FlashOptim: Optimizers for Memory Efficient Training
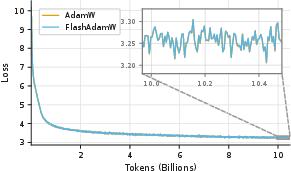
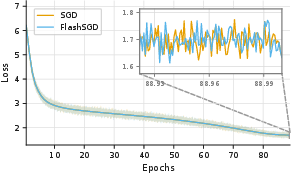
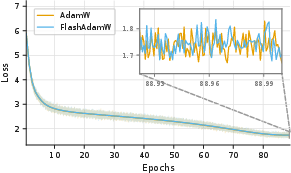
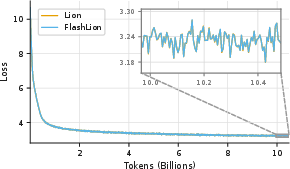
Abstract: Standard mixed-precision training of neural networks requires many bytes of accelerator memory for each model parameter. These bytes reflect not just the parameter itself, but also its gradient and one or more optimizer state variables. With each of these values typically requiring 4 bytes, training even a 7 billion parameter model can be impractical for researchers with less than 100GB of accelerator memory. We introduce FlashOptim, a suite of optimizations that reduces per-parameter memory by over 50% while preserving model quality and API compatibility. Our approach introduces two key techniques. First, we improve master weight splitting by finding and exploiting a tight bound on its quantization error. Second, we design companding functions that greatly reduce the error in 8-bit optimizer state quantization. Together with 16-bit gradients, these techniques reduce AdamW memory from 16 bytes to 7 bytes per parameter, or 5 bytes with gradient release. They also cut model checkpoint sizes by more than half. Experiments with FlashOptim applied to SGD, AdamW, and Lion show no measurable quality degradation on any task from a collection of standard vision and language benchmarks, including Llama-3.1-8B finetuning.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper presents FlashOptim, a set of clever tricks that makes training big neural networks use much less memory, without hurting speed or accuracy. Think of a neural network as a giant collection of numbers (called “weights”) that get adjusted during training. FlashOptim compresses how these numbers and their “helper” data are stored, so you can train larger models on the same hardware.
What is the paper trying to do?
In simple terms, the researchers asked:
- Can we cut the amount of memory needed per model weight by more than half during training?
- Can we do it without changing how optimizers work, slowing things down, or lowering the model’s quality?
- Can we make this easy to use, like a drop-in replacement for popular optimizers (SGD, AdamW, Lion)?
How did they do it?
To understand the approach, it helps to know three everyday ideas:
- Precision: Storing a number with more bits is like measuring with a ruler that has finer markings. 32-bit numbers have finer detail than 16-bit numbers, but take twice the memory.
- Gradients: These are the “directions” that tell the model how to adjust its weights during training.
- Optimizer state: Optimizers (like AdamW) keep extra data to make smarter updates. Two common pieces:
- Momentum: remembers the recent direction of changes (like pushing a cart, it keeps rolling).
- Variance: measures how “noisy” or uncertain the gradients are.
FlashOptim uses two key ideas:
1) Weight splitting (store the main number plus a tiny correction)
Normally, training keeps a full 32-bit “master” weight, plus a 16-bit copy used for fast math. That’s redundant. Instead, FlashOptim:
- Stores the 16-bit weight (the nearest mark on the shorter ruler),
- And a small “correction” number that says how far between marks the true value is.
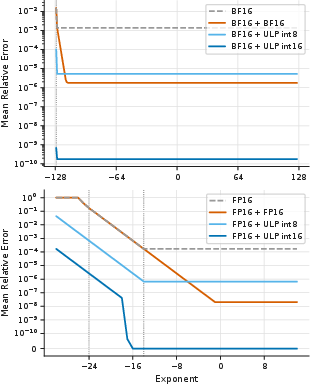
Analogy: If your ruler only shows centimeters, you save the centimeter mark plus a tiny note like “+0.3 cm” to reconstruct the original measurement. This combination acts like a 24-bit value: almost as precise as 32-bit, but much smaller.
