Vectorizing the Trie: Efficient Constrained Decoding for LLM-based Generative Retrieval on Accelerators
Abstract: Generative retrieval has emerged as a powerful paradigm for LLM-based recommendation. However, industrial recommender systems often benefit from restricting the output space to a constrained subset of items based on business logic (e.g. enforcing content freshness or product category), which standard autoregressive decoding cannot natively support. Moreover, existing constrained decoding methods that make use of prefix trees (Tries) incur severe latency penalties on hardware accelerators (TPUs/GPUs). In this work, we introduce STATIC (Sparse Transition Matrix-Accelerated Trie Index for Constrained Decoding), an efficient and scalable constrained decoding technique designed specifically for high-throughput LLM-based generative retrieval on TPUs/GPUs. By flattening the prefix tree into a static Compressed Sparse Row (CSR) matrix, we transform irregular tree traversals into fully vectorized sparse matrix operations, unlocking massive efficiency gains on hardware accelerators. We deploy STATIC on a large-scale industrial video recommendation platform serving billions of users. STATIC produces significant product metric impact with minimal latency overhead (0.033 ms per step and 0.25% of inference time), achieving a 948x speedup over a CPU trie implementation and a 47-1033x speedup over a hardware-accelerated binary-search baseline. Furthermore, the runtime overhead of STATIC remains extremely low across a wide range of practical configurations. To the best of our knowledge, STATIC enables the first production-scale deployment of strictly constrained generative retrieval. In addition, evaluation on academic benchmarks demonstrates that STATIC can considerably improve cold-start performance for generative retrieval. Our code is available at https://github.com/youtube/static-constraint-decoding.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is about making recommendation systems powered by LLMs faster and more reliable when they must follow strict rules. Think of a video app that only wants to recommend “fresh” videos uploaded in the last week. The model must generate item IDs that follow these rules while it’s generating them, not after. The authors introduce a new method, called STATIC, that lets LLMs follow such rules very quickly on hardware like GPUs and TPUs, so it works at huge scale (like YouTube).
Key questions the paper asks
- How can we make an LLM generate only allowed items (for example, only fresh, in-stock, or region-approved items) without slowing it down?
- Can this be done efficiently on GPUs/TPUs, which like to run big, regular batches of math?
- Will this work at massive industrial scale and improve real user metrics?
- Can it also help with “cold-start” items (brand-new items the model hasn’t seen before)?
Methods: How it works, in simple terms
First, some key ideas:
- Items are represented as short codes called Semantic IDs (SIDs). Imagine each item having a code like a license plate made of several tokens (for example, 8 positions, each can be one of 2048 values). The LLM generates this code one token at a time.
- Beam search is like exploring several best guesses at once. At each step, the model expands multiple promising partial codes and keeps the top-scoring ones.
- Constraints are business rules. Examples include:
- Freshness: “only items from the last 7 days”
- Category: “summer clothing only”
- Region: “only items allowed in your country”
- Availability: “in stock only”
The usual way to enforce constraints is with a trie (pronounced “try”):
- A trie is like a tree of allowed codes. Each level is the next token in the code. If a path doesn’t exist in the tree, that partial code is invalid.
- Problem: Traditional tries jump around in memory in unpredictable ways (“pointer chasing”), which GPUs/TPUs are bad at. That makes them slow for large-scale, real-time systems.
