- The paper introduces xGR, a novel framework that rethinks generative recommendation serving by integrating optimized attention, beam search, and scheduling to overcome memory and latency bottlenecks.
- It demonstrates impressive gains, including up to a 6.6× speedup in attention computations and a 3.5× throughput improvement under high concurrency.
- The study establishes new design patterns via KV cache partitioning, staged computation, and multi-stream scheduling for scalable, efficient recommendation systems.
Introduction and Motivation
The "xGR: Efficient Generative Recommendation Serving at Scale" (2512.11529) presents an architectural and system-level rethinking of serving platforms for generative recommendation (GR) systems. GR, which integrates transformer-based LLMs to directly predict recommended items from user-item behavioral sequences, represents a fundamental shift from cascaded discriminative pipelines prevalent in traditional recommendation systems. Unlike conventional LLM inference, GR systems operate under distinct constraints: extremely long prompt sequences encoding user history, very short fixed-length outputs (usually a handful of recommended item identifiers), a requirement for high-throughput beam search with large widths (to enhance retrieval diversity), and strict SLOs (e.g., P99 latency under 200ms at tens of thousands QPS). State-of-the-art LLM-serving systems such as vLLM and xLLM are fundamentally suboptimal in this scenario due to redundant KV cache access, inefficient block copying, severe memory fragmentation, and naive beam management.
The paper identifies three critical bottlenecks inherent to GR serving: (1) redundant memory operations due to repeated KV block loading/forking under wide beams on long prompts, (2) substantial latency and fragmentation induced by large candidate set sorting, item filtering, and beam forking, and (3) pipeline underutilization due to imbalanced and serial pipelines spread across scheduler, engine, and worker nodes, especially with lightweight GR models.
System Architecture: xGR Composition
The xGR system addresses these challenges by holistically redesigning attention computation, beam search, and scheduling. Its design is modular, with three interlocked components:
- xAttention: operator-level optimizations for self-attention (separating KV cache, staging computation)
- xBeam: algorithm-level acceleration for beam search (mask-driven valid path constraints, early sorting termination, structure reuse)
- xSchedule: system-level pipeline restructuring with multi-stream, resource-aware, three-tier batching and intelligent kernel dispatching.
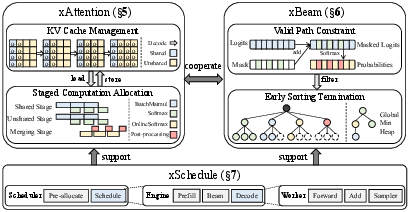
Figure 2: The xGR framework design, highlighting the interplay between xAttention, xBeam, and xSchedule for low-latency, high-concurrency GR.
Attention Mechanisms: KV Cache Management and Staged Computation
Traditional attention kernels fail to exploit the shared prefix among beams, incurring redundant, memory-bound KV cache access. xAttention divides the KV cache into a shared prefix and per-beam unshared suffixes, enabling allocation and update at the token (rather than block) granularity, which eliminates spurious copying and dramatically reduces memory fragmentation.
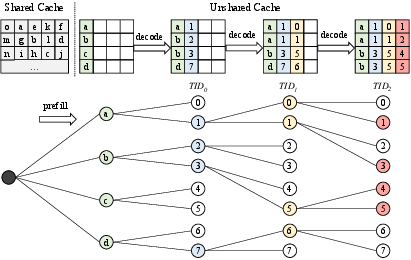
Figure 4: KV cache partitioning in xAttention separates shared long prompts (prefill) from unshared generated tokens, aligned precisely for beam reuse.
In-place, direction-aware cache updates preclude write-before-read hazards, permitting safe beam prefix extension as beam search progresses.
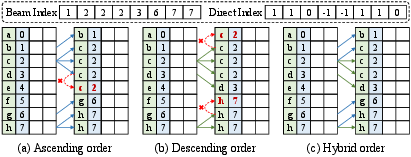
Figure 6: Direction-indexed in-place block update logic for the unshared cache in beam search.
Staged computation divides attention into shared prefix-attention and unshared beam-tail stages, allocating them to hardware core groups (CGs) for maximal parallelism and pipeline utilization, with resource balancing via learned predictors.