The trick they use ensures the correction only needs a few bits because it always lives within a tiny, known range around the 16-bit value.
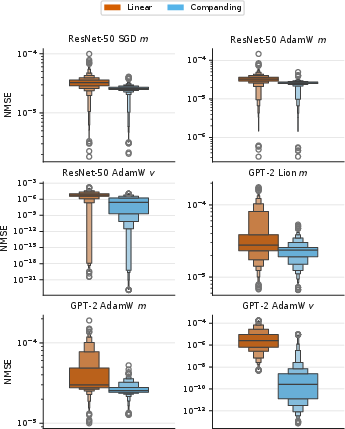
2) Companded quantization (smart squishing of optimizer state before compressing)
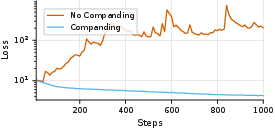
Compressing optimizer state (momentum and variance) to 8 bits can be risky if you do it naively, because those values aren’t evenly spread. FlashOptim uses a simple, one-line “companding” function that gently squishes extreme values toward the center before quantizing, and then unsquishes them later. This spreads the data more evenly across the 8-bit levels, reducing error.
Analogy: If you have tall and short items to fit on a shelf with limited levels, you temporarily compress the tall ones so everything fits better, then expand them back when you need them.
They also do this in small groups (like blocks of 32 numbers) and store one scale per group, which keeps compression accurate and fast.
What did they find?
Here are the main results, explained simply:
- Big memory savings per parameter:
- AdamW typically uses about 16 bytes per parameter during training.
- FlashOptim cuts that to about 7 bytes (and down to 5 bytes if “gradient release” is used, which throws away temporary gradients as soon as they’re used).
- Real-world memory reductions:
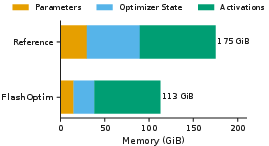
- Finetuning a large Llama-3.1-8B model saw peak memory drop from about 175 GiB to 113 GiB.
- Checkpoints (saved models) shrank by more than half (e.g., from ~84 GB to ~35 GB for a 7B model).
- Same accuracy and training behavior:
- On image classification (ResNet-50/ImageNet), LLM pretraining (GPT-2 on FineWeb), and finetuning (Llama-3.1-8B on math data), FlashOptim matched the quality of standard optimizers.
- Training curves (loss over time) looked the same.
- Little to no slowdown:
- The compression is implemented in fused kernels (fast GPU code), so training stays just as quick.
- Better precision where it matters:
- The weight splitting method reconstructs the original 32-bit weights extremely closely (often indistinguishable in practice).
- The companding step is crucial: without it, 8-bit optimizer states can cause training to break; with it, training stays stable.
Why is this important?
- Train bigger models on the same hardware: If you only have one or two GPUs, FlashOptim lets you fit models you couldn’t before.
- Save time and storage: Smaller checkpoints mean faster saves and less disk space.
- Easy to use: It works like a drop-in replacement for common optimizers, and it plays nicely with other memory-saving tricks (like sharding across GPUs or activation checkpointing).
- Open-source: You can try it today with the PyTorch library they released.
A quick note on limits
- If your model’s memory is mostly used by activations (temporary layer outputs), not parameters, the benefit may be smaller.
- Some models may be more sensitive to compression; the library lets you turn off compression for specific parts if needed.
- While 24-bit precision worked well in their tests, a rare case might still need full 32-bit precision for extreme tiny updates.
Final takeaway
FlashOptim makes training large neural networks much more memory-efficient by:
- Storing weights as a 16-bit value plus a tiny correction,
- Compressing optimizer states to 8 bits using simple, smart reshaping (companding).
It keeps speed and accuracy intact, cuts memory by over 50% for popular optimizers like AdamW, and helps more people train powerful models without needing huge, expensive hardware.
Knowledge Gaps
Below is a single, actionable list of knowledge gaps, limitations, and open questions that remain unresolved by the paper. These items focus on what is missing, uncertain, or left unexplored, and are phrased to guide follow-on research.
