- The paper finds that node and global diagram features are encoded early in LVLM vision transformers, while edge relationships emerge later during language processing.
- It employs a synthetic diagram dataset and linear probes across multiple model layers to systematically analyze the dynamics of diagram representation.
- Causal interventions confirm that disrupting early node encodings leads to significant performance drops, emphasizing the role of spatial features in model reasoning.
Motivation and Context
Despite advancements in Large Vision-LLMs (LVLMs), diagram understanding remains a challenging domain, especially the extraction and comprehension of relational structures such as node-to-node relationships and directed edges. Prior evaluations have shown strong LVLM performance on diagram-centric benchmarks, but consistently identify limitations in handling relationships — e.g., arrows, lines — essential to interpreting diagrams in STEM, business, and other structured domains. This work addresses a gap in the literature by systematically probing LVLM internal representations to determine where and when diagram visual information (nodes, edges, global structure) becomes linearly accessible within the model architecture, and analyzing the corresponding impact on model reasoning.
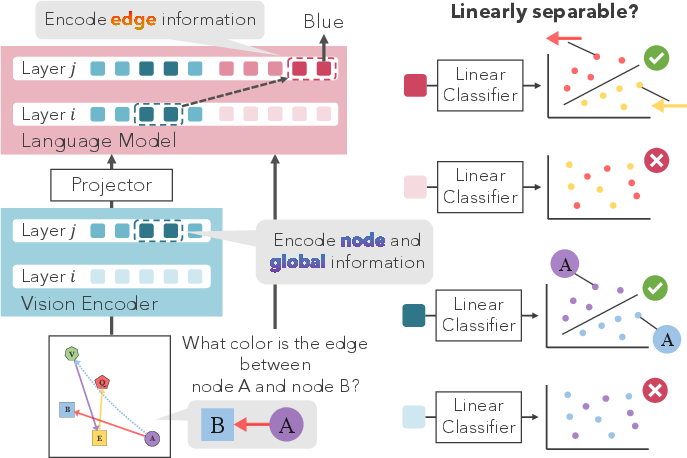
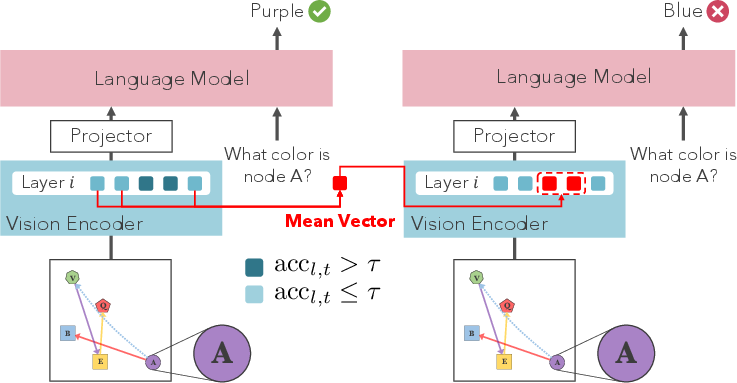
Figure 1: The study probes LVLMs on synthetic diagrams, revealing node and global info encoded in vision encoder patches, while edge info emerges in text tokens within the LLM.
Dataset Construction and Task Setup
A synthetic, controlled diagram dataset was designed to facilitate fine-grained analysis of LVLMs. Diagrams are directed graphs with exactly five nodes, each uniquely colored (eight possible colors) and shaped (five geometric options), with alphabetic identifiers. Edges vary in color, style, and direction. The dataset defers from real-world complexity—deliberately isolating bias—but offers rigorous control of evaluation aspects. Eleven aspects (node color/shape, degree, edge color/style/existence/direction, multi-hop paths, node and edge counts) were selected based on prior diagram analytics literature.
Evaluation involved a VQA classification task: for each diagram, the model answers aspect-specific questions (e.g., "What color is node A?", "Does an edge exist between node A and node B?"). The answer set is represented as Y; both random and fixed-node-layout variants were used to probe spatial encoding.
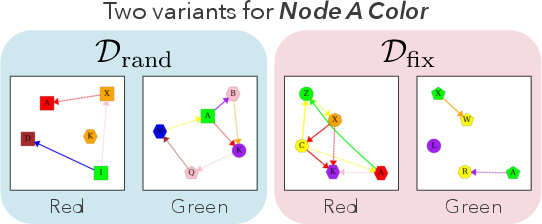
Figure 2: Examples of synthetic diagrams; each variant controls node/edge properties and layout for robust evaluation.