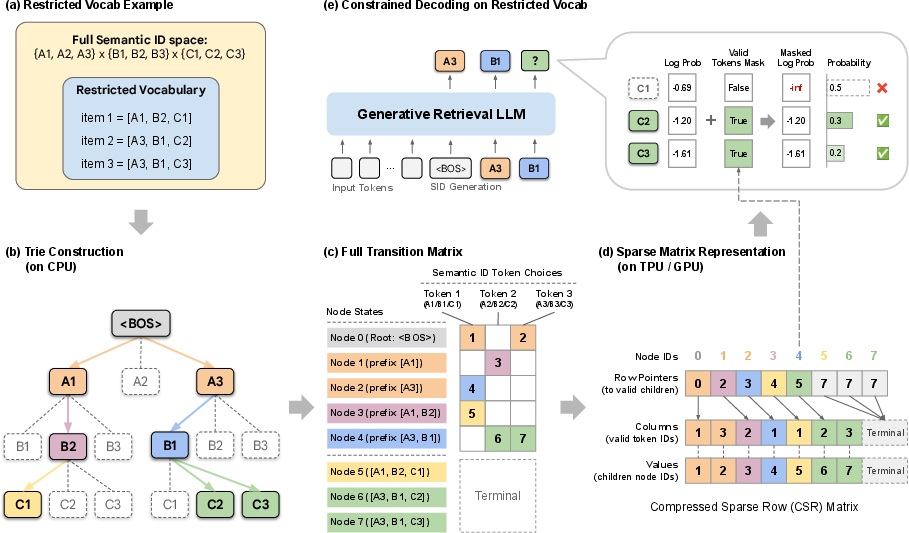
STATIC’s idea: turn the tree into math-friendly tables
- Flatten the trie into a sparse matrix (a table that stores only the non-empty parts), using a format called CSR (Compressed Sparse Row). In plain terms, it stores:
- Which next tokens are allowed from each state (prefix),
- And which state you move to if you pick that token.
- Keep a “state number” for each partial code in the beam. At each step:
- Look up all allowed next tokens for that state in one vectorized operation (a batch lookup the hardware likes).
- Create a mask (think of a stencil) that blocks illegal tokens by giving them a score of negative infinity, so they can’t be chosen.
- Do all of this on the GPU/TPU with no back-and-forth to the CPU (which is slow).
- Extra speed trick: For the very first 1–2 positions in the code, use a small, dense table for instant lookups (because those early steps are the most “branchy”). For later positions, use the sparse matrix, which stays small and fast because the allowed branches narrow down.
Why this is fast on GPUs/TPUs:
- GPUs/TPUs love regular, batched operations on contiguous memory. STATIC transforms messy tree walks into clean, batched table lookups.
- It’s “branch-free,” meaning it avoids if/else logic that would split GPU threads and slow them down.
- It pulls in the needed information in one coalesced read (like grabbing a whole shelf in one move), instead of many tiny random reads.
Main findings: What they achieved and why it matters
What they measured (on a YouTube-scale system with 20 million “fresh” items as the allowed set):
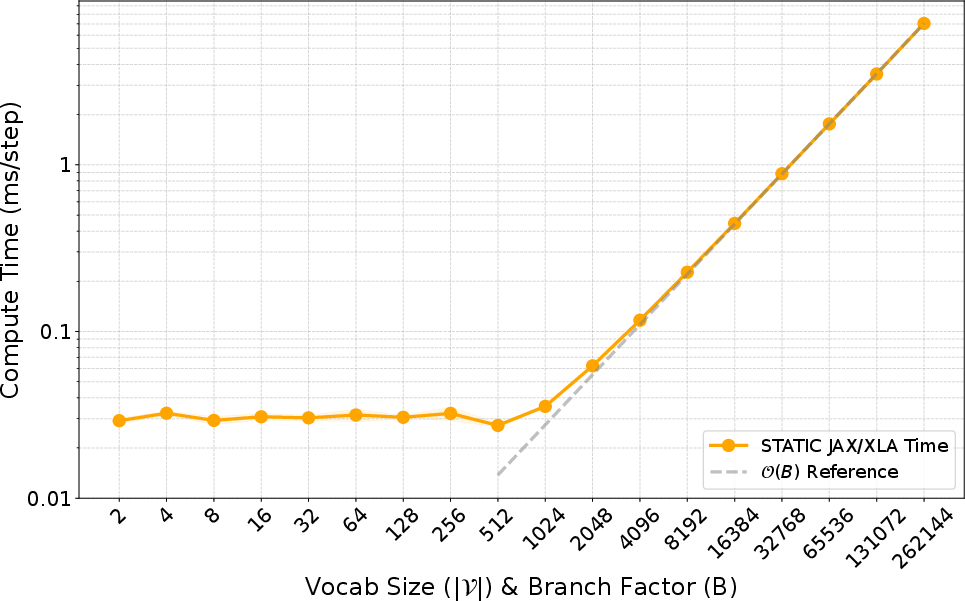
- Almost no slowdown: only +0.033 milliseconds per decoding step, which is just 0.25% of total model time per step.
- Huge speedups versus other methods:
- About 948× faster than a CPU-based trie approach.
