CLIP Is Shortsighted: Paying Attention Beyond the First Sentence
Abstract: CLIP models learn transferable multi-modal features via image-text contrastive learning on internet-scale data. They are widely used in zero-shot classification, multi-modal retrieval, text-to-image diffusion, and as image encoders in large vision-LLMs. However, CLIP's pretraining is dominated by images paired with short captions, biasing the model toward encoding simple descriptions of salient objects and leading to coarse alignment on complex scenes and dense descriptions. While recent work mitigates this by fine-tuning on small-scale long-caption datasets, we identify an important common bias: both human- and LLM-generated long captions typically begin with a one-sentence summary followed by a detailed description. We show that this acts as a shortcut during training, concentrating attention on the opening sentence and early tokens and weakening alignment over the rest of the caption. To resolve this, we introduce DeBias-CLIP, which removes the summary sentence during training and applies sentence sub-sampling and text token padding to distribute supervision across all token positions. DeBias-CLIP achieves state-of-the-art long-text retrieval, improves short-text retrieval, and is less sensitive to sentence order permutations. It is a drop-in replacement for Long-CLIP with no additional trainable parameters.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how popular vision–LLMs like CLIP read long captions. The authors noticed that these models mostly pay attention to the very beginning of a caption (the first sentence and early words) and often ignore details that come later. They propose a simple training fix, called DeBias-CLIP, that teaches the model to read more evenly across the whole caption, not just the first sentence.
What questions are the authors trying to answer?
- Why do CLIP-like models struggle with long, multi-sentence captions?
- Do these models rely too much on the first sentence (which is usually a summary)?
- Can we train them in a simple way so they pay attention to details that appear later in the text?
- Will this make them better at matching images with long descriptions without hurting performance on short captions?
How did they study the problem? (Methods in simple terms)
Think of CLIP as a system that learns to match pictures with the right captions by seeing lots of image–text pairs. It learns by making the right pairs look “similar” and the wrong pairs look “different.”
Here’s what the authors did and what the terms mean in everyday language:
- Early-token bias test: They took real long captions and did two simple experiments:
- They added a few boring sentences like “This is a photo.” at the start. This pushed the useful information later in the caption. Performance dropped a lot, meaning the model didn’t handle later information well.
- They swapped the first two sentences. Performance also dropped, showing the model expected the summary to appear first.
- Long-CLIP check: They tested a known method (Long-CLIP) that stretches the model’s “reading window” so it can take in longer texts. But even then, the model still mainly focused on the first sentence and early words.
- DeBias-CLIP training idea: Instead of changing the model’s architecture, they changed how the training captions are prepared so the model doesn’t rely on first-sentence shortcuts. During training, they create two versions of each caption: the full caption and a shorter, shuffled version that avoids the summary and pushes info later.
To make that short version, they use three simple tricks:
- Remove the opening summary sentence.
- Randomly pick some of the remaining sentences (and don’t worry about keeping the original order).
- Add some “empty” tokens before the text (like leaving a few blank spaces at the start) so the model practices paying attention to later positions too.
Importantly, these tricks:
- Do not add any new model parts.
- Are applied only to how the text is fed to the model during training.
- Keep the full caption training alongside the short, sampled one, so the model learns from both long and short styles.
What did they find, and why does it matter?
Main findings:
- Many CLIP-style models, including improved versions, are “shortsighted”: they heavily favor the first sentence and early words in a caption.
- Moving or removing the first sentence causes big drops in performance, even in models designed for longer texts.
- DeBias-CLIP fixes this by changing how captions are sampled during training:
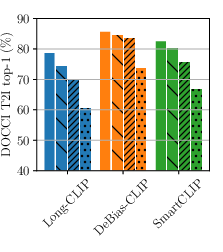
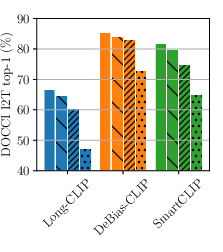
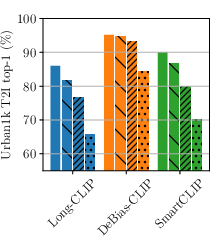
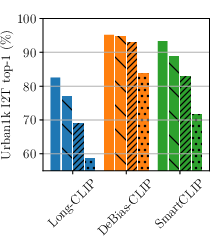
- It achieves state-of-the-art results on long-text image retrieval benchmarks (like DOCCI, DCI, and Urban1k).
