Pessimistic Auxiliary Policy for Offline Reinforcement Learning
Abstract: Offline reinforcement learning aims to learn an agent from pre-collected datasets, avoiding unsafe and inefficient real-time interaction. However, inevitable access to out-ofdistribution actions during the learning process introduces approximation errors, causing the error accumulation and considerable overestimation. In this paper, we construct a new pessimistic auxiliary policy for sampling reliable actions. Specifically, we develop a pessimistic auxiliary strategy by maximizing the lower confidence bound of the Q-function. The pessimistic auxiliary strategy exhibits a relatively high value and low uncertainty in the vicinity of the learned policy, avoiding the learned policy sampling high-value actions with potentially high errors during the learning process. Less approximation error introduced by sampled action from pessimistic auxiliary strategy leads to the alleviation of error accumulation. Extensive experiments on offline reinforcement learning benchmarks reveal that utilizing the pessimistic auxiliary strategy can effectively improve the efficacy of other offline RL approaches.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
Imagine learning to play a video game only by watching recordings, without ever touching the controller. That’s what “offline reinforcement learning” (offline RL) tries to do: train an AI from a fixed dataset instead of live trial-and-error. The problem is, the AI sometimes imagines moves it never saw in the recordings and becomes overly confident about them. This paper proposes a simple fix: a cautious “helper policy” (they call it a pessimistic auxiliary policy) that steers the AI toward reliable, low-risk actions while it learns from the offline data.
What questions the paper asks
- How can we stop an offline RL agent from overestimating the value of risky, unfamiliar actions it never saw in the dataset?
- Can a cautious, helper strategy that prefers safer, more certain actions reduce these errors and make learning more stable and effective?
- Will this idea work as a “plug-in” to improve different offline RL methods?
How the method works (in everyday terms)
First, some quick, simple ideas the method relies on:
- Offline RL: The agent learns only from a pre-collected dataset of state–action–reward examples (no new interaction with the real environment).
- Q-function: A “scorekeeper” that predicts how good an action is in a given situation (higher = better future rewards).
- Uncertainty: How unsure the agent is about its own predictions. If two separate judges (two Q networks) disagree a lot, uncertainty is high.
Here’s the approach, step by step, with plain analogies:
- Two judges for confidence
- The agent keeps two Q networks that both score how good an action is. If they agree, we’re probably in a familiar, well-understood situation. If they disagree, it’s likely unfamiliar or risky.
- This “disagreement” is used as an uncertainty measure.
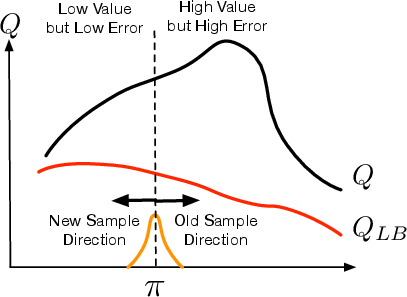
- A cautious score (lower confidence bound)
- Instead of trusting the optimistic score (“this move looks great!”), the method builds a cautious score: optimistic score minus a safety margin based on uncertainty.
- Think of it as: “Even if it looks good, let’s subtract a buffer if we’re uncertain.”
- A cautious helper policy (the pessimistic auxiliary policy)
- The agent’s current policy suggests an action. The helper policy then “nudges” that action in the direction that increases the cautious score the most, but only a little (so we don’t go too far from what the agent already knows).
- This “little nudge” comes from a simple local approximation (like looking at the slope on a small patch of a hill to decide which way to take a small step).
- There’s also a limit on how far this helper can move the action, so the agent stays near familiar territory and doesn’t become unstable.
- Use the cautious helper during learning
- When the agent updates its Q-function (its action scores), it uses actions suggested by the cautious helper policy rather than freely inventing actions.
- When the agent updates its own policy, it’s also guided by this cautious score and is gently kept close to actions seen in the dataset.
- Theory check: will it converge?
- The authors show that these updates stay within safe value ranges and still shrink errors over time, so the learning process remains stable and converges.
In short: the method adds a built-in, pessimistic “coach” that prefers reliable actions and avoids overconfident guesses in unknown areas.
What they found and why it matters
The authors tested their cautious helper on widely used offline RL benchmarks:
- D4RL “Gym” (robot control tasks like HalfCheetah, Hopper, Walker2d),
- D4RL “Adroit” (dexterous hand control),
- D4RL “AntMaze” (navigation),
- and NeoRL-2 (more realistic, real-world flavored tasks).