- 47× to 1033× faster than a strong GPU/TPU baseline that uses binary search on a sorted list.
- Memory scales well: roughly 90 MB per 1 million allowed items. For 20 million items, about 1.5–1.8 GB on the accelerator, which is manageable at production scale.
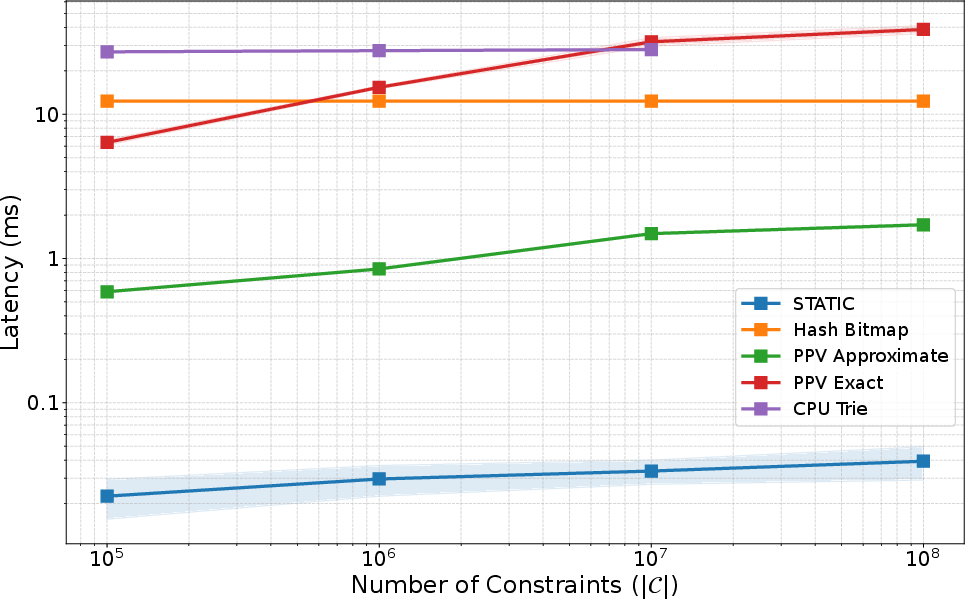
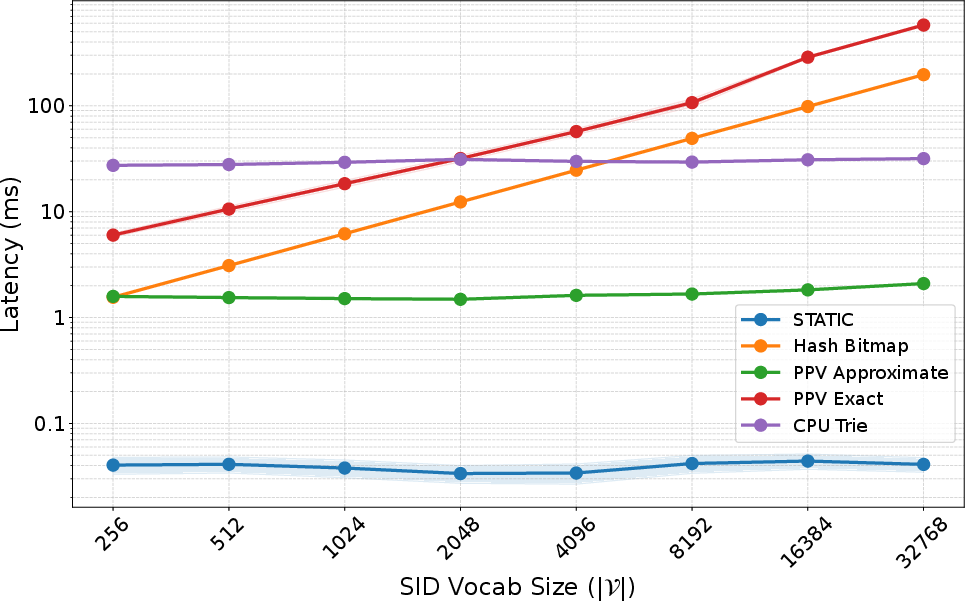
- Stable performance as things get bigger:
- Stays fast even as the allowed set gets very large.
- Nearly constant speed as the token vocabulary grows, thanks to the hybrid dense-then-sparse design.