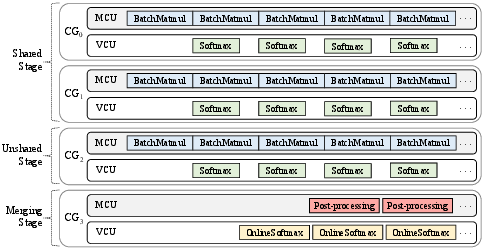
Figure 8: Pipeline-parallel execution strategy mapping attention computation across hardware core groups, maximizing compute/memory overlap.
Beam Search: Validity-Enforced, Efficient, Scalable
The combinatorial space of token sequences means that most outputs are invalid (nonexistent) items—a particular pathology in GR. xBeam integrates mask-driven constraint decoding at every phase, filtering out non-item token IDs using hybrid sparse–dense representations; masks are generated or updated as needed depending on expected candidate volumes and request stages.
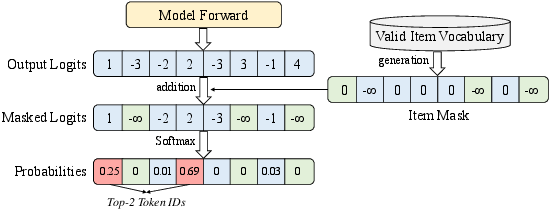
Figure 1: Valid path constraint ensures that only token sequences corresponding to real items can be proposed by beam search.
To further optimize, xBeam carries out partial sorting using early termination: only the top-BW cumulative log-probability sequences are maintained in a min-heap, and for descending-ordered log-prob beams, search is cut short once the heap cannot be improved, leading to large reductions in sorting overhead.
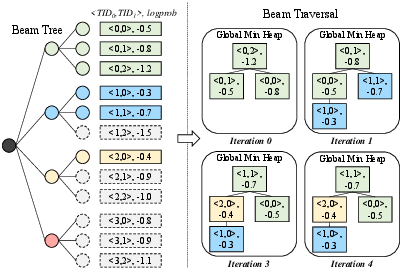
Figure 3: Early termination in partial sorting allows xBeam to avoid unnecessary candidate comparisons.
Memory and compute are additionally saved by reusing per-beam data structures, leveraging static allocations based on the known (fixed) beam width and output length, instead of repetitive creation/destruction cycles.
Scheduling and Pipeline Parallelism
Generative recommendation workloads, with their multi-level scheduling (scheduler–engine–worker), benefit from systemic pipeline parallelism. xSchedule enables overlap at request batching, intra-batch, and intra-request granularity. Host-side and device-side computations are aggressively overlapped, and device kernel launch is dispatched as captured graphs rather than individual calls (significantly lowering per-decode latency penalty for lightweight models).
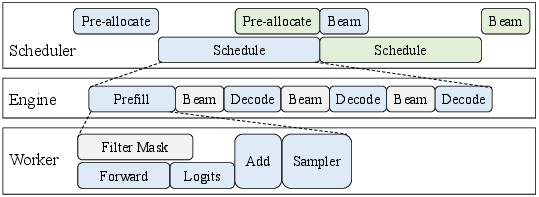
Figure 5: Overall xSchedule pipeline leverages three-tier scheduling and dynamic batching to fully utilize hardware resources under tight SLOs.
Masks are generated and transferred concurrently to computation (H2D overlap), and batches are dynamically sized and steered across multi-stream execution fabric to ensure maximized unit utilization under variable-length prompt loads.
Experimental Results
Kernel Latency and Memory Savings
xGR eliminates redundant KV cache loads and aligns memory management for scalability. Compared to PagedAttention and TreeAttention, xAttention achieves lower latency (e.g., a 6.6× speedup at BW=512) and transforms attention from memory-bound to compute-bound at the operator level.
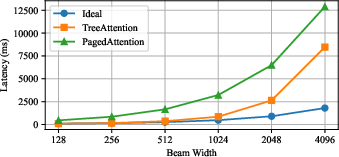
Figure 7: Attention kernel latency is almost independent of beam width under xGR, while PagedAttention and TreeAttention latency grows rapidly.
