- The paper introduces L2D, a latent-space decoding framework that reduces inference latency by over 10x while maintaining recommendation accuracy.
- It outlines a memory construction method and two aggregation strategies—global and local—to create candidate item representations from LLM hidden states.
- Empirical results validate that L2D outperforms traditional baselines and scales effectively with larger LLMs, enabling plug-and-play recommendation.
Decoding in Latent Spaces for Efficient Inference in LLM-based Recommendation
Introduction and Motivation
The paper addresses a critical bottleneck in LLM-based generative recommendation: the substantial inference overhead incurred by autoregressive language-space decoding. While fine-tuning LLMs to generate item recommendations in natural language yields strong performance, the token-by-token generation process is computationally expensive and scales linearly with the recommendation list size. Existing acceleration techniques, such as grounding and speculative decoding, either degrade performance or remain confined to the language space. The central question is whether it is possible to bypass language-space decoding while preserving the generative training paradigm and leveraging the pretrained knowledge of LLMs.
Light Latent-space Decoding (L2D): Framework and Implementation
The proposed Light Latent-space Decoding (L2D) framework enables efficient item decoding by directly matching candidate items with the LLM's internal "thought" representations in the latent space, eliminating the need for autoregressive generation. The approach consists of three main steps:
- Memory Construction: After generative fine-tuning, the hidden states from the final LLM layer for each training sample (user history prompt) are paired with their ground-truth items and stored in a memory module. This step is fully pre-computable and does not affect inference latency.
- Candidate Item Representation Generation: For each candidate item, its latent representation is constructed by aggregating the hidden states associated with it in the memory. Two aggregation strategies are proposed:
- Global Aggregation: Averages all hidden states for an item, yielding a comprehensive representation.
- Local Aggregation: For a given test sample, selects the top-M most similar hidden states (by L2 distance) from the memory and averages those associated with the candidate item, producing a test-specific representation.
- Item Decoding: At inference, the hidden state of the test sample is compared (via L2 distance) to the candidate item representations. The top-K items with the highest similarity scores are recommended.
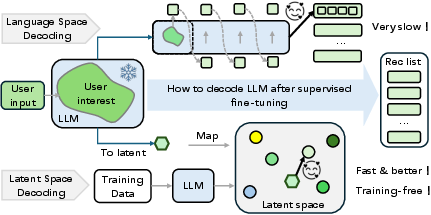
Figure 1: Latent-space decoding bypasses slow language-space decoding by matching candidate items with LLM internal 'thought' items in the latent space, preserving generative tuning and enabling efficient decoding.
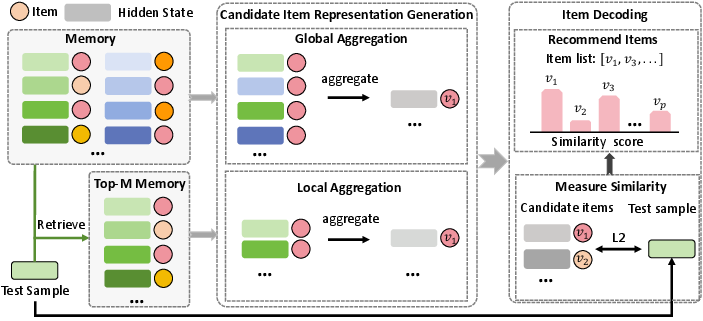
Figure 2: L2D framework overview: memory construction, candidate item representation via global/local aggregation, and item decoding by similarity matching.
Implementation Details
- Hidden State Extraction: For each prompt, extract the last hidden state from the final LLM layer.
- Memory Storage: Store (hj,vj) pairs for all training samples, where hj is the hidden state and vj is the ground-truth item.
- Aggregation:
- Global: For item v, hˉv=∣M(v)∣1hj∈M(v)∑hj.
- Local: For test sample t, select top-M most similar hj to ht; for item v, hˉvt=∣Mt(v)∣1hj∈Mt(v)∑hj.
- Decoding: For test hidden state ht and candidate item representation hv, compute S(ht,hv)=∥ht−hv∥21; recommend top-K items.
This approach is model-agnostic and does not require retraining or modification of the LLM architecture, making it plug-and-play for any generatively fine-tuned LLM recommender.