Probing Methodology
Probes (linear classifiers) were trained at multiple layers and positions within LVLMs' vision encoder and LLM to assess linearly separable encoding of diagram information. Probing evaluated three components: (i) vision encoder patches, (ii) LLM image-input patches, and (iii) text token positions. The maximal probing accuracy per layer (MaxAccl) was used to quantify the linear accessibility of information, with chance-level thresholds established for each aspect.
Empirical Results: Layerwise and Positionwise Encoding
Vision Encoder Analysis
For Qwen3-VL 8B (primary focus), probing revealed that:
- Node information (Single category) and global features: linearly separable representations emerge in progressively deeper Vision Transformer layers, reaching high accuracy localized at node positions for node info, and broadly across background patches for global info.
- Edge information (Multiple category): remains poorly linearly separable at all vision encoder layers, with accuracy near chance.
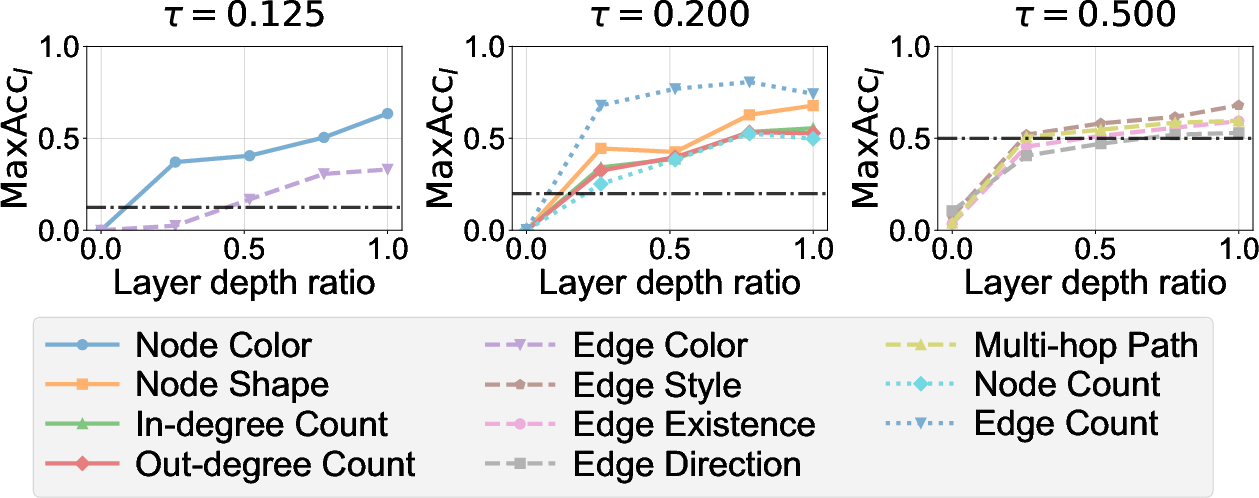
Figure 3: Layer-wise MaxAccl in the vision encoder; node and global information manifest strongly with depth, edge info lags.