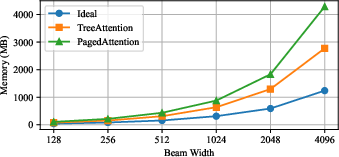
Figure 9: xAttention maintains minimal and flat memory footprint as beam width increases, in contrast to rapidly growing memory for older kernels.
End-to-End User-Perceptible Latency and Throughput
Serving Qwen3 and OneRec models on real-world e-commerce datasets (Amazon Review, JD Trace) at peak RPS, xGR sustains P99 latencies well below 200ms where baselines become orders of magnitude slower or fail due to system thrashing. Throughput improvements of at least 3.5× over baselines are consistent even at the highest concurrency or beam widths.
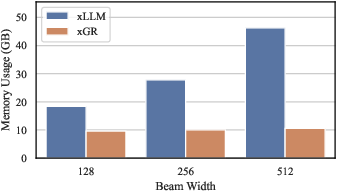
Figure 10: Peak memory usage of Qwen3-4B as beam width scales up; xGR outperforms alternatives by a large margin, supporting high-throughput concurrent requests.
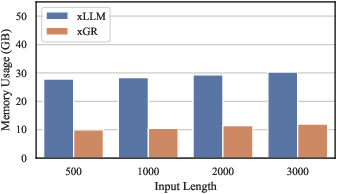
Figure 11: Memory consumption across user prompt lengths at fixed beam width; xGR remains flat, ideal for real production traffic.
Scheduling Optimizations
Ablation studies confirm that xSchedule’s kernel graph dispatch and multi-streaming are mandatory for ultra-high throughput, especially for lightweight GR models. Mask and filter optimizations incur minimal or negligible overhead, preserving full validity.
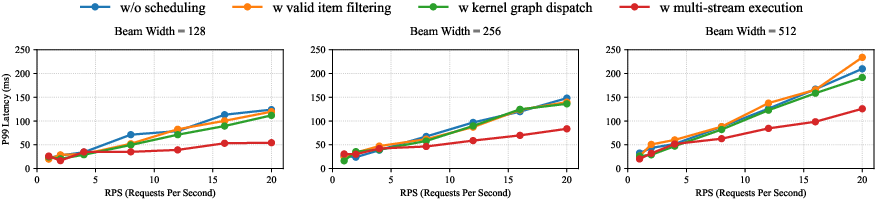
Figure 15: Ablation demonstrates the necessity of device-resident filtering and kernel graph optimizations for extreme request scaling.
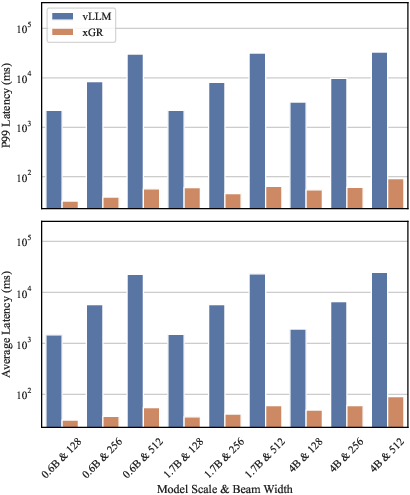
Figure 17: Large-scale deployment on GPU clusters verifies that xGR's GR-specific pipeline is key for latency and throughput improvements even on cutting-edge hardware.
Practical and Theoretical Implications
xGR is a rare end-to-end demonstration that targeted system and operator code redesign, rather than simply scaling hardware or adapting commodity LLM frameworks, is necessary for the emerging class of GR workloads. KV cache separation, intelligent staged computation, and mask-constrained beam search fundamentally change the memory-bandwidth and parallelism requirements, making high-concurrency, low-latency, and high-beam-width GR serving feasible. The work establishes a new baseline for GR inference platforms and offers design patterns directly usable in industry-scale deployments.
Conclusion
xGR proposes a comprehensive, workload-aware GR serving system that advances the state of the art in both throughput and tail latency for production-scale recommendation applications. By aligning memory management, attention kernel execution, beam search logic, and pipeline scheduling with the unique requirements of generative recommendation, xGR enables an order-of-magnitude improvement in efficiency. These innovations are likely to become foundational for future AI-powered personalization systems operating at the intersection of LLMs and massive-scale retrieval.