They plugged their idea into two popular offline RL methods:
- TD3-BC → becomes TD3PA (with the pessimistic helper),
- Diffusion-QL → becomes DQLPA.
What happened:
- Performance improved across most tasks, often by a clear margin, especially in harder settings like maze navigation.
- The learned Q-values became less overconfident (smaller gap between predicted value and actual returns).
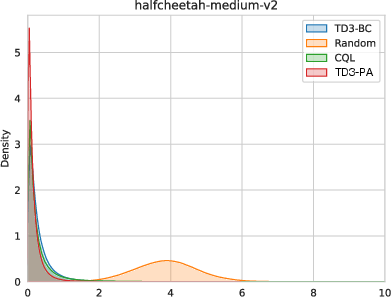
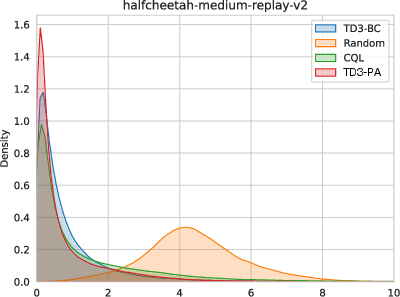
- The agent’s chosen actions stayed closer to those in the dataset, meaning fewer risky, unfamiliar moves during learning.
Why this is important:
- Less overestimation means fewer bad decisions based on inflated expectations.
- Staying near the dataset avoids the “I’ve never seen this move but I think it’s awesome” trap.
- The helper is a simple, general add-on, so it can enhance many offline RL approaches.
What this could change going forward
- Safer learning from fixed data: In areas like robotics or healthcare, where experimenting live can be risky or costly, a cautious helper can make offline learning more reliable.
- Easy to adopt: Because it’s a plug-in strategy, other offline RL methods can benefit without redesigning everything.
- Better real-world readiness: Reducing overconfidence on unfamiliar situations helps agents behave more responsibly and perform better when deployed.
Overall, the paper’s message is: when you can’t try things out live, it’s smart to be cautiously optimistic. By nudging actions toward low-uncertainty, well-understood choices, you get more accurate learning and better results.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions that remain unresolved and could guide future research.
- Uncertainty estimator validity and calibration
- The epistemic uncertainty is approximated using only two critics and a Gaussian assumption (δ_Q = 0.5|Q¹−Q²|). There is no empirical calibration (e.g., reliability diagrams) or analysis of correlation with TD error. It remains unclear whether this surrogate tracks true epistemic uncertainty across states/actions.
- Lack of ablations on ensemble size and alternative uncertainty estimators (bootstrapped ensembles, dropout, evidential methods, distributional critics) to assess impact on performance and robustness.
- Local Taylor approximation and trust region size
- The pessimistic auxiliary action μ_p is derived from a first-order Taylor expansion of the lower-confidence Q around the current policy μ. There is no bound on the approximation error or a principled way to choose the neighborhood radius σ where the linearization remains accurate.
- No curvature-aware variant is explored (e.g., second-order terms, Hessian or natural-gradient trust regions) to ensure valid local improvement when Q is highly non-linear.
- Choice and scheduling of pessimism and step-size hyperparameters
- The pessimism level β and the action-radius σ are fixed or scheduled heuristically (cosine annealing), with no sensitivity analysis, adaptive control, or state-dependent tuning. How to set β, σ to balance conservatism and learning speed across datasets is not addressed.
- Theoretical convergence and operator properties
- The convergence argument for the new Bellman operator T_p assumes μ_p yields “lower uncertainty than μ” and then asserts a contraction-like property without rigorous conditions. A precise proof is needed because μ_p depends on Q (policy-improvement step), making T_p a non-stationary operator.
- No finite-sample or error-propagation bounds are provided for learning with the uncertainty-driven auxiliary policy.
- Metric and constraint formulation
- The “Wasserstein distance” between Dirac policies is taken as 0.5∥μ_p−μ∥², which diverges from the standard 2-Wasserstein distance between point masses (which is ∥μ_p−μ∥). A principled choice of metric (e.g., KL to behavior model, CEM-based trust region, or true W₂) and its implications are not examined.
- The L2 action-space constraint does not guarantee in-distribution sampling; actions close in L2 can still be out-of-distribution under the behavior policy. How to tie the constraint to data coverage (e.g., via density models or classifier-based support estimators) is not explored.