Real-world impact:
- Deployed on YouTube for a “Home Feed” use case with a “last 7 days” constraint.
- Achieved 100% rule compliance (no out-of-date items slipped through).
- Increased views of fresh content (for example, +5.1% for 7-day fresh views).
- Improved user metrics, including click-through rate (+0.15%) and a satisfaction measure (+0.15%).
Academic benchmark impact:
- Helped with cold-start items (new items unseen during training) on Amazon Reviews datasets, by forcing the model to choose from a cold-start subset. This reduces “hallucinations” of invalid or old items and focuses the model on viable new content.
Why this matters:
- Enforcing constraints during generation avoids wasted compute and “empty” results when the model would have picked only invalid items.
- It lets one large model serve many different business needs just by swapping constraint sets (freshness, region, category, inventory).
Implications: Why this could be a big deal
- Makes strict, real-time constrained generation practical at massive scale. Companies can actually deploy LLM-based recommenders that follow rules without paying a big speed penalty.
- Simplifies operations: one powerful model can be reused across many use cases by changing the allowed set (fresh, in-stock, region-legal, etc.), instead of training many separate models.
- Better experience for users: more relevant, up-to-date content and fewer invalid recommendations.
- Helps with cold-start: focuses the model on new items when needed, improving discovery of fresh content.
- A blueprint for accelerator-friendly design: turning tree-like logic into vectorized, sparse matrix operations may inspire similar speedups in other areas that need constrained generation (like code generation with strict syntax, or speech/command systems with fixed menus).
In short, STATIC shows how to transform a good idea (constrained generation) into a practical, ultra-fast system for LLM-based recommendation—one that follows business rules, scales to tens of millions of items, and improves real user outcomes.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of the key uncertainties and unresolved issues left by the paper.
Theory and Correctness
- Provide a formal, end-to-end complexity analysis clarifying the apparent mismatch between the claimed O(1) I/O complexity and later statements that latency scales logarithmically with constraint set size ; specify assumptions, constants, and the precise conditions under which O(1) holds.
- Derive worst-case and probabilistic bounds on the per-level maximum branch factor for realistic SID distributions, and characterize latency when is large or skewed.
- Prove correctness and stability of the branch-free sanitization (Where/Scatter) under edge cases (e.g., repeated tokens, empty rows, large scatter collisions), including numerical considerations in log-space.
- Extend the formulation beyond fixed-length SIDs () to variable-length identifiers, including termination handling and its impact on CSR layout and kernels.
- Formalize guarantees for 100% constraint compliance under concurrent beam updates and device-side race conditions, especially in multi-chip execution.
System Design and Maintenance
- Quantify the end-to-end build time and engineering pipeline required to construct and deploy the CSR transition matrix and dense mask for large, frequently changing constraint sets (e.g., “last 7 days”), including daily/rolling-window updates.
- Design and evaluate incremental/streaming update mechanisms for the CSR and without full rebuilds or service interruption, including delta encoding and partial recompilation impacts on XLA/Inductor.
- Specify hot-swapping procedures for constraint sets on TPUs/GPUs without graph recompilation, and measure the latency/throughput impact of swapping at production cadence.
- Detail sharding/partitioning strategies when the CSR and early dense masks exceed on-chip memory; evaluate multi-chip distribution, interconnect overhead, and consistency guarantees.
- Provide a GPU-specific implementation and performance analysis (e.g., CUDA kernels, warp-level behavior, memory coalescing metrics), since results are reported only on TPU v6e.
- Assess memory footprint and performance on smaller accelerators or edge devices; explore compression (e.g., 16-bit/8-bit indices, delta coding) and its effects on latency and accuracy.
- Define failure-handling policies for beam collapse scenarios (all candidate tokens masked), including fallback generation, constraint relaxation strategies, or hybrid retrieval handoffs.
- Support and benchmark attribute- or predicate-based constraints (e.g., category, region, inventory) without full enumeration of , such as attribute-aware tries or composable constraint operators.
Evaluation and Benchmarking
- Conduct apples-to-apples comparisons with additional optimized baselines (e.g., GPU double-array tries, compressed perfect hashing, pruned FSTs with accelerator-friendly kernels) to isolate gains due to STATIC vs. implementation choices.
