- The paper introduces BabelRS, pioneering early language-pivoted pretraining to decouple cross-modal semantic alignment from detection-specific learning.
- It employs progressive multi-scale feature integration via LVSA to maintain semantic consistency and stabilize gradient dynamics.
- Experiments on RS benchmarks show superior accuracy and robustness over traditional late-alignment approaches, especially in SAR and IR modalities.
Language-Pivoted Pretraining for Heterogeneous Multi-Modal Remote Sensing Detection: BabelRS
Introduction
The challenge of unified object detection in heterogeneous remote sensing (RS) arises from disparate sensor modalities such as RGB, SAR, and Infrared, each encoding fundamentally different physical phenomena. Existing frameworks predominantly rely on late-stage modality alignment during fine-tuning, which tightly couples feature space reconciliation and task-specific learning. This strategy induces severe gradient interference and renders optimization ill-conditioned as model scale and modal diversity grow, a problem empirically evidenced by frequent gradient explosions and numerical failures in state-of-the-art approaches.
BabelRS reframes this paradigm by introducing early, language-pivoted alignment to decouple cross-modal semantic unification from downstream detection learning. Leveraging language as a universal anchor, BabelRS aligns disjoint modality datasets to a shared linguistic manifold, enabling robust and stable training dynamics. The framework comprises two components: Concept-Shared Instruction Aligning (CSIA) and Layerwise Visual-Semantic Annealing (LVSA), designed to optimize semantic alignment and multi-scale feature integration, respectively.
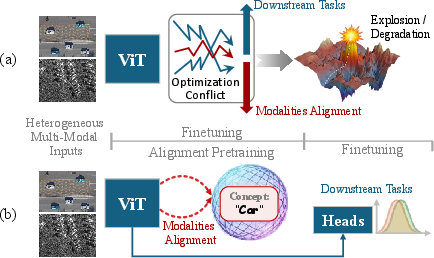
Figure 1: Late-stage modality alignment entangles cross-modal feature fusion with task loss, destabilizing optimization; BabelRS decouples these with language-pivoted early alignment.
Methodology
Concept-Shared Instruction Aligning
CSIA employs large-scale, instruction-following pretraining, aligning visual features from multiple modalities by projecting them into the embedding space of a frozen LLM. Each training sample comprises an RS image, a natural language instruction, and an answer; images from disparate modalities are thus mapped to linguistically consistent representations via a causal language modeling objective. Unlike prior paired-data dependent fusion models, BabelRS exploits spatially heterogeneous datasets, relying only on the semantic equivalence of language-level instructions.
Layerwise Visual-Semantic Annealing
Dense detection tasks require features spanning multiple spatial resolutions. LVSA incorporates visual features from intermediate layers of the backbone into the language-aligned space through a controlled, annealed fusion schedule. Fusion coefficients are annealed over a curriculum, progressively blending multi-scale visual representations into the language-pivoted embedding. This approach mitigates feature-space distribution shifts, stabilizes optimization, and guarantees that both low- and high-level features are semantically consistent and spatially discriminative.
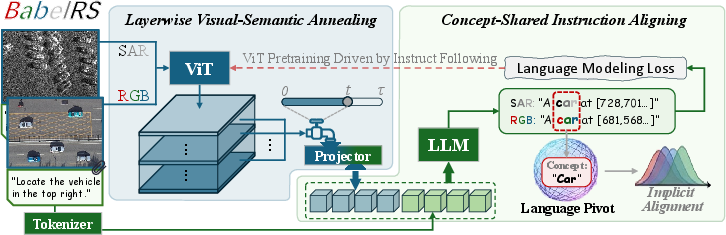
Figure 2: BabelRS architecture: CSIA projects modality-diverse features to a shared language space, and LVSA incrementally incorporates multi-scale features for dense localization.
Optimization Dynamics and Stability
Joint late-alignment methods suffer from destructive gradient interference, particularly as backbone dimensionality and modal heterogeneity increase. Theoretical analysis in the paper demonstrates that misaligned detection and alignment gradients result in uncapped condition numbers for the Hessian of the optimization landscape, leading to instability and poor convergence. By offloading alignment to a dedicated pretraining phase, BabelRS achieves positive inter-modal gradient coherence during task-specific fine-tuning, empirically confirmed by smooth loss curves and robust gradient norms—especially under AMP precision regimes where late-alignment methods fail.

Figure 3: BabelRS maintains stable gradients during fine-tuning, avoiding the gradient explosions that destabilize competing architectures.
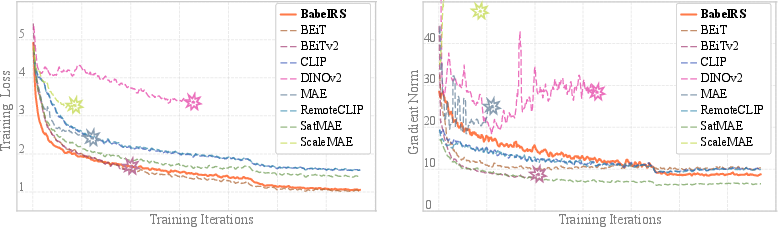
Figure 4: AMP loss/gradient trajectories: BabelRS exhibits controlled gradients and smooth loss, in contrast to late-alignment baseline spikes and NaNs.