- Long-horizon stability at scale: Evaluate FlashOptim during full pretraining of large LLMs (≥7B–70B parameters) over 100B–1T+ tokens to assess cumulative drift of quantized moments and 24-bit master weights.
- Broader optimizer coverage: Extend and test the approach with additional optimizers (e.g., Adafactor, RMSProp, LAMB, Adagrad, NovoGrad, Muon, Adam-mini, SM3), including designing companders for their specific state statistics.
- Theoretical guarantees: Derive convergence/error bounds for training with ULP-based weight splitting and companded INT8/UINT8 moment quantization, including how errors propagate through bias correction and adaptive scaling in Adam-like methods.
- Sensitivity to hyperparameters: Systematically sweep β1/β2, ε, weight decay, learning rate schedules, and gradient clipping to map regimes where quantization/splitting is fragile or requires adjustments.
- Gradient accumulation compatibility: Quantify memory savings and throughput when gradient accumulation is enabled (where gradient release is inapplicable), and assess quality/efficiency trade-offs.
- Distributed training and communication: Measure end-to-end scalability with FSDP/ZeRO across many nodes, including comms overhead when only 16-bit parameters are all-gathered and optimizer states remain sharded/quantized.
- FP8 and other low-precision compute: Empirically validate composition with FP8 forward/backward and explore optimal precision assignments among weights, corrections, gradients, and optimizer states.
- Compander design space: Explore alternative or learned companding functions (e.g., log, µ-law, piecewise-linear, per-layer learned transforms) and provide criteria for selecting per-tensor companders.
- Grouping and scale precision: Ablate group size (e.g., 16/32/64/128) and scale precision (FP16 vs INT8 vs shared per-channel scales) to optimize the accuracy–memory trade-off, especially for small tensors.
- 4-bit states and mixed-bit allocations: Investigate whether 4-bit (or mixed 4/8-bit) optimizer states with appropriate companding can preserve quality, and quantify when they fail.
- Adaptive per-parameter bit allocation: Develop schemes that allocate 0/8/16-bit correction terms per parameter (or per block) based on error/importance to further reduce memory usage.
- Edge-case numerics: Specify and evaluate handling for zeros, subnormals, denormals, NaNs, and Infs in weight splitting and state quantization (including guards for zero scales and saturation behavior).
- Smallest-update elision: Quantify how often updates are dropped due to 24-bit master weights; test mitigations (stochastic rounding, Kahan-like accumulation, dynamic rescaling) and their costs.
- Bias and drift analysis: Analyze bias introduced by nonlinear companding/inversion in momentum/variance estimates over long training, and its effect on calibration and generalization.
- Modalities and architectures: Evaluate on modalities beyond ImageNet and GPT-2 finetuning (e.g., diffusion models, high-res vision tasks, segmentation, speech, GNNs, RNNs, multi-modal models, MoE) to assess generality.
- RL and alignment pipelines: Test in RLHF/SFT/DPO and other post-training stages where optimizer dynamics and state distributions differ from pretraining and supervised finetuning.
- Interplay with activation-dominated regimes: Quantify net memory/throughput gains on workloads dominated by activations (e.g., high-resolution CNN/ViT training) and combinations with activation checkpointing.
- Portability and hardware coverage: Benchmark on A100/RTX-class GPUs, AMD GPUs, TPUs, and CPU-only settings to assess kernel availability, throughput, and numerical reproducibility outside NVIDIA H100 + Triton.
- Checkpoint portability and robustness: Specify a portable checkpoint format, measure conversion costs to/from standard formats, and study resilience to partial corruption (e.g., lost rho bytes, ECC faults).
- Reproducibility and determinism: Characterize determinism across CUDA versions / rounding modes / hardware, and provide settings to guarantee bitwise reproducibility where needed.
- Communication compression synergy: Evaluate combining FlashOptim with gradient communication compression (e.g., PowerSGD, 1-bit/low-rank) to reduce bandwidth in multi-node training.
- CPU/NVMe offload interaction: Measure whether quantized states and split weights reduce offload bandwidth, and quantify dequantization overheads when offloading optimizer states.