- It also improves or maintains performance on short-text benchmarks (like COCO and Flickr30k).
- It’s more robust when the order of sentences is changed, or when the summary sentence is missing.
- The model’s attention across words becomes more balanced instead of heavily weighted to the beginning.
Why it matters:
- Real-world descriptions aren’t always “summary first.” Important details might appear in the middle or end of a paragraph.
- A model that reads evenly across a caption will be better at finding the right image for long, detailed queries and more reliable in tasks like searching large databases or working with long documents.
What’s the bigger impact?
- Better long-caption understanding: DeBias-CLIP helps models match images with rich, detailed descriptions where crucial information isn’t always at the start.
- Fewer changes, more gains: Because it doesn’t add new parameters, this method is efficient—a small data-preparation change yields big improvements.
- More realistic evaluation needed: Many test sets also put summaries first, which can hide these biases. The authors argue for new benchmarks that reflect real document-like text, where important details can appear anywhere.
- Practical applications: This can improve search across photo libraries, help systems read and match images in reports or textbooks, and make AI assistants more reliable when using long, descriptive inputs.
In short, DeBias-CLIP teaches models not to stop at the first sentence—and that simple shift makes them smarter readers of long captions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains uncertain or unexplored, framed so future researchers can act on it.
- Evaluation realism: Current long-text benchmarks largely follow a “summary-first” structure; the method is not evaluated on more realistic long-context settings (e.g., multi-paragraph document pages, reports, textbooks, RAG corpora) where key details may be scattered without an opening summary. Build and test on benchmarks without summary-first bias.
- Length scaling beyond 248 tokens: The approach extends CLIP’s context window to 248 tokens via linear interpolation and partial freezing of positional embeddings, but there is no evaluation for substantially longer sequences (e.g., 512–2k tokens). Assess scaling limits and failure modes under much longer inputs.
- Positional encoding strategy: Only linear interpolation with first-20-position freezing is explored. The work does not ablate freeze length, interpolation methods, or alternatives (e.g., RoPE, ALiBi, learned shifts, position dropout, random position shifting). Systematically compare these strategies for both short- and long-text retention.
- Architectural source of position bias: The paper observes stronger position sensitivity for SigLIP/SigLIP2 but does not disentangle causes (causal mask, loss, tokenizer, data). Perform controlled ablations (e.g., toggling causal masks, swapping text encoders) to isolate which architectural choices drive early-token bias.
- Padding design and distribution shift: Prepending PAD tokens is used to expose later positions during training, but the impact at inference (where such padding is absent) is unquantified. Compare PAD vs synthetic-neutral tokens, vary padding distributions, and evaluate sensitivity at inference.
- Summary removal robustness: The method assumes the first sentence is a summary; when it is not, dropping it may remove unique or critical information. Develop and evaluate automatic summary detection (or confidence thresholds) to avoid harmful removal, especially on heterogeneous corpora.
- Sentence segmentation dependency: The approach treats sentences as independent units and randomly reorders/subsamples them. There is no analysis of sentence segmentation quality, languages without clear punctuation, or domain-specific tokenization. Quantify performance under noisy segmentation and across multiple languages.
- Semantic coherence and coreference: Reordering/subsampling sentences may break coreference and discourse structure. Evaluate the impact on tasks requiring cross-sentence reasoning and coherence (e.g., detailed QA, long-form caption matching) and explore coherence-preserving sampling.
- Generalization beyond LLM captions: Training and much of evaluation rely on LLM-generated, stylistically uniform captions (ShareGPT4V, etc.). Test on long human-authored prose (news, Wikipedia, manuals) and domain-specific texts (medical, legal) to assess stylistic and domain generalization.
