Understanding Usage and Engagement in AI-Powered Scientific Research Tools: The Asta Interaction Dataset
Abstract: AI-powered scientific research tools are rapidly being integrated into research workflows, yet the field lacks a clear lens into how researchers use these systems in real-world settings. We present and analyze the Asta Interaction Dataset, a large-scale resource comprising over 200,000 user queries and interaction logs from two deployed tools (a literature discovery interface and a scientific question-answering interface) within an LLM-powered retrieval-augmented generation platform. Using this dataset, we characterize query patterns, engagement behaviors, and how usage evolves with experience. We find that users submit longer and more complex queries than in traditional search, and treat the system as a collaborative research partner, delegating tasks such as drafting content and identifying research gaps. Users treat generated responses as persistent artifacts, revisiting and navigating among outputs and cited evidence in non-linear ways. With experience, users issue more targeted queries and engage more deeply with supporting citations, although keyword-style queries persist even among experienced users. We release the anonymized dataset and analysis with a new query intent taxonomy to inform future designs of real-world AI research assistants and to support realistic evaluation.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview of the paper
This paper looks at how people use AI tools to do scientific research. The authors studied a real system called Asta, which helps researchers find papers and get answers to scientific questions. They collected and analyzed a large, anonymized dataset of how people typed queries, clicked on results, and explored the information the AI produced. Their goal was to understand what people ask these tools to do, how they interact with the results, and how their behavior changes as they get more experienced.
Key questions the researchers asked
The paper focuses on two main questions:
- How do researchers ask for information when using AI systems that both search for papers and write summaries, and how is this different from using a traditional search engine?
- After the AI creates a response, how do users read, check, and navigate through it (especially the citations), and what does this tell us about how the tool should be designed?
How they did the study (methods)
The authors analyzed the Asta Interaction Dataset, which contains:
- Over 200,000 user queries and more than 400,000 recorded actions (like clicks) from February to August 2025.
- Data from two tools inside Asta:
- PaperFinder (PF): shows a ranked list of relevant research papers with short summaries.
- ScholarQA (SQA): writes a structured, multi-section report answering a scientific question, with inline citations.
Here’s how they approached the analysis:
- They kept the data private and safe by removing personally identifiable information.
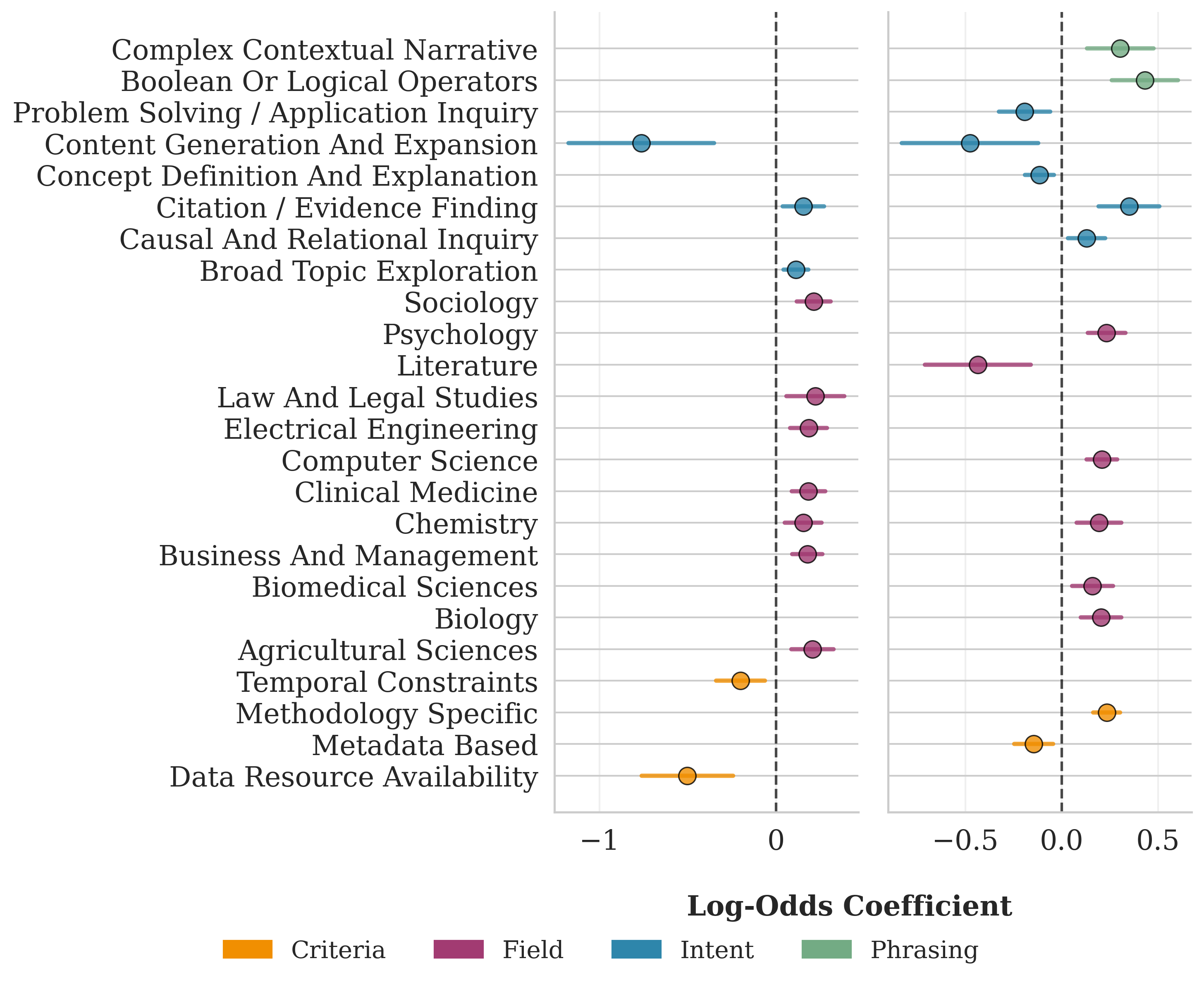
- They used an AI model (GPT-4.1) to label a subset of 30,000 queries with a “taxonomy”—simple categories describing:
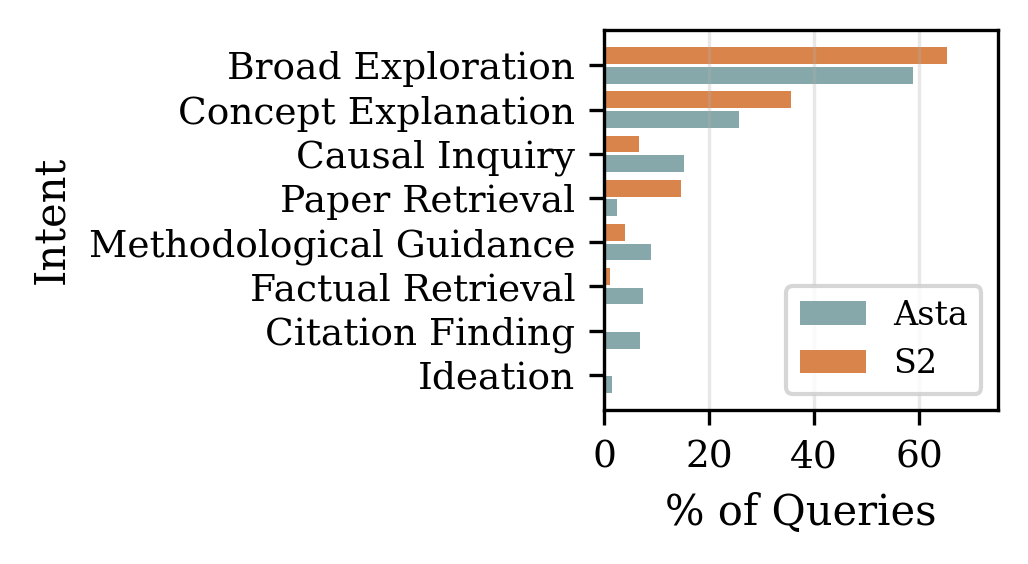
- Intent (what the user wanted, such as “find a paper” or “explain a concept”)
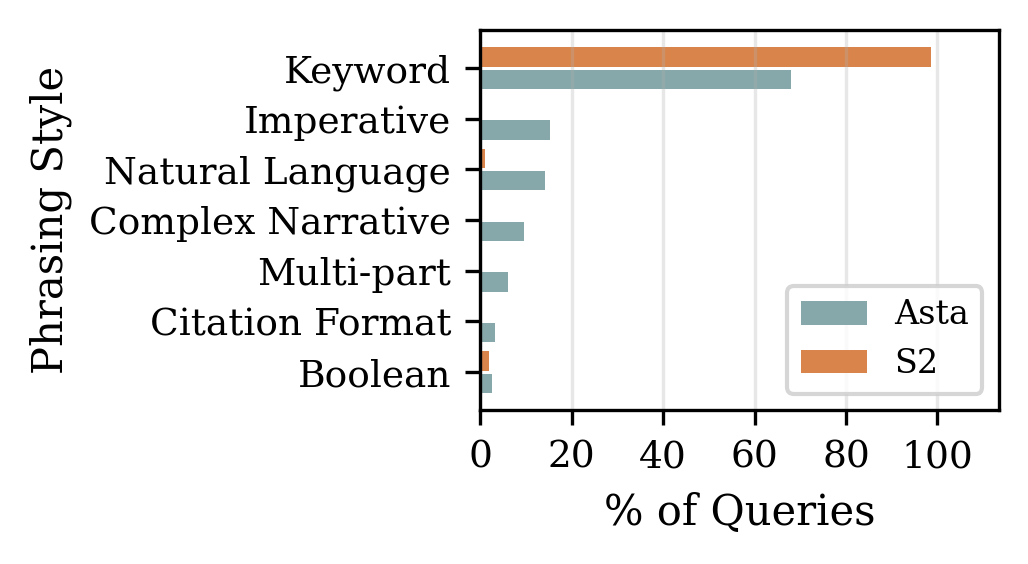
- Phrasing style (how the query was written, such as keywords or full sentences)
- Criteria (extra filters, like “papers only” or “specific methods”)
- They studied user actions such as clicking paper links, opening evidence citations, expanding sections, and giving thumbs-up/thumbs-down feedback.
- To measure success, they mainly used “click-through rate” (CTR): whether the user clicked at least one paper link. Clicking links tends to mean users found something useful.
- They tracked how the same users changed over time, grouping their activity into three stages: first query, early use (queries 2–10), and experienced use (after 10 queries).
- They ran statistical tests to confirm patterns were real and not due to chance.
In everyday terms: they watched how people “talked to” the AI, what buttons they pressed, and whether they kept using the tool. They taught another AI to categorize the questions. Then they used math to check which behaviors were common and how they evolved.
What they found and why it matters
The results show that people use AI research tools differently than simple search engines:
- People ask longer, more complex questions. Instead of short keyword searches like “diabetes GLP-1,” users often write full sentences or even paste parts of their drafts as context, then ask the AI to help.
- Users treat the AI like a research partner. Many queries go beyond finding papers. People ask for help designing experiments, comparing methods, identifying research gaps, interpreting results, and even drafting parts of a manuscript.
- Queries often include specific constraints. Users frequently request things like certain study methods, publication quality, time ranges (e.g., 2020–2025), or papers with available data/code.