- Per-layer selectivity: Develop automatic sensitivity detection to selectively disable compression on fragile layers (e.g., embeddings, layer norms, small layers) instead of relying on manual exclusion.
- Error metrics vs downstream quality: Go beyond NMSE by correlating quantization/splitting error with downstream metrics (e.g., perplexity, ICL accuracy, calibration) to guide method choices.
- Operational limits for linear quantization: Precisely characterize when non-companded linear quantization of variance/momentum is safe or diverges, and provide diagnostics/fallbacks.
- Kernel overheads on small models: Profile optimizer-step compute vs memory-bound behavior across model sizes to identify cases where companding and splitting become throughput bottlenecks.
- Memory/layout choices: Explore per-channel vs per-tensor vs blockwise layouts for scales/corrections to optimize cache/memory traffic, particularly under FSDP sharding.
- Security/fault tolerance: Study sensitivity to random bit flips in compressed states and corrections, and propose lightweight error-detection/correction strategies compatible with training.
Practical Applications
Immediate Applications
The following list distills practical, deployable uses of FlashOptim’s techniques that organizations can adopt now to reduce training memory without sacrificing quality.
- Drop-in memory-reduced training for common optimizers (software/AI across sectors)
- Use FlashAdamW, FlashSGD, or FlashLion as drop-in PyTorch optimizers to cut per-parameter training memory by >50% (e.g., AdamW from 16 B/param to 7 B/param; 5 B/param with gradient release).
- Concrete gains: training 7B-param models now fits in ~49 GB optimizer/weights vs ~112 GB (AdamW), enabling single- or fewer-GPU setups.
- Tools/workflows: pip-install FlashOptim, swap optimizer in training scripts, keep hyperparameters unchanged; integrate with PyTorch 2.8+ and CUDA 12.8.
- Assumptions/dependencies: BF16-capable GPUs (e.g., A100/H100), Triton-compatible environment, some tasks may need per-layer opt-out.
- Reduced peak memory for large-model finetuning (software/AI; healthcare, finance, legal)
- Finetune 7–8B LLMs with significantly lower peak memory (e.g., Llama‑3.1‑8B from 175 GiB to 113 GiB), enabling on-prem or smaller cloud SKUs.
- Tools/workflows: combine with FSDP/ZeRO and activation checkpointing for multiplicative savings; enable gradient release if not using gradient accumulation.
- Assumptions/dependencies: Activation memory may dominate on some models/datasets; gradient release incompatible with gradient accumulation.
- Smaller, faster checkpoints and cheaper storage (MLOps; academia; open-source)
- Cut checkpoint size by >50% (e.g., Adam: ~12 → 5 B/param; 7B model: ~84 GB → ~35 GB), reducing save/load time, CI runtime, bandwidth, and cloud storage bills.
- Tools/workflows: integrate FlashOptim checkpoints into training pipelines; faster experiment iteration and artifact sharing.
- Assumptions/dependencies: Teams must align artifact readers/writers; verify checkpoint compatibility for downstream tools.
- Train larger models or larger batches on fixed hardware (startups; research labs; education)
- Stretch limited-GPU budgets to run larger backbones, longer context windows, or higher batch sizes without changing training recipes.
- Tools/workflows: hyperparameters remain unchanged; “swap optimizer, keep schedule”; leverage same mixed precision and fused kernels.
- Assumptions/dependencies: Realized gains depend on how parameter vs activation memory dominates the workload.
- Democratized LLM/RL training for small labs and hobbyists (education; robotics; edge R&D)
- Enable full or near-full finetuning on 24–48 GB consumer/workstation GPUs where previously only LoRA/PEFT was feasible.
- Tools/workflows: integrate with Hugging Face Trainer or PyTorch Lightning; combine with PEFT if desired for further savings.
- Assumptions/dependencies: Some models/layers may be quantization-sensitive; selectively disable compression per layer if needed.
- On-prem privacy-preserving training in regulated domains (healthcare, finance, gov)
- Run finetuning within constrained on-prem clusters to keep data in-house, reducing the number of GPUs required and operational footprint.
