasks while preserving gameplay and data usefulness.
- Interface ergonomics and potential motion sickness are unstudied: the dynamic 3D viewer may cause discomfort; assess ergonomic loads and UI variants (camera motion, overlays) for usability across sessions.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging RoboCade’s gamified remote teleoperation platform, support-task design principles, and demonstrated co-training benefits.
- RoboCade-as-a-Service for robotics data collection
- Sector: robotics, software
- What: Offer a hosted or on-prem web platform (Next.js/Three.js frontend, ZeroMQ/WebSockets backend) with GELLO-based teleoperation to crowdsource support-task demonstrations aligned to target tasks (e.g., rearrangement, scanning, insertion).
- Workflow: Design support–target task pairs with overlapping skills; recruit novice users via leaderboards/badges; co-train Diffusion Policy or fine-tune VLA models; evaluate using staged success and in-/out-of-distribution setups.
- Assumptions/dependencies: Access to real robots (e.g., Franka FR3) and cameras; safety constraints (workspace bounds, collision avoidance); reliable low-latency internet; data storage pipelines; basic QA triage for demos; contributor authentication and consent.
- Co-training pipelines to boost manipulation policy performance
- Sector: robotics, software
- What: Integrate RoboCade-collected support-task data into existing policy training to improve target-task success (+16–56%) and OOD generalization (+20–48%) for tasks like packing, bottle scanning, and rearrangement.
- Workflow: Maintain a 50/50 batch mix of target vs. support data; keep fixed training budgets; adopt staged evaluations; apply the U-Net Diffusion Policy or fine-tune π₀.₅ VLA models.
- Assumptions/dependencies: Overlapping skill design (TD4), calibrated task difficulty (TD3), sufficient compute, consistent camera streams; privacy-compliant data logging.
- Retail and e-commerce robotic scanning alignment
- Sector: retail, logistics
- What: Use “GroceryCheckout” as a support task to co-train barcode alignment policies for SKU scanning robots (e.g., in backrooms, packing stations) where hard items (like thin-neck bottles) are present.
- Workflow: Rotate diverse “receipt” lists; gamified auditory/visual feedback to sustain engagement; co-fine-tune existing VLA models for improved OOD robustness.
- Assumptions/dependencies: Camera placement standardization; SKU diversity; mapping receipt variations to real-world barcodes; safety oversight in shared spaces.
- Warehouse kitting and small-part insertion
- Sector: logistics, manufacturing
- What: Leverage “AnimalDorms” support tasks to collect insertion data transferable to packing or bin-insertion policies (e.g., tape rolls, small components).
- Workflow: Randomize part poses; color-matched “homes” for quick task comprehension; staged scoring (reach, pick, insert, close).
- Assumptions/dependencies: Accurate gripper calibration; box geometry constraints; safe joint limits; consistent object sets.
- Remote robotics labs for education and training
- Sector: education
- What: Deploy RoboCade for K–12 and university courses to let students practice teleoperation on real robots via gamified tasks, increasing intuitiveness (+27%) and motivation (+24%).
- Workflow: Classroom accounts; session scheduling; badges/leaderboards for module completion; integrate SUS and Likert scales for usability tracking.
- Assumptions/dependencies: Institutional network reliability; IRB/consent where needed; instructor oversight; age-appropriate safety gates.
- User engagement toolkit for existing teleoperation systems
- Sector: software, robotics
- What: Add gamification modules (progress bars, goal overlays, badges, leaderboards, sound effects) to non-gamified interfaces to enhance retention and throughput.
- Workflow: A/B test SD1–SD4 components; leaderboards with anonymized profiles; per-episode shareable spectator links for real-time viewing.
- Assumptions/dependencies: UI integration into current stack; latency budgets for UI updates; moderation of usernames/avatars.
- Outreach and public demos (“robot arcades”)
- Sector: marketing, community engagement
- What: Pop-up installations in makerspaces, museums, campus lobbies where visitors earn badges by completing scanning/rearrangement/insertion challenges while contributing training data.
- Workflow: On-site staff; gamified narratives; prize tiers; safe physical boundaries; spectator streaming.
- Assumptions/dependencies: Venue insurance; robot safety checks; opt-in data licensing; local compute and storage.
- Open-source replication for academic labs
- Sector: academia
- What: Reproduce RoboCade’s stack with Franka FR3, ZED cameras, GELLO controller; run task design studies on narrative, goal diversity, and challenge calibration.