- Re-evaluate PPV baselines under consistent settings (full-logit vs top-k) and report exact vs approximate trade-offs, including top-k sensitivity and I/O behavior at scale.
- Run sensitivity analyses on beam size () and batch size () beyond the single configuration (batch=2, ), showing latency, throughput, and quality impacts across realistic ranges.
- Report comprehensive ranking quality metrics (e.g., Recall@k, NDCG@k, coverage, diversity, calibration) in addition to CTR; quantify trade-offs between strict constraint compliance and recommendation quality.
- Provide full details and results for the academic cold-start experiments (Amazon Reviews), including datasets, metrics, baselines, statistical significance, and generalization across domains.
- Extend online A/B testing to include long-term outcomes (retention, watch time, session length), fairness across user segments, and robustness to constraint churn; document confidence intervals and experiment duration.
- Measure end-to-end inference impact (model + STATIC + post-processing), not just per-step overhead, across heterogeneous production traffic patterns.
Applicability and Extensibility
- Demonstrate compatibility and performance with alternative decoding strategies (e.g., top-p/nucleus sampling, contrastive search, diverse beam search), and quantify any differences in constraint enforcement efficacy or latency.
- Support compositional constraints (logical AND/OR/XOR, CFG-like grammars) and mixed discrete/structured constraints; specify how STATIC can express and efficiently enforce these beyond membership in .
- Investigate training-time integration (e.g., constrained training, curriculum, RL with penalties for invalid tokens) to reduce reliance on inference-time masking; measure impacts on model calibration and exploration.
- Evaluate robustness to frequent constraint changes (e.g., inventory restocks, regional shifts) and provide SLAs for update latency vs. constraint freshness.
- Explore mixed-precision storage and kernels for CSR/ (e.g., fp16/int16/int8) and quantify effects on correctness, scatter collisions, and numerical stability in LogSoftmax masking.
- Analyze multi-objective scenarios (e.g., freshness + category + locality) and outline principled ways to prioritize or blend constraints without exhaustive enumeration.
- Provide guidance for constraint-set selection in cold-start regimes (e.g., how to populate , decay policies, automatic inclusion/exclusion) and measure the trade-offs between recall and novelty.
- Address cross-region/multi-corpus deployments (different SIDs per market), including multilingual compatibility and per-market constraint routing with minimal overhead.
Practical Applications
Overview
The paper introduces STATIC, a vectorized, accelerator-native constrained decoding method for LLM-based generative retrieval. By flattening tries into CSR sparse transition matrices and using branch-free kernels on TPUs/GPUs, STATIC enforces strict output constraints (e.g., freshness, locality, category, availability) with negligible latency overhead. Below are practical applications that leverage STATIC’s findings, methods, and engineering innovations, grouped by deployment horizon.
Immediate Applications
The following applications can be deployed now with existing tooling, hardware, and datasets.
- Bold business-logic-controlled generative recommender systems (freshness, locality, category, availability) (media/entertainment, e-commerce)
- Use STATIC to enforce strict corpus constraints (e.g., “uploaded within last 7 days,” “in stock,” “US-only inventory,” “summer clothes”) during decoding, preventing wasteful generation of invalid items and eliminating post-filtering failures.
- Potential tools/workflows: STATIC CSR builder (offline), per-market constraint sets, beam-search plugin for constrained logits masking, nightly refresh of constraints.
- Assumptions/Dependencies: Items must have Semantic IDs (fixed-length token sequences); a GR model (e.g., PLUM-like) is available; TPUs/GPUs with XLA/Inductor; constraint sets are maintainable at scale.
- Single model, multi-tenant deployments with per-tenant constraints (platform operations, SaaS marketplaces)
- Serve one large GR model across regions/verticals by swapping constraint matrices per tenant (e.g., country, brand, storefront, age-tier).
- Potential tools/workflows: Tenant-specific constraint loaders, configuration management, canary/A-B rollout.
- Assumptions/Dependencies: Per-tenant corpora are defined; HBM budget to load different CSR matrices; robust config governance.
- Cold-start promotion by constrained decoding (marketplaces, media platforms)
- Boost discovery of new items (never seen during training) by constraining decoding to a curated cold-start set and letting the GR model generalize with SID prefixes.
- Potential tools/workflows: “New arrivals” constraint sets, targeted experiments for new creators/sellers, re-ranking integration.