- Behavior changes with experience:
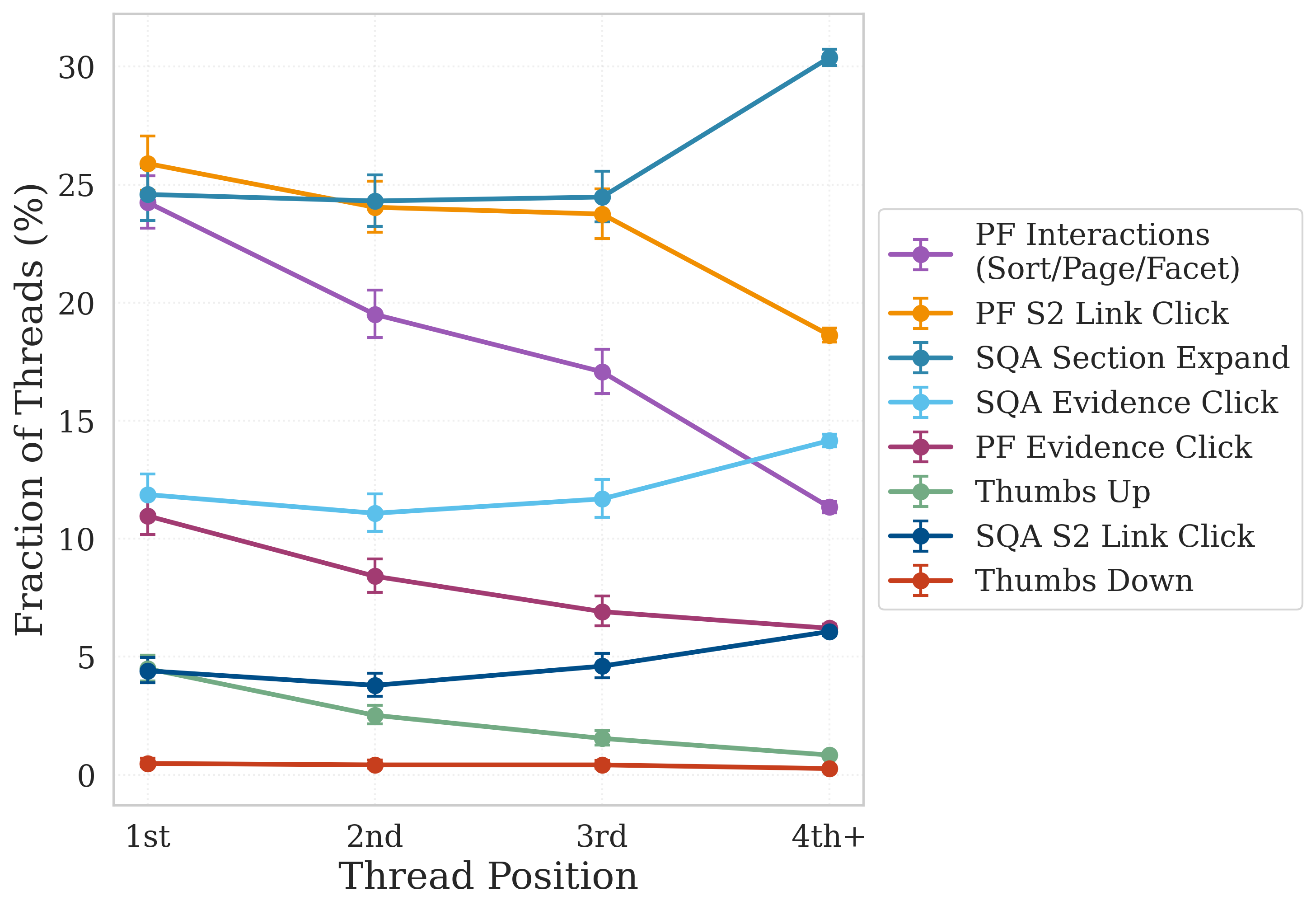
- Over time, users ask more targeted questions and engage more with citations (for SQA, evidence clicks grow noticeably after the first few queries).
- Experienced PF users rely more on the summaries in the result list and click fewer paper links, suggesting the summaries become enough for quick decisions.
- Users revisit the AI’s outputs. Many people return to previously generated reports hours later, treating them like persistent reference materials rather than one-off search results.
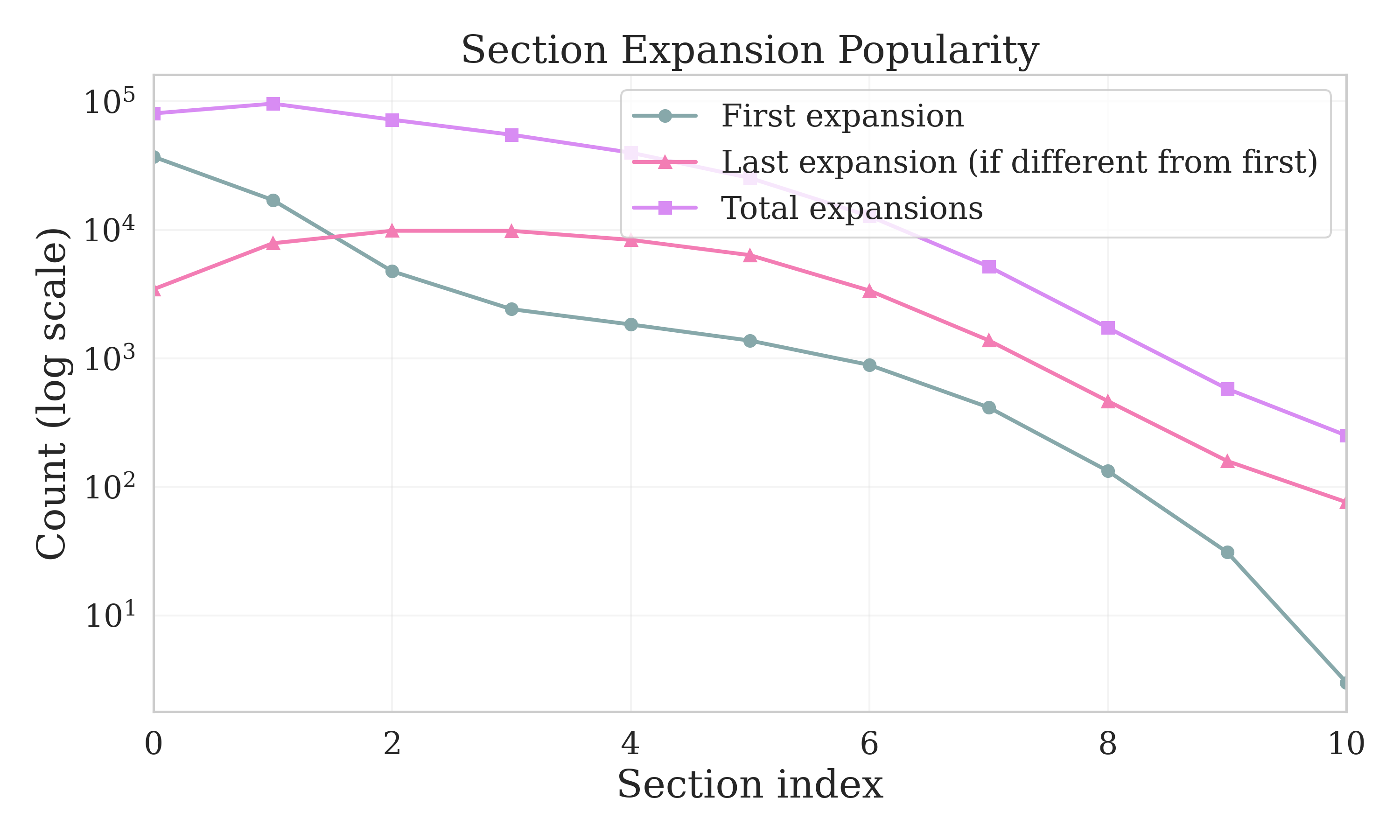
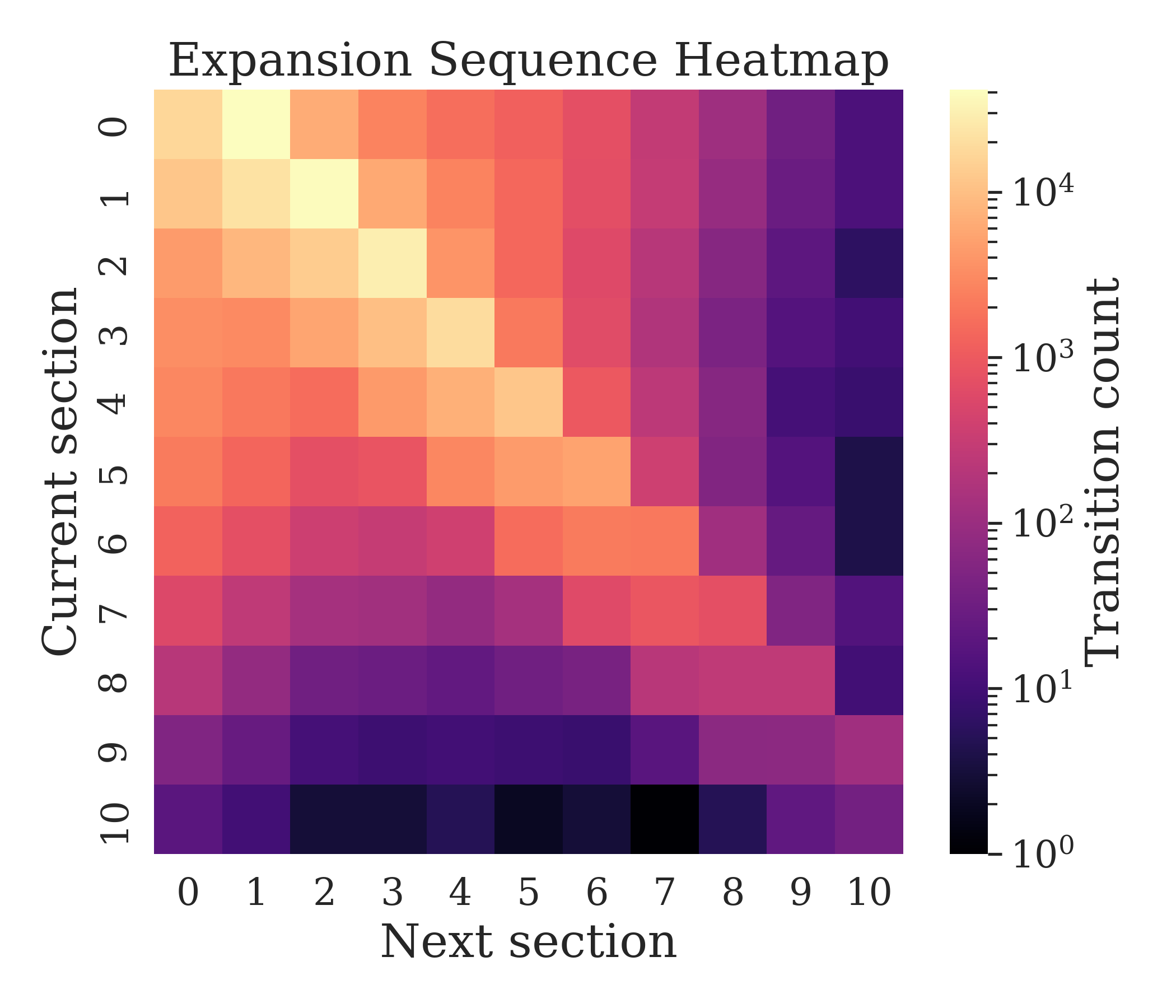
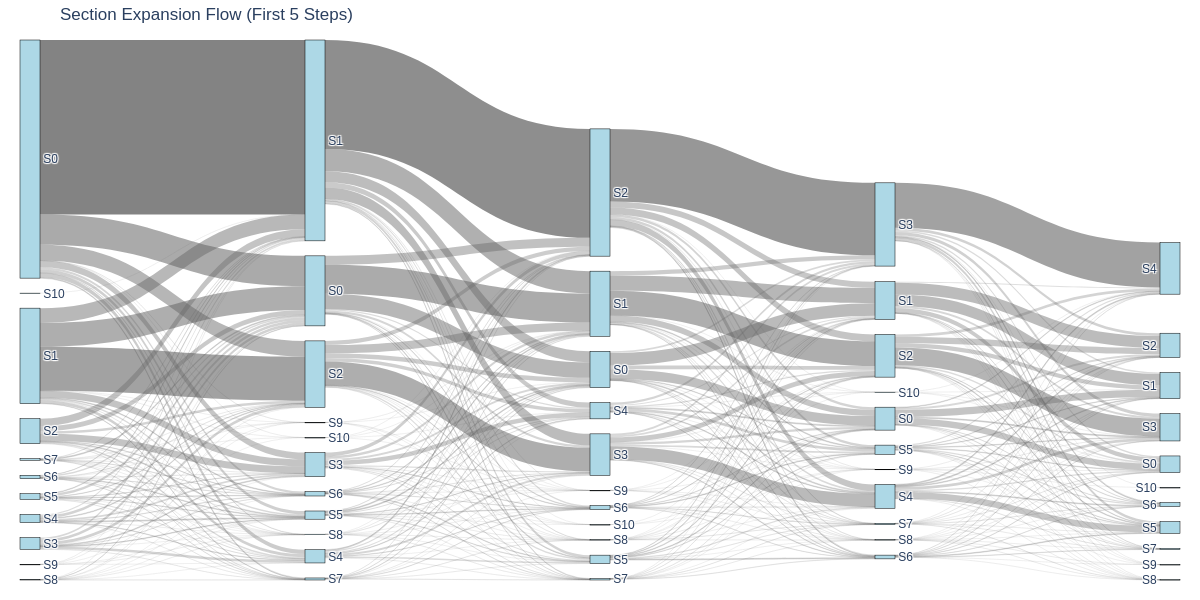
- Reading is non-linear. In SQA’s multi-section reports, users often skip the introduction, jump between sections, and open citations to verify claims. This suggests section-based layouts and TL;DR summaries are helpful.
- People tolerate some waiting—but not errors. Users accept longer generation times for full reports (SQA), but they expect PF (paper list) to be faster. Serious errors sharply reduce the chance that new users will come back.
Why it matters: These patterns suggest AI research assistants are becoming part of the research workflow, not just fancy search engines. Understanding how people use them can help designers build tools that better match what researchers actually do.
What this means and why it could be important
The authors suggest several practical implications:
- Help users sharpen their queries. Because people often realize they need extra details only after seeing results, tools could ask clarifying questions up front or support easy, conversational refinement.
- Make navigation easy. Since readers jump around and check citations, interfaces should offer clear section summaries, quick access to evidence, and flexible ways to read.