- Broader robustness testing: Beyond swapping/removing the first sentence, evaluate resistance to a wider set of perturbations—multi-sentence shuffles, paraphrases, distractor sentences, typographical noise, adversarial edits, and variable sentence length distributions.
- Attention analysis depth: The paper reports only last-layer aggregated self-attention over positions. Perform layer- and head-wise analyses, causal interventions (e.g., masking later tokens), and feature attribution to causally link later-token contributions to retrieval gains.
- Loss weighting schedule: Only static is explored. Investigate curricula or adaptive schedules (e.g., gradually increasing/decreasing short/long loss weights, per-sample weighting based on caption length or information density).
- Sampling policy design: Sentence subsampling is uniform and order-agnostic. Explore alternative policies (e.g., bias toward later sentences, content-aware sampling, order-preserving random spans) and curricula (e.g., progressively increase span depth).
- Combination with complementary techniques: The work does not test additive gains when combining DeBias-CLIP with image-side masking/pooling (SmartCLIP/FLAIR), distillation (LongD-CLIP), or alternative positional encodings (TULIP). Benchmark combined methods to assess complementarity.
- Image-side grounding effects: The method focuses on text-side debiasing; it does not examine whether image patch/token attention becomes more uniformly grounded. Evaluate phrase grounding, region-phrase alignment, and token-level attribution to assess visual grounding changes.
- Task transfer beyond retrieval: Only (long/short) retrieval is evaluated. Measure effects on zero-shot classification, dense tasks (segmentation/detection), VQA, and text-to-image generation guidance—especially fidelity to details that appear late in text.
- Error taxonomy and detail types: No breakdown of which detail categories improve (colors, counts, spatial relations, small objects, attributes). Conduct per-attribute analyses and negative case studies to identify remaining failure modes and guide targeted augmentations.
- Inference sensitivity across query lengths: While short-text retrieval improves on average, the model’s behavior across different query lengths (1 sentence to many) is not reported. Produce length-conditioned performance curves to detect under/over-weighting of first sentences.
- Compute and stability reporting: Training uses 3 epochs on 1.2M samples but lacks detailed compute/wall-clock, memory footprint, and seed sensitivity comparisons vs baselines. Report training cost, variance across random seeds, and scaling behavior.
- Retrieval metrics breadth: Only top-1 metrics are reported. Include R@K, mAP, nDCG, and calibration/confidence metrics to better assess ranking quality and practical retrieval performance.
- Multilingual applicability: All experiments appear to be in English. Evaluate whether the method extends to multilingual CLIP variants and languages with different sentence structures.
- Sentence- and token-level hyperparameters: Choices like “freeze first 20 positions,” padding ranges, and sampling counts lack comprehensive ablation. Provide sensitivity analyses to guide reproducible tuning.
- Safety and bias considerations: Shifting focus toward later details may inadvertently change social bias profiles or amplify specific content biases embedded in LLM captions. Audit fairness/bias impacts pre- and post-debiasing.
- Detection of summary-first bias in datasets: The presence and strength of summary-first bias are assumed but not quantified per dataset. Develop automatic measures of information concentration by position and use them to curate balanced training/evaluation sets.
Practical Applications
Immediate Applications
The paper introduces DeBias-CLIP, a drop-in training recipe that mitigates CLIP/Long-CLIP’s early-token and “summary-first” bias using three caption-level augmentations (remove opening summary sentence, random sentence subsampling, prefix padding) without adding trainable parameters. This directly enables the following deployable use cases:
- Long-caption–aware multimodal search upgrades — Sectors: software, media/creative, e-commerce, DAM/MAM
- What: Replace/augment existing CLIP/Long-CLIP encoders in image–text retrieval systems to maintain accuracy when users provide multi-sentence queries, reordered descriptions, or detailed briefs (e.g., creative shot lists, product specs).
- Tools/workflows: Fine-tune using the provided DeBias-CLIP recipe; integrate “sentence-permutation” regression tests; deploy as a “long-caption mode” in search APIs.
- Assumptions/dependencies: Access to a long-caption corpus (e.g., ShareGPT4V) or in-domain long captions; sentence segmentation available; training compute for 1–3 epochs; existing pipeline already supports CLIP encoders and longer positional embeddings.