- Assumptions/Dependencies: New items are tokenized into SIDs; curated cold-start pool quality; monitoring for relevance trade-offs.
- Compliance and policy enforcement at generation time (policy/compliance, media licensing)
- Enforce legal/licensing rules (e.g., region-limited content, age-restricted catalog, takedown/removal) by removing SIDs from constraint sets and ensuring 100% compliance in decoding.
- Potential tools/workflows: Takedown pipeline connected to constraint set management; auditable change logs; rapid refresh cadence.
- Assumptions/Dependencies: Accurate mapping from policy events to item SIDs; timely propagation to CSR; governance approvals.
- Brand safety and curated catalog gating for ads and sponsored content (ads/marketing)
- Restrict GR to approved creatives/campaigns, blocklists, and brand-safety lists; ensure valid items only during generation.
- Potential tools/workflows: Ad-creative SID registry, campaign constraint sets, real-time blocklist updates.
- Assumptions/Dependencies: Creatives/campaigns represented as SIDs; low-latency updates; coordination with serving systems.
- Accelerator-efficient constrained decoding in production inference stacks (ML infrastructure, software)
- Replace CPU trie or binary-search PPV-based checks with STATIC to cut latency overhead to ~0.033 ms/step and avoid host-device round trips.
- Potential tools/workflows: Drop-in decoding masks in JAX/XLA or PyTorch/Inductor; VNTK kernel integration; performance dashboards.
- Assumptions/Dependencies: Access to TPUs/GPUs; beam search integration; acceptable memory budget (~90 MB per 1M items for constraints plus dense masks).
- Inventory-aware product search and recommendations (retail/e-commerce)
- Guarantee “in-stock” and “deliverable” recommendations by constraining to inventory-available SIDs; optionally slice by shipping promise or price bands.
- Potential tools/workflows: Availability-based constraint builder, per-warehouse or per-region corpora, nightly sync with ERP.
- Assumptions/Dependencies: Up-to-date inventory systems; stable SID mappings when stock changes; refresh mechanisms.
- Education and family-safe feeds with age/curriculum filters (education, consumer apps)
- Enforce age appropriateness (e.g., K–12 standards) or curriculum-specific corpora at decode time to ensure only vetted content is generated.
- Potential tools/workflows: Curriculum catalog constraints, teacher/admin override workflows, parental control integrations.
- Assumptions/Dependencies: Vetted corpus encoded as SIDs; standardized age/curriculum classification; policy governance.
- Academic benchmarking for strictly constrained GR (academia)
- Use STATIC to run controlled experiments (e.g., Amazon Reviews) with strict validity to study recall, cold-start, and latency at scale without confounding from post-filters.
- Potential tools/workflows: Open-source code, reproducible CSR builders, standardized datasets and SID pipelines.
- Assumptions/Dependencies: Availability of datasets and SID tokenizers; accelerator access; experiment reproducibility practices.
Long-Term Applications
These applications require additional research, engineering, or productization to be fully realized.
- Real-time, streaming constraint updates with low-latency CSR refresh (ML infra, operations)
- Move from batch/nightly to sub-minute updates (e.g., just-in-time takedowns, flash sales, live events) via incremental CSR construction or diff-based patching.
- Potential tools/workflows: Incremental CSR builders, streaming constraint services, cache invalidation strategies.
- Assumptions/Dependencies: Efficient online updates without graph recompilation; consistency guarantees under concurrent decode.
- Variable-length or hierarchical SIDs and mixed constraint compositions (ML research, infra)
- Extend STATIC beyond fixed-length L to variable-length sequences, nested hierarchies, or mixed hard/soft constraints (weights/priorities).
- Potential tools/workflows: EOS-aware kernels, hierarchical CSR schemas, soft mask integration into scoring.
- Assumptions/Dependencies: Model and decoding changes; new semiring/mask semantics; thorough validation.
- Cross-domain constrained generation (code, APIs, structured outputs) (software, developer tools)
- Apply the vectorized-trie approach to grammar-constrained or schema-constrained generation (e.g., API calls, JSON schemas, domain-specific languages), replacing pointer-heavy CFG/FST pipelines on accelerators.
- Potential tools/workflows: Grammar-to-CSR compilers, accelerator-native constraint engines for IDEs and service agents.