- Workflow: Publish support–target task pairs; share evaluation overlays; contribute to open datasets; co-author multi-site studies.
- Assumptions/dependencies: Hardware procurement; staff expertise; reproducible calibration; shared licensing terms.
- Recruitment of specialized cohorts (e.g., gamers)
- Sector: community building, HRI research
- What: Target gaming communities to improve teleoperation performance and data quality, capitalizing on intrinsic motivation and competition.
- Workflow: Season-based leaderboards; team competitions; “boss” tasks; streamers co-host collection events.
- Assumptions/dependencies: Community moderation; prize rules; clear data-use disclosures; QA scoring to filter low-quality trajectories.
- Model evaluation and usability research
- Sector: academia, HRI
- What: Use the platform’s structured episodes and staged success scoring for controlled experiments on human–AI collaboration, engagement effects, and task transfer.
- Workflow: Counterbalanced within-subject designs; Holm-Bonferroni corrections; public replication kits.
- Assumptions/dependencies: IRB approvals; participant diversity; standardized initial-state overlays to reduce variance.
Long-Term Applications
These applications require additional research, scaling, standardization, or development before feasible large-scale deployment.
- Citizen Robot Data Corps (non-monetized or lightly incentivized crowdsourcing network)
- Sector: robotics, policy
- What: A global network of volunteers contributing support-task demonstrations to train manipulation policies across many task families, reducing reliance on paid operators.
- Dependencies: Safety governance, liability frameworks for remote operation; robust QA scoring; contributor vetting; scalable robot fleets; sustainable funding.
- Integration with mainstream gaming platforms
- Sector: software, entertainment, robotics
- What: AAA or indie games that embed real-robot teleoperation “events” or simulated tasks tightly coupled to real support-task data collection for policy training.
- Dependencies: Strong safety guarantees; cloud scheduling of limited robot time; ultra-low-latency streaming; content moderation; partnerships with game studios.
- Assistive home robotics training via gamified tasks
- Sector: healthcare, consumer robotics
- What: Collect household support-task data (e.g., placing utensils, organizing medication trays, laundry sorting) to train policies for eldercare and disability support.
- Dependencies: Home robot hardware reliability; privacy-preserving sensing; clinical safety certification; caregiver oversight; robust OOD performance.
- Telemedicine and medical robotics data collection
- Sector: healthcare
- What: Gamified simulators and constrained real tasks (e.g., tool alignment, ultrasound probe positioning on phantoms) to pre-train policies and teleop skills.
- Dependencies: Regulatory approval; device certifications; high-fidelity simulators; traceable QA; clinical liability coverage.
- Industry standards for gamified robot data collection
- Sector: policy, standards bodies (e.g., IEEE/ISO)
- What: Protocols for remote control safety, data provenance, consent, anonymization, staged success scoring, and cross-platform evaluation overlays.
- Dependencies: Multi-stakeholder consensus; reference implementations; compliance auditing; interoperability with existing datasets (e.g., DROID).
- Task marketplace for robots (skill brokering)
- Sector: platform economy, robotics
- What: A marketplace that posts support tasks; contributors earn points/tokens; enterprises receive curated datasets aligned to their target tasks.
- Dependencies: Payment/tokens regulations; quality metrics; fraud detection; IP rights management; workforce fairness considerations.
- Play-based data for training generalist robot policies
- Sector: robotics research
- What: Large-scale collection of task-agnostic “play” interactions to train goal-conditioned policies or world models for open-ended manipulation.
- Dependencies: Representation learning advances; scalable labeling via self-supervision; hardware robustness; coverage of diverse object/task distributions.
- In-the-wild fleets of low-cost home/lab robots
- Sector: consumer robotics, education
- What: Distributed SO-100/101-like robots in homes/classrooms, generating continuous support-task data streams via gamified interfaces.
- Dependencies: Affordable hardware; remote updates; maintenance logistics; household safety; bandwidth and edge compute.
- Public-space deployments and retail partnerships (“robot arcades at scale”)
- Sector: retail, community engagement
- What: National rollouts in malls and stores to collect data for shelf-stocking, scanning, and light packing tasks while engaging patrons.
- Dependencies: Retail agreements; robust uptime; incident response; localized QA; operations staffing and training.
- Safety assurance and data governance frameworks
- Sector: policy, compliance
- What: Comprehensive guidelines for remote robot operation (age restrictions, supervision), data rights, anonymization, and incident reporting.
- Dependencies: Legal harmonization across jurisdictions; insurer alignment; standard contracts; independent audits; public transparency.