- Integration with stochastic/diffusion and discrete policies
- The method is derived for deterministic policies with Dirac distributions. Its extension to stochastic policies, diffusion models (beyond the empirical DQLPA integration), and discrete action spaces is not theoretically or algorithmically detailed.
- How to compute μ and ∇_aQ_LB in diffusion-based policies (where sampling is nontrivial and actions are multi-modal) needs clearer algorithmic description and analysis.
- Early-training stability and failure modes
- When critics are poorly learned or nearly identical (Q¹≈Q²), δ_Q becomes small and Q_LB may be overconfident, potentially yielding misleading μ_p updates. Safeguards (burn-in, β annealing, uncertainty thresholds, or fallback to behavior actions) are not studied.
- Failure-case analysis is missing for regimes where uncertainty is miscalibrated, dynamics are highly stochastic, or rewards are noisy/outlier-prone.
- Interaction with existing conservatism and regularization
- The interplay with conservative value penalties (e.g., CQL), behavior cloning constraints, or regularizers used in IQL/AWAC is not systematically analyzed. Are gains additive, redundant, or conflicting?
- Ablations comparing “maximize Q_LB” versus simpler pessimistic heuristics (min of double-Q, clipped targets) would clarify where the benefit comes from.
- Coverage and generality of empirical evaluation
- Experiments focus on D4RL continuous-control and NeoRL-2; there is no evaluation on image-based tasks, partially observable settings, or highly stochastic domains, where uncertainty estimation and local linearization may behave differently.
- No reporting of confidence intervals in many tables; NeoRL-2 uses only 3 seeds. Statistical significance and variance across seeds/environments need fuller reporting.
- Off-policy evaluation (OPE) of value estimates
- Overestimation is assessed via online rollouts (environment access), which is not available in true offline settings. Incorporating OPE (e.g., FQE, MAGIC, doubly robust estimators) would provide offline-compatible diagnostics for value bias and policy quality.
- Computational overhead and scalability
- The additional gradients through Q_LB are claimed inexpensive but not quantified. Wall-clock time, GPU memory, and scaling on high-dimensional action/state spaces or larger networks are not reported.
- Effect of data quality and coverage
- The method aims to avoid OOD actions but does not quantify its behavior under extreme suboptimal or highly narrow datasets, long-horizon sparse-reward tasks, or severe state-distribution shift (not just action shift).
- Behavior policy modeling in policy extraction
- The policy objective includes a behavior term log πβ(π(s)|s), but details on estimating πβ (e.g., behavior cloning model, density model) and its fidelity are limited. The sensitivity of results to the behavior model quality is not analyzed.
- Robustness to reward scaling and misspecification
- No experiments study the effects of reward normalization/scaling, corrupted rewards, or different discount factors γ on the stability and efficacy of the pessimistic auxiliary policy.
- Second-order effects on exploration vs. conservatism
- While the approach reduces OOD actions, it may sacrifice improvement when the dataset is suboptimal. A principled mechanism to trade off improvement (policy advancement) against pessimism, possibly state- or dataset-dependent, is not provided.
- State-wise vs. action-wise conservatism
- The method only constrains action shifts near μ; it does not address out-of-distribution states. Combining state coverage estimators (e.g., density models or uncertainty on dynamics) with action-level pessimism is left unexplored.
- Compatibility with model-based and hybrid methods
- How the auxiliary pessimistic policy interacts with model-based offline RL (e.g., MOPO, MOReL) or with uncertainty in dynamics models is not addressed. Cross-paradigm synergies remain open.
- Formal connection between uncertainty and approximation error
- The paper motivates that lower epistemic uncertainty implies lower approximation error using linear regression intuition. A formal statement or empirical study relating δ_Q to TD error across training and datasets is missing.
- Reproducibility and derivational clarity
- Several equations contain typographical inconsistencies (e.g., δ vs. σ, bounds for Q, “γ concentration” vs. contraction). A clarified derivation and open-source code with detailed integration steps (especially for DQLPA) would improve reproducibility.
Practical Applications
Immediate Applications
The following applications can be deployed with current offline RL pipelines by plugging in the paper’s pessimistic auxiliary policy (PAP) module (i.e., lower-confidence-bound–guided action sampling near the learned policy using twin-Q uncertainty), with minimal engineering overhead and no additional networks.