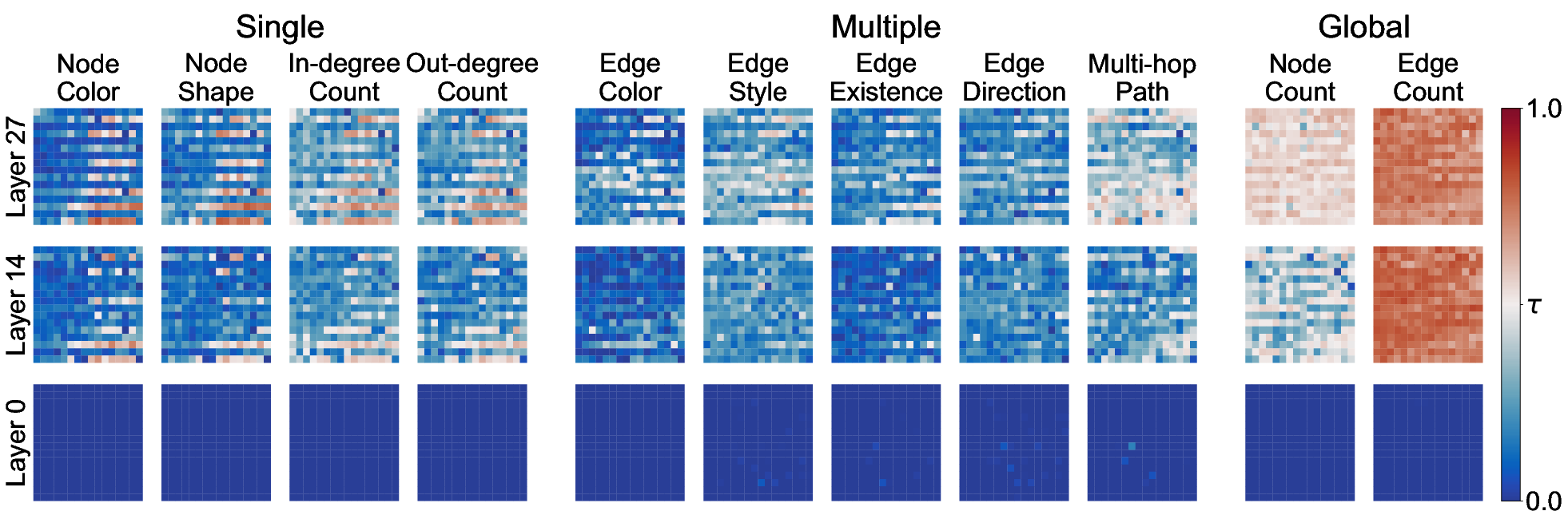
Figure 4: Patch-wise accuracy heatmaps; node info localizes spatially, global info aggregates in background patches.
LLM Analysis
Node/global info was preserved after adapter transfer but edge info did not become linearly accessible until text token processing. Sharp increases in probing accuracy occur at text token positions referencing target nodes or edges, indicating selective aggregation conditioned on the language input. Global information manifests uniformly from the first text token without explicit cueing.

Figure 5: Probing results for text tokens; edge info is linearly encoded in specific token positions, node info is broadly accessible.
Causal Intervention: Reasoning Dependency
To validate causality, patch positions with high probing accuracy were selectively corrupted (mean-replacement), and subsequent VQA accuracy drops were measured:
Comparative Analysis Across Model Architectures
Replicated experiments on Qwen2.5-VL 7B, LLaVA1.5 7B, and Gemma3-4B-IT yielded broadly consistent results:
- Node information encoding was robust but more distributed in LLaVA1.5 (background patch storage).
- Gemma3-4B-IT encoded node info more locally but had lower overall accuracy.
- Edge info consistently failed to manifest linearly in vision encoders, only emerging in text tokens.
Implications and Theoretical Considerations
The core finding — nodes are early, edges are late — asserts that node and global diagram information are encoded early and locally in vision encoders, while edge information (relations) only becomes linearly accessible during text processing in the LLM. This encoding asymmetry is strongly correlated with the model's observed difficulty in relational understanding (e.g., edge direction), and suggests that LVLMs fundamentally lack architectural mechanisms for compositional, abstract, relational visual integration. This may also explain performance limitations on benchmarks evaluating diagram-based reasoning [Zhang2025-bh, Zhu2025-mw].
Practically, these insights flag a need for enhanced LVLM architectures or training objectives specifically tailored to promote relational encoding. For downstream diagram analytics, system designers should be aware of this asymmetry and may need to leverage auxiliary relational pretraining or explicit relation-aware modules.
Future Directions
Extending probing and causal intervention to real-world diagrams, higher-order relations, and composite visual patterns is required for broader applicability. Architectural exploration to improve relational representation (e.g., graph neural mechanisms, register tokens, enhanced cross-modal adapters) will be critical. Alternative probing paradigms (e.g., dictionary learning [Bricken2023-xu], sparse probing [Gurnee2023-bk]) warrant investigation for capturing nonlinear representations.
Conclusion
This work demonstrates that LVLMs encode node and global structural information in linearly decodable form within vision encoder patches, while edge relationship information only becomes linearly accessible in text tokens processed by the LLM. Causal interventions confirm that these linearly encoded features are directly used for inference. The delayed, indirect encoding of relational diagram information explains deficiencies in LVLM relational reasoning, motivating architectural and training adaptations to address domain-specific requirements in diagram understanding.
Figure 1: Study overview — highlighting the temporal and spatial encoding disparity for node vs. edge information within LVLMs.