- Assumptions/Dependencies: Mapping grammars/schemas to efficient CSR structures without state explosion; tooling for developers.
- Privacy-first and regulated content governance embedded at decode (policy/compliance, data governance)
- Integrate STATIC with auditable policy engines to honor “right to be forgotten,” consent revocation, and data residency constraints at generation time.
- Potential tools/workflows: Policy-as-code services feeding constraint sets; audit trails; continuous compliance monitoring.
- Assumptions/Dependencies: Strong identity-to-SID mapping; robust governance; external audits.
- Hybrid GR + ANN ensembles with constrained candidate fusion (search/retrieval, ML systems)
- Combine STATIC-constrained GR with approximate nearest neighbor retrieval for coverage/latency trade-offs and robust fallbacks in extreme catalog conditions.
- Potential tools/workflows: Candidate fusion pipelines, constraint-aware re-ranking, dynamic source selection.
- Assumptions/Dependencies: Ensemble orchestration; consistent scoring; operational complexity.
- Memory-optimized deployments for edge accelerators or multi-tenant HBM limits (ML infra)
- Advance compression and sharing strategies for CSR and dense masks (e.g., trie compaction, quantization) to fit tighter memory budgets.
- Potential tools/workflows: CSR compression libraries, shared constraint pools, per-tenant memory isolation.
- Assumptions/Dependencies: Acceptable accuracy–memory trade-offs; safe compaction strategies.
- Constraint analytics and management platform (product/ops)
- Build a “Constraint Management Service” for creating, validating, monitoring, and A/B testing constraint sets, with performance/quality analytics and rollbacks.
- Potential tools/workflows: UI/CLI for constraint authoring, validation pipelines, SLA dashboards, incident response integrations.
- Assumptions/Dependencies: Organizational processes; data quality; role-based access controls.
- Multi-objective constrained decoding (quality, fairness, diversity) (research, policy)
- Integrate fairness/diversity-aware constraints or quotas as masked sets and dynamic policies to achieve multi-objective goals (e.g., exposure guarantees).
- Potential tools/workflows: Policy schedulers, dynamic mask switching, objective-aware beam search variants.
- Assumptions/Dependencies: Formalization of objectives; measurement frameworks; careful evaluation for unintended consequences.
- Cross-accelerator portability and standardized kernels (TPUs, GPUs, future NPUs) (ML infra)
- Standardize STATIC-like kernels across XLA/Inductor and future compilers, enabling vendor-neutral constrained decoding with consistent performance.
- Potential tools/workflows: Kernel libraries, GraphBLAS-inspired APIs for constraints, CI benchmarks across hardware.
- Assumptions/Dependencies: Compiler support; community adoption; maintenance across hardware generations.
Notes on Feasibility
- STATIC relies on items being represented as fixed-length Semantic IDs with level-specific codebooks. Adopting SID pipelines (e.g., via RQ-VAE) is a prerequisite for non-YouTube domains.
- Constraint sets must be expressible as prefix-closed subsets over SIDs. Complex policies may need pre-processing to align with prefix semantics.
- Dense masks (early levels) and CSR matrices (later levels) introduce memory overhead that scales with |V|d and the number of trie nodes. Capacity planning is necessary for very large catalogs.
- Hardware dependencies include accelerator access (TPU/GPU) and ML compilers that support static graphs and vectorized operations; integration into beam search is required.
- Quality outcomes (e.g., CTR uplift, cold-start gains) depend on curated constraint sets and the underlying model’s semantic generalization through SID prefixes.
Glossary
- Approximate nearest neighbor search: Algorithms that quickly find points close to a query in high-dimensional spaces with some approximation. "approximate nearest neighbor search such as ScaNN"
- Autoregressive decoding: Generating sequences by predicting each next token conditioned on previously generated tokens. "standard autoregressive decoding cannot natively support."