Extensive experiments on Amazon CDs and Games datasets demonstrate that L2D achieves over 10x reduction in inference latency compared to language-space decoding, while maintaining or improving recommendation accuracy. The method outperforms both traditional baselines (SASRec, GRU4Rec) and LLM-based methods (AlphaRec, BIGRec, GPT4Rec, D3) across Recall@K and NDCG@K metrics.
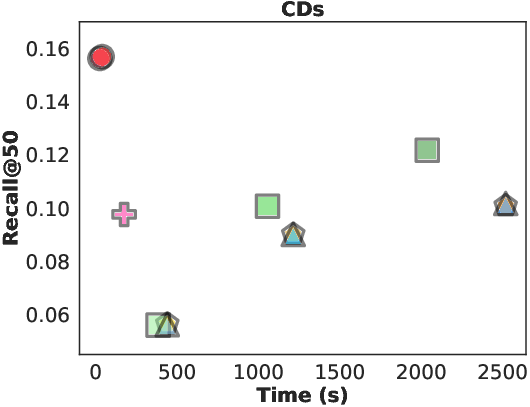
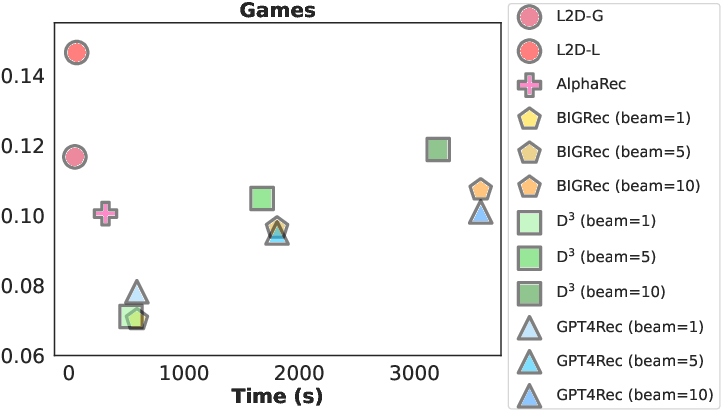
Figure 3: Recall@50 and inference overhead of LLM-based recommenders on two datasets; L2D achieves superior performance with minimal latency.
Aggregation Strategy Trade-offs
- Global Aggregation is robust in sparse scenarios, where items have few associated hidden states.
- Local Aggregation excels in dense scenarios, providing more personalized candidate item representations by focusing on test-specific aspects.
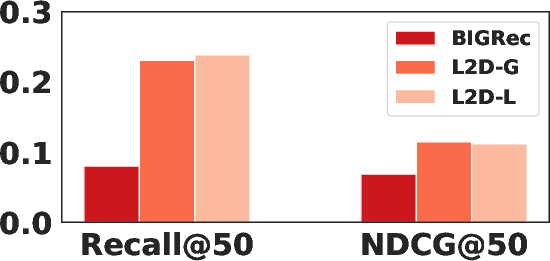
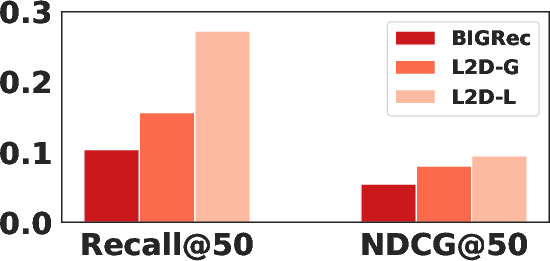
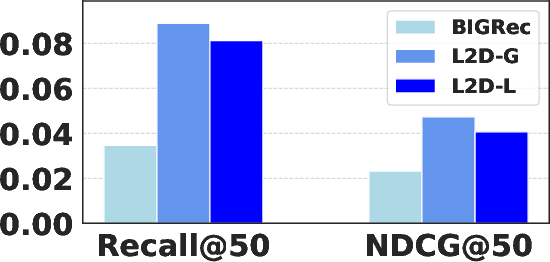
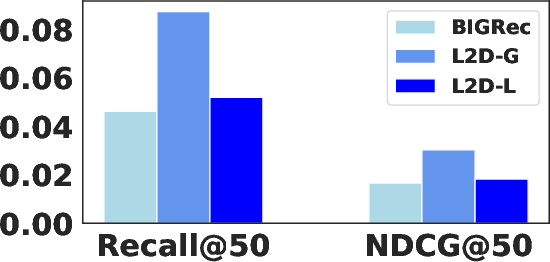
Figure 4: Performance of BIGRec, L2D-G, and L2D-L on sparse and dense scenarios; L2D-L is optimal in dense, L2D-G in sparse settings.