- Document-vision RAG indexing for enterprise search — Sectors: software, legal, finance, public sector
- What: Use DeBias-CLIP to index figures/photos against longer document passages (MD&A, contracts, reports) so retrieval remains stable regardless of sentence order or where the key detail appears.
- Tools/workflows: “Image ↔ paragraph” indexer module; permutation-robust scoring during ingestion; visual evidence retrieval for RAG answers.
- Assumptions/dependencies: Fine-tuning with document-style long captions or synthetic recaptions; document OCR and sentence splitting; validation on sensitive domains before production.
- Photo and asset management with long notes — Sectors: marketing/creative, newsrooms, knowledge management
- What: Improve personal/enterprise media libraries so photos can be reliably found using long annotations, briefs, or editorial copy (not only short tags).
- Tools/workflows: Plug-in DeBias-CLIP model in DAM/MAM; bulk re-index; “order-insensitivity” QA.
- Assumptions/dependencies: Existing metadata pipelines; caption/notes often exceed 1–2 sentences; minimal model-serving changes.
- E-learning and digital libraries — Sectors: education, publishing
- What: Robustly match textbook figures and slides to long descriptive passages and study notes; better cross-references and study search.
- Tools/workflows: Figure–paragraph linker; lecture-assets auto-organization; librarian curation tools with sentence-order stress tests.
- Assumptions/dependencies: Availability of long figure descriptions or extracted paragraphs; permission for re-indexing.
- Maintenance and field operations visual retrieval — Sectors: manufacturing, energy, utilities
- What: Find reference images from lengthy SOPs and maintenance logs where crucial details often appear mid/late in the text.
- Tools/workflows: Technicians’ mobile app with DeBias-CLIP back end; “long-instruction” search profile.
- Assumptions/dependencies: In-domain long captions/logs; industrial privacy/compliance; modest fine-tuning effort.
- Case/teaching-file search (non-diagnostic) — Sectors: healthcare education, medical knowledge bases
- What: Enhance retrieval of exemplar images using multi-sentence teaching notes where findings are detailed beyond the first sentence.
- Tools/workflows: Teaching-file indexer; robust retrieval for grand rounds or continuing education.
- Assumptions/dependencies: In-domain captions; de-identification; not for clinical decision-making without validation.
- CLIP model QA and MLOps hardening — Sectors: software/ML platforms
- What: Adopt a permutation-robustness test suite (swap/remove first sentence; prefix padding) to detect “summary-first” shortcuts before deployment.
- Tools/workflows: CI checks for position sensitivity; token-attention uniformity monitors; A/B dashboards for long-caption T2I/I2T metrics.
- Assumptions/dependencies: Access to long-caption eval sets (Urban1k, DCI, DOCCI) or in-domain analogs.
- Dataset and prompt curation guidelines — Sectors: ML data operations
- What: Update captioning pipelines to reduce summary-first bias (e.g., randomized sentence order, structured detail-first variants) to improve generalization.
- Tools/workflows: “Caption debiasing” preprocessor (drop/permute summaries, add prefix padding during training); data documentation to track sentence-structure balance.
- Assumptions/dependencies: LLM-based captioning or human workflows can be adjusted; downstream tasks are retrieval-oriented.
- Long-prompt controllability exploration in generation — Sectors: creative tools, AIGC
- What: Where CLIP guidance is used, test DeBias-CLIP to better respect details in longer prompts (e.g., mood, fine attributes later in the prompt).
- Tools/workflows: Optional CLIP-guidance swap; long-prompt benchmark sets for image generation.
- Assumptions/dependencies: Your generator accepts a CLIP-like encoder; effectiveness depends on the specific T2I pipeline (some use non-CLIP text encoders).
Long-Term Applications
These opportunities likely require additional research, scaling, domain adaptation, and/or productization beyond the training recipe presented.
- Position-robust multimodal assistants — Sectors: productivity, education, customer service
- What: Vision-language agents that ground multi-paragraph context (e.g., pages mixing text and images) without being brittle to sentence order or summary placement.