- Handle errors gracefully, especially for first-time users. Clear explanations and recovery options are crucial because early bad experiences can drive users away.
- Support “agent-like” tasks. Many users expect the AI to help with ideation, drafting, and complex constraints. Tools should recognize these needs and guide users on what’s possible and reliable.
Finally, the dataset they released can help other researchers evaluate AI research assistants in realistic ways. This could lead to better tools that truly assist scientists across their entire workflow—from finding papers, to understanding them, to creating new research.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored, framed as concrete opportunities for future research and evaluation.
- Multi-turn behavior gap: The study largely omits follow-up queries (PF analysis restricted to first turn; SQA and S2 single-turn), leaving open how users iteratively refine prompts, correct errors, and converge on goals across turns and sessions.
- Cross-tool workflow gap: Transitions between PF and SQA (what triggers switching, how artifacts move across tools, and role specialization) are not characterized.
- Success metrics mismatch: CTR to S2 pages is an imperfect proxy for success—especially as experienced PF users consume more in-situ summaries—warranting richer, triangulated measures (e.g., dwell time on sections/evidence, saving/exporting, bookmarking, task completion, downstream paper reads).
- Downstream impact unknown: Effects on real research outcomes (paper selection quality, literature review accuracy/coverage, experimental design improvements, later citations or manuscript quality) are not measured.