- Software/ML Tooling: PAP plug-in for offline RL libraries
- Sector: Software, ML infrastructure
- What: Release a lightweight module for TD3-BC, Diffusion-QL, IQL-like algorithms that computes π_p via the lower confidence bound (LCB) gradient step and replaces target action sampling in the Bellman update.
- Tools/workflows: Integration into existing frameworks (e.g., Stable Baselines3, CleanRL, Acme) with:
- Twin-Q variance as uncertainty proxy, β for pessimism, cosine-annealed σ for proximity constraint
- Training loop hooks for computing π_p and swapping the target operator
- Monitoring: overestimation gap (Q vs. Monte Carlo), dataset-action distance, OOD action rates
- Assumptions/dependencies: Continuous actions with differentiable Q(s, a); twin Qs available (or ensembles); appropriate β, σ schedules; sufficient dataset coverage.
- Robotics & Industrial Automation: Safer offline policy learning from logs
- Sector: Robotics, manufacturing, logistics
- What: Train manipulation, assembly, and navigation policies from pre-collected robot logs or simulation buffers with reduced OOD overestimation (e.g., bin picking, kitting, mobile robot navigation in warehouses).
- Tools/workflows:
- Add PAP to existing TD3-BC/Diffusion-QL pipelines used for sim-to-real
- Validation via offline evaluation and replay datasets (e.g., D4RL-like setups)
- Assumptions/dependencies: Adequate diversity in logged data; continuous control; reliable state estimation and calibration; offline validation in simulators before deployment.
- Recommender Systems & Online Platforms: Conservative policy optimization from logged interactions
- Sector: Internet services, advertising, content platforms
- What: Learn ranking/serving policies from bandit logs while curbing OOD action overestimation (e.g., CTR optimization with offline RL backbones).
- Tools/workflows:
- Actor-critic offline RL with PAP for target sampling
- IPS/DR-based simulators for offline policy evaluation; batch logging workflows
- Assumptions/dependencies: Action space must be parameterized continuously (e.g., continuous scores or embeddings) or adapted; robust counterfactual evaluation; compliance with user safety constraints.
- Energy & Process Control: Offline control from historical SCADA/plant logs
- Sector: Energy, chemicals, manufacturing process control
- What: Train conservative controllers for setpoint tuning, anomaly mitigation, or demand response from historical operations without online exploration.
- Tools/workflows:
- PAP-enabled offline RL loops integrated with digital twin simulators
- Shadow deployment with human-in-the-loop approval
- Assumptions/dependencies: Sufficient coverage of normal/abnormal regimes in logs; stable state estimation; hard safety constraints enforced during deployment.
- Autonomy & Mobility: Offline navigation and planning policies
- Sector: Autonomous driving, drones, mobile robotics
- What: Train waypoint-following, obstacle-avoidance, or path-planning policies using fleet logs; PAP reduces risky OOD action overestimation (analogous to AntMaze improvements).
- Tools/workflows:
- Data curation from fleet logs; PAP in TD3-BC/Diffusion-QL stacks
- Evaluation in scenario libraries (e.g., MetaDrive, CARLA)
- Assumptions/dependencies: High-quality logs; careful scenario coverage; continuous control assumptions; strict safety validation before on-road trials.
- Finance (Research/Backtesting): Offline RL for strategy learning from market history
- Sector: Finance
- What: Use PAP to train trading/execution policies with conservative action sampling to mitigate overestimation induced by rare/unseen market conditions.
- Tools/workflows:
- Backtesting frameworks; stress tests with regime shifts
- Risk constraints integrated as penalties during policy extraction
- Assumptions/dependencies: Continuous action parameterization (e.g., order size); careful train/test split to avoid leakage; regulatory compliance.
- Education (Offline Personalization): Policy learning from historical tutoring logs
- Sector: EdTech
- What: Learn content/pace recommendation policies using PAP to avoid risky OOD sequences that the data does not support.
- Tools/workflows:
- Offline simulators or replay evaluations; uncertainty-aware policy updates
- Assumptions/dependencies: Counterfactual evaluation quality; action parameterization; data coverage across student profiles.
- Healthcare (Retrospective Decision Support Research): Safer offline RL analysis from EHR logs
- Sector: Healthcare
- What: Retrospective training and analysis of dosing/triage policies with PAP to reduce overestimation and prioritize low-uncertainty recommendations.