- Tools/products: LMMs using DeBias-CLIP-style encoders for retrieval-augmented grounding; “order-invariant” agent benchmarks.
- Assumptions/dependencies: Integration with LMMs; alignment/safety; end-to-end evaluation on real tasks.
- Clinical retrieval and decision support (regulated) — Sectors: healthcare
- What: Link diagnostic images to long clinical notes/reports (where “Impression” vs “Findings” order varies) to surface relevant priors and literature.
- Tools/products: Position-robust case-retrieval systems; report–image linking for PACS.
- Assumptions/dependencies: Extensive in-domain fine-tuning; rigorous validation; regulatory clearance; privacy controls.
- Legal discovery and compliance evidence retrieval — Sectors: legal, finance, public sector
- What: Match images/figures/photos to long filings, emails, and reports (where critical details are not front-loaded) to increase recall and reduce manual review.
- Tools/products: E-discovery vision–text indexers with order-invariance; audit trails for retrieval steps.
- Assumptions/dependencies: Secure on-prem deployment; domain-specific long-caption corpora; scalability to millions of documents.
- Scientific figure and dataset retrieval across literature — Sectors: academia, R&D
- What: Cross-paper retrieval aligning figures to multi-sentence captions and descriptive paragraphs beyond the first line.
- Tools/products: Literature discovery engines; reproducibility assistants mapping figures ↔ methods or results sections.
- Assumptions/dependencies: High-quality parsing and sentence segmentation; large-scale indexing; disciplinary variation in caption style.
- Instruction-following robots grounded by long language — Sectors: robotics, logistics, home automation
- What: Better grounding of long, detailed instructions (e.g., “go to the shelf with … then pick the item with …”) where key constraints are mid-sentence or later.
- Tools/products: Perception stacks with DeBias-CLIP-based retrieval for language-conditioned visual search; robustness tests for instruction permutations.
- Assumptions/dependencies: On-device efficiency; closed-loop policy integration; safety.
- Benchmarking and standards for order-invariance — Sectors: standards bodies, policy
- What: New public benchmarks that avoid summary-first bias and explicitly test sentence-order invariance; procurement guidelines requiring such tests for public-sector deployments.
- Tools/products: Position-robustness evaluation suites; standardized reporting on token-attention distribution.
- Assumptions/dependencies: Community adoption; dataset curation funding.
- Multilingual and cross-script long-caption robustness — Sectors: global platforms, localization
- What: Extend debiasing to languages with different sentence/word-order conventions and punctuation (where “first sentence” semantics vary).
- Tools/products: Multilingual DeBias-CLIP variants; cross-lingual retrieval for documents and media.
- Assumptions/dependencies: Large multilingual long-caption corpora; sentence segmentation quality in each language.
- Safer, fairer multimodal models — Sectors: policy, trust & safety
- What: Reduce spurious reliance on early tokens that could encode biases from templated captions; improve fairness by distributing supervision across positions.
- Tools/products: Auditing tools that flag position shortcuts; training-time debiasing policies.
- Assumptions/dependencies: Access to diverse, representative long-caption data; fairness auditing protocols.
- Data- and compute-efficient scaling of long-context VLMs — Sectors: AI infrastructure
- What: Combine DeBias-CLIP’s simple augmentations with large-scale training to maintain short-text performance while scaling long-context alignment.
- Tools/products: Training recipes for billion-scale long-caption corpora; “drop-in” long-context encoders for downstream apps.
- Assumptions/dependencies: Compute budget; careful choice of positional-embedding extension; curriculum over short vs long losses (λs scheduling).
- Cross-modal generation with position-robust conditioning — Sectors: AIGC, design tools
- What: Improve controllability of long prompts in image or video generation by conditioning on encoders that do not collapse onto the first sentence.
- Tools/products: Long-prompt evaluation harnesses; hybrid guidance mixing DeBias-CLIP with native text encoders.
- Assumptions/dependencies: Integration into generation stacks; empirical validation on creative tasks.
Notes on feasibility and integration:
- The approach assumes captions can be sentence-segmented; random sentence sampling works well for contrastive retrieval but may harm coherence-dependent tasks (e.g., generation or NLG), requiring task-specific adaptations.