- Reliability/factuality unquantified: Hallucination rates, misgrounded citations, and evidence sufficiency are not systematically audited; impacts on trust, user verification behavior, and retention are unmeasured beyond coarse CTR correlations.
- LLM labeling validity: The taxonomy labels (intent, phrasing, criteria, abstractiveness) rely on GPT-4.1 without reported human agreement studies; inter-annotator reliability, error analysis, and sensitivity to model choice are missing.
- Taxonomy generalizability: Stability and transfer of the proposed taxonomy across other AI research tools, corpora, and domains is untested; no cross-system replication or domain adaptation analysis.
- Sampling/selection bias: Dataset is opt-in and time-bounded (Feb–Aug 2025); user composition (discipline, region, institution, career stage) and representativeness are not reported, limiting generalizability.
- Privacy-driven reproducibility gap: Released data excludes user identifiers, preventing reproduction of cohort and retention analyses; need privacy-preserving linkage (e.g., differential privacy or secure multi-party linkage) to enable longitudinal studies.
- Experience thresholds sensitivity: Cutoffs for “single-query,” “inexperienced,” and “experienced” stages (1, 2–10, >10) are arbitrary; no sensitivity analysis to alternative thresholds or continuous experience measures.
- Session boundary assumptions: A 45-minute inactivity timeout defines sessions; robustness to other timeouts or activity heuristics is not tested.
- Baseline comparability: S2 comparisons lack user matching and may confound by population differences and temporal drift; within-subject or propensity-matched comparisons are needed.
- Interface causality: Observed SQA navigation (skipping introductions, non-linear reading) is descriptive; no controlled experiments (A/B tests) isolate the causal effects of section layout, TL;DR placement, or citation affordances.