- Tools/workflows:
- Retrospective policy evaluation; clinician-in-the-loop review
- Logging of uncertainty metrics and avoidance of OOD actions
- Assumptions/dependencies: Observational biases managed (e.g., confounding); strict non-deployment for live care without trials; continuous action modeling.
- Public Policy Simulation: Counterfactual policy exploration from administrative data
- Sector: Government/Policy
- What: Use PAP-enabled offline RL to simulate and stress-test policy interventions (subsidies, inspections) conservatively, focusing on well-supported action regimes.
- Tools/workflows:
- Retrospective simulations; sensitivity analyses; fairness checks
- Assumptions/dependencies: Strong causal identification strategy; action parameterization; policy remains in retrospective simulation phase.
- Consumer/IoT Optimization (Offline updates): Energy/comfort schedulers learned from usage logs
- Sector: Consumer electronics, smart home, HVAC
- What: Update thermostat/charging/scheduling policies offline with PAP to lower risk of unsound behaviors due to sparse logs.
- Tools/workflows:
- On-device batch updates; fallback safe controllers
- Assumptions/dependencies: Continuous control; robust fallback policies; privacy-preserving data handling.
Long-Term Applications
These opportunities require further research, domain adaptation, regulatory approvals, or scaling to discrete/structured action spaces, partial observability, or multi-agent settings.
- Safety-Critical Deployment in Healthcare: Live clinical decision support
- Sector: Healthcare
- What: Transition PAP-enabled policies from retrospective analysis to bedside decision support with on-policy monitoring and guardrails.
- Potential products/workflows: Certified RL-based dosing advisors with uncertainty-aware recommendations and hard safety constraints.
- Assumptions/dependencies: Prospective trials, regulatory approval (FDA/EMA), causality-aware offline RL, robust POMDP handling, clinician oversight.
- Autonomous Driving Stack Integration: Fleet-scale offline RL with PAP
- Sector: Automotive
- What: Incorporate PAP into large-scale perception–planning stacks to train policies from fleet logs with measurable safety gains.
- Potential products/workflows: Safety case artifacts, PAP-enabled value estimation modules, ODD-aware training pipelines.
- Assumptions/dependencies: Extensive scenario coverage, certification frameworks, interpretable uncertainty; interaction with rule-based safety layers.
- Grid & Industrial Orchestration: Closed-loop PAP-enabled controllers
- Sector: Energy, smart grids, process industries
- What: Deploy PAP-trained policies in real-time SCADA systems for economic dispatch, DER coordination, and alarm response.
- Potential products/workflows: Digital twin + RL co-simulation, anomaly-aware fallbacks, certified safety envelopes.
- Assumptions/dependencies: Robust online monitoring, fail-safe switching, discrete/structured action adaptations.
- Discrete/Structured Action Extensions: PAP for combinatorial decisions
- Sector: Software, logistics, networking
- What: Extend LCB-guided pessimistic sampling to discrete actions (e.g., routing choices, inventory decisions) via differentiable surrogates or Gumbel-Softmax.
- Potential products/workflows: PAP variants using action embeddings, cross-entropy-based pessimistic selection, or ensemble-based LCB on discrete sets.
- Assumptions/dependencies: New theory/algorithms for non-differentiable action spaces; computational trade-offs.
- Multi-Agent Offline RL with Pessimism: Coordinated policies from logs
- Sector: Robotics swarms, multi-robot warehouses, traffic control
- What: Apply PAP to multi-agent critics to avoid joint-action OOD blow-up and stabilize coordination learning.
- Potential products/workflows: Centralized training with decentralized execution (CTDE) and uncertainty-aware critics.
- Assumptions/dependencies: Scalability of uncertainty measures; counterfactual joint-action estimation.
- RL for Recommender/Ads with Safety & Fairness Constraints
- Sector: Internet platforms, advertising
- What: Combine PAP with fairness, exposure, and content risk constraints to deploy safer, auditable recommenders.
- Potential products/workflows: Constrained offline RL stacks with PAP, calibrated uncertainty estimates, bias mitigation.
- Assumptions/dependencies: High-quality evaluation (e.g., logged bandits with positivity); stakeholder-defined fairness metrics.
- Regulation & Standards: Pessimism-by-Design for Offline RL
- Sector: Policy, standards bodies
- What: Codify conservative uncertainty-aware targets (e.g., LCBs) into safety guidelines for offline RL in high-stakes domains.
- Potential products/workflows: Compliance checklists, auditing tools measuring OOD action rates and overestimation gaps.
