- The paper introduces conditional neural control variates (CNCV) that achieve full amortization and variance reduction in Bayesian inverse problems using Stein's identity.
- CNCV leverages hierarchical affine coupling layers and ensemble averaging to compute divergence efficiently and manage high-dimensional parameter spaces.
- Numerical results confirm robust variance reduction and strong sample efficiency across both Gaussian and nonlinear posteriors, reducing computational cost.
Amortized Stein-Based Neural Control Variates for Bayesian Inverse Problems
Motivation and Problem Context
Estimation of posterior expectations in Bayesian inverse problems is computationally demanding when relying on Monte Carlo (MC) methods, especially in PDE-constrained scenarios where each sample can require an expensive forward solve. While control variates (CVs) have been established as a method for variance reduction in MC estimators, traditional CV approaches—especially those leveraging Stein's identity—are non-amortized and require retraining for every new data observation, incurring prohibitive computational cost. This paper introduces conditional neural control variates (CNCV), a modular, observation-conditioned variance reduction method, that leverages joint model–data samples and the posterior score function to learn CVs that generalize across arbitrary observations without retraining, thus delivering full amortization.
Stein's Identity and Neural Control Variate Construction
Stein's identity offers a principled approach for constructing CVs with zero expectation under the target posterior. Specifically, for any smooth function ϕ(x,y), Stein's identity ensures
Ep(x∣y)[∇x⋅ϕ(x,y)+ϕ(x,y)⋅∇xlogp(x∣y)]=0.
Parameterizing ϕ using neural networks enables flexible, high-capacity CV families. However, exact computation of the divergence for a generic neural architecture incurs O(d) backward passes for d-dimensional parameter spaces. To address this, the paper employs hierarchical affine coupling layers with a triangular Jacobian, enabling exact, efficient computation of the divergence in a single forward pass.
An ensemble of hierarchical trees with random input permutations further increases the expressivity, guaranteeing robust correlation with the quantity of interest across all dimensions and facilitating vector-valued CVs that operate efficiently in high-dimensional settings.
CNCV Training and Inference Pipeline
CNCV training leverages joint samples (x,y) drawn from the prior predictive distribution; these are standard byproducts of simulation-based inference pipelines. Posterior score functions, necessary for Stein-based construction, can be obtained analytically from physics-based models, via neural operator surrogates, or through learned conditional normalizing flows (CNFs) and diffusion models. The entire CNCV model—including all ensemble members—is trained offline to minimize the mean squared error between the quantity of interest and the CV-augmented estimator. Once trained, inference is performed by drawing posterior samples (from any compatible sampler) and evaluating the CNCV across arbitrary new observations, with zero retraining, retaining the amortized property.
Numerical Results: Variance Reduction and Robustness
Dimension Scaling and Sample Efficiency
Experiments on Gaussian posteriors demonstrate CNCV achieves variance reduction factors (VRF) in [0.03,0.15] across d∈{2,4,8,16} for mean estimation, with VRF below $0.08$ at d≤8 and $0.27$ at d=16 for variance estimation. Strong sample efficiency gains are observed, with VRF invariant to MC sample size.
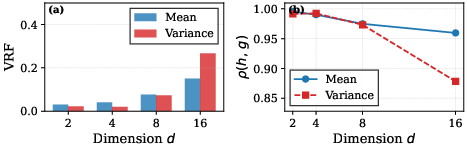
Figure 1: VRF exhibits mild growth with dimension for CNCV mean and variance estimation; correlation between h and g remains high across d.
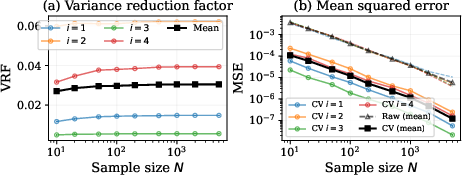
Figure 2: CNCV delivers constant VRF and substantial MSE reduction, matching $1/N$ scaling with a lower constant factor.