- Latency effects causality: Latency tolerance findings are observational; causal identification (e.g., randomized latency injections or natural experiments) is needed to estimate true retention impacts.
- Error taxonomy missing: “Catastrophic errors” are not categorized (e.g., timeouts, retrieval failures, formatting errors, hallucinations); recovery pathways and their efficacy are not evaluated.
- Underserved query types: Lower CTR for content generation, data/resource requests, temporal constraints, and citation formatting is identified, but no design interventions (e.g., specialized tools, templates, constraint-aware retrieval) are trialed.
- RAG configuration unknowns: Effects of retrieval depth, re-ranking strategies, grounding methods, and citation selection policies on engagement, verification behavior, and trust are not analyzed.
- Model/version drift: The impact of model or corpus updates over the collection period on behaviors and outcomes is not isolated; time-series segmented by version is needed.
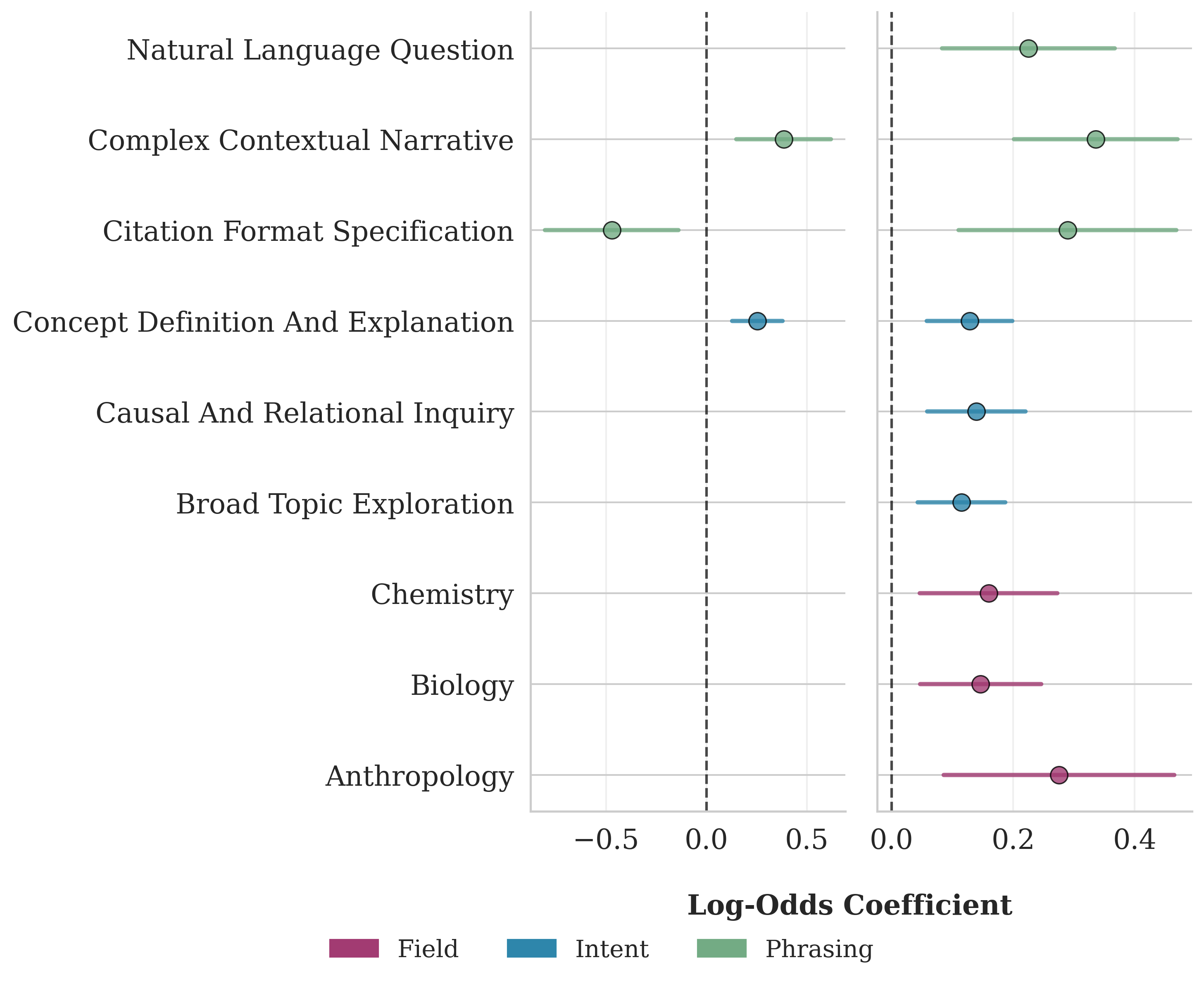
- Field-specific heterogeneity: While some field variation is noted, a systematic per-discipline analysis (intent mix, phrasing, criteria, success) and implications for tailored interfaces remains open.
- User expertise heterogeneity: Researcher expertise, prior LLM experience, and mental models are not measured; behavior differences by persona or proficiency remain unexplored.
- Multilingual usage: Language distribution, non-English performance, and localization needs are not analyzed; near-duplicate refinements mention language preferences but outcomes are unreported.
- Abstractiveness metric validation: The “abstractiveness” classifier is LLM-based; construct validity, agreement with lexicon-based or human-coded measures, and cross-domain stability are untested.
- Bot/PII filtering robustness: Criteria, error rates, and residual contamination for bot removal and LLM-based PII detection are not quantified; potential bias from false positives/negatives is unknown.
- Metrics for in-situ success: For PF, reduced link CTR among experienced users may reflect better on-page synthesis; combined metrics (evidence clicks, time-on-report, save/export actions) are needed to avoid misclassification of success.