Hyperparameter Sensitivity
The local aggregation hyperparameter M (number of top similar hidden states) controls the trade-off between personalization and robustness. Increasing M improves performance up to a point, after which it converges to global aggregation.
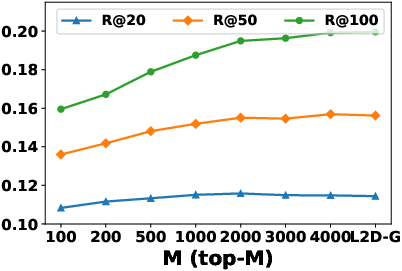
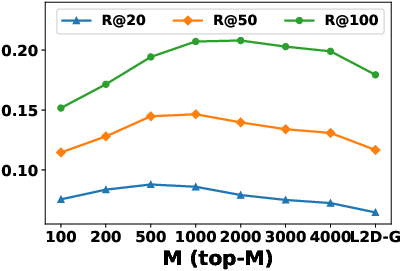
Figure 5: Impact of M on Recall for L2D-L; performance saturates as M increases, converging to L2D-G.
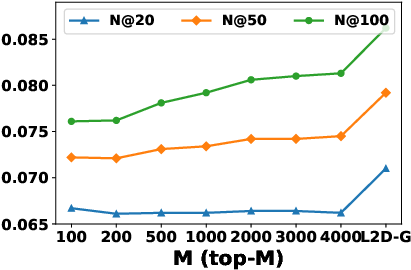
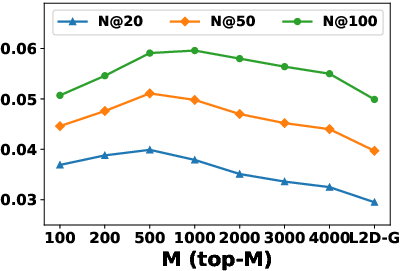
Figure 6: Impact of M on NDCG for L2D-L; similar saturation behavior as Recall.
Comparison with ID-based Classifiers
Directly training a classifier head to predict item IDs from hidden states is less effective, especially for sparse items, and requires additional training. L2D, by leveraging generative training and latent matching, achieves higher accuracy and better generalization to sparse scenarios.
Space and Scalability Considerations
- Memory Overhead: Storing hidden states for 109 samples (1024-dim, float16) requires ~2TB, feasible for large-scale deployments.
- Reservoir Sampling: Retaining only 30% of training samples still yields superior performance to baselines, enabling further space optimization.
- Model Generalizability: L2D scales effectively to larger LLMs (e.g., Llama3.1-8B), with consistent performance gains.
Practical and Theoretical Implications
L2D fundamentally shifts the decoding paradigm for LLM-based recommendation from language-space to latent-space, enabling efficient, scalable, and high-performance inference. The approach is compatible with any generatively fine-tuned LLM and does not require architectural changes or retraining, facilitating rapid deployment in real-world systems. The latent matching mechanism preserves the benefits of generative training, including rich user understanding and preference mining, while eliminating the computational bottleneck of autoregressive decoding.
Theoretically, L2D demonstrates that the internal "thought" representations of LLMs are sufficiently expressive for recommendation tasks, and that direct latent-space matching can fully leverage pretrained knowledge. This opens avenues for further research into latent-space reasoning, memory-efficient representation learning, and plug-and-play personalization modules for LLMs.
Limitations and Future Directions
- Memory Construction Overhead: Pre-computation of hidden states incurs time cost; more efficient memory construction methods are needed.
- Cold-start Items: L2D cannot recommend items with zero interaction history; future work may explore interpolation or auxiliary models.
- Memory Updating: Dynamic updating of memory with new user interactions is an open problem.
- Integration with Preference Alignment: Combining L2D with causality-aware or difference-aware personalization approaches may further enhance performance.
Conclusion
The L2D framework provides an efficient and effective solution for LLM-based recommendation by decoding in the latent space, bypassing the limitations of autoregressive language-space generation. Empirical results validate its superiority in both accuracy and inference efficiency. The approach is theoretically sound, practically scalable, and extensible to future developments in LLM personalization and recommendation.