Generalization to Non-Gaussian and Nonlinear Posteriors
CNCV is validated on the Rosenbrock "banana-shaped" posterior and nonlinear forward models such as F(x)=Ax+sin(x). Amortization is confirmed: a single trained CNCV yields robust variance reduction across diverse test observations, achieving VRF in [0.08,0.23] on Rosenbrock and 0.57±0.29 on nonlinear posteriors.
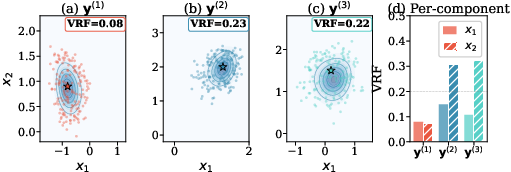
Figure 3: CNCV generalizes to unseen observations in banana-shaped Rosenbrock posteriors, maintaining low VRF across diverse inference conditions.
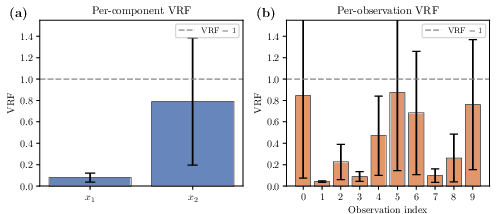
Figure 4: Posterior variance estimation VRF reveals disparity: modes with strong nonlinear correlation are harder to control.
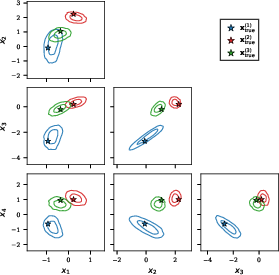
Figure 5: Nonlinear posteriors exhibit complex structure; CNCV posterior means (stars) closely track true parameters.
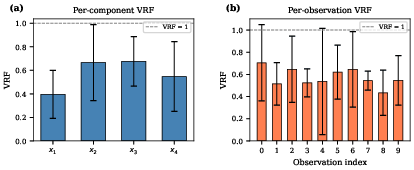
Figure 6: CNCV provides consistent variance reduction across all components and observations in nonlinear settings.
Training Efficiency and Ensemble Size Effects
CNCV converges rapidly during training, with VRF dropping orders of magnitude within a modest data regime. Ensemble size L is significant; L≥8 yields saturating variance reduction, supporting the default L=16.
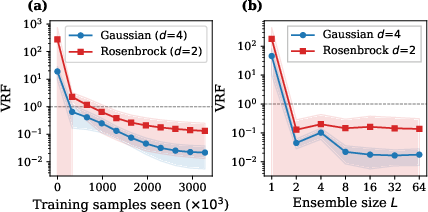
Figure 7: VRF decreases quickly with training sample size; ensemble size is critical for achieving strong variance reduction.
Robustness to Score Approximation
CNCV's efficacy persist under score approximation via CNFs and diffusion models. VRF and correlation with the target remain high, with only marginal degradation relative to analytic scores, confirming robustness to moderate score inaccuracies.
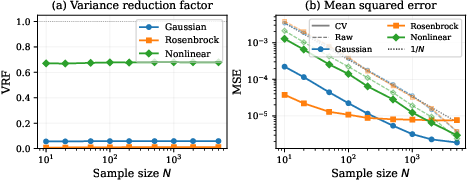
Figure 8: CNCV remains sample-size invariant and achieves strong constant-factor MSE improvement with CNF-learned scores.
High-Dimensional PDE-Constrained Applications: Darcy Flow
For a 100-dimensional PDE-constrained Darcy flow inverse problem, CNCV paired with a CNF posterior achieves VRF ∼0.18, delivering a 5.5× reduction in estimator MSE at fixed sample size. CNCV posterior means accurately reconstruct the log-permeability field, and estimator variance is strongly reduced for high-frequency (low variance) KL modes.
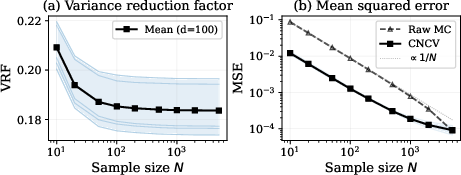
Figure 9: CNCV achieves sample-size invariant VRF and a 5.5× MSE reduction on the Darcy flow problem.