- For SigLIP/SigLIP2 or other CLIP-like encoders, the paper shows consistent gains, but position sensitivity from pretraining can persist; expect residual order effects without deeper architectural changes.
- Positional-embedding extension and λs (short-caption loss weight) matter operationally; the paper finds small λs (≈0.1) balance short/long retrieval, with degradation at higher values.
- Domain-specific deployments (e.g., healthcare, legal) require in-domain long-caption pairs and strong governance (privacy, compliance, bias evaluation).
Glossary
- batch-wise PCA operator: A principal component analysis applied per batch to approximate image features with a low-rank representation. "a batch-wise PCA operator~\cite{zhang2024long} that approximates the image feature vector from a low-rank decomposition."
- causal mask (text causal masks): A masking scheme that enforces autoregressive dependency in sequences by preventing attention to future tokens. "the use of text causal masks (CLIP vs SigLIP/SigLIP2)."
- contrastive learning: A training paradigm that pulls matched image-text pairs together and pushes mismatches apart in representation space. "via image-text contrastive learning on internet-scale data."
- contrastive loss: The objective used in contrastive learning to increase similarity of positive pairs and decrease similarity of negatives. "allowing the models to minimize the contrastive loss without needing to extend the effective context window size."
- contrastive pretraining: Pretraining with a contrastive objective to learn aligned representations across modalities. "a dual-encoder, contrastive pretraining paradigm"
- context window: The maximum sequence length (in tokens) a model can effectively attend to. "CLIP models were originally trained with a short context window (77 tokens)"
- cross-modal alignment: Aligning representations across different modalities (e.g., image and text). "adds image/text self-supervision and cross-modal alignment,"
- distillation: A training technique where a student model learns from a teacher model’s outputs or representations. "LongD-CLIP~\cite{feng2025retaining} trains with a second distillation phase"
- dual-encoder: An architecture with separate encoders for each modality (image and text) whose embeddings are compared via similarity. "a dual-encoder, contrastive pretraining paradigm"
- effective context window: The portion of the context window the model practically uses for information, which can be smaller than the nominal limit. "extend the effective context window size."
- end-of-text (EOT) token: A special token indicating the end of a text sequence. "Here, SOT and EOT refer to start-of-text and end-of-text tokens, respectively."
- fine-tuning: Adapting a pretrained model to a specific task or dataset with additional training. "fine-tuning a pretrained CLIP model on a small long-caption dataset"
- image-feature pooling: Aggregating spatial image features into a compact representation, potentially guided by text queries. "FLAIR~\cite{xiao2025flair} uses text features as queries for image-feature pooling,"
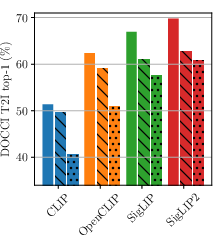
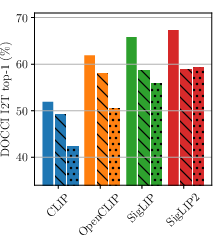
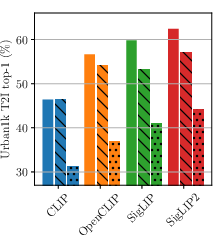
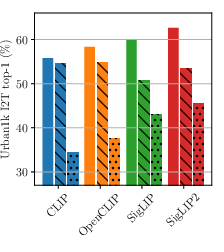
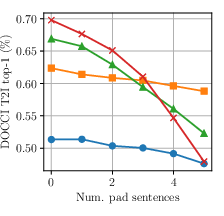
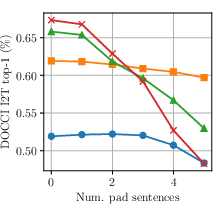
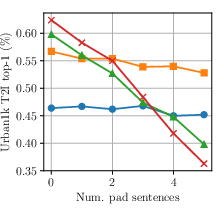
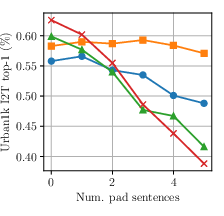
- image-to-text retrieval: Finding the best-matching text descriptions for a given image. "Top-1 image-to-text retrieval on DOCCI"
- linear interpolation (of positional embeddings): Extending positional embeddings to longer sequences by interpolating existing positions. "linearly interpolating the pretrained modelâs positional embeddings to a longer window"
- long captions: Multi-sentence, detailed textual descriptions that exceed short caption lengths. "training CLIP encoders~\cite{zheng2024dreamlip, xiao2025flair, xie2025fg} or VLMs~\cite{chen2024sharegpt4v, deitke2025molmo} with curated long captions instead of short captions"
- padding tokens: Special tokens added to sequences to reach a required length or shift content position. "we add padding tokens to the start of the tokenized sampled caption"
- pairwise sigmoid: A contrastive objective variant replacing softmax with sigmoid computed pairwise between examples. "SigLIP~\cite{zhai2023sigmoid} replaces softmax with pairwise sigmoid for better scaling."