- Assumptions/dependencies: Cross-domain consensus on metrics and thresholds; standardized datasets for benchmarking.
- Data-Centric Offline RL Operations: Curation and uncertainty monitoring
- Sector: MLOps, data engineering
- What: Build pipelines to quantify coverage, sparsity, and epistemic uncertainty, feeding PAP schedules (β, σ) adaptively.
- Potential products/workflows: Dataset coverage dashboards, adaptive pessimism controllers, auto-tuning of σ via validation overestimation metrics.
- Assumptions/dependencies: Reliable proxies for uncertainty; scalable logging and analytics.
- Foundation-Model + RL Hybrids: PAP with diffusion/model-based policies at scale
- Sector: General AI, robotics
- What: Integrate PAP with diffusion policies, world models, or large control-oriented foundation models to safely exploit generative priors offline.
- Potential products/workflows: Uncertainty-aware action sampling atop generative action models; hybrid value–model controllers.
- Assumptions/dependencies: Calibrated uncertainty in generative models; alignment of LCB with model confidence.
- Daily-Life Assistant Systems: Personalized automation with assured safety
- Sector: Consumer AI
- What: Offline-learned assistants (scheduling, diet, training plans) with PAP to avoid risky/unvalidated recommendations.
- Potential products/workflows: On-device policy updates with strict bounds, uncertainty-driven abstention/deferral.
- Assumptions/dependencies: Privacy-preserving data processing; interpretable uncertainty; user consent and transparency.
Notes on feasibility and transferability (common dependencies across use cases):
- Method assumptions: Continuous action spaces with differentiable Q(s, a); twin Q-networks (or ensembles) to estimate epistemic uncertainty; local linearity validity for Taylor approximation near the current policy (small σ).
- Data dependencies: Offline datasets must cover relevant state–action regions; PAP mitigates but does not remove distribution shift risks.
- Hyperparameters: β (pessimism level) and σ (distance bound) require tuning; cosine annealing for σ is effective per paper.
- Compute/engineering: Minimal overhead vs. baselines; ensure numerical stability and gradient quality for ∇_a Q_LB.
- Safety: PAP reduces overestimation but should be combined with domain constraints, uncertainty-aware abstention, and robust offline evaluation before deployment.
Glossary
- Banach space: A complete normed vector space used to analyze contraction mappings and convergence. "Due to the bellman operator is a contractor under Banach space,"
- Behavior policy: The policy that generated the offline dataset, often used as a reference for constraints. "behavior policy might be difficult to be obtained."
- Bellman optimality operator: The operator that defines the optimal value backup in RL. "is the Bellman optimality operator:"
- Bellman residual: The squared difference between the current Q-value and its Bellman backup used for training. "The value function is learned by minimizing the bellman residual:"
- Bootstrapping: Updating estimates using other learned estimates (e.g., next-step value), potentially compounding errors. "Apart from the bootstrapping associated with temporal difference (TD) updates, the neural network of the agent engages in linear regression."
- CQL (Conservative Q-learning): An offline RL algorithm that penalizes Q-values for OOD actions to reduce overestimation. "CQL directly minimizes the Q-values of OOD actions and maximizes the Q-values of in-distribution actions."
- Cosine annealing: A scheduling technique that smoothly decays a hyperparameter following a cosine curve. "Hence, we adopt cosine annealing to scale the δ appropriately, ensuring a smooth transition from the initial value (δ_init=1) to zero."
- D4RL: A suite of standardized offline RL datasets and benchmarks. "Extensive experiments conducted on D4RL benchmark demonstrate pessimistic auxiliary policy can effectively improve the efficacy of TD3BC and Diffusion-QL."
- Deterministic policy: A policy that outputs a single action for each state (no randomness). "here, we utilize wasserstein distance to calculate the distance of two deterministic policy and ."
- Diffusion-QL: An offline RL method that leverages diffusion models for policy learning. "we apply pessimistic auxiliary policy to the TD3BC and Diffusion-QL."
- Dirac distribution: A degenerate distribution concentrated at a single point, representing a deterministic choice. "where is the learned policy under Dirac distribution "
- Distribution shift: The mismatch between the behavior policy’s data distribution and the learned policy’s induced distribution. "The distribution shift refers to the difference between the behavior policy and the current learned policy."