- Beam search: A heuristic search strategy that keeps the top-k partial sequences at each step to find likely outputs. "we typically employ beam search"
- Bloom-filter: A space-efficient probabilistic data structure for membership testing with false positives. "A Bloom-filter \cite{Bloom1970SpacetimeTI} style approach"
- Coalesced reads: Aligned, contiguous memory accesses that maximize bandwidth on accelerators. "via coalesced reads"
- Cold-start: The problem of recommending items or users with little or no historical data. "improve cold-start performance"
- Compressed Sparse Row (CSR): A storage format for sparse matrices using row pointers, column indices, and values. "Compressed Sparse Row (CSR) matrix"
- Constrained decoding: Enforcing structural or validity constraints during sequence generation. "existing constrained decoding methods"
- Context-Free Grammars (CFGs): Formal grammars that generate languages via production rules independent of context. "Context-Free Grammars (CFGs)"
- DISC-PPV: A hardware-aware constrained decoding approach featuring parallel prefix verification on-device. "DISC-PPV"
- Double-Array Trie: An array-based trie data structure optimizing space and traversal speed. "Double-Array Trie"
- Dual (user, item)-encoders: Two-tower models that separately embed users and items for retrieval via similarity. "dual (user, item)-encoders"
- Finite State Transducers (FSTs): Automata that map input symbol sequences to output sequences, often used to encode constraints. "Finite State Transducers (FSTs)"
- FlashAttention: An attention computation algorithm optimized for memory bandwidth and tiling efficiency. "FlashAttention"
- GraphBLAS: A standard for expressing graph algorithms as linear algebra over sparse structures. "the GraphBLAS standard"
- Hardware prefetchers: Processor mechanisms that fetch data into caches ahead of use to hide memory latency. "hardware prefetchers"
- High-Bandwidth Memory (HBM): Stacked DRAM providing very high memory bandwidth for accelerators. "High-Bandwidth Memory (HBM)"
- Host-device round-trips: Data/control transfers between CPU (host) and accelerator (device) during execution. "host-device round-trips"
- I/O complexity: A measure of costly data transfers between memory hierarchies, especially off-chip to on-chip. "I/O complexity"
- Inductor: A deep learning compiler backend (e.g., PyTorch Inductor) for generating optimized kernels. "XLA/Inductor"
- Memory coalescing: Combining memory accesses from parallel threads into fewer, wider transactions. "This prevents memory coalescing"
- Memory Wall: The growing performance gap between CPU/GPU compute speed and memory bandwidth/latency. "The ``Memory Wall'' remains the primary bottleneck"
- Mixture-of-Experts (MoE): A neural architecture with multiple expert subnetworks, selectively activated per input. "non-Mixture-of-Experts (MoE) architecture"
- Parallel Prefix-Verification (PPV): A method that parallelizes validity checks via binary search over sorted constraints. "Parallel Prefix-Verification (PPV)"
- PCIe: A high-speed interface standard for connecting accelerators to CPUs and memory. "PCIe transfer overhead"
- Pointer-chasing: Traversing pointer-linked data structures that cause irregular memory access patterns. "pointer-chasing"
- Prefix tree (trie): A tree that indexes sequences by shared prefixes for fast prefix-based lookups. "prefix tree (trie)"
- Residual-Quantized Variational AutoEncoder (RQ-VAE): An autoencoder that quantizes residuals across levels to produce discrete codes. "Residual-Quantized Variational AutoEncoder (RQ-VAE)"
- ScaNN: A scalable approximate nearest neighbor search library for high-dimensional embeddings. "ScaNN"
- Semantic IDs (SIDs): Discrete token sequences representing items, structured to reflect semantic similarity. "Semantic IDs (SIDs)"
- SIMT parallelism: Single Instruction, Multiple Threads execution model used by GPUs. "SIMT parallelism"
- Sparse Transition Matrix (STM): A sparse matrix encoding allowed transitions between trie states for vectorized checks. "Sparse Transition Matrix (STM)-based Trie Conversion"
- Static computation graphs: Fixed-shape, compile-time-known execution graphs required by some ML compilers. "static computation graphs"
- Transformer: A neural network architecture leveraging self-attention for sequence modeling. "Transformers"
- TPU: Google’s Tensor Processing Unit, an accelerator specialized for matrix-heavy ML workloads. "TPU v6e accelerators"
- Vectorized Node Transition Kernel (VNTK): A kernel that performs batched, branch-free trie transitions via sparse ops. "Vectorized Node Transition Kernel"
- Warp divergence: Performance loss when threads in a GPU warp follow different control paths. "GPU warp divergence"
- XLA: Accelerated Linear Algebra, a compiler framework for optimizing ML computations. "XLA-reliant"
Collections
Sign up for free to add this paper to one or more collections.