- The paper introduces ECO, an optimizer that eliminates full-precision master weights by directly injecting quantization errors into the momentum.
- It integrates stochastic rounding to manage error feedback, achieving convergence close to FP32 baselines with a small constant-radius error bound.
- Empirical results demonstrate up to 25% memory reduction in diverse LLM models, with ECO maintaining training stability and baseline accuracy.
ECO: Error-Compensating Optimizer for Quantized Training without Full-Precision Master Weights
Motivation and Problem Statement
As LLM training scales, the static memory footprint—dominated by model parameters and associated optimizer states—emerges as a primary system bottleneck. While quantized and quantization-aware training methods (QAT) offer substantial reductions in memory and compute requirements by performing arithmetic in reduced formats (e.g., FP8, INT4), nearly all pipelines retain a full-precision (typically FP32) master weight copy for update accumulation. These master weights preclude achieving Pareto-optimal memory efficiency: for instance, in Sparse MoE models, all master weights must be resident, even though only a fraction of the parameters are active per sample.
The core technical obstacle stems from the vanishing of small updates when applied directly to quantized weights due to the discretization gap; memory savings from aggressive quantization are hence negated by mandatory FP32 accumulation. Previous attempts to eliminate the master weight buffer have resulted in either unscalable instability or limited applicability, especially at the LLM regime. The necessity for master weights in quantized training therefore remains a fundamental open problem impeding memory and bandwidth efficiency.
The Error-Compensating Optimizer (ECO)
ECO introduces a principled algorithm that eliminates the need for full-precision master weights by directly applying updates to quantized weights. It injects quantization errors into the optimizer’s momentum, forming a memory-neutral error feedback loop. At each optimization step, after calculating the updated parameters and quantizing them, ECO computes the residual error and augments the optimizer’s momentum accordingly. This approach precludes storing an extra error buffer (essential for memory gains) and supports both classic momentum SGD and Adam-style adaptive optimizers with straightforward modifications.
Mathematically, for SGD with momentum, the quantized iterate update incorporates the quantization error et+1 via
mt+1←mt+1+η1(1−β1)et+1
where η is the learning rate and β the momentum parameter. For Adam, the element-wise learning rate replaces η in the corresponding injection rule.
The algorithm also leverages the empirical observation (validated experimentally) that successive quantization errors are highly similar, enabling efficient error management without a persistent error buffer.
Theoretical Analysis and Convergence Properties
The convergence properties of ECO are analyzed in non-convex settings under L-smoothness, bounded gradients, and zero-mean, bounded-variance quantization error (for stochastic rounding). The analysis constructs a virtual sequence and demonstrates that ECO traces an SGD-like trajectory on this auxiliary variable. A key result is that ECO achieves convergence to a constant-radius neighborhood of the optimum, where the radius scales modestly with respect to the quantization noise floor. Specifically, with decaying learning rates, ECO’s stationary error is only a factor 1/(1−β2) larger than the lower bound set by the quantization grid, closely matching the FP32 master weight process. In contrast, naive master-weight removal (direct update application without error compensation) leads to stationary errors that diverge as the learning rate vanishes (∼1/η blow-up), precluding high-precision convergence.
For deterministic round-to-nearest quantization (non-uniform error, nonzero mean), a similar but looser bound is established, confirming that stochastic rounding is preferable when hardware support is available.
Empirical Results
ECO’s practical impact is evidenced across pre-training and fine-tuning experiments on dense Transformers (30M to 800M), a Gemma-3 1B model, a 2.1B parameter SMoE, and DeepSeek-MoE-16B. When coupled with stochastic rounding, ECO nearly matches the validation loss of master-weighted baselines (e.g., <0.01 absolute loss increments across all sizes), achieving up to 25% static memory reduction. Naive master-weight removal consistently diverges or yields much higher loss, evidenced particularly in the SMoE and DeepSeek settings where the optimizer state and master weight buffers are the dominant contributors to overall memory usage.
A highlight is the fine-tuning of DeepSeek-MoE-16B in INT4, where ECO enables training to baseline accuracy and loss, while naive approaches diverge. Extensive evaluation on standard zero-shot benchmarks (ARC, GSM8K, HellaSwag, PIQA, MMLU, etc.) confirms negligible accuracy degradation for ECO relative to full-precision baselines. The shifting Pareto front with respect to memory vs. validation loss is clearly visualized for Gemma-3 1B and SMoE-2.1B.