- Epistemic uncertainty: Model uncertainty arising from limited data, reducible with more evidence. "Epistemic uncertainty is adopted to assess the reliability of the predictive model,"
- Error accumulation: The compounding of estimation errors over iterative TD backups. "causing the error accumulation and considerable overestimation."
- Explicit divergence penalties: Direct regularizers that penalize divergence between the learned policy and the behavior policy. "utilizing explicit divergence penalties"
- First-order Taylor expansion: Linear approximation of a function around a point using its gradient. "By first-order Taylor expansion of the lower confidence bound, an appropriate pessimistic auxiliary policy within the neighborhood of current policy can be found."
- Gaussian distribution: A normal distribution used here to model uncertainty of value estimates. "we model the Epistemic uncertainty using Gaussian distribution,"
- γ concentration: The property that a Bellman-like operator is a contraction with factor γ, ensuring convergence. "Boundedness (Proposition 2) and γ concentration guarantee the convergence of ."
- KKT condition: Necessary conditions (Karush–Kuhn–Tucker) for optimality in constrained optimization. "By KKT condition, we can know "
- Lagrangian function: A function combining objective and constraints via multipliers for constrained optimization. "To solve the Eq. \ref{eq:11}, we construct the Lagrangian function:"
- Lower confidence bound: A pessimistic value estimate defined as mean minus a multiple of standard deviation. "we maximize the lower confidence bound of the Q-function."
- Markov Decision Process: A formal model for sequential decision-making defined by states, actions, transitions, and rewards. "We consider a Markov Decision Process formulated environment"
- MuJoCo: A physics simulation suite often used to benchmark continuous-control RL. "The experiments are run on MuJoCo-v2, Adroit-v0 and AntMaze-v0 dataset"
- NeoRL-2: A near real-world offline RL benchmark introducing realistic complexities. "Additionally, we evaluate our method on NeoRL-2"
- Offline reinforcement learning: Learning policies solely from fixed, pre-collected datasets without further environment interaction. "Offline reinforcement learning aims to learn an agent from pre-collected datasets,"
- Out-of-distribution (OOD) actions: Actions not well represented in the dataset, leading to unreliable value estimates. "out-of-distribution (OOD) actions might be encountered,"
- Pessimism in the face of uncertainty: A principle that selects actions by considering lower bounds under uncertainty to avoid overestimation. "new policy impedes exploration by applying the principle of pessimism in the face of uncertainty"
- Pessimistic auxiliary policy: An auxiliary policy that maximizes a lower confidence bound to sample reliable, low-uncertainty actions. "we construct a new pessimistic auxiliary policy for sampling reliable actions."
- Policy constraint approaches: Offline RL methods that restrict the learned policy to remain close to the behavior policy. "Policy constraint approaches regularize the learned policy to be close to the behavior policy,"
- Policy evaluation: The phase where value functions are learned via minimizing Bellman error. "Policy evaluation. The value function is learned by minimizing the bellman residual:"
- Policy extraction: The phase where a policy is derived by maximizing estimated values under the learned Q-function. "Policy extraction. The optimal policy under the value function is extracted as follows:"
- Q-function: The action-value function estimating expected return of a state-action pair. "we maximize the lower confidence bound of the Q function"
- Replay buffer: A storage of experience tuples; in offline RL, the dataset may derive from a replay buffer. "m-r utilizes the replay buffer of a policy trained up to the performance of the medium agent;"
- Soft update: Gradual update of target network parameters using a smoothing factor τ. "Soft update target V-net"
- Target Q-net (target network): A periodically/soft-updated copy of the Q-network used for stable bootstrapping. " is the parameters of a separate target Q-net without gradient propagation"
- Temporal difference (TD) update: A learning rule updating value estimates based on bootstrapped targets from next states/actions. "temporal difference (TD) update "
- Uncertainty quantification: Measuring uncertainty in model predictions, often via ensembles or variance estimates. "Uncertainty Quantification. Epistemic uncertainty is adopted to assess the reliability of the predictive model,"
- Value regularization approaches: Methods that adjust or constrain value estimates to mitigate overestimation. "value regularization approaches, which directly regularize the value of actions sampled by the learned policy;"
- Wasserstein distance: A metric between probability distributions; here used to bound policy deviation. "here, we utilize wasserstein distance to calculate the distance of two deterministic policy and ."
- World model: A learned model that simulates environment dynamics for planning or policy learning. "constructing a world model to simulate the real world"
Collections
Sign up for free to add this paper to one or more collections.