- Cross-sector inspection and infrastructure training (energy/utilities)
- Sector: energy, infrastructure
- What: Gamified scanning/alignment tasks extended to inspection robots (barcode/label reading, tool alignment), improving training for utility sites and warehouses.
- Dependencies: Domain-specific hardware; hazardous-environment safety; labeling schemas; secure connectivity.
Notes on Assumptions and Dependencies
- Overlapping skill design is critical: support tasks must share core manipulation primitives with target tasks to realize transfer.
- Latency and streaming: smooth teleoperation with concurrent gamified feedback requires stable, low-latency links; otherwise user performance and data quality degrade.
- Safety envelopes: joint limits, collision avoidance, and workspace constraints must be enforced and continuously monitored, especially with novice operators.
- QA and data curation: points/badges alone won’t guarantee data quality; incorporate trajectory scoring, automated checks, and human review where necessary.
- Governance and consent: clear data-use disclosures, contributor licensing, and privacy safeguards are needed for public participation and education settings.
- Compute and integration: co-training and VLA fine-tuning require GPU resources and MLOps pipelines; ensure reproducible evaluation protocols (e.g., staged success, consistent initial-state overlays).
- Hardware diversity: while results were shown on Franka FR3 + ZED cameras + GELLO, portability to other arms/sensors may require retargeting and calibration work.
Glossary
- Action chunks: Fixed-length blocks of actions predicted or executed together by a policy. "with action chunks of size 16 and execution horizon of 8."
- ALOHA: A purpose-built robot puppeteering platform designed to streamline high-fidelity teleoperation data collection. "purpose-built puppeteering platforms such as ALOHA \cite{zhao2023learning} and GELLO \cite{wu2024gello} are designed to streamline data collection while preserving real-robot fidelity."
- Augmented Reality (AR): Technology that overlays digital content onto the real world to enable interactive control or feedback. "AR \cite{duan2023ar2,wang2024eve}"
- Behavior cloning: An imitation learning approach that trains a policy via supervised learning on expert demonstrations. "IL is often formulated as behavior cloning, where a policy parameterized by is trained using supervised learning from a dataset "
- Co-fine-tuning: Further fine-tuning a pre-trained model on multiple datasets jointly to improve performance or generalization. "or co-fine-tune it on and ."
- Co-training: Training on a mixture of datasets (e.g., support and target tasks) in the same training process. "For co-training, we sample batches with a 50\%-50\% split between data sources."
- Cosine decay: A learning rate schedule that decays the rate following a cosine function over training. "LR Schedule & Cosine Decay"
- DDIM: Denoising Diffusion Implicit Models; an inference scheduler for diffusion-based generative policies. "Inference Scheduler & DDIM"
- DexCap: A wearable end-effector teleoperation system that maps human hand poses to robot motion. "Wearable end-effector systems (DexCap \cite{wang2024dexcap}, UMI \cite{chi2024universal}, DexUMI \cite{xu2025dexumi})"
- DexUMI: A wearable teleoperation system for dexterous manipulation, related to UMI-style control. "Wearable end-effector systems (DexCap \cite{wang2024dexcap}, UMI \cite{chi2024universal}, DexUMI \cite{xu2025dexumi})"
- Diffusion Policy: A policy-learning method that uses diffusion models to generate actions conditioned on observations. "We train policies with Diffusion Policy \citep{chi2023diffusion}"
- DROID: A large-scale robot manipulation dataset and platform used for training and evaluating policies. "fine-tuned on the DROID dataset \cite{Khazatsky2024DROIDAL}"
- Egocentric camera: A camera viewpoint mounted on the robot (or operator) to capture first-person visual observations. "one ZED Mini egocentric camera"
- End-effector: The tool or gripper at the tip of a robot arm that interacts with objects. "The camera angle of the 3D viewer moves based on the position of the end-effector"
- Execution horizon: The number of future action steps a policy outputs or executes at once. "with action chunks of size 16 and execution horizon of 8."
- Flow (psychology): A state of optimal engagement and challenge that sustains motivation during tasks. "Guided by the concept of flow \cite{Csikszentmihalyi_1988}"
- Franka FR3: A 7-DoF industrial robot arm commonly used in research for manipulation tasks. "We implement RoboCade using the Franka FR3 robot arm."