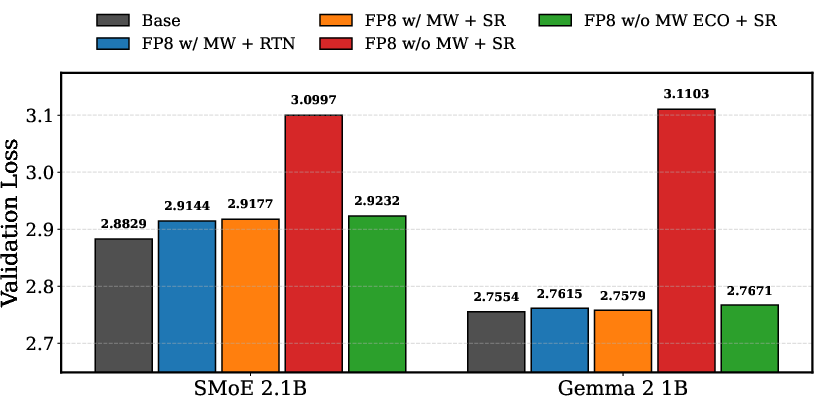
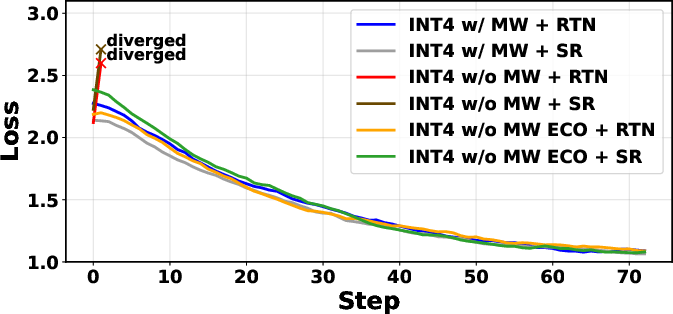
Figure 1: (Left) Validation loss for Gemma 3 1B and SMoE 2.1B across methods; (Right) Smoothed training loss for DeepSeek-MoE-16B fine-tuning demonstrates ECO’s stability and accuracy parity relative to FP32-based training.
ECO’s error-injection mechanism incurs negligible runtime overhead as it is implemented via element-wise operations. Analysis of consecutive quantization errors confirms their high similarity; mean cosine similarity is close to one, providing the empirical foundation for the ECO error management heuristic.
Practical and Theoretical Implications
Practical Implications: ECO makes feasible full LLM training and MoE fine-tuning with no FP32 master weight buffer, unlocking large-scale deployment on hardware with limited memory, including edge devices. Its design requires no additional persistent buffer and no hyperparameter tuning, making integration with existing QAT frameworks straightforward.
Theoretical Implications: The algorithm extends error feedback concepts from distributed optimization and communication minimization to single-GPU, on-device, and LLM scenarios with nontrivial update dynamics. It tightens the lower bound on stable quantized training, quantifying the tradeoffs in noise propagation across optimizers, error characteristics, and learning schedules.
Limitations and Future Trajectories: Although flexible, the most precise accuracy recovery is achieved under stochastic rounding, which is becoming more widely available in hardware but is not universally supported. When only deterministic rounding is used, ECO still outperforms naive approaches but cannot fully match RTN-based master-weight baselines. Future developments may explore adaptive injection rules for more aggressive quantization (e.g., INT2) or hybrid schemes combining low-precision optimizer states [see also (Dettmers et al., 2021, Castro et al., 20 May 2025)]. There is potential for extending ECO to emerging quantization granularities and custom accelerator topologies.
Conclusion
ECO constitutes the first universal methodology for scalable, memory-optimal quantized training by eliminating master weights through a theoretically justified error feedback loop in the momentum buffer. It enables memory reductions (up to 25% in SMoE models) without accuracy compromise when using stochastic rounding, unlike naive approaches which are provably and empirically unstable in this context. Its adoption can facilitate further scaling and democratization of LLM deployment under stringent hardware constraints and is anticipated to synergize with forthcoming advances in optimizer state quantization and ultra-low-bit arithmetic.
(2601.22101)