- Revisitation motivations: Report revisitation is common, but the reasons (e.g., trust-building, re-finding, ongoing tasks, collaboration) are not elicited; mixed-methods (surveys/interviews) could inform artifact and update design.
- Evidence-use quality: Whether clicked citations actually support claims, and how evidence card design affects verification and learning, is not evaluated.
- Ethical considerations: Potential for overreliance, ghostwriting, or superficial reviews is not discussed; guidelines and guardrails for responsible use are absent.
- Dataset content scope: It is unclear whether generated reports and evidence snippets are released; lack of outputs limits third-party quality audits—safe-release strategies (redaction, sampling, DP) are needed.
- Reproducible modeling: CTR logistic models depend on unreleased user covariates; providing aggregate or synthetic user histories, or reproducible pipelines with privacy-preserving summaries, would enable verification.
- Prompting support efficacy: The paper motivates intent clarification and pre-execution disambiguation but does not test prompt-suggestion widgets, schema-based intent capture, or interactive constraint builders.
- Transition triggers: Which query or interaction features predict a user’s move from broad exploration to targeted tasks over time (and how interfaces can accelerate this shift) remains untested.
Practical Applications
Overview
Based on the paper’s findings, methods, and innovations—especially the released Asta Interaction Dataset (AID), the multidimensional query taxonomy, and behavior analyses—there are several practical applications for industry, academia, policy, and daily life. Below, applications are grouped into Immediate and Long-Term, with sector links, potential tools/workflows, and feasibility assumptions noted.
Immediate Applications
- Intent-aware onboarding and query formulation assistants (software; education; academia)
- Deploy prompt wizards that clarify user intent and criteria before running long jobs, reducing near-duplicate queries and unnecessary latency (e.g., “Add temporal range,” “Specify methodology,” “Preferred citation format”).
- Provide templates for common intents (Broad Topic Exploration, Methodology Guidance, Citation/Evidence Finding, Comparative Analysis).
- Dependencies/assumptions: Reliable LLM parsing of user intent; UI integration; access to retrieval corpora; guardrails for citation integrity.
- Interface design playbook for RAG research tools (software; healthcare; pharma; legal; engineering)
- Adopt proven UI elements: collapsible sections with TL;DRs, inline evidence cards, section-level navigation, non-linear reading support, and persistent report artifacts.
- Tailor latency budgets by task type (short for search-like PF tasks; longer acceptable for synthesis-oriented SQA tasks).
- Dependencies/assumptions: Product engineering capacity; evidence-grounding pipelines; analytics to monitor latency vs. churn.
- Operational analytics and evaluation suite (software; academia; industry)
- Implement CTR-based success monitoring, logistic regression to identify underserved query types, and A/B tests that differentiate SQA vs. PF latency tolerances.
- Use AID-derived taxonomies to segment usage by intent/phrasing/criteria and prioritize feature development.
- Dependencies/assumptions: Availability of clickstream data; privacy-compliant logging; acceptance of CTR as a surrogate metric.
- Realistic benchmark construction for LLM+RAG systems (academia; software)
- Build evaluation sets from AID’s real-world query distributions and intents; create leaderboards and offline tests that reflect actual researcher needs (e.g., Methodology-Specific Criteria, Complex Contextual Narrative).
- Dependencies/assumptions: Dataset licensing/usage terms; standardized evaluation protocols; community buy-in.
- Privacy-preserving telemetry practices (policy; compliance; software)
- Adopt opt-in logging, PII filtering, hashed identifiers, and session debouncing from the paper’s pipeline as a blueprint for compliant analytics.
- Dependencies/assumptions: Legal review; institutional data governance; transparent user consent flows.
- Researcher training and “AI research literacy” materials (education; academia; daily life)
- Teach effective prompting strategies and evidence-verification workflows (e.g., when to use explicit constraints, how to leverage TL;DR + citations; avoiding functional fixedness).
- Integrate into graduate seminars and lab onboarding as practical modules.
- Dependencies/assumptions: Instructor capacity; curriculum alignment; access to tools.
- Domain-specific rapid evidence screening (healthcare; pharma; public health; engineering)
- Use PF-like interfaces with Methodology-Specific filters (e.g., RCT-only, meta-analyses) for quick triage in systematic reviews, technology scouting, or guideline updates; rely on evidence cards to verify claims.
- Dependencies/assumptions: Comprehensive domain corpora; accurate methodology tagging; trusted citation links.
- Productivity integrations for research workflows (software; academia; daily life)
- Plugins for Zotero/Mendeley/EndNote, Jupyter/VS Code/Obsidian/Word to import SQA sections, TL;DRs, and citations as living artifacts; enable revisitation and versioning.
- Dependencies/assumptions: Stable APIs; document model compatibility; update mechanisms.
Long-Term Applications
- Agentic, personalized research assistants (software; academia; industry)
- Multi-turn agents that adapt to the user’s experience stage and preferences (e.g., more targeted queries over time), remember context, and auto-refresh “living literature reviews” as new papers are published.
- Dependencies/assumptions: Advances in LLM reliability, memory, and personalization; robust RAG pipelines; privacy-preserving user modeling.
- Automated research gap mining and funding alignment (academia; policy; publishers)
- Systems that detect gaps via intent signals (e.g., Research Gap Analysis) across corpora, propose study designs, and surface opportunities for funders and editorial boards.
- Dependencies/assumptions: High-quality coverage of scholarly corpora; novelty detection; partnerships with funders/publishers.
- Sector-specific evidence assistants
- Healthcare: Clinical guideline updaters that structure evidence into sections with traceable citations; safety checks for overreliance and hallucination mitigation.
- Law: Brief drafting assistants that prioritize authoritative sources and format citations per jurisdiction.
- Engineering/Energy: Design assistants that filter by methodology constraints and safety standards; technology scouting for emerging methods.
- Finance: Due diligence research assistants that synthesize filings/news with verifiable evidence trails.
- Dependencies/assumptions: Domain corpora access; strict compliance standards; auditability; industry-specific UI/UX needs.