- Games-with-a-Purpose (GWAPs): Game experiences designed to collect useful data (e.g., for ML) from player interactions. "Early work on Games-with-a-Purpose (GWAPs) \cite{von2008designing} proposed the idea of channeling user interactions in game-like experiences towards collecting data"
- GELLO: A low-cost, 3D-printable robot puppeteering controller enabling intuitive joint-space teleoperation. "Built on top of a 3D-printable GELLO controller \cite{wu2024gello}"
- Holm-Bonferroni correction: A statistical method for controlling the familywise error rate across multiple tests. "We run Wilcoxon signed-rank tests with Holm-Bonferroni correction"
- ICP registration: Iterative Closest Point; an algorithm for aligning point clouds by minimizing point-to-point distances. "merge point clouds via point-to-point ICP registration."
- Imitation learning: Training policies by learning from expert demonstrations rather than explicit reward optimization. "Imitation learning from human demonstrations has become an increasingly popular approach for training robot policies"
- In-distribution: Refers to evaluation conditions that match the distribution of the training data. "in-distribution success on 3 non-gamified target tasks (+16--56\%)"
- Joint impedance control: A control mode that regulates motion by modeling joints as virtual springs and dampers to ensure compliant behavior. "with joint impedance control."
- Joint-space control: Controlling a robot by specifying joint angles directly rather than end-effector Cartesian poses. "allows for intuitive joint-space control"
- Kinematic constraints: Geometric and motion limits (e.g., joint ranges) that a robot must satisfy when moving. "naturally obeying kinematic constraints and avoiding self-collisions;"
- Kinesthetic teaching: Demonstration method where an operator physically guides the robot through desired motions. "Kinesthetic teaching \cite{argall2009survey} is precise and safe, but is labor-intensive and requires collocation with a robot."
- Out-of-distribution: Refers to evaluation conditions that differ from the training distribution, testing generalization. "additional boosts in out-of-distribution performance up to 20\%."
- Point cloud: A set of 3D points representing the geometry of a scene, often captured by depth sensors. "a live point cloud of objects in the scene is displayed alongside a virtual rendering of the robot"
- Polymetis: A robotics control framework used to implement compliant control modes on hardware. "We use joint impedance control via Polymetis \cite{polymetis}."
- Publisher-subscriber messaging pattern: A communication paradigm where producers publish messages to topics and consumers subscribe to receive them. "We use a publisher-subscriber messaging pattern with ZeroMQ \cite{zeromq}"
- Puppeteering platforms: Teleoperation systems that let operators “puppet” robots by mirroring controller motions onto the robot. "purpose-built puppeteering platforms such as ALOHA \cite{zhao2023learning} and GELLO \cite{wu2024gello}"
- Retargeting: Mapping human motions or poses to robot kinematics to produce feasible control commands. "require custom hardware, calibration, and careful retargeting."
- RoboTurk: A crowdsourcing platform for remote robot teleoperation via consumer devices. "Early systems such as RoboTurk \cite{Mandlekar2018ROBOTURKAC} crowdsource demonstrations via a smartphone teleoperation interface"
- SpaceMouse: A 3D input device used for precise teleoperation or CAD manipulation. "SpaceMouse \cite{zhu2023viola}"
- System Usability Scale (SUS): A standardized questionnaire for assessing the usability of systems. "with an SUS score \cite{brooke1996sus} of "
- Teleoperation: Remote control of a robot by a human operator, typically via an input device and live feedback. "remote teleoperation platforms \cite{Mandlekar2018ROBOTURKAC, dass2024telemoma}"
- UMI: A wearable end-effector teleoperation system enabling dexterous robot control via hand pose mapping. "Wearable end-effector systems (DexCap \cite{wang2024dexcap}, UMI \cite{chi2024universal}, DexUMI \cite{xu2025dexumi})"
- U-Net: A convolutional neural network architecture with encoder-decoder and skip connections, often used in diffusion models. "We follow the U-Net architecture from \citep{chi2023diffusion}"
- Vision-Language-Action (VLA) models: Multi-modal models that integrate visual inputs, language, and action outputs for robot control. "larger, pre-trained vision-language-action (VLA) models."
- WebSockets: A protocol enabling bidirectional, low-latency communication between clients and servers over the web. "and WebSockets for transmitting data between the backend and frontend."
- Wilcoxon signed-rank test: A nonparametric statistical test for comparing paired measurements. "* denotes significance at under a Wilcoxon signed-rank test."
- ZeroMQ: A high-performance messaging library used to implement distributed and real-time communication patterns. "We use ZeroMQ \cite{zeromq} for message passing"
Collections
Sign up for free to add this paper to one or more collections.