- Tools/workflows: fold FlashOptim into secure MLOps stack; pair with FSDP for sharding states while only all-gathering 16-bit weights.
- Assumptions/dependencies: IT policy may require validation of new kernels/libraries; ensure deterministic training where required.
- Lower training costs and carbon footprint (cloud providers; enterprises)
- Fewer GPUs and smaller instances for the same training job reduce $/epoch and energy usage; smaller checkpoints cut IO energy and time.
- Tools/workflows: introduce “memory-optimized training” preset in internal platforms; update cost calculators and capacity planning.
- Assumptions/dependencies: Savings are workload-dependent (less benefit when activations dominate); internal validation for quality parity.
- Improved distributed training efficiency (HPC; SaaS ML platforms)
- Only 16-bit weights are all-gathered; optimizer corrections remain local, reducing comms volume and memory pressure per rank.
- Tools/workflows: use with FSDP/ZeRO; maintain drop-in optimizer semantics for simple adoption across multi-node jobs.
- Assumptions/dependencies: Overall speedups depend on network topology and how much optimizer-state sharding already exists.
- Faster iterative research and teaching (academia; MOOCs)
- Smaller memory footprint and checkpoints shorten iteration cycles in classes and workshops; more students can run larger labs on shared GPUs.
- Tools/workflows: standardize course repos with FlashOptim; provide smaller downloadable checkpoints for assignments.
- Assumptions/dependencies: Course infra must have BF16-capable GPUs; ensure compatibility with grading scripts and reproducibility settings.
Long-Term Applications
These opportunities likely require further research, ecosystem scaling, or hardware/compiler support to reach production maturity.
- Hardware and compiler co-design for sub-FP32 master weights (semiconductor; systems software)
- Native support for “24-bit effective master weights,” ULP-based splitting, and companding in hardware instructions or memory controllers to further reduce bandwidth/latency.
- Potential products: GPU/ASIC kernels with dedicated ops; training accelerators with on-die companders; compiler passes that auto-insert split/quant-dequant.
- Assumptions/dependencies: ISA changes and vendor tooling; validation across diverse workloads and numerics.
- Generalized companding for more tensors and optimizers (ML research; libraries)
- Extend simple, invertible companders to gradients, activations, and alternative optimizer states (e.g., second-order stats), unifying memory compression across the training stack.
- Potential tools: auto-tuned compander libraries; per-tensor distribution-aware transforms; layer/adaptive policies.
- Assumptions/dependencies: Stability on sensitive architectures; automated detection of distribution shifts to prevent divergence.
- Standardized compressed checkpoint formats (MLOps standards; cloud platforms)
- Industry-wide format for compressed weights/optimizer states with metadata for scales and companding transforms (“FlashCheckpoints”), enabling faster sharing and deployment.
- Potential products: cross-framework checkpoint converters; registry support (e.g., Model Hubs) for compressed artifacts.
- Assumptions/dependencies: Community consensus and backward compatibility; security review for new binary formats.
- On-device continual learning and federated training (mobile/edge; IoT; automotive)
- With smaller optimizer states and checkpoints, enable limited-scope on-device model adaptation and federated rounds with lower bandwidth/compute budgets.
- Potential products: edge SDKs with memory-efficient optimizers; privacy-preserving local adaptation for assistants or perception models.
- Assumptions/dependencies: Activation memory and training compute must also be controlled; robust power/thermal constraints; task sensitivity to compression.
- Memory-aware AutoML and schedulers (platforms; cloud)
- AutoML systems that scale model size and batch dynamically under a memory budget using FlashOptim, picking companding strategies per layer/task.
- Potential products: “Memory budget as a hyperparameter” in AutoML; cluster schedulers that place jobs based on compressed footprints.
- Assumptions/dependencies: Reliable profiling APIs; guardrails for layers that opt out of compression.
- Sustainability and access policies (public policy; funding agencies; corporate ESG)
- Best-practice guidelines or incentives for memory-efficient training to reduce compute inequality and emissions in publicly funded research and industry.
- Potential actions: grant requirements for reporting memory-efficiency; ESG metrics for training pipelines; procurement preferences for efficient methods.