BabelRS consistently surpasses both generic and remote-sensing-specific late-alignment pretraining methods. On the SOI-Det benchmark, it achieves the highest AP@50, overall mAP, and crucially, the Harmonic Modality mAP (H-mAP), a robust metric penalizing modality-specific failures. It demonstrates substantial gains especially in SAR and IR domains, where semantics deviate most from typical RGB-centric pretraining. Noteworthily, competing late-alignment pretraining strategies (e.g., CLIP, MAE, BEiT, SatMAE, DINOv2, ScaleMAE) not only lag in accuracy but frequently diverge under aggressive optimization protocols.
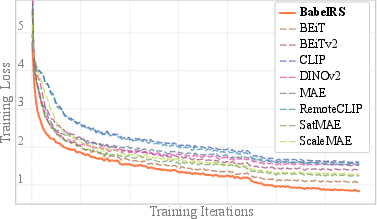
Figure 5: BabelRS achieves lower initial loss and smooth convergence, in contrast to the erratic training dynamics of late-alignment competitors.
Ablation: Multi-Scale Feature Integration
The LVSA module outperforms alternative feature merging strategies (concatenation, summation, independent projectors on each layer), delivering superior mAP and H-mAP with minimal complexity. Table and figure ablations confirm that progressive annealed fusion is necessary; abrupt or non-hierarchical aggregation degrades both optimization and final test performance.
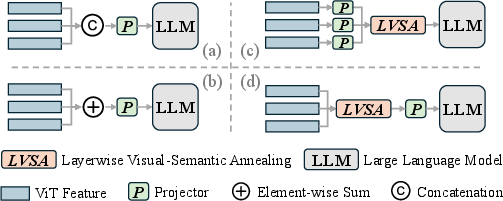
Figure 6: Comparison of feature merge paradigms; only LVSA-based progressive fusion with a shared projector yields optimal trade-off between stability and accuracy.
Analysis: Pretraining Duration and Annealing Schedules
Analysis of pretraining step count and annealing schedule length demonstrates that longer pretraining and gradual LVSA fusion reliably improve both mAP and H-mAP, with performance saturating at moderate curriculum lengths. Overly rapid multi-scale feature incorporation destabilizes the optimization landscape, whereas excessively slow annealing yields diminishing returns.
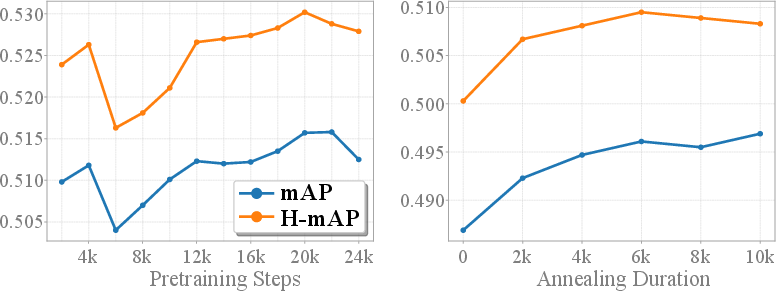
Figure 7: Both pretraining duration and LVSA annealing schedule are positively correlated with detection accuracy, with optimal results at moderate to high values.
Implications and Future Directions
BabelRS establishes that early, language-pivoted alignment is both theoretically and practically superior for heterogeneous multi-modal RS detection. Decoupling cross-modal semantics from task learning not only stabilizes joint optimization for massive vision backbones but also broadens generalization capacity for under-resourced or sparsely labeled modalities. This points toward a unification path for geospatial foundation models—scalable to temporal, multi-task, and multi-sensor regimes—via language-pivoted, curriculum-based training.
Practical implications include enabling robust RS object detection with reduced demand for meticulously labeled and spatially aligned multi-modal datasets, as well as facilitating extensibility to new sensor types by adapting language ontologies. Further research directions include hierarchical language prompt engineering for fine-grained domain adaptation, hybrid backbones coupling language-aligned cores with lightweight sensor-specific modules, and the extension of BabelRS to spatiotemporal tasks and multi-task objectives (instance/semantic segmentation, video detection, etc.).
Conclusion
BabelRS delivers a formal and empirical framework for language-pivoted pretraining in heterogeneous multi-modal remote sensing, establishing a new SOTA in cross-modal object detection. By decoupling alignment from task learning and leveraging progressive multi-scale feature integration, BabelRS addresses the long-standing optimization and generalization limitations of late-alignment paradigms, setting a precedent for future RS and geospatial foundation models.
(2603.01758)