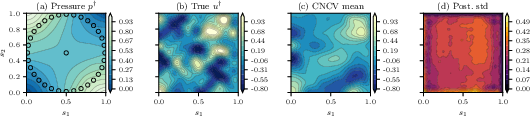
Figure 10: CNCV posterior reconstructions for Darcy flow closely match truth; uncertainty concentrates in sensor-sparse regions.
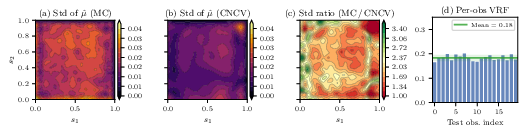
Figure 11: Pixelwise standard deviation is reduced most significantly along large-scale spatial modes; VRF is consistent across test observations.
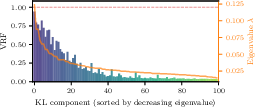
Figure 12: VRF per KL component shows stronger reduction for high-frequency modes unconstrained by data; leading modes with large eigenvalues yield VRF near unity.
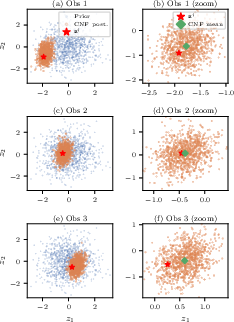
Figure 13: CNF posteriors concentrate correctly around the true parameters in KL space for diverse held-out observations.
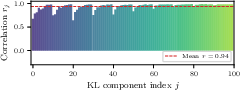
Figure 14: CNF score functions exhibit high correlation (mean rˉ=0.94) with adjoint-based physics scores.
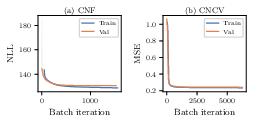
Figure 15: CNCV ensemble and CNF model loss curves indicate smooth convergence and absence of overfitting.



Figure 16: CNCV posterior means generalize well across multiple held-out Darcy flow observations.



Figure 17: Individual posterior samples retain variability; mean reconstructions smooth over uncertain modes.
Theoretical and Practical Implications
CNCV offers a modular, amortized variance reduction mechanism for Bayesian inverse problems, compatible with simulation-based inference workflows and agnostic to the source of posterior samples and scores. Its flexibility enables integration with both physics-based and learned (e.g., CNF, diffusion) samplers, delivering significant computational savings via strong variance reduction. The zero-mean guarantee imposed by Stein's identity is empirically preserved irrespective of the neural architecture choice, provided score and samples are consistently sourced. CNCV notably does not bias the MC estimator or alter the underlying posterior, but enhances estimator efficiency.
Practically, CNCV is especially advantageous in scenarios where high-fidelity forward model evaluations dominate computational budgets. In high-dimensional settings, CNCV achieves strong VRF for modes unconstrained by data, aligning with theoretical expectations from the eigenstructure of the prior covariance.
Theoretically, CNCV represents the first amortized Stein-based control variate architecture, contributing new methodology at the intersection of score-based inference, neural transport architectures, and MC variance reduction. Its robust performance with learned scores opens avenues for scaling uncertainty quantification and Bayesian inference in forward models, inverse problems, and beyond.
Future Research Directions
Potential extensions include:
- Combining CNCV with iterative, observation-specific refinement procedures for further variance reduction.
- Application to policy gradient estimators in reinforcement learning for improved sample efficiency.
- Integration with latent function space autoencoders for scalable inference in infinite-dimensional or functional spaces.
- Leveraging CNCV for amortized uncertainty quantification in digital twins and generative AI-powered model surrogates.
Conclusion
Conditional neural control variates, leveraging amortized training and Stein's identity, enable significant variance reduction in MC posterior expectation estimation for Bayesian inverse problems. The hierarchical coupling layer architecture, ensemble averaging, and compatibility with simulation-based inference yield robust, scalable performance in both low- and high-dimensional settings. CNCV complements existing MC and variational inference methods, enhancing sample efficiency while generalizing across observations without retraining, with theoretical guarantees preserved under mild score approximation error. Its practical and theoretical implications support broader adoption in uncertainty quantification, inverse problem solving, and probabilistic modeling.