- Standards and regulatory frameworks for evidence-grounded AI (policy; standards bodies; industry)
- Define requirements for traceable citations, error handling, latency expectations, and audit logs; certification schemes for AI research tools used in high-stakes domains.
- Dependencies/assumptions: Multi-stakeholder consensus; alignment with privacy and IP law; enforcement mechanisms.
- Cross-system benchmarking consortium and shared taxonomies (academia; industry)
- Establish open evaluation protocols and shared taxonomies for research assistants across platforms; enable generalizability studies and meta-analyses.
- Dependencies/assumptions: Data-sharing agreements; privacy guarantees; standardized label definitions and scoring.
- Reliability, trust, and guardrails at scale (software; policy)
- Build citation-verification engines, structured output validators, and graceful degradation pathways to mitigate catastrophic errors (especially for first-time users).
- Dependencies/assumptions: Continued improvements in RAG; robust uncertainty handling; institutional risk frameworks.
- Educational platforms integrating non-linear evidence consumption (education)
- LMS-integrated assistants that teach section-level reading, TL;DR usage, and evidence verification; assignments that require citation inspection and revisitation.
- Dependencies/assumptions: School adoption; content moderation; accessibility requirements.
- Enterprise knowledge search with Asta-inspired UI/analytics (industry; software)
- Apply the taxonomy and interface patterns to internal document search (policies, specs, wikis), with CTR-based evaluation and latency tuning per task type.
- Dependencies/assumptions: Secure access to proprietary corpora; governance; change management.
Feasibility Notes and Assumptions
- Generalizability: Findings are derived from Asta’s PF/SQA tools and may not fully generalize to systems with different scopes, modalities, or optimization goals.
- Metrics: CTR is used as a success proxy; while validated against return rates, it is not a direct measure of satisfaction or correctness.
- Data/labels: LLM-based labeling introduces noise; taxonomy application at scale depends on consistent definitions and QA.
- Corpora/IP: Many applications depend on broad, licensed access to high-quality scholarly corpora and reliable citation metadata.
- Reliability and safety: Overreliance risks, hallucinations, and catastrophic errors require guardrails, auditing, and domain-specific compliance.
- Privacy: Opt-in logging, PII removal, and hashed identifiers must be maintained for analytics-driven products and shared benchmarks.
Glossary
- Agentic system: An AI that can plan and execute multi-step tasks or take initiative toward a user’s goal. Example: "function as a general-purpose agentic system."
- Benjamini-Hochberg procedure: A multiple-comparisons correction that controls the expected proportion of false discoveries. Example: "controlling for false discovery with the Benjamini-Hochberg procedure over all estimated -values."
- Binomial logistic regression: A statistical model for predicting a binary outcome using the log-odds of the probability. Example: "We also fit binomial logistic regression models predicting click-through"
- Bootstrap (resampling): A method for estimating uncertainty (e.g., confidence intervals) by resampling data with replacement. Example: "bootstrap for unbounded values"
- Churn rate: The fraction of users who stop using a product after an interaction or period. Example: "churn rate, the fraction of users with no subsequent query"
- Clickstream: The sequence of recorded user interaction events within an interface or website. Example: "clickstream logs"
- Click-through rate (CTR): The proportion of results or reports that receive at least one link click. Example: "click-through rate (CTR)"
- Debouncing: A processing step that collapses rapid, repeated events into a single event to avoid overcounting. Example: "Action debouncing is performed for page revisits"
- Empirical Bayes smoothing: Shrinking noisy individual estimates toward a global prior to reduce variance. Example: "an empirical Bayes-smoothed estimate of the user's historical click rate"
- False discovery: Erroneous rejections among multiple hypothesis tests; controlled by procedures like BH. Example: "controlling for false discovery with the Benjamini-Hochberg procedure"
- Functional fixedness: A cognitive bias where users stick to familiar patterns and fail to exploit new capabilities. Example: "suggesting functional fixedness."
- Heavy-tailed behavior: A distribution with a tail that decays more slowly than an exponential (often implying rare but large values). Example: "showing heavy-tailed behavior."
- Logit link: The link function in logistic regression mapping probabilities to log-odds. Example: "using maximum likelihood estimation with a logit link"
- Maximum likelihood estimation: A method for estimating model parameters by maximizing the likelihood of observed data. Example: "using maximum likelihood estimation with a logit link"
- Near-duplicate queries: Repeated queries differing only slightly (e.g., minor edits or added constraints). Example: "Near-duplicate queries occur on shorter timescales"
- Odds ratio (OR): A measure of association in logistic models comparing the odds of an outcome across conditions. Example: "(OR\,=\,1.47)"
- Pearson correlation coefficient: A measure of linear association between two variables. Example: "Pearson "
- Position bias: Users’ tendency to prefer or interact more with items shown earlier in a ranked list. Example: "position bias towards the first sections"
- Pseudonymous identifiers: Stable identifiers not directly revealing the user’s identity. Example: "pseudonymous user identifiers"
- Re-identification risk: The possibility that anonymized data could be linked back to individuals. Example: "re-identification risk"
- Retrieval-augmented generation: LLM text generation grounded in retrieved documents or evidence. Example: "retrieval-augmented generation platform."
- Sankey diagram: A flow diagram visualizing transitions or flows between states with proportional link widths. Example: "the Sankey diagram"
- Structured decoding: Constraining model outputs to follow a specified schema or format during generation. Example: "using GPT-4.1 with structured decoding."
- TL;DR: A concise summary intended to convey the main point at a glance. Example: "a one-sentence TL;DR (visible when collapsed)"
- Two-sided t-test: A statistical test checking for differences in means in either direction. Example: "two-sided t-tests ()."
- Wilson CIs: Wilson confidence intervals; a method for interval estimation of binomial proportions with good small-sample properties. Example: "Wilson CIs for rates"
Collections
Sign up for free to add this paper to one or more collections.