- positional embeddings: Vector encodings that inject token position information into transformer models. "positional embeddings"
- pre-softmax attention weights: Attention weights measured before the softmax normalization step, used for analysis. "the averaged pre-softmax attention weights"
- Retrieval-Augmented Generation (RAG): Systems that retrieve relevant documents to augment inputs for generation tasks. "Retrieval-Augmented Generation (RAG) pipelines."
- rotary positional embeddings: A positional encoding method that rotates queries and keys to encode relative positions. "rotary positional embeddings~\cite{su2024roformer}"
- self-attention: A mechanism that lets tokens attend to other tokens in the sequence to compute contextualized representations. "a steady decline in self-attention as a function of token depth"
- self-supervised losses: Objectives that learn from the data itself without explicit labels, such as contrastive or reconstruction losses. "SLIP~\cite{mu2022slip} and SILC~\cite{naeem2024silc} add image-only self-supervised losses,"
- sentence sub-sampling: Randomly selecting a subset of sentences from a caption to encourage robustness and reduce bias. "applies sentence sub-sampling and text token padding"
- start-of-text (SOT) token: A special token marking the beginning of a text sequence. "Here, SOT and EOT refer to start-of-text and end-of-text tokens, respectively."
- stretched positional embeddings: Positional embeddings extended to longer contexts by interpolation or scaling. "The use of stretched positional embeddings has since been adopted in several state-of-the-art long-caption retrieval methods,"
- student-teacher frameworks: Training setups where a teacher model supervises a student model, often for distillation. "does not require multi-stage or student-teacher frameworks"
- temperature parameter: A scaling factor in softmax-based losses that controls the sharpness of probability distributions. "a temperature parameter"
- text-conditional masking network: A module that masks parts of image features conditioned on text to focus alignment. "SmartCLIP learns a text-conditional masking network to mask image feature channels that are not significant for alignment"
- text-to-image diffusion: Generative models that synthesize images from text prompts using diffusion processes. "text-to-image diffusion,"
- text-to-image retrieval: Finding the best-matching images for a given text query. "On DOCCI text-to-image retrieval, swapping the first and fourth sentences of the long caption (Move) substantially degrades performance"
- tokenizer: A function or model that converts raw text into discrete tokens for model input. "The caption C can be tokenized with a tokenizer as "
- token depth: The position index of a token within a sequence, often used when analyzing attention across positions. "as a function of token depth"
- token limit: The maximum number of tokens supported by a model’s text encoder. "the token limit of 77 of the CLIP text encoder"
- vision-LLMs (VLMs): Models that jointly process visual and textual data for multimodal tasks. "or VLMs~\cite{chen2024sharegpt4v, deitke2025molmo}"
- visual question answering (VQA): A task where a system answers questions about images. "visual question answering (VQA),"
- zero-shot classification: Classifying images into categories without seeing labeled examples during training by using text prompts. "zero-shot classification,"
- zero-shot segmentation: Segmenting images into classes without labeled segmentation data for those classes, using text guidance. "zero-shot segmentation,"
Collections
Sign up for free to add this paper to one or more collections.