- Assumptions/dependencies: Measurement frameworks and standardized reporting; consensus on metrics and baselines.
- Domain-specific compressed training recipes (healthcare, finance, robotics, energy)
- Curated, validated recipes per domain that specify which layers to compress, companding settings, and monitoring to ensure compliance/accuracy.
- Potential products: certified training templates for regulated sectors; audit-ready logs tracking compression settings and outcomes.
- Assumptions/dependencies: Regulatory approval; robust validation on domain-specific distributions; fallback paths for sensitive layers.
- Communication-efficient distributed learning (HPC; federated/cloud-edge)
- Combine companded states with gradient/parameter communication compression for end-to-end bandwidth reduction in large-scale pretraining and federated setups.
- Potential tools: unified comms stack that compands optimizer states and quantizes gradients with error feedback.
- Assumptions/dependencies: Numerical stability of multi-stage compression; scheduling compatibilities with DDP/FSDP and async protocols.
Glossary
- absmax: The maximum absolute value within a group, used as a scale for quantization. "they are rescaled using the maximum absolute value (absmax), which is stored as an additional scale with 32 or 16 bits of precision."
- Activation checkpointing: A memory-saving technique that recomputes activations during backpropagation. "Activation checkpointing~\citep{chen2016training,korthikanti2023reducing} trades compute for memory by recomputing activations during the backward pass."
- Adam Accumulation: A method that fuses parameter updates into the backward pass to free gradient memory early. "LOMO~\citep{lv2024lomo}, AdaLOMO~\citep{lv2024adalomo}, and Adam Accumulation~\citep{zhang2023adam} fuse parameter updates into the backward pass to release gradient memory eagerly."
- AdamW: An Adam optimizer variant with decoupled weight decay. "Experiments with FlashOptim applied to SGD, AdamW, and Lion show no measurable quality degradation on any task from a collection of standard vision and language benchmarks, including Llama-3.1-8B finetuning."
- Adafactor: A memory-efficient optimizer that factorizes second-moment statistics. "Adafactor~\citep{shazeer2018adafactor} achieves sublinear memory by factorizing the second moment into row and column statistics;"
- Adapprox: A method that reduces memory by approximating optimizer statistics with low-rank structure. "Adapprox~\citep{zhao2024adapprox} uses a low-rank approximation."
- APOLLO: An approach that approximates adaptive scaling via random projections. "APOLLO~\citep{zhu2025apollo} approximates adaptive scaling with random projections."
- BFloat16 (BF16): A 16-bit floating-point format with a wide exponent, used for mixed precision. "BFloat16~\citep{google_cloud_bfloat16_2019} works equally well"
- Companding: A nonlinear preprocessing that reshapes value distributions to reduce quantization error. "we design companding functions that greatly reduce the error in 8-bit optimizer state quantization."
- Denormal floating-point range: The subnormal region of floating-point numbers near zero. "Denormal floating point ranges are indicated with vertical dotted lines."
- Error feedback: A technique that accumulates quantization or compression error back into updates for accuracy. "compressing gradients to 1-bit with error feedback~\citep{tang20211bit},"
- FSDP (Fully Sharded Data Parallel): A strategy that shards model states across data-parallel workers. "Our implementation is compatible with parameter sharding approaches such as PyTorch FSDP~\citep{zhao2023pytorchfsdp}."
- FP16: 16-bit floating point used for reduced-precision compute. "Mixed-precision training~\citep{micikevicius2018mixed} executes forward and backward passes in FP16 to reduce memory and compute,"
- FP32: 32-bit floating point used for higher-precision storage and updates. "while retaining FP32 precision for optimizer states and master weights to preserve numerical stability."
- FP8: 8-bit floating point formats used for low-precision training. "Recent work has pushed further with FP8 training~\citep{wang2018training,mellempudi2019mixed,micikevicius2022fp8,fishman2024scaling,narayan2025mu},"
- GaLore: A method that reduces memory by projecting gradients to a low-rank subspace. "GaLore~\citep{zhao2024galore} projects gradients to a low-rank subspace,"
- Gradient accumulation: Aggregating gradients over multiple minibatches before performing an optimizer step. "However, this conflicts with gradient accumulation, which requires the full accumulated gradient before updating."
- Gradient release: Eagerly applying updates during backpropagation to free gradient memory. "We implement gradient release~\citep{zhang2023adam}, interleaving gradient computation with optimizer updates during backpropagation."
- Group-wise quantization: Quantizing values per group with a shared scale to improve precision range. "a common approach is group-wise quantization: dividing tensors into fixed-length groups and mapping values to a lower-precision format like INT8~\citep{dettmers2022optimizers}."
- INT8/UINT8: 8-bit signed/unsigned integer formats used to store quantized tensors. "We store the normalized momentum in signed integers (INT8) and variance in unsigned integers (UINT8) since it is non-negative."
- Kahan summation: A compensated summation algorithm that reduces floating-point error. "stochastic rounding and Kahan summation."
- Lion: A memory-efficient optimizer that uses sign-based momentum updates. "Lion~\citep{chen2023lion} uses sign-based momentum,"
- LoRA: Low-Rank Adaptation that fine-tunes with small low-rank adapters while freezing base weights. "LoRA~\citep{hu2022lora} and QLoRA~\citep{dettmers2023qlora} freeze base weights and train only low-rank adapters."
- Master weights: High-precision copies of parameters used to accumulate accurate updates. "maintain FP32 precision master weights during training."
- Muon: An optimizer that applies orthogonalized parameter updates. "Muon~\citep{jordan2024muon,liu2025muon} applies orthogonalized updates."
- NanoGPT: A reference repository and recipe for training GPT-2 models. "We evaluate LLM pretraining using the training recipe outlined in the nanoGPT repository~\citep{karpathy2023nanogpt}."
- NovoGrad: An optimizer that replaces per-parameter variance with layer-wise normalization. "NovoGrad~\citep{ginsburg2019stochastic} replaces per-parameter variance with layer-wise normalization."
- PXR24: A 24-bit float storage format (OpenEXR) providing high dynamic range with reduced bits. "This is analogous to the PXR24 format used in high-dynamic-range imaging, which achieves similar precision by rounding 32-bit floats to 24 bits~\citep{kainz2004openexr}."
- QLoRA: Quantized LoRA that fine-tunes using low-rank adapters with quantized base weights. "LoRA~\citep{hu2022lora} and QLoRA~\citep{dettmers2023qlora} freeze base weights and train only low-rank adapters."
- Quantization bins: Discrete levels used to map continuous values during quantization. "spreading the momentum distribution more evenly across quantization bins."
- Sharding (tensor sharding): Splitting tensors across devices to distribute memory and computation. "Distributed training with tensor sharding~\citep{rajbhandari2020zero} divides the memory load across multiple accelerators."
- SM3: A memory-efficient optimizer that stores structured maxima for scaling updates. "SM3~\citep{anil2019memory} stores structured maxima;"
- Softsign: A smooth nonlinear function similar to softsign used to compress values before quantization. "then apply a softsign-like function:"
- Stochastic rounding: Probabilistic rounding that reduces bias by randomly choosing neighboring representable values. "pure BF16 master weights with stochastic rounding and Kahan summation."
- Triton kernel: A fused GPU kernel implemented in the Triton language for efficient training steps. "we implement the optimizer step as a single fused Triton kernel~\citep{tillet2019triton}."
- ULP (Unit in the Last Place): The spacing between adjacent representable floating-point numbers at a given magnitude. "u = \text{ULP}() is the unit in the last place~\citep{goldberg1991every}."
- Weight splitting: Storing a low-precision weight plus a small correction to reconstruct a higher-precision master weight. "weight splitting~\citep{zamirai2020revisiting,warner2024optimi} instead stores the downcast weights and narrow error-correction values."
- ZeRO: A system technique that partitions optimizer states, gradients, and parameters across ranks to reduce memory. "ZeRO~\citep{rajbhandari2020zero} partitions optimizer states, gradients, and parameters across data-parallel ranks,"
Collections
Sign up for free to add this paper to one or more collections.